






 文章讲述了甲骨文这一古老的文字系统及其文化价值,同时介绍了如何利用现代技术,特别是YOLOv5深度学习模型进行甲骨文字符的检测和识别。通过一系列模型的开发和对比,展示了技术在考古研究中的应用和影响。
文章讲述了甲骨文这一古老的文字系统及其文化价值,同时介绍了如何利用现代技术,特别是YOLOv5深度学习模型进行甲骨文字符的检测和识别。通过一系列模型的开发和对比,展示了技术在考古研究中的应用和影响。
甲骨文,又称“契文”、“甲骨卜辞”、“殷墟文字”或“龟甲兽骨文”,是迄今为止在中国考古发现中年代最早的成熟文字系统,具有无比深厚的历史与文化内涵。这一独特的文字体系,不仅为我们揭示了汉字的源头,更是中华优秀传统文化的根脉,展现了古代中国人民的智慧与创造力。甲骨文的发现可追溯到清乾隆年间,但真正引起学术界关注的是在1899年。商代前期的甲骨文遗存主要发现于郑州商城,而商代后期则以安阳殷墟的出土最为丰富和具有代表性。这些甲骨文主要出现在龟甲和兽骨上,数量众多,据统计,截至目前,甲骨文发现总计约十五万片,经科学考古发掘的有三万五千余片,单字数量已逾四千字左右。这些珍贵的甲骨文记录,为我们打开了一扇通往古代社会文化的窗户。
甲骨文的内容丰富多样,主要记载了商王室的占卜活动,涉及祭祀、战争、农业、狩猎、气象等诸多方面。通过甲骨文,我们可以窥见商代社会的政治、经济、文化、宗教等多个层面的生活面貌。同时,甲骨文也反映了当时人们的思维方式、价值观念以及审美取向,为我们理解古代社会提供了宝贵的资料。从文字学的角度来看,甲骨文已具备汉字构形的各种类型,兼备传统“六书”中之“四体”,即象形、指事、会意、形声。这表明在殷商晚期,以甲骨文为代表的汉字已基本确立了构形方式,构形系统已逐步发展成熟。这一文字体系不仅为后来的汉字发展奠定了基础,也对世界文明史产生了深远影响。此外,甲骨文在书法艺术上也具有重要地位。其错落多姿而又和谐统一的字形结构,被誉为中国书法史上的第一块瑰宝,开启了中国书法艺术的先河。