






这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
多标签学习是监督学习的重要组成部分,旨在为给定的数据点预测一组相关标签。在大数据时代,复杂数据集的不断生成使得多标签学习任务(如多标签分类(MLC)和多标签排序)面临显著挑战,引起了各领域的广泛关注。这些挑战包括高维特征和标签、标签依赖性以及部分或缺失标签的存在,使得传统方法失效。近年来,深度学习(DL)技术在解决MLC中的这些挑战方面得到了显著的应用。特别是,利用DL的强大学习能力来改进标签依赖性及其他内在复杂性的建模的努力日益增多。然而,专门针对DL在多标签学习中的综合研究仍然稀缺。因此,本综述旨在细致回顾DL在多标签学习中的最新进展,同时提供MLC中开放研究问题的简要概述。综述整合了现有关于DL在MLC中的研究成果,如深度神经网络、变换器、自编码器以及卷积和递归架构。最后,研究提供了现有方法的比较分析,以提供有见地的观察并激发该领域未来的研究方向。
关键词:多标签学习,深度学习,多标签分类,MLC的深度学习,MLC的变换器,自编码器,多标签挑战,多标签数据集。
引言
在许多现实应用中,一个对象可能同时与多个标签相关联,这类问题被称为多标签学习(MLL)[1]。MLL扩展了传统的单标签学习方法,其中通常有一组有限的潜在标签可以应用于多标签数据(MLD)的实例。基本目标是同时为给定的单一输入预测一组输出,这意味着可以解决更复杂的决策问题。这与每个实例仅分配一个标签的标准单标签分类相反。
在多标签任务的背景下,一个实例通常与一组标签相关联,这些标签构成不同的组合,称为相关标签(活动标签),而未与实例关联的标签称为无关标签。MLD中标签的数量决定了表示相关和无关标签的二进制向量的大小。根据目标,MLL中有两个主要任务:多标签分类(MLC)和多标签排序(MLR)[2]。MLC是主要的学习任务,旨在训练一个模型,将标签集划分为相对于查询实例的相关和无关类别。另一方面,MLR专注于训练一个模型,根据标签与查询实例的相关性对其进行排序。
尽管MLC应用传统上集中在文本分析、多媒体和生物学领域,但它们的重要性正在逐渐扩展到文档分类[3][4][5]、医疗保健[6][7][8]、环境建模[9][10]、情感识别[11][12]、商业[13][14]、社交媒体[15][16][17]等领域。许多其他具有挑战性的任务,如视频注释、语言建模和网页分类,也可以通过将其构建为涉及数百或数千个标签的MLC任务而受益。这种广泛的标签空间带来了研究挑战,包括数据稀疏性和可扩展性问题。MLC还存在额外的复杂性,包括建模标签相关性[18][19]、标签不平衡[20]和噪声标签[21]。传统的MLC方法,如算法适应和问题转换[22][23],在解决这些挑战方面表现不佳。
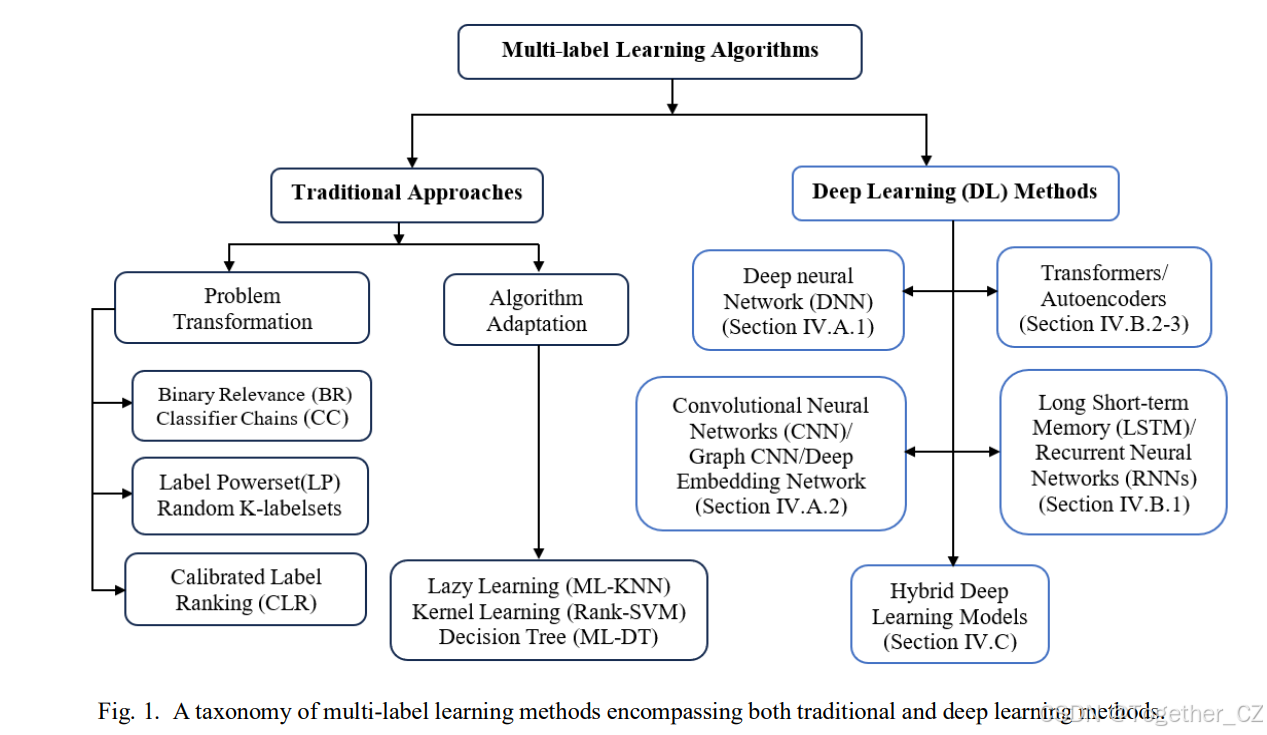
除了传统方法外,深度学习(DL)技术在解决MLC的挑战方面越来越受欢迎。深度学习的强大学习能力特别适用于解决MLC挑战,正如其在解决单标签分类任务中的显著成功所示。目前,MLC中一个主要趋势是广泛采用DL技术,甚至用于更具挑战性的问题,如极端MLC[24][25][26]、不平衡MLC[27][28]、弱监督MLC[29][30][31]以及带有缺失标签的MLC[32][33]。有效利用DL的强大学习能力对于更好地理解和建模标签相关性至关重要,从而使DL能够有效解决MLC问题。多项研究表明,专门设计用于捕捉标签依赖性的MLC方法通常表现出更好的预测性能[34][19]。本文对现有文献进行了简要回顾,以识别用于MLC问题的广泛DL技术,以激发对MLC的创新DL方法的进一步探索。已有关于MLC传统方法的综述,如[35][23][36]。此外,还有一些综述包含传统和DL方法[37][38],但这些综述对MLC的最先进DL方法的覆盖有限,并且集中在特定领域。然而,本文独特地集中于一系列DL架构,包括递归和卷积网络、变换器、自编码器和混合模型,以解决跨不同领域的MLC挑战。图1展示了包括传统方法和DL方法在内的MLL方法的分类。
本文的主要贡献如下:
-
本综述全面涵盖了用于解决MLC任务的DL方法,涉及不同领域和数据模式,包括文本、音乐、图像和视频。
-
提供了多个公开可用数据集上最新的DL方法的全面总结(表I、II和III),简要概述了每种DL方法并进行了深入讨论。因此,读者可以更好地识别每种方法的局限性,从而促进开发更先进的DL方法用于MLC。
-
我们简要描述了当前MLC领域面临的挑战。此外,我们还总结了MLC中使用的多标签数据集,并定义了用于评估这些数据集特征的属性。
-
最后,本文提供了现有方法的比较研究,涉及各种DL技术,并考察了每种方法的优缺点(表V)。它提供了有助于选择合适技术和开发未来研究中更好的DL方法的见解。
本文的后续部分组织如下。第二部分介绍了多标签学习的基本概念。第三部分介绍了研究方法,重点是数据来源和搜索策略、选择标准以及出版物的统计趋势。第四部分是本综述的重点,探讨了用于解决MLC挑战的一系列DL方法。第五部分关注MLC中的开放挑战和数据集。第六部分提供了各种方法的比较,概述了它们各自的优点和局限性。最后,第七部分提供了本文的结论。
多标签学习的基本概念

