






这篇文章介绍了SwissADT,一个针对瑞士三种主要语言(德语、法语、意大利语)和英语的多语言和多模态音频描述翻译(ADT)系统。主要内容包括:
-
背景与挑战:音频描述(AD)是为盲人和视觉障碍者提供的重要无障碍服务,但现有的ADT系统面临数据稀缺和缺乏多模态支持的问题。瑞士的多语言环境进一步增加了ADT系统的复杂性。
-
SwissADT系统:SwissADT通过结合视频片段和文本输入,利用大型语言模型(LLM)自动将AD脚本翻译为瑞士的三种主要语言。系统包含三个主要组件:时刻提取器(选择视频中最相关的片段)、帧采样器(从视频片段中提取帧)和AD翻译器(使用LLM进行翻译)。
-
数据收集与处理:通过DeepL生成合成AD脚本,并结合瑞士国家电视台的AD数据,构建了多语言的AD数据集。
-
评估方法:通过自动评估(BLEU、METEOR、chrF)和人工评估(AD专家评分)验证了SwissADT的翻译质量。结果表明,多模态输入(结合视频帧)可以显著提高翻译质量。
-
贡献与未来工作:SwissADT是首个针对瑞士语言的多语言和多模态ADT系统,展示了LLM在ADT任务中的潜力。未来计划包括微调LLM、整合人在回路原则以及探索其他语言的支持。
-
局限性:未包含罗曼什语、无法对法语和意大利语进行人工评估、未考虑AD的多模态性质、未使用瑞士德语数据。
SwissADT通过结合多模态输入和LLM,展示了其在多语言ADT任务中的潜力,为瑞士的盲人和视觉障碍者提供了更好的信息可访问性。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里,如下所示:
摘要
音频描述(AD)是为盲人和视觉障碍者提供的一项重要无障碍服务,旨在通过声音形式传达视觉信息。尽管多语言机器翻译研究取得了进展,但由于缺乏精心制作且时间同步的AD数据,开发满足瑞士等多语言国家需求的音频描述翻译(ADT)系统仍然面临挑战。此外,大多数ADT系统仅依赖文本,尚不确定是否可以通过结合相应视频片段的视觉信息来提高ADT输出的质量。在本研究中,我们提出了SwissADT,这是首个为瑞士三种主要语言和英语实现的ADT系统。通过收集德语、法语、意大利语和英语中带有视频片段的精心制作的AD数据,并利用大型语言模型(LLMs)的力量,我们旨在通过自动将AD脚本翻译为所需的瑞士语言,增强瑞士多语言人群的信息可访问性。我们广泛的ADT实验结果,包括自动和人工评估的ADT质量,展示了SwissADT在ADT任务中的潜力。我们相信,结合人类专家的知识与LLMs的生成能力可以进一步提高ADT系统的性能,最终使更多的多语言目标人群受益。
1 引言
AD是指通过声音描述使电视或电影等流媒体内容对盲人和视觉障碍者部分可访问的过程[5, 26, 27]。该服务涉及创建关键视觉元素的文本描述,即所谓的“AD脚本”,如动作、环境、面部表情和其他未通过对话、音效或音乐传达的重要细节[28, 24]。它们通常插入在不影响正在进行的叙述的自然停顿中。AD脚本由专业的人类配音员或计算机合成并混合到原始音频中。

