







文章目录
一.渗透测试流程
- 信息收集(DNS信息、路由关系、电子邮件、电话、所有人)
- 目标识别(网络种有哪些联网设备以及通信地址)
- 服务枚举(找到开放的端口及端口上提供的服务)
- 漏洞映射(通过手动或工具发现漏洞)
- 漏洞利用(在可接受范围内利用漏洞进行一些操作)
- 权限提升(获取更高权限,尝试进一步攻击及漏洞发现)
- 访问维护(埋后门,维护测试人员的访问权限)
- 文档报告(提交给客户)
二.扫描与信息收集
1. DNS信息收集
站长之家 : whois查询,输入域名进行查询
kali系统查询:命令行输入whois 域名 得到信息 ,信息较不直观 。
2.子域名查询
对一个域名进行查询,看看他有没有子域名,从而更好的进行测试。网站和子域名挖掘机:基于字典,需要丰富完善不同前缀,枚举检测。
3.NDS2IP
- 查询IP,可以通过ping域名方式获得。
- 站长之家也可以获得,得到IP更详细,通过不同服务器访问,得到大致位置。
- nslookup 域名
- dig 域名
- dnsenum 域名
4.nmap测试
测试服务器所在局域网情况(服务器有哪些设备,开放了什么端口端口),防止一台服务器被攻陷,再延续到局域网其他服务器,nmap -sp 地址。 nmap -O 查询这一网络中每一台设备是什么系统 。
5. web漏洞扫描
AWVS ——new scan 输入网站地址,得到所有漏洞的信息,点击相应漏洞,右侧出现漏洞详情,整理后可汇总为 漏洞文档报告发送给客户。
三.sql注入
1.万能密码
1' or '1'='1
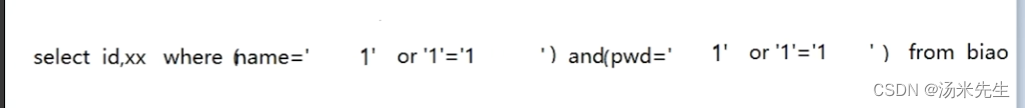
2.其他sql注入方式
- get注入
- 联合查询 :先添加一个变量 ,变量值后面加单引号(报错),然后注释后方命令,用order by确定字段数,再用union select 12 3…进行 联合测试查询,把id变量值改为一个不存在的值(-1),把联合查询的值显示出来,找到显示位置(1,2,3)。
- 报错注入
- 布尔盲注
- 延时注入
- 堆叠查询
- POST注入 : url不显示,用bp抓包,在抓包工具中进行sql注入。
- COOKIE注入:先用bp抓包,修改cookie=值 中的值
- HTTP头注入: 同上
- base64注入:如果cookie中的值不属于用户名,那可能就是base编码了,需要用base64解码。
- 宽字节注入:自动加转义字符/,在/前后加上%凑成汉字,对照ascall数对照gbk表,找到是什么汉字,就这sql语句的对应位置加上什么汉字。
- 文件读写
3.SQLmap
sql注入的自动化方式
get方式
sqlmap -u ‘url’ : 检测漏洞类型,方式
sqlmap -u ‘url’ --dbs: 查询目标服务器的数据库
sqlmap -u ‘url’ -D ’数据库名称‘ --tables: 查询目标服务器的指定数据库的表
sqlmap -u ‘url’ -D ’数据库名称‘ -T ‘表名’ --columns: 查询目标服务器的指定数据库的表的属性名
sqlmap -u ‘url’ -D ‘数据库名称’ -T ‘表名’ -C ‘属性名,属性名’ --dump: 查询目标服务器的指定数据库的表的属性名 中的内容 ,可选择攻击否,得到内容一般是md5加密的,需要解码。
post方式
抓包,得到请求报文,复制请求报文,粘贴到一个新建txt文件中。
然后再使用sqlmap - r ‘请求报文文件名’ 后面命令同get一样。
四.xss攻击
通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。
当用户输入的内容能在网页中原模原样的显示出,这样就有可能存在xss漏洞。
1.反射性xss
当网站使用的是get请求,可通过修改url来进行xss攻击,但这种攻击需要将完整攻击的url发送给用户才能造成攻击,是临时性的攻击。
2.存储型xss
比如网站留言板,当留言板输入script代码,命令被存入数据库当作,那么当用户查看留言板的时候,就会执行 script代码,从而形成网站攻击,这种是长期的。
3.DOM型xss
在页面中构造新的DOM元素,之后由DOM元素触发JS命令。
