







前言
在数据驱动的时代,掌握数据抓取、处理和存储的能力变得至关重要。本文小支同学将带领大家完成两个关键任务:一是从中国历史票房红榜中抓取电影数据,并将其存储到MySQL数据库中;二是从API接口获取电影数据,进行统计分析后,将结果写入数据库。通过这两个任务,我们将深入了解数据处理的全流程,从数据获取到清洗,再到最终的存储和分析。无论您是数据分析师、开发人员,还是对数据处理感兴趣的初学者,本文都将为您提供宝贵的知识和实践经验。让我们一起开始这段数据处理的旅程吧!

题目一:获取电影数据并写入数据库
1. 题目具体分析
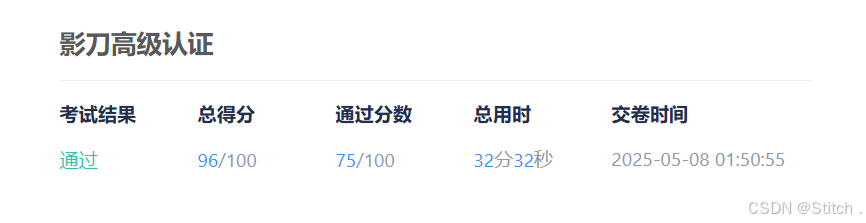
目标:从中国历史票房红榜抓取数据,存入指定MySQL数据库。
数据库信息:IP
43.143.30.32,端口3306,用户名yingdao,密码9527,库名ydtest,表名movie。测试结果:
首先我们来到题目中所说的网址进行分析,发现我圈起来的红色框内的数据是我们需要获取的,但是观察到网页中的数据与我们最后需要的数据有点出入,因此我们需要对数据进行相关的处理。那么我们就需要开始请求获取数据。
快捷使用
题目一:获取电影数据并写入数据库
1.1 安装三个需要的库
pymysql lxml requests1.2 模块代码
# 使用提醒: # 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能 # 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能 # 3. 当此模块作为流程独立运行时执行main函数 # 4. 可视化流程中可以通过"调用模块"的指令使用此模块 # author - 夜时雨 # time - 2025-3-19 # csdn - https://blog.csdn.net/qq_48902216 import xbot from xbot import print, sleep from .import package from .package import variables as glv # 本模块所需要的包 import re import requests from lxml import etree import pymysql # 缩写字母国家字典(🇨🇳_中国) country_dict = { '🇨🇳': '中国', '🇺🇸': '美国', '🇯🇵': '日本', '🇭🇰': '香港', '🇹🇼': '台湾', '🇰🇷': '韩国', '🇩🇪': '德国', '🇫🇷': '法国', '🇮🇹': '意大利', '🇪🇸': '西班牙', '🇷🇺': '俄罗斯', "🇮🇳": '印度', "🇬🇧": '英国', "🇫🇮": '芬兰', "🇱🇧": '黎巴嫩共和国', "🇦🇺": '澳大利亚', } # 获取电影数据 def get_movie(): url = 'http://www.boxofficecn.com/the-red-box-office' res = requests.get(url) res_text = etree.HTML(res.text) tr_list = res_text.xpath('//*[@id="tablepress-4"]/tbody/tr') result = [] for tr in tr_list: movie_time_and_country = tr.xpath('./td[1]/text()')[0] try: movie_time, movie_country_words = movie_time_and_country.split(' ') except Exception as e: print(e) # 正则识别年份与国家例如:2023🇨🇳,将年份2023与关键字段🇨🇳分别识别出来 movie_time = re.findall(r'\d+', movie_time_and_country)[0] movie_country_words = movie_time_and_country.split(movie_time)[1] print(movie_time, movie_country_words) movie_country = country_dict[movie_country_words.strip()] movie_name_and_score = tr.xpath('./td[2]/text()')[0] movie_name = movie_name_and_score.split('(')[0] movie_score = movie_name_and_score.split('(')[1].split(')')[0] movie_actors = tr.xpath('./td[3]/text()')[0] movie_money_list = tr.xpath('./td[last()]/font/text()') or tr.xpath('./td[last()]/text()') or [] if len(movie_money_list) == 0: movie_money = 0 else: try: movie_money = int(movie_money_list[0]) except: movie_money = int(movie_money_list[0][0:-1]) # 将数据整合成json格式 movie_dict = { 'movie_time': movie_time, 'movie_name': movie_name, 'movie_score': movie_score, 'movie_country': movie_country, 'movie_actors': movie_actors, 'movie_money': movie_money, } result.append(movie_dict) return result # 最终数据 def perfect_data(movie_data, submitter): mysql_insert_data = [] for movie in movie_data: movies_tuple = ( movie["movie_name"], movie["movie_time"], movie["mov
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