MLC目前受到广泛关注,并适用于包括生物信息学[40][41]、文本分类[42][43]、音乐分类[44][45]、医学诊断[46][47]、图像分类[48]和视频注释[49]在内的多个研究领域。例如,在医学诊断中,患者可能同时经历与疾病相关的多种副作用,或者医学诊断可能发现患者同时患有多种疾病。现实世界中的图像可以被分配多个标签,因为其语义信息丰富,涵盖对象、场景、动作、属性和它们的交互。有效建模这种多样化的语义信息及其相互依赖性对于全面理解图像至关重要。在文本分类中,新闻文章可能包含事件的多个方面,导致其在多个主题下被分类。在这种情况下,目标是为每个新实例分配一个标签集[50]。在MLR中,目标不仅是从一组预定义标签中预测一组输出,还要根据其与提供输入的相关性对其进行排序。在多标签学习场景中,任务不仅限于预测相关和无关标签;它通常涉及为每个未见示例生成相关标签的有序排序(即偏好列表)。MLR是一个有趣的问题,因为它包含了多标签、多类和层次分类等多种监督学习任务[51]。文档分类是MLR的一个突出用例,涉及对新闻文章等文档集合中的主题(如技术、政治和体育)进行分类。一个文档可能与多个主题相关联,学习算法的目标是为给定的文档查询将相关主题排在非相关主题之前。
解决MLL任务的两种传统方法是算法适应和问题转换。算法适应旨在修改或扩展传统学习方法,以直接处理多标签数据[53]。另一方面,问题转换涉及将MLC任务转换为一个或多个单标签分类任务[52],或标签排序任务[2]。问题转换类别中最突出的三种方法包括标签幂集(LP)[54]、二元相关性(BR)[1]和分类器链(CC)[55]。BR方法将多标签问题分解为一系列独立的二元问题。随后,每个二元问题使用传统分类器解决。最后,将各个预测结果组合起来,得到每个测试实例的相关标签子集。尽管BR实现相对简单,但人们意识到BR忽略了标签之间可能的关系(如标签依赖性、共现性和相关性)。为了解决BR方法的局限性,引入了分类器链(CC)[55]。该方法将二元分类器按顺序连接,前一个分类器的预测作为后一个分类器的特征。这使得后一个分类器能够利用与先前预测的相关性来提高其预测质量。LP方法涉及将每个不同的标签组合视为一个类标识符,从而将原始多标签数据集转换为多类数据集。使用该数据集训练传统分类器后,预测的类将被转换回相应的标签子集。LP和CC都是传统的学习标签间依赖性的方法。然而,在处理大量标签时,CC和LP的计算成本较高,且难以捕捉标签之间的高阶相关性。
无论采用何种方法解决多标签问题以及标签相关性的方法,MLC还存在额外的复杂性,如处理标签之间的高阶依赖性、处理大量标签所需的计算资源以及处理部分或弱监督MLC以及不平衡MLC[20]。此外,前面提到的经典方法在解决这些挑战方面效果不佳。近年来,深度学习(DL)技术在各个领域越来越受欢迎,MLC也不例外,受益于DL的最新发展。因此,本综述的目标是全面回顾DL方法用于MLC,旨在解决这些挑战并促进DL在各个领域的应用。
研究方法
本节揭示了搜索策略、研究选择标准和出版物趋势,以确保对文学来源进行全面和客观的选择。
搜索策略
在这项全面综述中,我们对2006年至2023年间关于DL方法用于MLC的研究论文进行了探索。最初,我们使用了涵盖各个研究领域的著名图书馆数据库作为主要来源:Springer、IEEExplore、DBLP、ACM数字图书馆、Science Direct和Google Scholar等。我们使用布尔运算符来细化搜索,将具有同义词的术语合并,并限制查询范围。预定的搜索术语包括短语,如“深度学习用于多标签分类”、“使用深度卷积神经网络(CNN)进行多标签分类”、“使用递归神经网络(RNN)、变换器、自编码器进行多标签预测”或“用于多标签分类的混合深度学习”。此外,我们还努力从其他来源(包括同行评审的期刊和会议)识别相关文章。
选择标准
本文主要关注研究DL技术用于解决MLC。我们建立了一套资格标准,所有这些标准都需要同时满足,以选择相关出版物:(1) MLL的出版物应包含多标签数据和深度学习;(2) 它要么使用DL方法解决MLC,要么提出DL方法;(3) 实验结果使用多标签场景的度量评估DL方法;(4) 全文文章应以英文撰写。提出DL方法用于解决MLC的出版物被包括在内,不受出版日期的限制。在搜索过程中,我们最初收集并识别了382篇出版物。其中,我们识别出64篇重复文献,并在筛选标题和摘要后排除了106篇。随后,我们对每篇论文的全文进行了仔细检查,最终确定了212篇相关论文纳入本研究。此外,任何具有重复标题、摘要或内容的出版物都被仔细删除,确保最终选择中只保留每篇出版物的一个副本。
出版物趋势
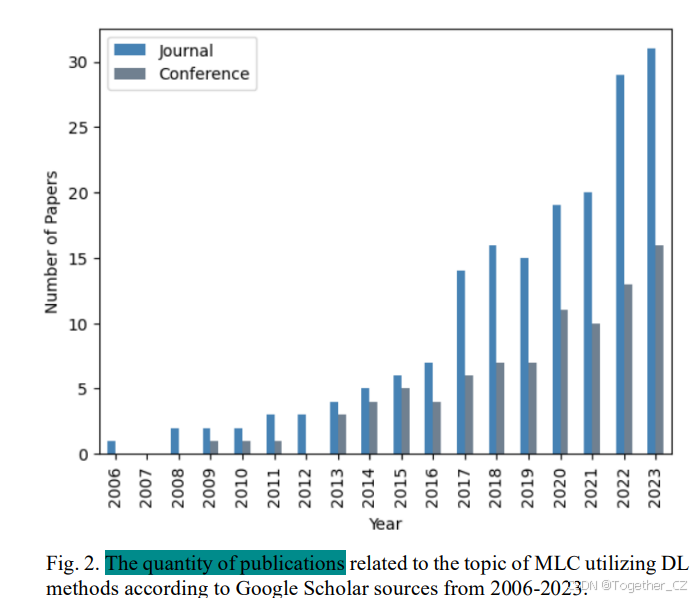
大约15年前,MLC领域开始吸引研究人员,标志着这一动态领域作为一个引人注目的研究主题的出现。图2显示了与DL用于MLC相关的出版物数量从2006年到2023年的增长趋势。值得注意的是,从2012年到2023年,出版物数量持续增加。2019年,出版物数量相比2018年略有下降;然而,随后的年份显示出上升轨迹。特别是近年来,采用DL技术进行MLC的出版物数量显著超过了以往年份。这一观察结果强调了继续探索创新DL技术以解决MLC任务的重要性,这是一个值得注意且活跃的研究领域,吸引了研究界的广泛关注和兴趣。
深度学习用于多标签分类
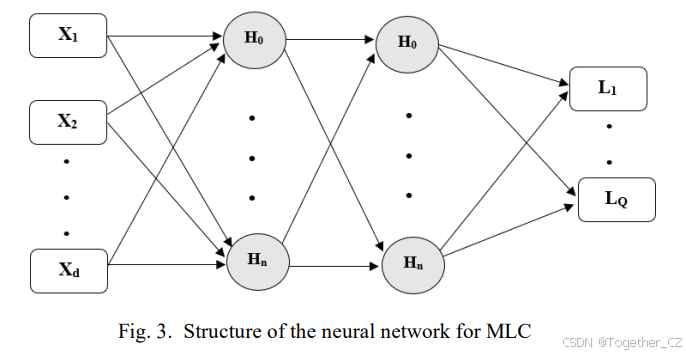
近年来,DL的进展显著丰富了MLC的领域。DL架构在生成输入特征和输出空间的嵌入表示方面发挥着关键作用。DL的强大学习能力在MLC任务中得到了广泛应用,涉及图像、文本、音乐和视频等多个领域。用于MLC的最常用的DL方法包括深度神经网络、卷积、递归、自编码器和变换器架构以及混合模型。有效利用这些DL方法的优势对于解决MLC中的标签依赖性及其他挑战至关重要。本节概述了这些用于MLC的突出DL方法,并详细考察了每种技术专门用于MLC的概况。
