






这篇文章提出了一种解决多条件混淆的无微调个性化图像生成方法,主要内容和贡献如下:
-
问题背景:
个性化文本到图像生成方法能够基于参考图像生成定制化图像。现有的无微调方法(如IP-Adapter)在生成单个参考图像时表现良好,但在处理多个参考图像时会出现对象混淆问题,即无法将每个参考图像正确映射到其对应的对象。 -
解决方案:
-
加权合并方法:提出了一种加权合并方法,通过估计潜在图像特征中不同位置与目标对象的相关性,将多个参考图像特征合并到相应的对象中,从而缓解对象混淆问题。
-
对象质量评分:提出了一个对象质量评分,用于从大规模数据集中选择高质量的训练样本,减少训练成本并提高模型性能。
-
训练框架:将加权合并方法集成到预训练模型中,并在多对象数据集上继续训练,进一步提升了模型在多对象和单对象个性化图像生成中的表现。
-
-
实验验证:
-
实验结果表明,该方法在多对象个性化图像生成任务中优于现有的最先进方法,并在单对象生成任务中显著提升了性能。
-
通过消融实验验证了加权合并方法和对象质量评分的有效性。
-
-
主要贡献:
-
扩展了无微调方法的解耦交叉注意力机制,解决了多参考图像生成中的对象混淆问题。
-
构建了一个高质量的多对象数据集,并提出了对象质量评分用于图像选择。
-
在多个基准数据集上验证了方法的优越性,代码和数据集将公开以促进社区研究。
-
这篇文章通过提出加权合并方法和对象质量评分,有效解决了多参考图像生成中的对象混淆问题,显著提升了无微调个性化图像生成的性能。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里
摘要
个性化文本到图像生成方法能够基于参考图像生成定制化的图像,引发了广泛的研究兴趣。最近的方法提出了一种无微调的方法,通过解耦的交叉注意力机制生成个性化图像,无需在测试时进行微调。然而,当提供多个参考图像时,当前的解耦交叉注意力机制会遇到对象混淆问题,无法将每个参考图像映射到其对应的对象,从而严重限制了其应用范围。为了解决对象混淆问题,本文研究了扩散模型中潜在图像特征的不同位置与目标对象的相关性,并相应地提出了一种加权合并方法,将多个参考图像特征合并到相应的对象中。接着,我们将这种加权合并方法集成到现有的预训练模型中,并在从开源的SA-1B数据集构建的多对象数据集上继续训练模型。为了减轻对象混淆并降低训练成本,我们提出了一个对象质量评分来估计图像质量,以选择高质量的训练样本。此外,我们的加权合并训练框架可以应用于单对象生成,当单个对象有多个参考图像时。实验验证了我们的方法在多对象个性化图像生成上优于现有技术,并显著提高了单对象个性化图像生成的性能。
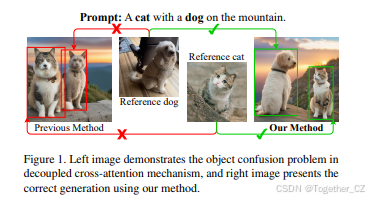
1. 引言
个性化文本到图像生成方法基于参考图像生成图像,指定生成内容的细节,由于其多样化的应用,引发了广泛的研究兴趣。该领域的方法逐渐从基于微调的方法(如DreamBooth [17]、Custom Diffusion [9])转向无微调技术(如IP-Adapter [22]、Subject-Diffusion [14]),因为无微调方法消除了测试时的微调需求,显著降低了使用成本。
早期的无微调方法,如InstantBooth [18]和FastComposer [20],简单地将参考图像的特征集成到文本嵌入中,并将其输入文本编码器,没有充分利用参考图像的信息。最近的无微调方法,如IP-Adapter [22],通过训练额外的交叉注意力层将参考图像特征集成到扩散模型的中间层,更全面地利用了参考图像的特征,并实现了与基于微调方法相当的性能。然而,当前的解耦交叉注意力机制仅考虑每次生成一个参考图像。当提供多个参考图像时,解耦交叉注意力机制如果直接应用,会遇到对象混淆问题,即参考图像中的对象特征被错误地分配到生成图像中的错误对象,如图1所示。一些先前的图像生成方法[21]尝试通过将对象特征合并到扩散模型中潜在图像特征的相应区域来缓解对象混淆问题。然而,由于深度网络中的大感受野[1, 13],对象信息分布在整个图像特征空间中,而不是局限于相应的局部区域,因此生成的图像在忠实于参考图像方面可能受限(即生成图像与参考图像的外观存在差异),如图2所示。