图1:(a) SwissADT概述:一个端到端的管道,将给定的AD片段从英语翻译为瑞士的三种主要语言,并结合最显著的视频帧;(b) 时刻提取器细节:选择一个时刻,即最显著的连续帧序列,以增强翻译输入;(c) 帧采样器细节:从提取的时刻中线性插值,获取一系列帧作为AD翻译器的输入。在我们的实现中,我们选择LLM(GPT-4模型)作为AD翻译器,因为它们在执行多语言机器翻译任务方面具有卓越的能力
尽管多语言机器翻译[16, 27]和大型语言模型(LLMs)研究[6, 1]取得了进展,但在开发高性能ADT系统方面仍存在两个主要挑战。首先,许多ADT系统基于预训练的机器翻译模型,这些模型需要源语言和目标语言的文本作为输入。训练这些ADT系统需要大量手工制作的数据,导致高昂的运营成本[30]。其次,现有的ADT系统主要是仅依赖文本的机器翻译模型,忽略了视觉模态,而视觉模态对于ADT任务至关重要,并且在多模态机器翻译中已被证明是有用的[14]。
在瑞士,AD用户的主要目标群体包括约55,000名盲人和327,000名视觉障碍者[29]。瑞士的多语言人口构成了一个挑战,因为AD脚本需要同时以多种语言制作。这凸显了实施多语言ADT系统的必要性。
在本研究中,我们通过开发一个专门针对瑞士三种主要语言(即德语、法语和意大利语)的ADT系统来解决上述挑战。为了以最少的人力创建基于LLM的ADT模型训练数据,我们利用DeepL2(以英语作为辅助语言)生成德语、法语和意大利语的AD脚本。为了验证LLM是否是解决ADT任务的潜在方案,我们对LLM生成的AD脚本进行了自动和人工评估。此外,为了进一步提高翻译质量,我们将视频片段作为输入的一部分,整合到基于LLM的ADT模型中。
我们的贡献如下:1)我们提出了SwissADT,这是首个针对瑞士语言的多语言和多模态ADT系统;2)我们通过自动和人工质量评估对ADT系统进行了广泛的评估;3)我们提供了SwissADT的源代码,便于复现。
2 相关工作
从视频片段自动生成音频描述(AD)的研究已经在自然语言处理(NLP)和计算机视觉(CV)领域展开。这类研究通常作为视频字幕生成(为视频生成描述性文本)或视频定位(将文本查询与视频片段进行时间对齐)等任务的一部分。
近年来,已经发布了多个用于AD的数据集和模型,其中许多是电影字幕或视频描述(Chen和Dolan, 2011; Lison和Tiedemann, 2016; Xu等, 2016; Lison等, 2018)。Oneescu等(2021)提出了QueryD,一个用于文本-视频检索和事件定位任务的开源数据集,其中AD和视频片段由人类志愿者进行标注。Soldan等(2022)提出了MAD,一个大规模的视频-语言定位基准数据集,通过将AD与其视频中的时间对应部分进行对齐。Zhang等(2022)介绍了MovieUN,一个专门为中文电影理解和叙述任务设计的大型基准数据集。Han等(2023a)发布了AutoAD,一个利用仅文本的LLM和多模态视觉-语言模型(VLMs)生成上下文相关AD的模型。在他们的另一项研究中(Han等, 2023b),作者进一步开发了一个扩展模型,以解决AD生成的三个关键方面,即_演员身份_(谁)、时间间隔(何时)和_AD内容_(什么)。尽管这些研究受益于现有的大规模语料库和NLP与CV领域的最新研究成果,但它们仅限于单语言应用,因此无法满足瑞士多语言人口的需求。