神经网络用于MLC
本节深入探讨了深度神经网络(DNN)和卷积神经网络(CNN)用于MLC的情况,并总结了最新的DL方法、应用和MLC中的数据集。

1) 深度神经网络用于MLC




BP-MLL开创了使用神经网络架构解决MLC的先河,利用其能力来整合标签相关性。这种方法有望在考虑标签依赖性至关重要的多标签场景中优于传统神经网络。然而,发现BM-LL随着标签数量的增加需要更多的计算复杂性和收敛速度。因此,后来通过最先进的学习技术对其进行了扩展。作者在[57]中提出了一种改进的BP-MLL方法,通过修改全局误差函数。该修改后的误差函数允许在神经网络学习期间自动确定阈值,而不是在BP-MLL中使用额外的步骤来定义阈值函数。此外,[58]发现BP-MLL在文本数据集上的性能不佳。为了应对这一限制,[58]通过用更常用的交叉熵误差函数替换排序损失最小化来探索BP-MLL的约束。作者展示了通过利用DL中的可用技术(如ReLUs、AdaGrad和Dropout),单隐藏层神经网络在广泛的多标签文本分类任务中达到最先进的性能水平。
在另一项研究中,[59]将标签决策模块集成到DNN中,从而在多标签图像分类任务中获得了顶级准确性。在此框架的基础上,Du等人[60]引入了ML-Net,一种用于生物医学文本的DNN,用于MLC。ML-Net整合了[59]中的标签决策模块,但将框架从图像处理转换为文本分类。ML-Net模型在同一网络中整合了标签预测和决策,通过标签置信度得分和文档上下文的组合来确定输出标签。其目标是减少标签之间的成对排序误差,从而实现端到端的标签集训练和预测,而无需额外的步骤来确定输出标签。
最近,[61]提出了一种新的MLC损失函数,称为ZLPR损失,以扩展DL在MLC中的应用。作者从单标签分类的交叉熵损失(公式4)扩展了该损失。

备注:DNN已成为用于MLC的最广泛使用的DL方法之一。为了支持DNN在MLC任务中的应用,已经开发了各种损失函数来确定任务范围。BP-MLL损失被确定为早期研究之一,是用于MLC的第一个DNN,随后由各种研究人员进行了改进。DNN在MLC中的应用已在各个领域得到应用。例如,在医疗保健领域,它已被用于智能健康风险预测[62]、蛋白质功能预测[63]、电子病历编码[64]和多标签慢性病预测[65]等任务。其他使用DNN进行MLC的相关任务包括SLA违规预测[66]、用于肽生物活性的层次DNN[67]和用于多标签图像分类的鲁棒DNN[68]。
2) 深度CNN用于MLC
深度CNN在单标签图像学习问题中显示出令人鼓舞的结果。然而,多标签图像分类代表了更广泛和更实际的挑战,因为大多数现实世界的图像包含属于多个不同类别的对象。深度CNN模型在单标签图像分类中的成功可以扩展并应用于解决多标签挑战。多标签任务通过从架构角度改进DL模型,特别是损失层来解决。为了建立多标签损失,研究主要致力于改进二元交叉熵(BCE)。一项研究[69]探讨了在训练CNN时使用的各种多标签损失,包括SoftMax、成对排序和加权近似排序损失(WARP)。结果表明,WARP损失(公式5)在解决多标签注释挑战方面表现良好。

2014年,Yoon Kim[72]引入了一种基于CNN架构的文本分类模型,随后使用另一个CNN进行句子级分类。然而,该模型的局限性在于无法克服CNN中固定窗口的缺点,从而阻碍了其有效建模长序列信息的能力。后来,[73]提出了一种XML-CNN模型,该模型通过引入动态池化改进了TextCNN模型[72],改进了损失函数为二元交叉熵,并在输出层和池化层之间引入了一个隐藏层。这个额外的层旨在将高维标签转换为低维空间,从而减轻计算负担。
在[74]中,作者介绍了CNN假设池化(HCP)作为一种创新方法。它涉及使用一组对象段假设作为输入。然后,每个假设被纳入CNN模型,不同假设的结果通过最大池化组合以生成多标签预测。图4显示了HCP的架构。Weiwei等人[75]提出了一种用于多标签图像的深度CNN,引入了一种新的目标函数,包括最大边际目标、最大相关性目标和交叉熵损失。他们提出的框架旨在优化标签之间相关信息的利用。这是通过优化图像中存在的标签相对于不存在的标签的得分,使用预定义的边际来实现的。在语义空间中的学习增强了提取特征与其相应标签之间的相关性。Zhu等人[76]引入了一种空间正则化网络(SRN),利用注意力图来捕捉图像数据集中不同标签之间的语义和空间联系。SRN为每个标签生成注意力图,并通过可训练的卷积捕捉内在关系。在另一种方法中,Kurata等人[77]提出了一种在多标签文本分类的背景下初始化神经网络以利用标签共现信息的方法。该方法应用基于CNN的词嵌入来捕捉标签相关性。
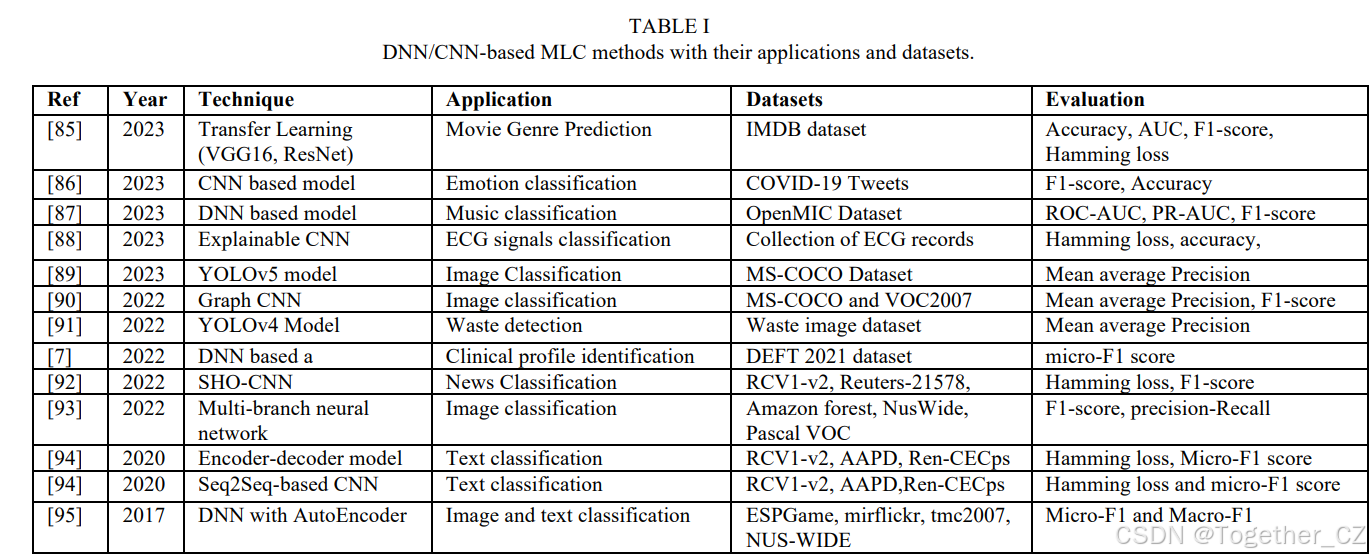
在[78]中,提出了一种用于多标签图像分类的深度CNN集成,结合了著名的架构,如VGG16[79]和Resnet-101[80]。该研究探讨了不同图像维度对结果的影响,并使用了一系列数据增强方法和交叉熵损失来训练和评估模型。最近,Park等人[81]介绍了MarsNet,一种基于CNN的架构,适用于输入大小不同的MLC。为了处理不同尺寸的图像,作者调整了膨胀残差网络(DRN)以生成更高分辨率的特征图。此外,他们引入了水平-垂直池化(HVP),以巧妙地融合这些特征图中的位置细节。该方法进一步集成了一个多标签评分模块和一个用于MLC的阈值估计模块,并通过一系列多样化的实验验证了其有效性。表I总结了最新的基于CNN/DNN的方法用于MLC。