4.xss过滤绕过
- 如果网站禁止script,那就可以改成大写,或者大小写混合的方式进行绕过过滤。
- 如果禁用 单引号,可用双引号,如果禁用双引号,可用/。
- 禁用空格时空用 \ 代替
- 禁用各种大小写混合的script时 可在script中间加Tab制表符和回车换行符 ,也可以使用 ASCII码表 中数字代替字母。
5.xss平台
五. WebShell
所谓Shell,指的是命令解释器。以Web形式进行通信的命令解释器就是WebShell。
通过WebShell可以对Web服务器进行控制,因此WebShell属于木马的一种。
webShell接收来自于浏览器的命令,然后在Web服务器上运行。WebShell本质上来讲就是一个网页脚本文件。
1. WebShell使用方法
- 将WebShell上传到服务器
- 通过浏览器或专用工具访问WebShell
- 通过WebShell发送各种命令
- WebShell在服务器上完成命令的执行
2. WebShell大小马
WebShell分为php,asp,jsp等类型,WebShell文件内容必须有密码。文件代码量大的叫大马,一般功能齐全,上传完WebShell文件后,输入url+文件名就可访问WebShell,输入密码后,可使用大马。代码量小的叫小马 ,一把只有一两行代码,需要借助Cknife(中国菜刀)等软件进行操作。
六. OS命令执行漏洞
system()
exec()
shell_exec()
passthru()
``
七.文件上传漏洞
对上传文件没有限制的时候,为了避免过滤机制,上传的时候会修改后缀,在保存的时候再把后缀名称改回来,这样同样能够实现木马文件的上传。
1.前台过滤绕过
- 上传文件的,利用bp抓包,在抓到的数据包中修改 文件后缀
- 上传文件时,打开开发者页面,把过滤元素删掉,直接上传。
2.MIME类型过滤绕过
同样通过bp抓包,修改数据包MIME类型。
3.文件内容过滤绕过
可用将图片和木马文件利用copy命令合并为一个合法后缀文件 ,上传文件后,后前再执行木马文件
4.黑名单绕过
将某些文件格式加入上传黑名单。
这时候可以使用格式变体,
php: php2 、php3、 php5、 phtml
asp: aspx 、ascx、 ashx、asa、cer
5.htaccess攻击
htaccess是一种文件格式,来告诉apache服务器以什么格式解析某类文件,这就可以结合前面的所学,先上传一个合法文件再上传htaccess文件,再次访问文件,文件便会以新的格式被执行。
6.文件解析漏洞
如果apache遇到一个不认识的文件后缀名,会往前读取,直到找到一个认识的拓展名来解析文件。
7.文件包含漏洞
实现文件包含的命令
include:可重复包含,出错时显示错误提示,不影响后续语句执行。
include_once:重复内容只能包含—次,出错时显示错误提示,不影响后续语句执行。
require:可重复包含,出错时显示错误提示,后续语句不予执行。
require_once :重复内容只能包含一次,出错时显示错误提示,后续语句不予执行。
利用文件包含,可以获取服务器其他文件内容,当获取到敏感内容,便会对服务器造成攻击。
八.业务逻辑漏洞
业务逻辑漏洞是一种设计缺陷、逻辑缺陷,表现为设计者或开发者在思考过程中做出的特殊假设存在明显或隐含的错误。攻击者会特别注意目标应用程序采用的逻辑方式,设法了解设计者与开发者做出的可能假设,然后考虑如何攻破这些假设。
九.CSRF漏洞
CSRF,全称: Cross-site request forgery,即跨站请求伪造。它是一种挟制用户在当前已登录的web应用程序上执行非本意的操作的攻击方法。
CSRF 利用的是网站对用户网页浏览器的信任。
十.服务器提权
- 查看没有安装补丁对应的漏洞
- 上传漏洞对应的提权工具
- 利用提权工具最高权限,创造一个用户。
- 将用户提高到最高权限。
- 查看开放端口
- 根据端口可进行攻击
十一.MSF
Metasploit就是一个安全漏洞检测工具。















 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