第二类研究探讨了将机器翻译模型应用于ADT的可行性和适用性,而ADT最初是一项人工任务。在Fernandez-Torne和Matamala(2016)的研究中,对英语-加泰罗尼亚语AD脚本对的_创建_、_翻译_和_后期编辑_进行了广泛研究,以评估机器翻译的AD脚本是否能达到令人满意的质量。作者发现,机器翻译模型可以作为一个可行的解决方案。Vercauteren等(2021)研究了英语-荷兰语AD脚本对,发现机器翻译的AD脚本中错误普遍存在,表明需要人工专家进行后期编辑。
与上述一些研究不同,我们展示了将视觉输入引入ADT系统可以带来改进的结果,这在我们的AD专家进行的人工评估中得到了验证。
3 SwissADT:瑞士语言的ADT系统
SwissADT是一个多语言和多模态的基于LLM的ADT系统,能够在英语和瑞士三种主要语言之间进行AD脚本的翻译,并结合视觉和文本输入。它包含三个基本组件:
时刻提取器(Moment Retriever):为了识别视频片段中最相关的时间段(即一系列连续帧),我们首先选择一个从AD开始时间(起始时间)前10秒到结束时间(结束时间)后10秒的视频片段3。然后,我们应用视频时间定位器CG-DETR(Moon等, 2023),该定位器接收AD脚本和选定的视频片段,并通过提供起始和结束时间以及定位分数,输出长度可变的最相关时间段。最终的时刻是通过从候选时刻池中选择得分最高的时刻来提取的。
脚注3:添加10秒的缓冲区确保所描述的时刻完全包含在视频片段中。尽管AD通常与描述内容同步,但在对话较多的场景中,可能会为了适应无语音段而进行时间偏移。根据我们的AD专家建议,这种缓冲区足以捕捉到即使有偏移的描述内容。
帧采样器(Frame Sampler):我们从提取的时刻中线性采样多个视频帧4。这些帧随后作为AD翻译器的视觉输入。我们根据经验报告了使用4帧和每50帧采样的结果5。
脚注4:线性采样可靠地包含了代表整个片段的帧。我们将其他采样方法留待未来研究。
脚注5:在我们的系统中,视频帧的数量可以由用户手动设置。
AD翻译器(AD Translator):我们部署了多语言和多模态的LLM作为SwissADT的核心AD翻译器。我们在实验中使用了基础的GPT-4模型(gpt-4o和gpt-4-turbo)。我们决定采用零样本学习作为成本效益的解决方案。
SwissADT的模块化实现简化了最先进LLM研究成果的整合。这种设计使得在最小努力下无缝集成最新的时刻提取器和AD翻译器成为可能。
4 数据收集
AD脚本和视频片段
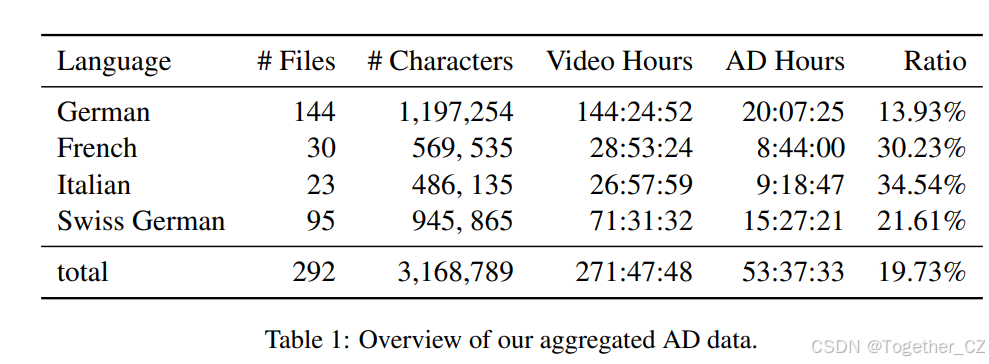
我们从瑞士国家电视台播出的电影和电视节目中收集AD脚本,包括瑞士广播电视公司(SRF)、瑞士法语电视台(RTS)和瑞士意大利语电视台(RSI)。表1概述了我们收集的AD脚本。
值得注意的是,法语和意大利语的AD脚本在视频中的运行时间明显长于德语。这种差异源于数据来源:德语AD主要来自电视游戏节目《1 gegen 100》的剧集,该节目场景相对静态(相同的演播室设置和主持人,只有游戏参与者变化),因此减少了AD的需求。相比之下,法语和意大利语AD主要来自电影和纪录片,这些内容通常需要更多的描述性叙述。