MLC也可以通过联合标签嵌入来执行。一个例子是多视图典型相关分析[82],这是一种三向典型分析,将图像、标签和语义对齐在一个共享的潜在空间中。WASABI[83]和DEVISE[84]等技术采用带有WARP损失的学习排序框架来开发联合嵌入。度量学习[96]专注于获取判别度量,以衡量图像和标签之间的相似性。此外,标签编码可以通过矩阵补全[97]和布隆过滤器[98]等方法实现。虽然这些策略有效地利用了标签的语义冗余,但它们通常无法有效捕捉标签共现的依赖性。认识到这一限制,图卷积网络(GCN)[99]已被发现有效建模MLC问题中的标签相关性。基于图的深度网络,如图卷积神经网络(GCN),提供了一种有效的标签依赖性建模方法。在这种框架中,每个标签被表示为图中的一个节点。Chen等人[100]提出了一种用于对象标签的有向图,使用图卷积网络(GCN)来发现标签之间的相关性。该方法将标签表示转换为相互依赖的对象分类器,从而增强了对标签之间关系的整体理解。同样,基于语义的图学习[101]通过交互模块和语义解耦来关联基于语义的特征。这些关联是通过从标签相关数据构建的GCN建立的。在相关研究中,后续工作[102]通过在不同深度的GCN和CNN层之间引入横向连接来增强标签意识。这种集成确保了标签信息更好地注入到主干CNN中。在[103]中,提出了一种深度学习模型,通过将其构建为文本MLC问题来解决多标签专利数据挑战。他们的方法涉及利用GCN来捕捉复杂细节。该模型集成了一个动态二阶注意力层,旨在捕捉文本内容中的广泛语义关系。
基于图的技术,如条件随机场[104]、依赖网络[105]和共现矩阵[106],提供了处理标签依赖性和共现的解决方案。此外,标签模型[107]通过结合常见的标签组合来增强标签集。然而,这些方法通常专注于捕捉成对标签相关性,并且在处理大量标签时可能变得计算密集,特别是当涉及更复杂的标签关联时[107]。相比之下,具有低维递归神经元的RNN模型提供了一种更高效的捕捉高阶标签相关性的方法。最近的相关研究包括用于多标签图像分类的深度CNN[93]、基于CNN的跨模态哈希方法[108]、通过CNN改进的序列生成模型[94]、用于多标签ECG记录的一维CNN(1D CNN)残差和注意力机制、使用标签间相关性的图形CNN[90]。
备注:几种方法提出了基于CNN的技术用于MLC,涉及不同的数据模式。然而,深度CNN特别以其有效性在多标签图像分类中闻名,并通过两种主要策略应用。第一种方法是为图像中的每个标签单独训练CNN,将多标签问题视为一系列单标签任务[74][109][110]。这种方法通常使用多个局部边界框和学习技术实例,从而提高了性能。然而,它往往忽略了标签之间可能的关系,并且在处理仅部分信息的图像时难以准确分配描述整个图像的标签。
第二种策略采用整体方法,从原始图像中提取全局特征,并使用考虑多个标签的全局损失函数[111]。这种方法将整个图像整合到分类任务中,增强了模型分配描述整体内容的标签的能力。例如,[69]提出了一种使用多标签损失函数的深度CNN模型用于top-k排序。这种二阶策略可能计算标签相关性,包括相关和无关标签之间的排序,从而实现良好的泛化。尽管二阶策略在一定程度上利用了标签相关性,但在现实场景中,标签关联可能超越二阶关系。这可以通过高阶策略解决,其中MLL考虑标签之间的关联,超越成对相关性。这涉及解决随机子集的标签之间的连接,以捕捉更复杂的关系[55]。
LSTM和变换器用于MLC
递归神经网络(RNN)扩展了常规的前馈神经网络,使其能够处理可变长度的序列数据并进行时间序列预测。RNN可以被视为隐马尔可夫模型的扩展,集成了非线性转移函数,并能够建模长期的时间依赖性。LSTM是RNN的一种变体,通过设计解决了梯度消失问题。它在机器翻译、语音识别和各种其他任务中显著提升了领域。LSTM已被证明对传统上非顺序的任务(如MLC)[12][13]也很有价值。
1) 基于LSTM的MLC
据我们所知,Nam等人[14]的工作标志着RNN首次用于替换分类器链,用于序列到序列(seq2seq)文本分类,从而有效捕捉MLC中的标签相关性。此后,出现了各种模型来解决MLC,如注意力RNN[115]、无序RNN[113]和LSTM[116]。
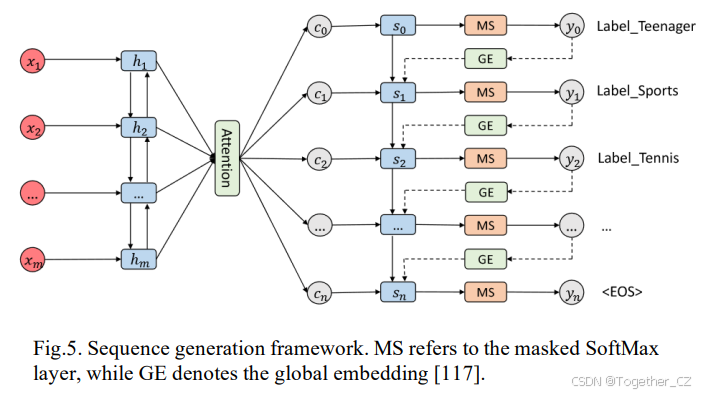

解码器使用LSTM按顺序生成标签,利用先前预测的标签来预测下一个标签。这种机制允许模型通过在LSTM框架内导航标签序列依赖性来理解标签关系。通过在序列生成模型中采用解码器结构,它不仅能够辨别标签之间的相关性,还能在预测不同标签时自主选择最相关的单词。
Yang等人[118]介绍了RethinkNet,一种旨在克服CC方法限制的DL模型。它通过使用全局记忆来保留标签关系信息来解决标签排序问题。这种全局记忆使所有学习模型能够访问相同的信息,从而缓解了标签排序问题。在另一项研究中,研究人员[119]提出了一种用于高维时间序列数据中多标签故障预测的深度RNN。他们的模型包含一个专门用于处理类别不平衡的损失函数。它由两个相互连接的LSTM网络组成,即编码器和解码器,分别用于捕捉时间序列数据的历史或未来部分的动态。最近,Loris Nanni等人[120]提出了一种集成方法,结合LSTM、GRU和时间CNN(TCN)用于MLC任务。他们提出的模型使用各种Adam优化的改编进行训练,并结合了多聚类中心(IMCC)的概念,以增强多标签分类系统的有效性。该模型采用二元交叉熵损失函数,由公式(7)表示:

在[122]中,作者将LSTM和贝叶斯决策理论应用于多标签lncRNA功能预测。他们使用LSTM捕捉层次关系,并使用贝叶斯方法将层次多标签分类问题转化为条件风险最小化问题,以获得最终预测结果。Sagar等人[123]提出了一种基于LSTM自编码器的多标签分类方法,用于非侵入性电器负载监测。他们提出的方法从智能电表获取电力消耗作为输入,并使用编码器-解码器范式重建输入的时间翻转版本。在多标签情感分类的背景下,一项提议[124]提出了潜在情感记忆(LEM),以在不依赖外部知识的情况下获取潜在情感分布。LEM由潜在情感和记忆模块组成,分别用于捕捉情感分布和情感特征。这两个组件的组合随后输入双向门控递归单元(BiGRU)进行预测。
其他基于RNN的研究包括极端MLC[125],使用堆叠的BiGRU进行文本嵌入,并结合对集群敏感的注意力机制,以利用大标签空间中的相关性。Li等人[115]提出了一种用于弱监督MLC的端到端RNN,而[122]设计了基于LSTM和贝叶斯决策理论的层次MLC,用于lncRNA功能预测。
2) 基于自编码器的MLC
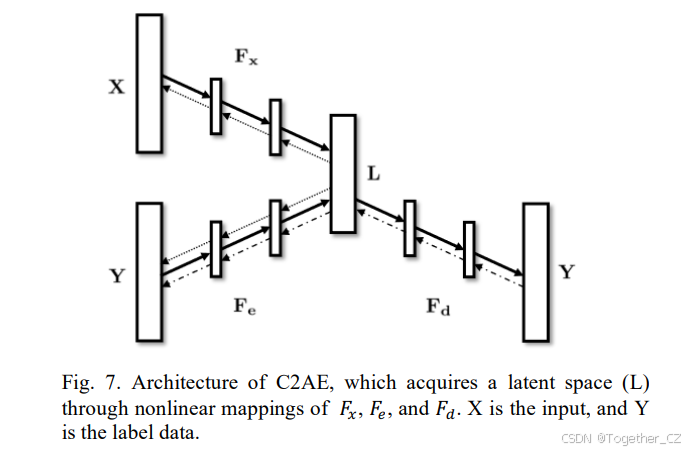
自编码器是一种无监督的特征表示学习技术[126],旨在通过协调编码器和解码器层来近似输入表示。这些技术在MLC任务中得到了广泛应用。值得注意的是,典型相关自编码器(C2AE)[95]是第一个用于MLC的基于DL的标签嵌入方法。其结构如图7所示。C2AE的基本概念涉及探索一个深刻的潜在空间,以同时整合实例及其相关标签。C2AE通过参与特征感知标签编码和利用标签相关性进行准确预测来实现这一点。这涉及两种方法:首先,在自编码器的编码阶段结合深度典型相关分析(DCCA)进行特征感知的标签编码;其次,引入一个定制的损失函数,以增强从解码输出中进行标签相关性感知的预测。C2AE由两个关键组件组成:DCCA和自编码器,两者都旨在揭示三个关键映射函数:编码Fe、解码Fd和映射函数Fx。在训练阶段,C2AE接受输入实例及其相应的目标标签。C2AE的目标定义如公式9所示。

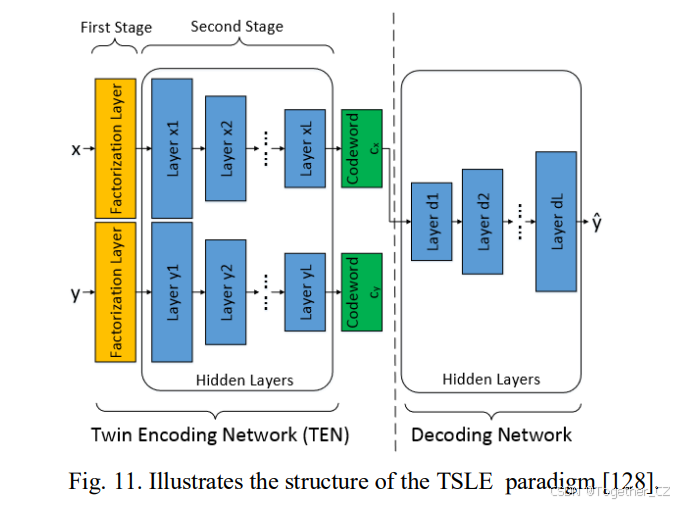
后来,Bai等人[127]发现C2AE中学习的确定性潜在空间缺乏平滑性和结构。在这个潜在空间中的微小扰动可能导致截然不同的解码结果。尽管相应的特征和标签代码接近,但不能保证解码的目标会表现出相似性。为了解决这个问题,[127]提出了一种创新框架,多元概率变分自编码器(MPVAE),旨在高效获取潜在嵌入空间并捕捉MLC中的标签相关性。MPVAE巧妙地学习和对齐两个概率嵌入空间——一个用于标签,另一个用于特征。MPVAE框架中的解码器处理这些嵌入空间的样本,有效地使用多元概率模型建模输出目标的联合分布,这是通过学习共享协方差矩阵实现的。类似的概念出现在[128]中,提出了通过神经分解机的双阶段标签嵌入(TSLE)用于MLC,如图11所示。在这个框架中,编码器是一个双编码网络(TEN),由一个单一特征网络和一个单一标签网络组成。解码器的目的是基于特征嵌入重建标签。特征网络和标签网络都使用一个分解层,以计算特征和标签之间的成对相关性。
最近,Bai等人[129]提出了他们之前MPVAE[127]模型的扩展,提出了对比学习增强的高斯混合变分自编码器(C-GMVAE)。他们模型中使用的损失函数是几个组件的组合,包括特征和标签嵌入的KL损失、VAE重建损失、特征和标签嵌入的监督对比损失,以及最终的分类交叉熵损失。在[130]中,作者提出了一种具有双编码层的自编码器,旨在通过第二个编码权重矩阵交换知识。该自编码器模型旨在联合优化表示学习和多标签学习,以增强MLC性能。然而,现有的基于自编码器的方法通常依赖于单一自编码器模型,在多标签特征表示的学习中存在挑战,并且缺乏评估数据空间之间相似性的能力。
为了解决[130]中单模型限制的问题,Zhu等人[131]提出了一种新的方法,称为RLDA(具有双自编码器的表示学习方法)。该方法通过顺序集成两种不同类型的自编码器,有效地捕捉数据的多样特征和抽象特征。首先,算法在稀疏自编码器框架内使用重建独立成分分析(RICA),对训练和测试数据集的补丁进行训练,以稳健地学习全局特征。随后,使用RICA的输出,然后采用具有流形正则化的堆叠自编码器来细化多标签特征表示的质量。最终,这两种自编码器类型的顺序组合生成用于多标签分类的创新特征表示。
3) 基于变换器的MLC
最初引入用于捕捉序列学习挑战中的长期依赖性的变换器[132],在各种自然语言处理任务中得到了广泛应用。最近,基于变换器的模型在视觉相关任务中也展示了显著的前景。变换器在解决MLC中的应用源于需要动态提取针对不同标签的局部判别特征。这种自适应特征提取是一个高度理想的属性,特别是在单个图像中涉及多个对象的场景中。
Ramil和Pavel[133]首次将BERT模型应用于多标签问题,并研究了其在层次文本分类挑战中的有效性。他们引入了一种基于BERT的模型,旨在生成用于多标签文本分类的序列。Gong等人[134]后来引入了一种HG-transformer,这是一种深度学习架构,首先将输入文本转换为图结构。该模型然后使用具有多注意力机制的多层变换器在词、句子和图级别全面捕捉文本特征。利用层次标签关系,该模型生成标签表示,并结合一个针对语义标签距离定制的加权损失函数。尽管基于变换器的MLC模型的有效性超过了CNN和RNN结构,但值得注意的是,变换器模型通常涉及大量参数和复杂的网络结构,导致实际应用中的局限性。在追求增强变换器在MLC中的适用性时,[135]提出了一种混合模型,名为tALBERT,它结合了LDA和ALBERT以获得多样化的多层次文档表示。使用三个数据集进行的广泛实验证明了他们的混合方法在多标签文本分类领域优于当前最先进方法的更高性能。