甲骨文作为中国古代文化的瑰宝,不仅具有极高的历史价值和文化价值,也为我们研究古代社会、文字演变以及书法艺术提供了丰富的素材和线索。作为历史考古学家,我们有责任深入挖掘和研究这些珍贵的文化遗产,为传承和弘扬中华优秀传统文化贡献自己的力量。
在前文系列博文中,我们已经进行了很多相关的开发实践,感兴趣的话可以自行移步阅读即可:
《勇闯第十四届MathorCup【一】,从无人问津到一夜爆火,肝到凌晨,我们用AI深度学习技术带你实现手写甲骨文字符图像检测识别系统》
《勇闯第十四届MathorCup【二】,从无人问津到一夜爆火,肝到凌晨再接再厉,基于实况甲骨文拓片图像数据开发实现甲骨文字符检测识别系统》
《勇闯第十四届MathorCup【三】,从无人问津到一夜爆火,肝到凌晨卧听风雨,基于单字符甲骨文字符图像数据开发实现甲骨文字符识别系统》
《勇闯第十四届MathorCup【四】,从无人问津到一夜爆火,肝到凌晨迎接黎明,基于轻量级MobileNet模型开发构建实况甲骨文拓片单字符图像识别分析系统》
《python开发构建轻量级卷积神经网络模型实现手写甲骨文识别系统》
《紧接上文,基于轻量级yolov5s模型开发构建手写甲骨文检测识别系统》
《python基于yolov7开发构建手写甲骨文检测识别系统》
《探索考古文字场景,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建文本考古场景下的甲骨文字符图像检测识别系统》
《探索考古文字场景,基于YOLOv9全系列【gelan/gelan-c/gelan-e/yolov9/yolov9-c/yolov9-e】参数模型开发构建文本考古场景下的甲骨文字符图像检测识别系统》
《探寻殷墟文化,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建殷墟考古场景下的甲骨文字符检测识别分析系统》