为了方便数据存储,我们使用SRT格式(常用于字幕)存储AD,并以mp4格式存储视频。图2(附录A)展示了我们数据集中的一段AD片段。
使用DeepL生成合成AD
由于缺乏平行数据,我们使用DeepL为系统中的每种语言对生成合成AD脚本。
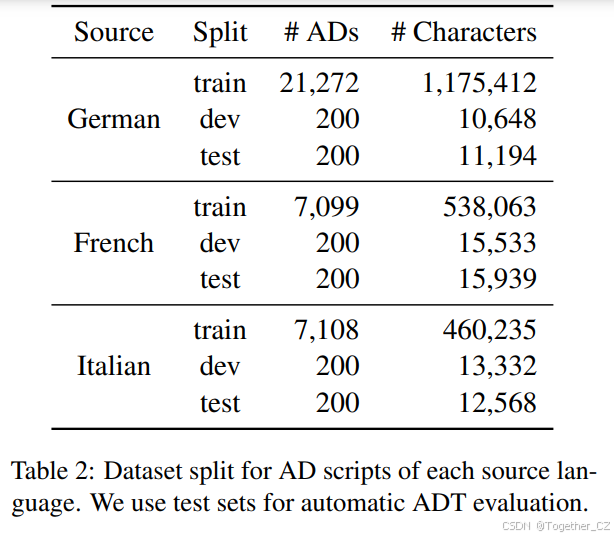
我们将所有德语、法语和意大利语的AD脚本分别翻译成其他两种瑞士语言以及英语。我们将英语作为中介语言,以便与项目合作伙伴开发的AD脚本生成系统协同工作。此外,时刻提取器CG-DETR是在英语数据集上训练的,因此英语在我们的管道中是必需的。对于每种源语言,我们随机将合成AD分为训练集、开发集和测试集(详见表2)。我们将开发集和测试集中的AD数量限制为每种语言200个样本,以保留训练数据用于进一步实验,考虑到法语和意大利语的数据集大小为7,500个样本。AD数据稀缺,因此我们在训练和测试之间谨慎平衡其使用。此外,我们保持所有语言的测试集大小一致,以确保评估的一致性。
由于使用DeepL翻译瑞士德语AD脚本的质量不足,我们排除了瑞士德语AD脚本。
5 评估方法
DeepL翻译质量评估
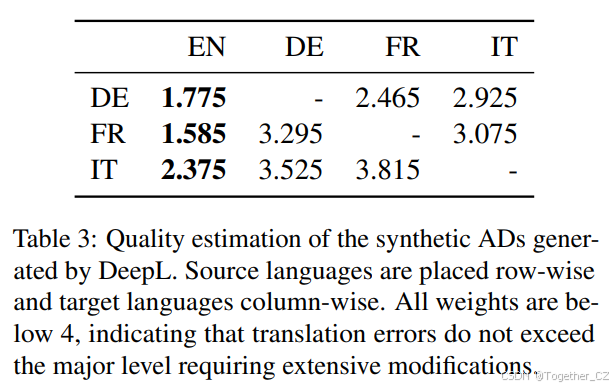
我们使用GEMBA-MQM(Kocmi和Federmann, 2023)评估DeepL翻译的银标准AD脚本的质量,该指标基于GPT-4的三次提示,用于识别和标注错误片段。该评估在每种源-目标语言对的200个AD测试集上进行,无错误、轻微错误、_重大错误_和_严重错误_的权重分别为0、1、5和10。表3展示了DeepL翻译的AD脚本的整体错误权重。
这些结果表明,DeepL翻译的AD脚本中的错误从轻微到重大不等,从机器学习的角度来看,这些错误是可以接受的。
自动ADT评估
我们使用bleu(Papineni等, 2002)、meteor(Banerjee和Lavie, 2005)和chrf(Popovic, 2015)作为SwissADT翻译的AD脚本的自动评估指标,通过将生成的AD脚本与真实值进行比较来计算得分。
人工评估与AD专家
我们与AD专家6进行人工评估,以评估SwissADT翻译的AD脚本的质量。我们的目标是验证自动评估分数是否能很好地反映人类判断,以及多模态输入是否能提高翻译质量。
我们使用Microsoft Forms7进行研究。根据标量质量度量(SQM,Freitag等, 2021)评估,我们沿三个维度评估每对AD(源语言和目标语言):流畅性、充分性_和AD的_实用性。AD专家在0到6的七点量表上对这些维度进行评分。评估在线进行,我们按每小时85瑞士法郎的标准补偿AD专家。我们比较了我们最佳AD翻译器gpt-4o的两种输入模态的翻译:仅文本和文本加四帧,以进行评估。
由于难以聘请具备足够英语知识的法语和意大利语AD专家,我们集中评估德语AD脚本。因此,我们招募了三位AD专家A、B和C进行人工评估。预研究问卷的反馈显示,所有三位AD专家都拥有翻译学位,并且具有三到五年至十年以上的专业经验。此外,AD专家B和C还接受过专业后期编辑的培训。