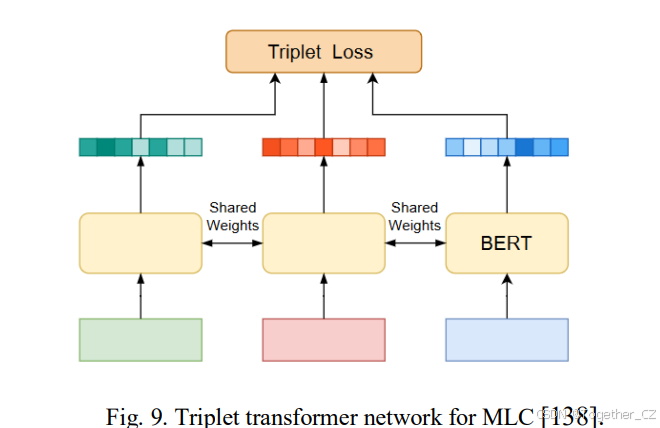
在研究[136]中,框架Query2Label提出了一种新颖的MLC方法,采用变换器解码器。据我们所知,这是首次应用此类框架来解决MLC挑战。Query2Label在两个阶段运行,利用变换器解码器提取特征。在此过程中使用的多头注意力专注于对象类别的不同方面或视角。此外,该框架自主地从提供的数据中学习标签嵌入。为了更好地处理不平衡问题,框架采用了一种简化的非对称焦点损失来计算每个训练样本的损失,如公式(12)所示。

Ridnik等人[137]提出了一种ML-Decoder模型,可以为多标签分类提供统一的解决方案。ML-Decoder可以通过排除任何预训练的全连接层无缝应用,在MS-COCO MLC任务的测试中展示了速度和准确性之间的持续改进平衡。[138]提出了一种用于多标签文档分类的三元组变换器架构,如图9所示。该模型擅长将标签和文档嵌入到一个统一的向量空间中。该架构由三个共享权重的BERT网络组成,通过定位最接近的标签来促进文档分类。最近,[139]提出了一种用于MLC问题的图注意力变换器网络(GATN)。该网络专门设计用于高效发现标签之间的复杂关系。GATN通过两步过程增强标签关系的表达能力。最初,使用标签词嵌入计算余弦相似度以创建初始相关矩阵,捕捉广泛的语义信息。随后,为适应当前领域,构建了一个图注意力变换器层以调整该邻接矩阵。他们采用节点嵌入来构建最终的相关矩阵,如公式(12)所示。生成相关矩阵的过程如下。对于具有n个类别的MLC,设Zi表示长度为dd的第ii个标签的嵌入向量,Ri,j表示第i个标签和第j个标签之间的相关值。Ri,j基于嵌入向量的余弦相似度计算(公式13)。

在不同的研究中,Chen等人[148]开发了一种基于空间和语义变换器(SST)的多标签图像识别。SST作为一个模块化的即插即用系统,能够同时提取多标签图像中的语义和空间相关性。它由两个独立的变换器组成,各有不同的目标:空间变换器用于捕捉标签的共存,而无需手动定义规则。最近,使用变换器架构在大数据集上预训练的大型语言模型已被建议用于多标签文本分类,如LP-MTC[42]、提示调优[149]和SciBERT[150]。表II总结了用于解决MLC挑战的最先进的变换器和LSTM。
备注:变换器和自编码器已成为近年来用于MLC的最成功DL方法之一。这些技术已在各种现实场景中得到应用,包括多标签情感分类[4]、用于水下船只检查的视频MLC[151]、文本数据MLC[135]和多标签疾病分类[152]。基于变换器结构的MLC模型通常优于基于RNN和LSTM的模型。然而,值得注意的是,变换器模型通常涉及大量参数和复杂的网络结构,在实际应用中引入了一定的局限性。此外,解决MLC中的标签相关性对于某些目标至关重要,由于数据中标签空间的固有结构,这带来了挑战。在未来的研究中,探索有效捕捉标签相关性及其他相关挑战的方法将是自编码器和变换器用于MLC的主要研究重点。
混合DL用于MLC问题
将CNN扩展到MLC的一种常见方法是将问题转换为多个单标签分类任务,使用排名损失[69]或交叉熵损失[153]。然而,这些方法在独立处理多个标签时未能捕捉它们之间的依赖性。多项研究表明,MLC问题中存在显著的标签共现依赖性。为了捕捉标签依赖性,现有研究采用了多种技术,包括基于最近邻的方法[154][155]、基于排名的方法[156][157]、结构化推理模型[158][159]和图形模型[106][160][107]。一种常见策略是通过成对兼容概率或共现概率表示依赖性和共现关系。随后,通常使用马尔可夫随机场[105]来推导最终的联合概率。然而,这些方法通常侧重于捕捉成对标签相关性,并且在处理大量标签时可能变得计算密集,特别是当涉及更复杂的标签关联时[107]。相比之下,具有低维递归神经元的RNN模型提供了一种更高效的捕捉高阶标签相关性的方法。
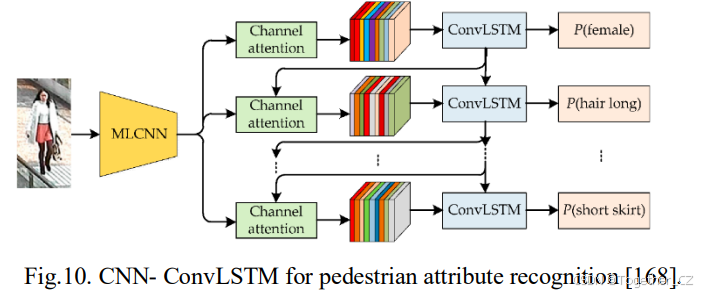
利用RNN模型解决标签依赖性的概念最初在[162]和[163]中提出,其中提出了CNN与RNN架构的融合。由于分类器链(CC)被视为一种存储早期分类器标签预测的记忆机制,基于CNN-RNN的算法可以通过用更复杂的基于记忆的模型替换该机制来扩展CC。Wang等人[162]提出了一种统一的CNN-RNN框架,学习联合图像-标签嵌入以表征语义标签依赖性。CNN-RNN结构包括一个CNN特征映射层(编码器),用于从图像中提取语义表示,以及一个RNN推理层(解码器),利用编码生成标签序列,建模图像/标签关系和依赖性。RNN采用频繁优先的排序方法进行顺序输出,并通过最近邻搜索在预测层生成多个标签输出。在[163]中,发现训练期间的标签顺序显著影响注释性能,稀有到频繁的顺序产生最有利的结果,这一发现得到了后续研究如[162][164]的证实。Jin等人[107]使用CNN表示图像,并将其输入RNN进行预测。他们尝试了稀有优先、字典顺序、频繁优先和随机标签排序,比较了每种方法的结果。Liu等人[164]采用类似的框架,其中他们明确将标签预测和标签相关性任务分配给CNN和RNN模型。研究人员将RNN与从CNN模型中提取的输出特征一起输入,从而在整个训练过程中监督两个模型。他们采用稀有优先的排序方法,以赋予稀有标签更大的重要性。作者探索了各种视觉表示以输入RNN。在[162]中,探索图像-文本关系涉及将图像和标签映射到一个共同的低维空间,而[164]使用预测的类概率,[163]在其实验中探索了CNN的各个内部层。其他基于CNN-RNN架构的研究包括用于文本分类的CNN-RNN集成[165]、用于亚马逊雨林卫星图像的CNN-RNN[166]、用于多标签航空图像分类的混合CNN和双向LSTM网络[167]以及用于行人属性识别的CNN-ConvLSTM[168],如图10所示。