在本研究中,我们提出了一种加权合并方法,而不是将潜在特征分割到不同区域。具体来说,我们通过巧妙地利用稳定扩散模型中目标对象的文本特征与潜在图像特征之间的交叉注意力权重,估计这些权重作为潜在图像特征中不同位置与目标对象的相关性。此外,我们设计了一个实验,基于预测的对象相关性向潜在图像特征添加不同的噪声,验证了这种对象相关性估计方法的有效性。我们将该方法应用于预训练的无微调个性化生成模型(如IP-Adapter),通过同时将多个条件(参考图像和文本提示)合并到模型中,实现了多对象生成。实验结果表明,我们的方法可以缓解对象混淆,并显著提高这些模型在多对象个性化图像生成中的性能,而无需任何训练。
尽管加权合并有效缓解了对象混淆,但一次性添加多个参考图像会干扰潜在图像特征,导致其偏离原始模型中的分布,从而降低生成质量。为了解决这个问题,本研究在多对象数据集上使用加权合并方法对预训练的无微调模型进行训练。具体来说,该数据集是从开源的SA-1B数据集[8]构建的,该数据集包含约1100万张包含多个对象的图像。此外,本研究提出了一个对象质量评分,根据多个对象之间的混淆程度以及对象文本与图像之间的匹配度来估计图像的对象质量。基于对象质量评分,我们可以选择高质量图像,以缓解对象混淆问题,提高性能,同时降低训练成本。
此外,这种加权合并训练框架可以应用于单对象生成,因为在实际应用中,单个对象可能有多个参考图像。与之前仅使用单个参考图像或简单平均多个图像特征的方法相比,我们的加权合并方法可以从不同的参考图像中提取多样化的有用信息,并自适应地合并它们,以实现更好的结果。
我们进行了全面的实验来验证所提出框架的性能。实验结果表明,仅从SA-1B数据集中选择的10万张高质量图像(占Subject Diffusion数据集的0.13%),我们的模型在Concept101数据集和DreamBooth数据集上的多对象个性化图像生成中达到了最先进的性能。此外,我们的加权合并训练框架显著提高了预训练模型在DreamBooth数据集上的单对象个性化图像生成性能。
总而言之,本研究的主要贡献可以总结如下:
-
我们扩展了无微调个性化图像生成方法的解耦交叉注意力机制,以合并多个条件,并提出了加权合并方法来解决对象混淆问题。
-
我们从开源的SA-1B数据集中构建了一个小而高质量的数据集用于模型训练,并提出了对象质量评分用于图像选择。
-
实验结果表明,我们的加权合并训练框架在合并多个条件方面表现出色,我们的模型在Concept101数据集和DreamBooth数据集上的多对象个性化图像生成中达到了最先进的性能。
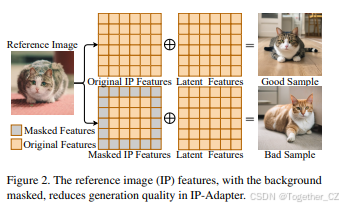
2. 相关工作
基于微调的个性化图像生成。 早期的个性化图像生成方法需要在参考图像上对原始扩散模型进行微调。具体来说,DreamBooth微调了扩散模型的整个UNet网络,Textual Inversion [2]仅微调目标对象的特殊嵌入向量,而Custom Diffusion仅微调UNet网络中交叉注意力的K和V层。Cones [12]检测K和V层中的概念神经元,并在训练期间更新它们。Mix-of-Show [3]为每个对象训练一个单独的LoRA模型,并通过梯度融合将它们合并。然而,这些方法需要对每个对象进行微调,消耗大量计算资源,不适合实际应用。
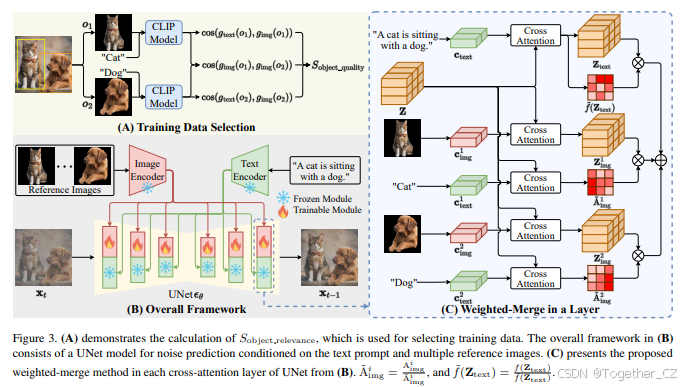
无微调的个性化图像生成。 无微调方法在大数据集上训练模型,直接合并参考图像特征,无需在测试时进行额外的微调。早期的无微调方法(如InstantBooth、FastComposer和Taming Encoder [6])简单地将图像特征集成到文本嵌入中,没有充分利用参考图像信息。最近的方法(如IP-Adapter、ELITE [19]和SSR-Encoder [23])通过使用解耦交叉注意力机制将图像特征集成到扩散模型的中间层,更广泛地利用了参考图像信息。这些方法在合并单个参考图像时表现出色,并取得了令人印象深刻的性能。然而,当合并多个参考图像时,解耦交叉注意力会遇到对象混淆问题,这也是本研究旨在解决的问题。
3. 方法
在本节中,我们首先在第1节中给出预备知识,然后在第2节中提出对象相关性估计方法。接着,第3节和第4节提出了加权合并方法,并直接将其应用于当前的预训练模型。最后,第5节提出了进一步提高性能的训练框架。
3.1 预备知识
扩散模型。 当前的个性化图像生成方法采用扩散模型[16, 4]作为基础模型。扩散模型由两个过程组成:扩散过程通过马尔可夫链在T步中逐渐向原始图像添加噪声,以及去噪过程使用深度神经网络预测噪声以生成图像。具体来说,个性化图像生成方法同时基于文本提示和参考图像生成图像。通常,ϵθϵ表示用于噪声预测的深度神经网络,个性化扩散模型的训练损失定义如下:

3.2 对象相关性估计


3.3 无训练的个性化图像生成

3.4 对象相关性评分的验证

3.5 基于训练的个性化图像生成

4. 实验
实现细节。 我们的主要实验在预训练的IP-Adapter上进行,使用sdxl模型[15]和sdxl_plus模型[5]作为文本到图像扩散模型,并使用OpenCLIP ViT-bigG/14作为图像编码器。sdxl和sdxl_plus模型以及图像编码器的参数被冻结,仅训练用于投影图像特征和预测文本权重的参数。在训练期间,我们采用AdamW优化器,学习率为1e-4,并在8个PPU上训练模型30,000步,每个PPU的批量大小为4。为了启用无分类器指导,我们使用0.05的概率单独丢弃文本和图像,并使用0.05的概率同时丢弃文本和图像。在推理时,我们采用DDIM采样器,步数为50,并将指导尺度设置为7.5。我们还在基于解耦交叉注意力的其他预训练模型上进行了实验,以验证我们方法的泛化能力,详见附录S2.2。
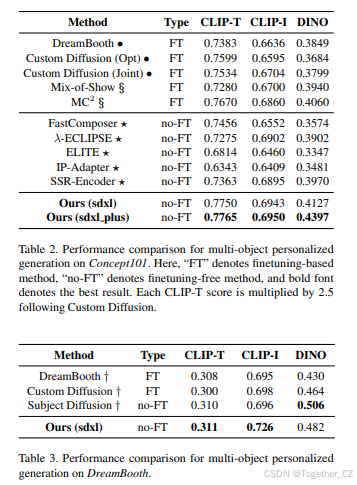
测试基准。 对于多对象个性化图像生成,我们遵循_Concept101_[9]基准,该基准评估了许多方法。此外,我们还在_DreamBooth_基准上评估了我们的方法,以与Subject-Diffusion进行比较。


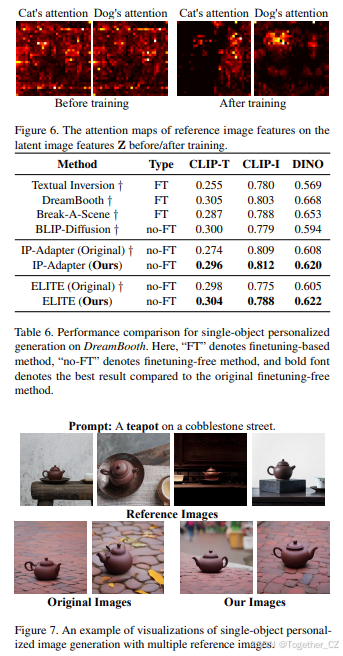
评估指标。 我们遵循之前的方法,采用三个指标(CLIP-T、CLIP-I和DINO)进行评估。具体来说,CLIP-T评估生成图像与给定文本提示之间的相似性;CLIP-I和DINO评估生成图像与参考图像之间的相似性。每个提示生成5张图像以确保评估的稳定性。
基线方法。 我们将我们的方法与基于微调的方法(如Textual Inversion、DreamBooth、Custom Diffusion、![]() )和无微调方法(如SSR-Encoder、Subject-Diffusion)进行了比较。
)和无微调方法(如SSR-Encoder、Subject-Diffusion)进行了比较。
5. 结论
在本研究中,我们通过解决对象混淆问题,扩展了无微调方法的解耦交叉注意力机制,以合并多个参考图像。为此,我们探索了扩散模型中潜在图像特征的不同位置与目标对象的重要性,并相应地提出了一种加权合并方法,将参考图像特征与其对应的对象合并。这种加权合并方法可以直接以无训练的方式提高现有预训练模型在多对象生成中的性能。接着,我们在使用提出的对象质量评分构建的多对象数据集上继续训练预训练模型,以进一步提高性能。此外,我们的加权合并训练框架可以应用于单对象生成,当单个对象有多个参考图像时。实验结果表明,我们的方法显著优于现有方法。我们希望我们的方法和数据集(将公开提供)能够为个性化图像生成社区做出贡献。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