《探索考古文字场景,基于YOLOv7【tiny/l/x】不同系列参数模型开发构建文本考古场景下的甲骨文字符图像检测识别系统》
《探索考古文字场景,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建文本考古场景下的甲骨文字符图像检测识别系统》
本文的主要目的是想要基于经典的YOLOv5模型来开发构建80种类的甲骨文检测识别系统,数据集是我们自主开发构建的,用于科研学术实验,首先看下实例效果:
接下来简单看下实例数据:

本文是选择的是YOLOv5算法模型来完成本文项目的开发构建。相较于前两代的算法模型,YOLOv5可谓是集大成者,达到了SOTA的水平,下面简单对v3-v5系列模型的演变进行简单介绍总结方便对比分析学习:
【YOLOv3】
YOLOv3(You Only Look Once version 3)是一种基于深度学习的快速目标检测算法,由Joseph Redmon等人于2018年提出。它的核心技术原理和亮点如下:
技术原理:
YOLOv3采用单个神经网络模型来完成目标检测任务。与传统的目标检测方法不同,YOLOv3将目标检测问题转化为一个回归问题,通过卷积神经网络输出图像中存在的目标的边界框坐标和类别概率。
YOLOv3使用Darknet-53作为骨干网络,用来提取图像特征。检测头(detection head)负责将提取的特征映射到目标边界框和类别预测。
亮点:
YOLOv3在保持较高的检测精度的同时,能够实现非常快的检测速度。相较于一些基于候选区域的目标检测算法(如Faster R-CNN、SSD等),YOLOv3具有更高的实时性能。
YOLOv3对小目标和密集目标的检测效果较好,同时在大目标的检测精度上也有不错的表现。
YOLOv3具有较好的通用性和适应性,适用于各种目标检测任务,包括车辆检测、行人检测等。
【YOLOv4】