尽管CNN-RNN架构展示了令人鼓舞的性能,但其依赖于预定义的标签顺序进行学习是一个显著挑战。由于基于RNN的模型产生顺序输出,因此在MLC任务的训练期间需要预定义标签顺序。例如,Wang等人[162]根据训练数据中观察到的标签频率确定标签顺序。然而,采用这种预定义的标签顺序可能无法准确捕捉自然的标签依赖性,引入了对RNN模型的刚性约束。采用频繁到稀有标签顺序会使模型偏向于频繁标签,需要在处理稀有标签之前进行大量准确预测。相反,稀有到频繁标签顺序迫使模型优先学习稀有标签,这在训练示例稀缺的情况下是一个具有挑战性的任务。总体而言,基于频率的预定义标签顺序通常忽略了真实的标签依赖性。这是因为多标签图像中的每个标签都与更广泛的上下文中的许多其他标签紧密相关,尽管一个标签可能仅与少数标签显示出更强的关联。此外,定义这种顺序引入了数据集特定的统计偏差,损害了模型的泛化能力。在[162]中验证的缺乏学习最优标签顺序的鲁棒性,由于视觉注意力信息利用不足,预测较小尺寸对象的标签时变得更加复杂。因此,如何在同时利用相关视觉信息的情况下引入学习最优标签顺序的灵活性成为一个重要的研究焦点。
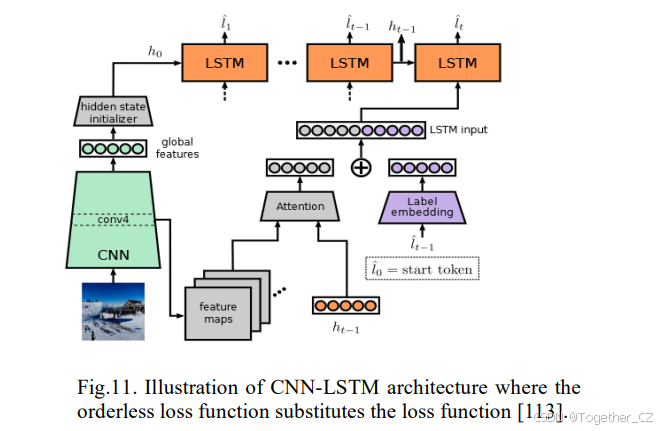
为了解决这些与标签顺序相关的约束,一些研究[112][113]提出了消除将地面真实标签按预定义顺序输入RNN的必要性的方法。Chen等人[112]引入了一种用于MLC的RNN,不依赖于顺序,结合了视觉注意力和LSTM模型。他们使用每个时间步的二元交叉熵损失来预测标签,而不考虑其顺序。同时学习注意力和LSTM模型使识别与每个标签相关的感兴趣区域成为可能,自动捕捉标签顺序而无需预定义约束。注意力和LSTM的集成略微提高了CNN-RNN模型的性能。[13]中提出的另一种方法是一种无序的递归模型,用于MLC,如图11所示。该方法探索了预测标签序列与地面真实标签动态顺序的交互,从而加速了LSTM模型的训练以实现更好的优化。值得注意的是,该方法避免了Chen等人[112]中明确的重复去除模块。随后的研究,包括[169]和[115],也采用了无序策略进行MLC。在[169]中,作者提出了一种端到端可训练的框架,用于多标签图像识别。该框架包括用于提取复杂特征表示的CNN,以及使用LSTM的注意力感知模块。该模块迭代识别与类别相关的区域,并预测这些识别区域的标签分数。框架的端到端训练仅依赖于图像级标签,通过强化学习技术实现。该过程首先将图像输入CNN,生成特征图。随后,LSTM模块处理这些特征,结合先前迭代的隐藏状态来预测每个区域的分数。这些分数在确定后续迭代的区域位置中起关键作用。为了获得最终的标签分布,预测的分数通过类别明智的最大池化进行整合。然而,这些方法倾向于在初始时间步内部选择特定的标签顺序,然后在后续时间步中继续遵循相同的顺序。本质上,这些策略使RNN隐含地偏好众多顺序中的一个,从而引入了固有的偏差。
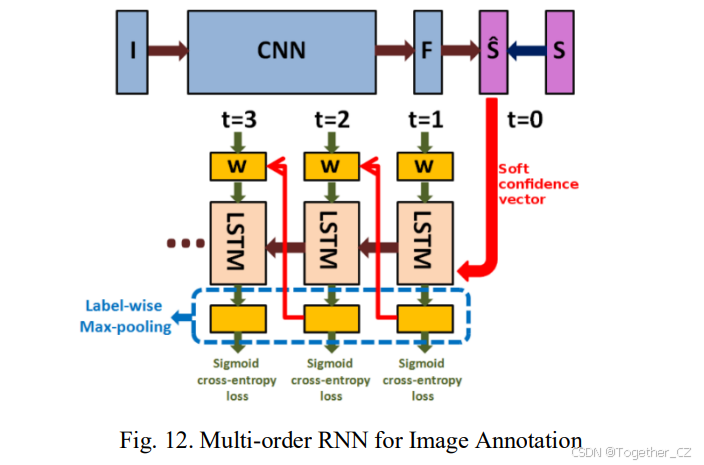
后来,Ayushi等人[175]提出了多顺序RNN,以解决这些无序方法的限制(图12)。他们的方法为RNN提供了探索和掌握通过多个标签顺序的各种相关标签依赖性的灵活性,而不是受限于预定义和固定的顺序。多顺序RNN的架构包括一个使用指定数据集的地面真实数据进行微调的深度CNN和一个利用从CNN获得的软置信向量作为起点的LSTM模型。在每个样本的每个时间步,计算交叉熵损失,考虑所有真实标签,除了前一时间步的标签作为潜在预测。最终预测通过在所有时间步对各个标签分数进行最大池化得出。多顺序RNN展示了优于CNN-RNN方法的性能,提供了一种直观的方法,通过探索多个标签顺序来适应序列预测框架进行图像注释任务。
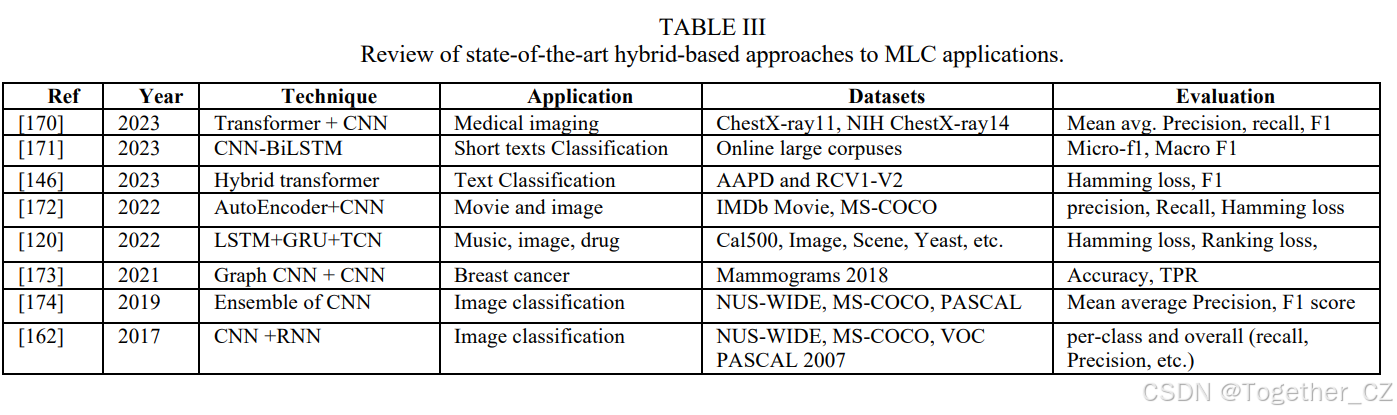
最近,Wang和他的同事们[176]提出了一种用于多标签图像分类的新方法。他们的方法结合了跨模态融合和注意力机制,利用图卷积网络和注意力机制无缝处理局部和全局标签相关性。该方法包括三个主要组件:一个配备注意力机制的特征提取模块,一个用于学习标签共现编码的模块,以及一个采用多模态因子化双线性池化的跨模态融合模块。通过有效融合图像特征和标签共现嵌入,他们的方法展示了有希望的结果。他们的方法在COCO和VOC2007数据集上进行了测试,并显示出比其他类似方法更好的分类结果。另一项研究[177]介绍了两种用于分类DNA序列的混合DL模型。第一种模型结合了堆叠卷积自编码器(SCAE)和多标签极限学习机(MLELM),而第二种模型将变分卷积自编码器(VCAE)纳入MLELM框架。这些模型巧妙地生成准确的特征图,捕捉DNA序列中的个体和标签间交互,封装空间和时间特征。提取的特征输入MLELM网络,产生软分类分数和硬标签。值得注意的是,VCAE-MLELM模型始终优于SCAE-MLELM模型,而后者在软分类方面表现出色,超过了现有的方法,如CNN-BiLSTM和DeepMicrobe[178]。卷积自编码器有助于提取空间组织,通过识别潜在关联提高计算效率。提取的特征输入两个MLELM,第一个模型生成概率标签,第二个模型建立确定性和概率标签之间的关联。表III总结了一些最先进的混合DL技术用于MLC,包括其应用领域、数据集和评估指标。