在人工评估中,我们随机从德语数据集中抽取30个连续的10段AD片段块。我们选择连续的AD片段,以便AD专家有更多上下文来判断翻译。为了减少偏见,每位AD专家以随机顺序评估相同的30个块。
我们使用gpt-4o将英语银标准AD片段翻译回德语。我们随机为每个片段选择两种策略之一:仅文本和文本加四帧。AD专家会看到英语源片段和gpt-4o的德语翻译,但不知道使用了哪种输入模态进行翻译。
我们报告加权Cohen's kappa(Cohen, 1968)以评估评估者间的一致性。
6 结果与讨论
AD翻译
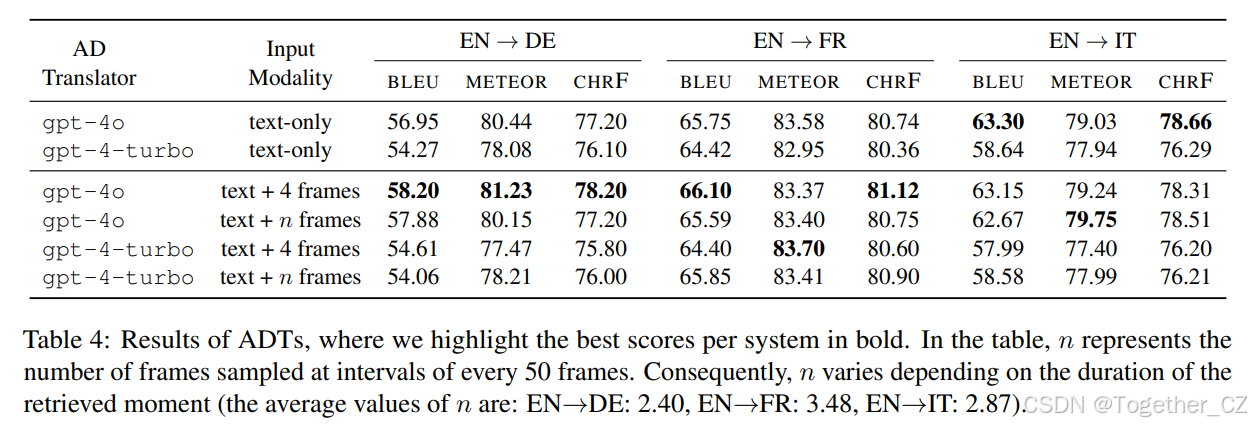
表4展示了各种AD翻译器的自动评估结果。我们观察到:
-
gpt-4o优于gpt-4-turbo;
-
基于GPT-4的结果在ADT任务中表现出良好的性能,自动评估分数较高,支持了应用机器翻译模型解决ADT任务的有效性,这与之前的文献一致;
-
通过在源AD中加入相应的视频帧,通常可以提高翻译质量,输入帧数越多,结果越好。这表明将视觉模态整合到ADT管道中,利用基础LLM的力量是有益的。
gpt-4o在仅文本输入下EN→IT的略好表现可能是由于语言特定因素、数据集规模较小或多语言零样本能力的差异,因为这些差异在统计上并不显著。这一结果并不削弱多模态输入总体上提高翻译质量的假设,因为其他语言对显示了预期的优势。有关视觉输入有益的示例,请参见附录D。
鉴于培训AD专家需要完成涵盖多种基本能力和技能的课程(Matamala和Orero, 2007; Jankowska, 2017; Colmenero等, 2019),AD制作方一直面临AD专家短缺的问题。因此,基于多语言和多模态LLM的自动ADT系统,结合人工后期编辑,可以有效利用AD制作。
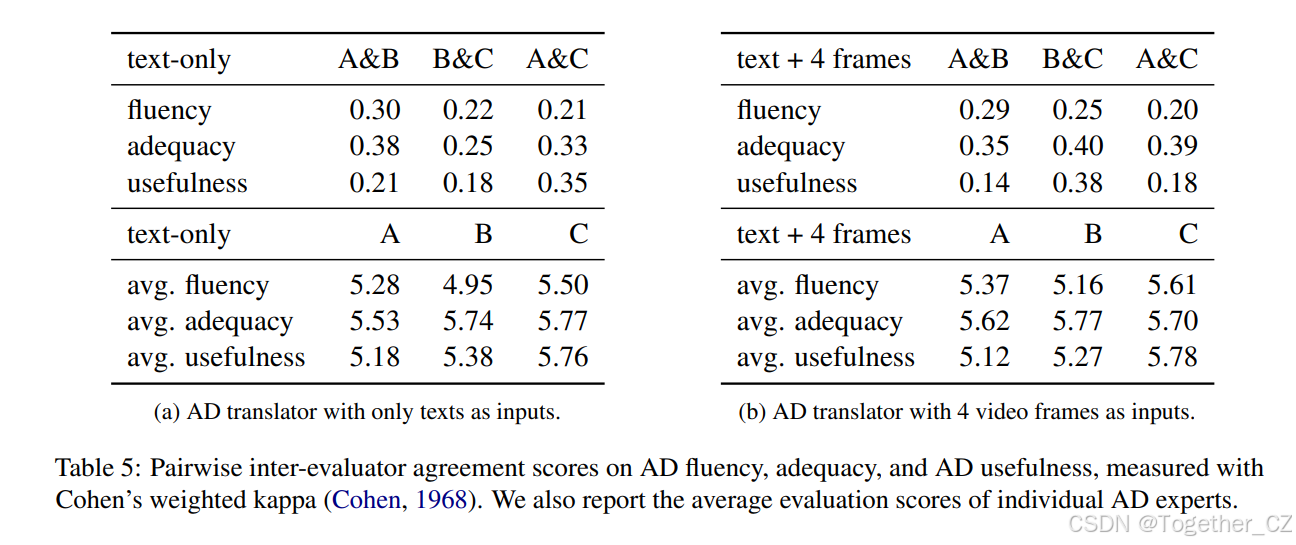
人工评估
表5展示了我们AD专家进行的评估者间一致性结果以及每位AD专家的平均评估分数。首先,我们发现AD专家总体上表现出一定程度的一致性,突显了即使在专业培训的人员中,评估AD翻译也具有内在的难度。鉴于人类评估者之间的主观差异,我们认为自动评估指标仍然至关重要,因为它们提供了独立于评估者培训的额外客观评估。我们还观察到,使用四帧输入翻译的AD脚本在流畅性(5.38)和充分性(5.70)方面得分高于仅文本输入的翻译(流畅性:5.24,充分性:5.68)。这些结果验证了我们的假设,即多模态输入可以提高翻译质量。然而,AD实用性维度对仅文本输入的翻译评分略高(5.44),而四帧输入的翻译评分为5.39。鉴于AD专家对AD实用性的主观意见,我们认为引入终端用户可能会带来更客观的评估。这一方法将在我们未来的研究中进行探索。
7 结论与未来工作
在本研究中,我们提出了SwissADT,一个支持瑞士三种语言和英语的多语言和多模态ADT系统。我们的研究结果表明,利用LLM解决ADT任务是实现信息可访问性的重要第一步,并得到了我们经验丰富的AD专家的验证。我们预计,我们的工作将使瑞士的盲人和视觉障碍者受益,增强他们访问流媒体内容的能力。