YOLOv4是一种实时目标检测模型,它在速度和准确度上都有显著的提高。相比于其前一代模型YOLOv3,YOLOv4在保持较高的检测精度的同时,还提高了检测速度。这主要得益于其采用的CSPDarknet53网络结构,主要有三个方面的优点:增强CNN的学习能力,使得在轻量化的同时保持准确性;降低计算瓶颈;降低内存成本。YOLOv4的目标检测策略采用的是“分而治之”的策略,将一张图片平均分成7×7个网格,每个网格分别负责预测中心点落在该网格内的目标。这种方法不需要额外再设计一个区域提议网络(RPN),从而减少了训练的负担。然而,尽管YOLOv4在许多方面都表现出色,但它仍然存在一些不足。例如,小目标检测效果较差。此外,当需要在资源受限的设备上部署像YOLOv4这样的大模型时,模型压缩是研究人员重新调整较大模型所需资源消耗的有用工具。
优点:
速度:YOLOv4 保持了 YOLO 算法一贯的实时性,能够在检测速度和精度之间实现良好的平衡。
精度:YOLOv4 采用了 CSPDarknet 和 PANet 两种先进的技术,提高了检测精度,特别是在检测小型物体方面有显著提升。
通用性:YOLOv4 适用于多种任务,如行人检测、车辆检测、人脸检测等,具有较高的通用性。
模块化设计:YOLOv4 中的组件可以方便地更换和扩展,便于进一步优化和适应不同场景。
缺点:
内存占用:YOLOv4 模型参数较多,因此需要较大的内存来存储和运行模型,这对于部分硬件设备来说可能是一个限制因素。
训练成本:YOLOv4 模型需要大量的训练数据和计算资源才能达到理想的性能,这可能导致训练成本较高。
精确度与速度的权衡:虽然 YOLOv4 在速度和精度之间取得了较好的平衡,但在极端情况下,例如检测高速移动的物体或复杂背景下的物体时,性能可能会受到影响。
误检和漏检:由于 YOLOv4 采用单一网络对整个图像进行预测,可能会导致一些误检和漏检现象。
【YOLOv5】