MLC的挑战和数据集
MLC的持续吸引力可归因于多标签数据在生物学、环境、医疗保健、商业、推荐系统、社交媒体、零售、情感分析、能源、交通和机器人等多个领域的广泛存在。此外,互联网每天持续生成数万亿字节的数据流,为MLC任务带来了显著挑战。在现实应用中,MLC由于标签存在的复杂性继续面临挑战。例如,在某些情况下,存在大量标签,这些标签仅部分或弱提供,并且它们的呈现可能是连续的或完全不可预测的。本节探讨了MLC中的一些挑战及其相关数据集。
-
*标签依赖性: 多个数据标签的存在可能表明不同实体之间的关联。例如,在识别图像中的对象时,狗和猫可能经常共存,而猫和鲨鱼通常不会共享同一空间。因此,建模和学习类别之间的相关性一直是MLC的基本焦点[190]。然而,有效利用标签依赖性继续是MLC中的一个持久挑战。关于这些依赖性的建模,学习方法可以分为一阶(独立处理每个不同标签)、二阶(建模标签对)和高阶(同时处理两个以上标签)。DL方法的强大学习能力通常用于以各种方式解决二阶标签依赖性,包括图CNN[90][191]、基于自编码器的方法[127][129]、变换器[3][192]和混合DL模型[170][171][162]。然而,高阶标签依赖性在MLC中的挑战仍然是研究人员的主要关注点,包括实际和理论考虑,持续至今。
-
*极端MLC: MLC中的另一个重要挑战是存在大量标签,也称为极端MLC。这是一个活跃的研究领域,其中标签数量可能异常高,在某些情况下达到数百万。直接应用传统的分类器,如一对一、SVM和神经网络,在极端MLC的背景下面临两个主要障碍[193]。首先,大量标签构成了主要瓶颈,因为为所有标签实施经典模型在计算上是不可行的。此外,标签数量有限样本的存在进一步复杂化了这些特定标签的学习过程。已经做出了一些努力,如Ranking-based Auto-Encoder(Rank-AE)[194]、DeepXML框架[195]、AttentionXML[24]和两阶段XMTC框架(XRR)[26],以解决极端MLC带来的挑战。
-
*弱监督MLC: 弱监督学习侧重于MLC中更具挑战性的方面,其中训练集中的某些标签缺失。鉴于此类任务涉及的大量数据量和多样领域,完全监督学习需要手动注释的数据集,成本高昂且耗时。涉及每个样本部分观察标签的弱监督MLC任务的重要性日益增加,因为它有可能显著节省注释成本[29]。在解决带有缺失或部分标签的MLC时,已经提出了几种值得注意的方法,包括图神经网络(GNN)[33]、深度生成模型[30]和层次MLC[196]。此外,学习范式,如零样本学习[197]、少样本学习[198]和自监督学习[199],是部分或弱监督MLC的新兴研究方向。
-
*不平衡MLC: 不平衡学习是多标签数据集中广泛认可和固有的特征,影响各种MLC算法的学习动态。MLD中的不平衡问题可以从多个因素进行分析[20]:标签内不平衡、标签间不平衡和标签集之间的不平衡。这些因素也可能同时出现,进一步加剧MLC任务的复杂性。尽管传统的独立方法通常用于解决不平衡MLD[200],但DL模型适应方法仍处于发展阶段[201][202]。
-
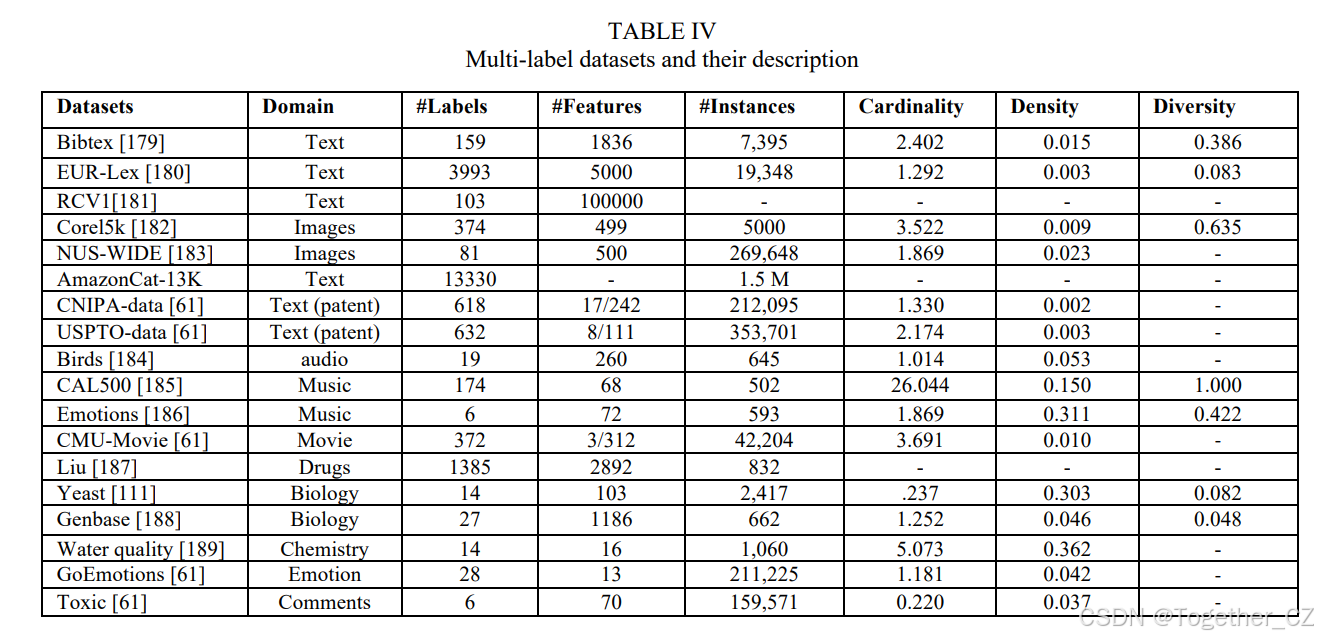
*高数据维度: 与许多学习任务一样,MLC面临维度的挑战。多标签数据集中数据规模的快速扩展通常会导致这一问题的发生,这是由于存在大量冗余、噪声和无关特征,导致过拟合问题。为了缓解这些挑战,必须通过两种主要方法降低特征维度:特征提取和特征选择。前者涉及将高维特征映射到低维空间[204],而后者涉及选择较小的特征子集来替换整个原始集[205]。特征提取产生缺乏物理意义的新特征,而特征选择保留物理意义并增强解释力。表IV提供了一些跨不同领域的多标签数据集的总结。该表包括实例数量、特征、标签、基数、密度、多样性和应用领域的信息。
第六节 比较分析
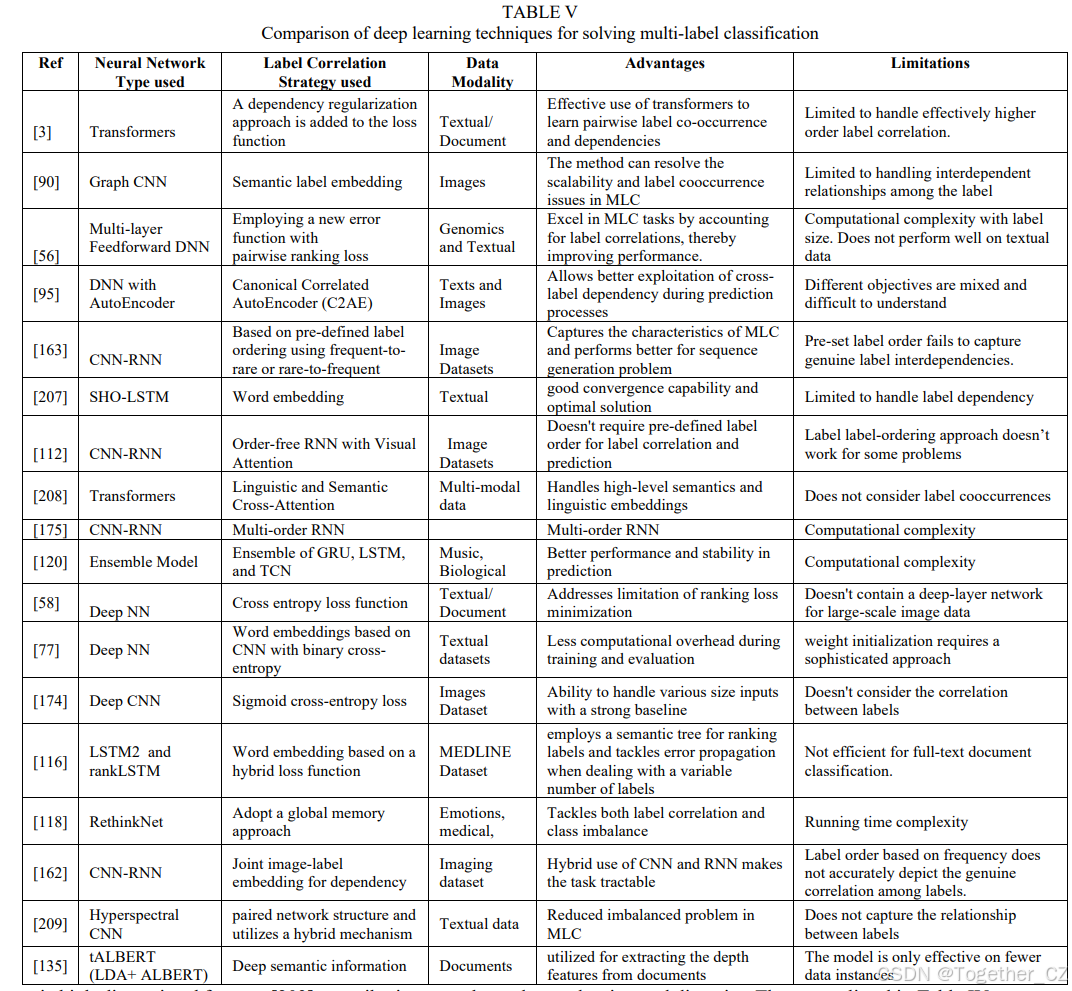
在本节中,我们对现有文献中提出的多种深度学习(DL)方法进行了比较分析,这些方法旨在解决多标签学习(MLL)问题。比较参数包括网络架构、标签相关性处理方法、评估指标、关键发现以及每种提出方法的局限性。表V展示了迄今为止提出的各种使用DL方法解决多标签分类(MLC)问题的详细信息。
第七节 结论
由于其强大的学习能力,DL在各种实际的多标签学习应用中取得了更高的性能,包括多标签图像和文本分类。在解决多标签学习问题时,主要挑战在于有效利用DL更熟练地捕捉标签依赖性。本文对DL方法在MLL问题上的应用进行了广泛考察,主要侧重于涉及标签相关性的多标签分类(MLC)的DL方法。我们整理并审查了2006年至2023年间发表的与MLC的DL技术相关的众多文章。该调查详细介绍了与各种DL方法相关的最新方法,包括深度神经网络(DNN)、卷积神经网络(CNN)、长短期记忆网络(LSTM)、自编码器、变换器和混合模型,以应对MLC挑战。研究概述了所引用的代表性工作,深入探讨了应用于MLC的最新DL技术及其局限性。还简要描述了MLC中现有的挑战和公开可用的多标签数据集。此外,我们对MLC的DL方法进行了比较分析,突出了现有方法的优缺点,并为未来研究提供了有前景的方向。
总体而言,尽管MLC在不同领域的需求不断增加,但开发一个高效且全面的多标签分类DL框架,以及一个有效应对标签相关性等挑战的模型,仍然是一个挑战。因此,未来需要进一步探索以识别更有效的解决方案。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