在未来的工作中,我们计划探索其他LLM用于ADT任务,并通过使用训练数据对这些模型进行微调。此外,我们计划将ADT管道与人在回路原则相结合,使用强化学习方法训练系统,以更好地将ADT系统的输出与人类偏好对齐。我们相信,将人类专业知识整合到LLM管道中,将更有效地满足终端用户的需求和满意度。正如任何无障碍技术一样,确保其服务于终端用户的需求至关重要。
8 局限性
我们工作的局限性如下:1)由于缺乏高质量数据,我们未将罗曼什语作为目标AD语言,尽管它是瑞士的官方语言,拥有近35,000名母语使用者8;2)鉴于难以找到法语和意大利语的AD专家,我们无法对这两种语言进行人工评估。然而,我们预计结果将与德语AD相当,因为我们的最佳AD翻译器gpt-4o的翻译结果相似;3)AD的多模态性质未在人工评估中考虑,这需要AD专家能够访问视觉输入;4)我们未使用瑞士德语部分的数据集,因为瑞士德语缺乏标准化的拼写规则,导致机器翻译系统面临挑战。这主要是因为瑞士德语中的每个词可能有多种拼写变体,导致词汇量扩大。然而,我们最近了解到,TextShuttle9开发的瑞士德语到德语翻译模型取得了良好的效果,我们计划将其模型整合到SwissADT管道中。
脚注9:https://www.textshuttle.com
9 伦理声明
为了确保隐私保护和数据匿名化,我们按照苏黎世应用科技大学(ZHAW)的指南,正式获得了人类评分数据收集的知情同意。
本研究由瑞士创新局(Innosuisse)的包容性信息与通信技术(IICT)旗舰项目资助,资助协议号为PFFS-21-47。我们感谢我们的行业合作伙伴SWISS TXT和SRG,特别是Daniel McMinn和Veronica Leoni,为我们提供了用例并提供了数据。
附录
附录A:音频描述脚本
我们使用常见的字幕格式SRT,将AD视为字幕。详见图2的数据模式。

附录B:定价
为了估算翻译大量AD数据集的成本,我们根据我们的数据集提供了表6中的计算。请注意,OpenAI的定价政策可能会有变动,其他因素如输入帧的分辨率和大小、AD片段的频率和长度也会对总价格产生重大影响。
附录C:提示
表7展示了我们在实验和系统演示中使用的经验提示。我们使用这些提示进行gpt-4o和gpt-4-turbo的AD翻译。
附录D:示例
以下示例展示了多模态输入如何通过提供额外上下文来增强翻译质量。相关帧如图3所示。
语法歧义:意大利语音频描述_Volta la testa verso un treno che avanza sui binari_存在多种翻译可能性。动词_volta_可以有两种解释:
-
第三人称单数直陈式:Helshe turns his/her head towards a train moving on the tracks.
-
第二人称单数命令式:Turn your head!
这种歧义通过图3a中显示的一个人坐在火车站台上的视觉上下文得以解决。
词汇歧义:法语音频描述_Le phare eclaire deux chevreuils_有两种可能的翻译:
-
The lighthouse illuminates two deer.
-
The spotlight illuminates two deer.