YOLOv5是一种快速、准确的目标检测模型,由Glen Darby于2020年提出。相较于前两代模型,YOLOv5集成了众多的tricks达到了性能的SOTA:
技术原理:
YOLOv5同样采用单个神经网络模型来完成目标检测任务,但采用了新的神经网络架构,融合了领先的轻量级模型设计理念。YOLOv5使用较小的骨干网络和新的检测头设计,以实现更快的推断速度,并在不降低精度的前提下提高目标检测的准确性。
亮点:
YOLOv5在模型结构上进行了改进,引入了更先进的轻量级网络架构,因此在速度和精度上都有所提升。
YOLOv5支持更灵活的模型大小和预训练选项,可以根据任务需求选择不同大小的模型,同时提供丰富的数据增强扩展、模型集成等方法来提高检测精度。YOLOv5通过使用更简洁的代码实现,提高了模型的易用性和可扩展性。
训练数据配置文件如下:
# Dataset
path: ./dataset
train:
- images/train
val:
- images/test
test:
- images/test
# Classes
names:
0: O0
1: O1
2: O2
3: O3
4: O4
5: O5
6: O6
7: O7
8: O8
9: O9
10: O10
11: O11
12: O12
13: O13
14: O14
15: O15
16: O16
17: O17
18: O18
19: O19
20: O20
21: O21
22: O22
23: O23
24: O24
25: O25
26: O26
27: O27
28: O28
29: O29
30: O30
31: O31
32: O32
33: O33
34: O34
35: O35
36: O36
37: O37
38: O38
39: O39
40: O40
41: O41
42: O42
43: O43
44: O44
45: O45
46: O46
47: O47
48: O48
49: O49
50: O50
51: O51
52: O52
53: O53
54: O54
55: O55
56: O56
57: O57
58: O58
59: O59
60: O60
61: O61
62: O62
63: O63
64: O64
65: O65
66: O66
67: O67
68: O68
69: O69
70: O70
71: O71
72: O72
73: O73
74: O74
75: O75
76: O76
77: O77
78: O78
79: O79实验截止目前,本文将YOLOv5系列五款不同参数量级的模型均进行了开发评测,接下来看下模型详情:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv5 object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/yolov5
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 1024]
l: [1.00, 1.00, 1024]
x: [1.33, 1.25, 1024]
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)
]在实验训练开发阶段,所有的模型均保持完全相同的参数设置,等待漫长的训练完成后,来整体进行评测对比分析。
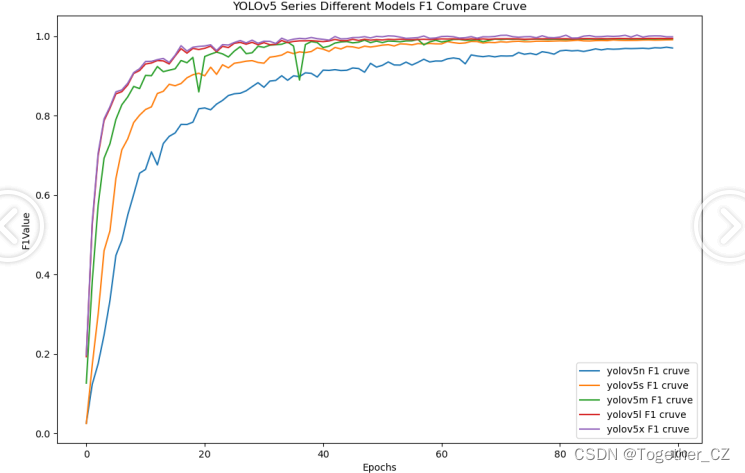
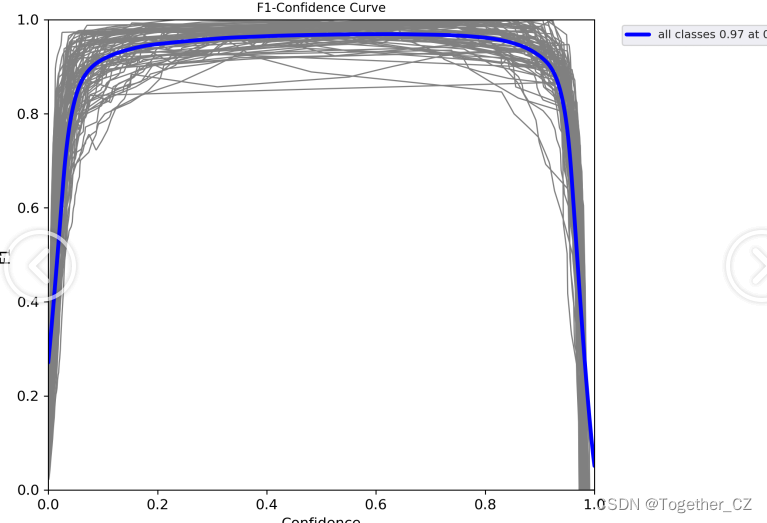
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能.F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
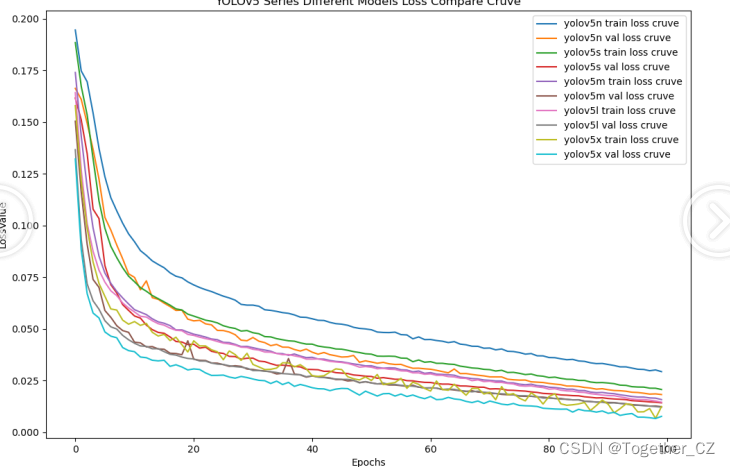