图2(b)中的第二帧清楚地显示,在此上下文中,phare_应翻译为_spotlight。
我们的SwissADT系统演示(见图4的系统界面)托管在https://github.com/fischer192/swissADT。请按照我们项目页面上的详细说明设置演示。
此外,我们的演示也在我们部门的服务器上运行,地址为https://pub.cl.uzh.ch/demo/swiss-adt,无需配置即可访问。我们还录制了一段YouTube视频,解释如何使用该演示,视频链接为https://youtu.be/5PQs8DscubU。
图表
图1:SwissADT概述
(a) SwissADT概述:一个端到端的管道,将给定的AD片段从英语翻译为瑞士的三种主要语言,并结合最显著的视频帧。
(b) 时刻提取器细节:选择一个时刻,即最显著的连续帧序列,以增强翻译输入。
(c) 帧采样器细节:从提取的时刻中线性插值,获取一系列帧作为AD翻译器的输入。在我们的实现中,我们选择LLM(GPT-4模型)作为AD翻译器,因为它们在执行多语言机器翻译任务方面具有卓越的能力。
图2:AD脚本示例
图2展示了德语AD脚本的一个示例,包含字幕和特殊字符。美元符号($)表示语速较快的受限时间框架。星号(*)表示脚本中的场景变化。字幕用UT标记,是德语“Untertitel”的缩写。

图3:歧义示例
图3展示了两个需要额外上下文来解决歧义的示例。通过视觉输入正确消歧的词语以粗体突出显示。
表1:收集的AD数据概览
| 语言 | 文件数 | 字符数 | 视频时长 | AD时长 | 比例 |
|---|---|---|---|---|---|
| 德语 | 144 | 1,197,254 | 144:24:52 | 20:07:25 | 13.93% |
| 法语 | 30 | 569,535 | 28:53:24 | 8:44:00 | 30.23% |
| 意大利语 | 23 | 486,135 | 26:57:59 | 9:18:47 | 34.54% |
| 瑞士德语 | 95 | 945,865 | 71:31:32 | 15:27:21 | 21.61% |
| 总计 | 292 | 3,168,789 | 271:47:48 | 53:37:33 | 19.73% |
表2:每种源语言的AD脚本数据集划分
| 源语言 | 划分 | AD数量 | 字符数 |
|---|---|---|---|
| 德语 | 训练 | 21,272 | 1,175,412 |
| 开发 | 200 | 10,648 | |
| 测试 | 200 | 11,194 | |
| 法语 | 训练 | 7,099 | 538,063 |
| 开发 | 200 | 15,533 | |
| 测试 | 200 | 15,939 | |
| 意大利语 | 训练 | 7,108 | 460,235 |
| 开发 | 200 | 13,332 | |
| 测试 | 200 | 12,568 |
表3:DeepL生成的合成AD的质量评估
| 源语言 | 目标语言 | 错误权重 |
|---|---|---|
| 德语 | 英语 | 1.775 |
| 法语 | 2.465 | |
| 意大利语 | 2.925 | |
| 法语 | 英语 | 1.585 |
| 德语 | 3.295 | |