【loss曲线】
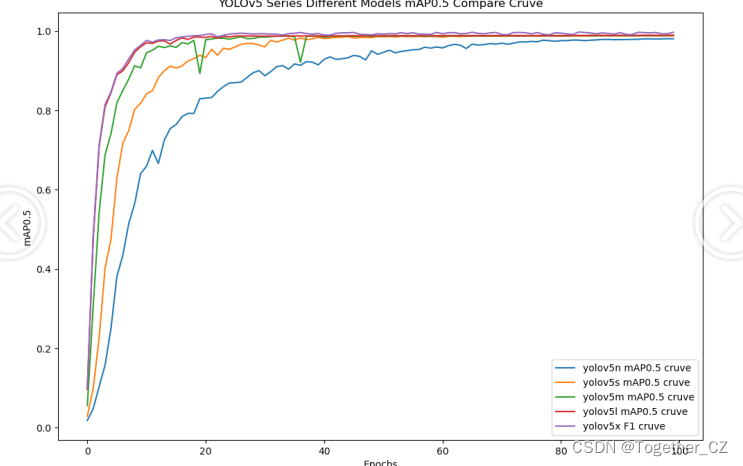
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
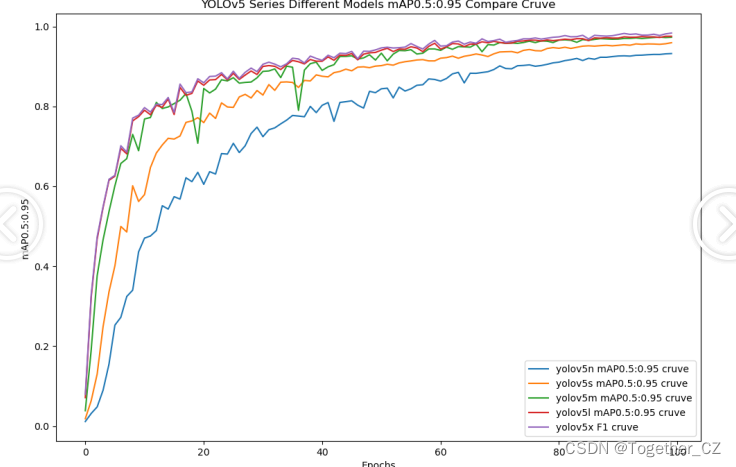
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
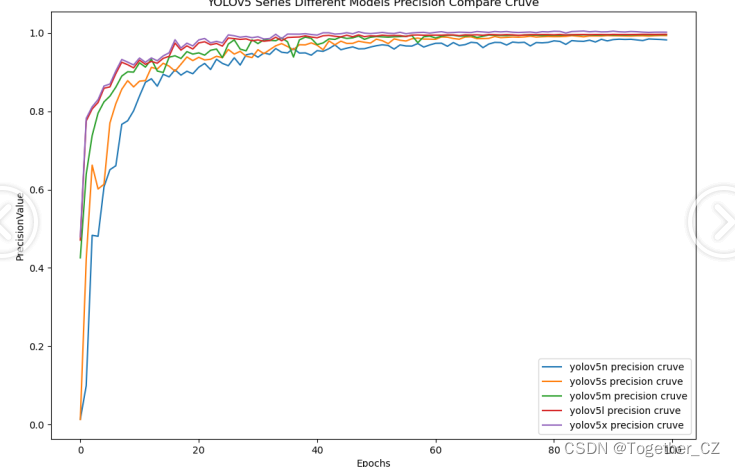
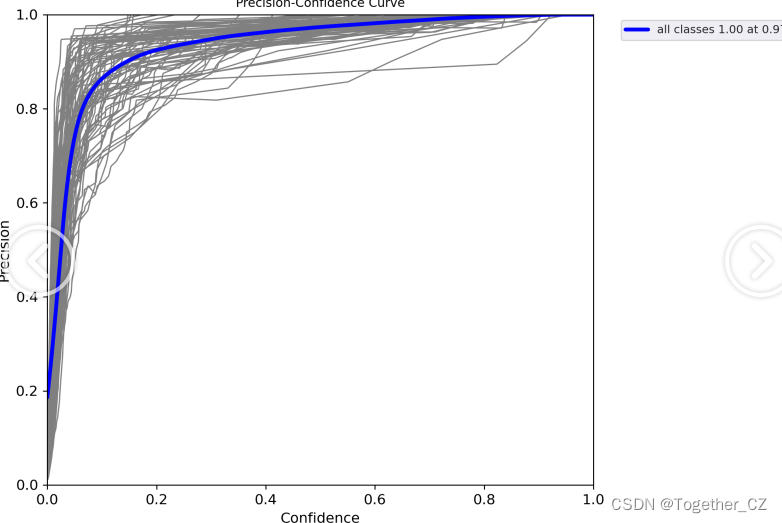
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
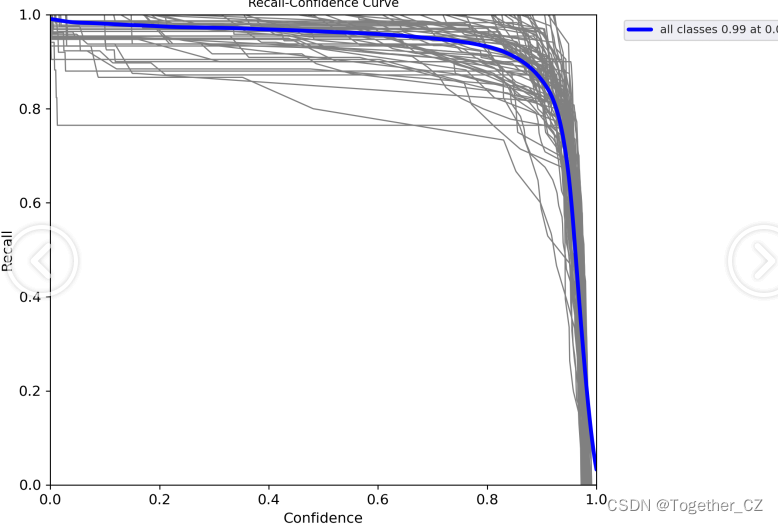
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
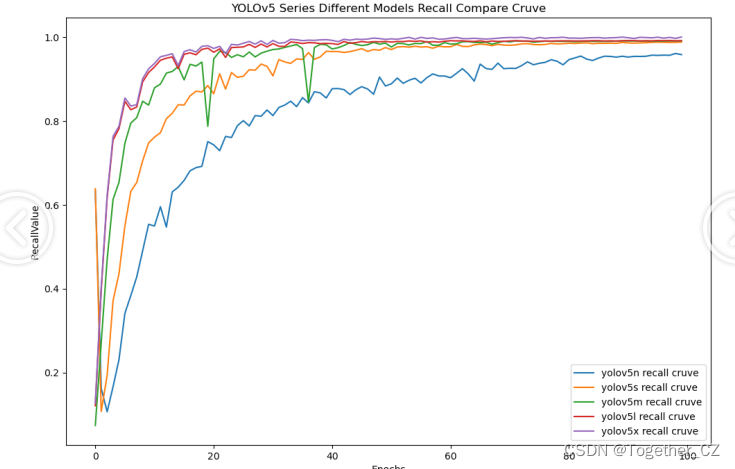
整体5款模型对比结果来看,不难看出:n系列的模型效果最差,其他四款模型则是达到了较为相近的水准,这里我们综合考虑使用s系列的模型作为最终的推理模型。
接下来看下s系列模型的详情。
【离线推理实例】
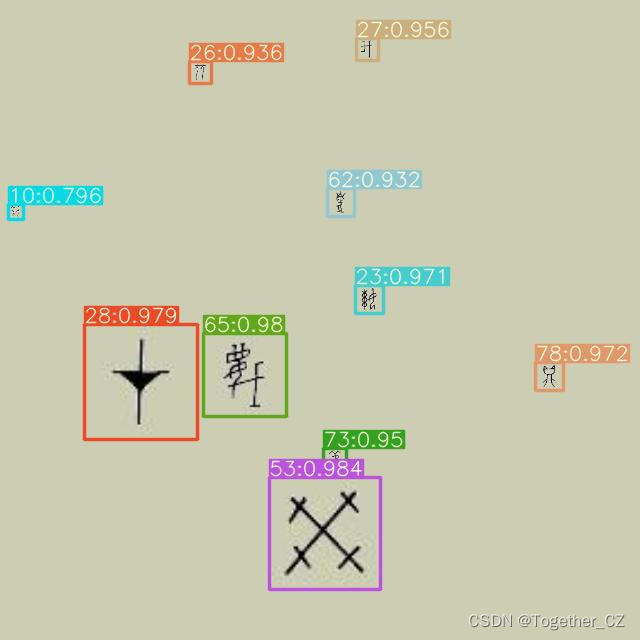
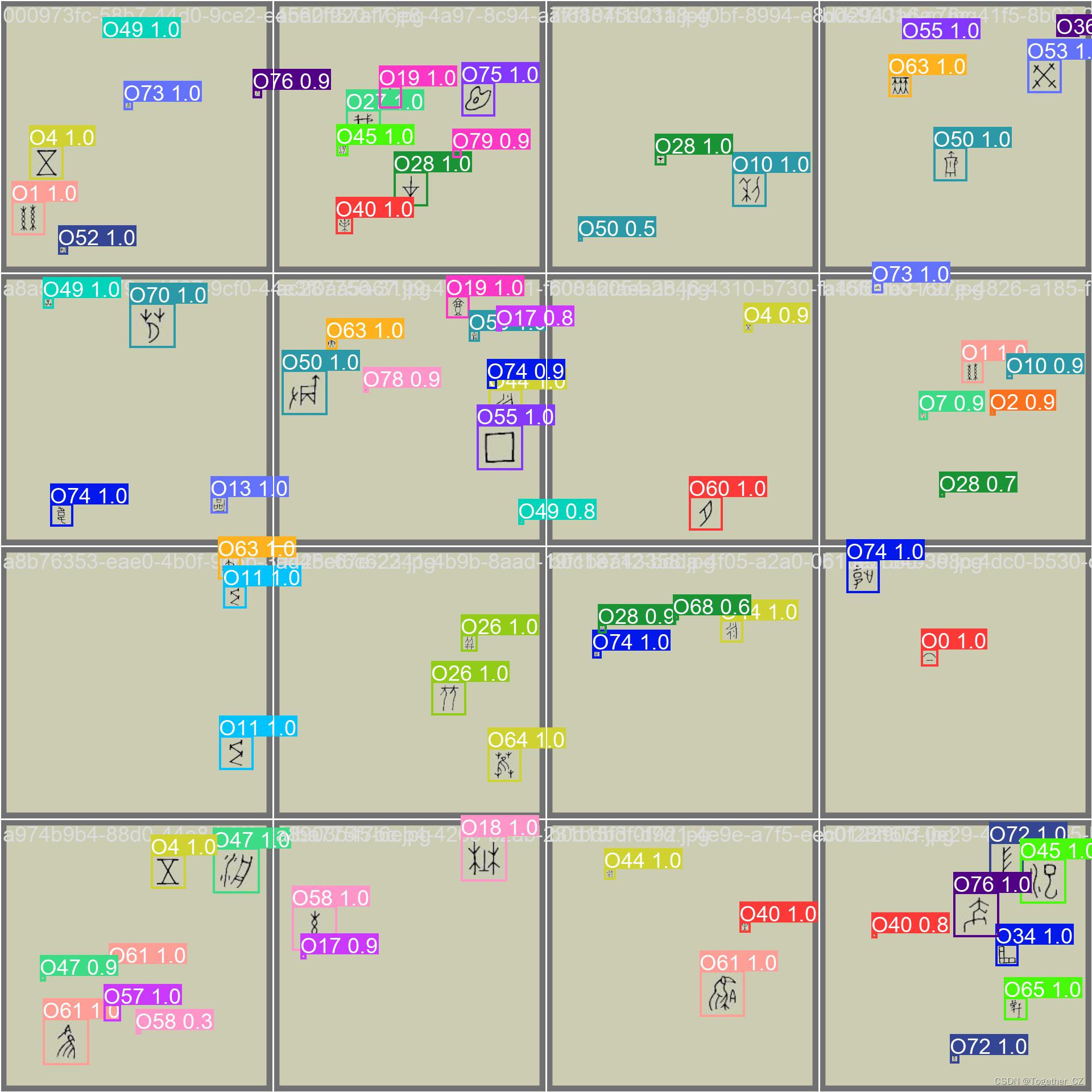
【Batch实例】

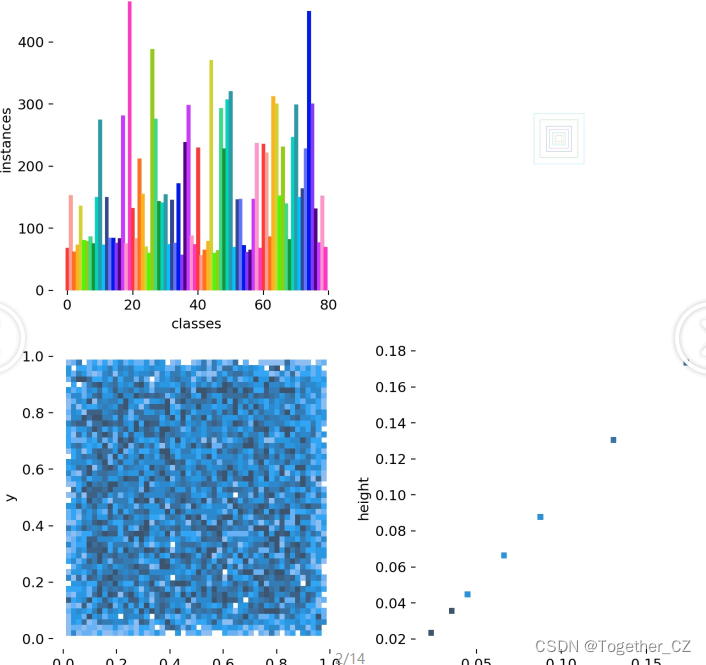
【类别数据分布可视化】
【F1值曲线】
【Precision曲线】
【Recall曲线】
感兴趣的话也可以对照尝试下!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