| 意大利语 | 3.075 | |
| 意大利语 | 英语 | 2.375 |
| 德语 | 3.525 | |
| 法语 | 3.815 |
表4:ADT结果
| AD翻译器 | 输入模态 | EN→DE | EN→FR | EN→IT |
|---|---|---|---|---|
| gpt-4o | 仅文本 | 56.95 | 65.75 | 63.30 |
| gpt-4-turbo | 仅文本 | 54.27 | 64.42 | 58.64 |
| gpt-4o | 文本+4帧 | 58.20 | 66.10 | 63.15 |
| gpt-4o | 文本+n帧 | 57.88 | 65.59 | 62.67 |
| gpt-4-turbo | 文本+4帧 | 54.61 | 64.40 | 57.99 |
| gpt-4-turbo | 文本+n帧 | 54.06 | 65.85 | 58.58 |
表5:AD专家的评估结果
| 输入模态 | 评估者间一致性 | 平均评分 |
|---|---|---|
| 仅文本 | A&B: 0.30, B&C: 0.22, A&C: 0.21 | A: 5.28, B: 4.95, C: 5.50 |
| 文本+4帧 | A&B: 0.29, B&C: 0.25, A&C: 0.20 | A: 5.37, B: 5.16, C: 5.61 |
表6:翻译成本估算
| 模型 | 定价 | 190个AD的成本 |
|---|---|---|
| gpt-4o | 输入tokens: 5.00/百万,输出tokens:5.00/百万,输出tokens:15.00/百万 | 仅文本: 0.11,文本+4帧:0.11,文本+4帧:4.33 |
| gpt-4-turbo | 输入tokens: 10.00/百万,输出tokens:10.00/百万,输出tokens:30.00/百万 | 仅文本: 0.23,文本+4帧:0.23,文本+4帧:8.66 |
表7:翻译提示
| 仅文本 |
|---|
| 将以下音频描述从{source_language}翻译为{target_language}。仅返回翻译结果。待翻译的音频描述:{audio_description} |
| 文本+帧 |
|---|
| 将以下音频描述从{source_language}翻译为{target_language},并结合视频帧。仅返回翻译结果。如果音频描述与图像不匹配,请忽略图像。待翻译的音频描述:{audio_description} |
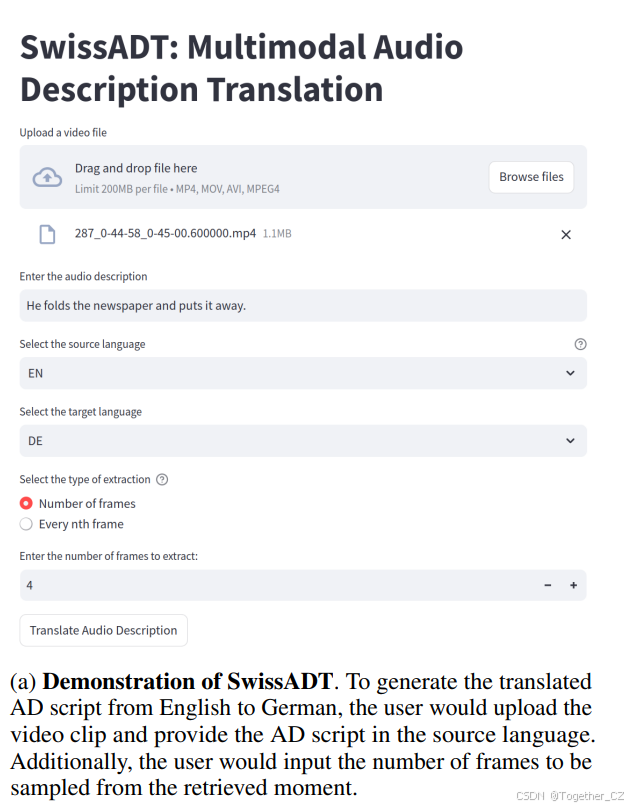
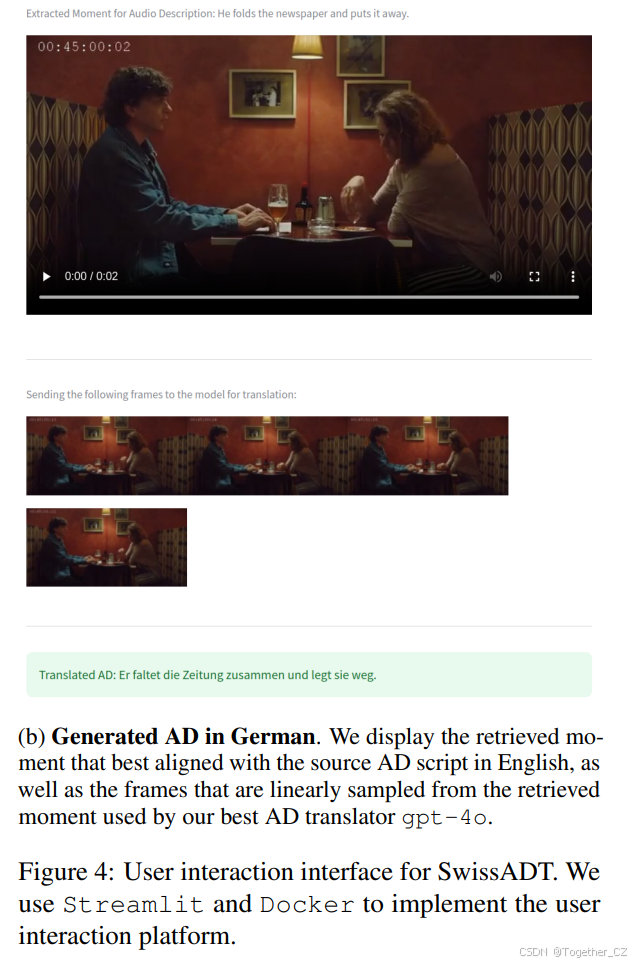
图4:系统演示界面
图4展示了SwissADT系统演示的界面。
结论
SwissADT通过结合多语言和多模态LLM,展示了其在ADT任务中的潜力,并得到了AD专家的验证。我们相信,这一系统将为瑞士的盲人和视觉障碍者提供更好的流媒体内容访问体验,并期待未来的进一步研究能够进一步提升其性能和适用性。



















 1961
1961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











