







目录
Antlr是什么?
ANTLR(另一种语言识别工具)是功能强大的解析器生成器,用于读取,处理,执行或翻译结构化文本或二进制文件。它被广泛用于构建语言,工具和框架。ANTLR从语法中生成一个解析器,该解析器可以构建和遍历解析树。
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files. It's widely used to build languages, tools, and frameworks. From a grammar, ANTLR generates a parser that can build and walk parse trees.
Antlr能干什么?
ANTLR能够根据用户定义的语法文件自动生成词法分析器和语法分析器,并将输入文本处理为语法分析树。这一切都是自动进行的,所需的仅仅是一份描述该语言的语法文件。
ANTLR自动生成的编译器高效、准备,能够将开发者从繁杂的编译理论中解放出来,集中精力处理自己的业务逻辑。ANTRL4引入的自动语法分析树创建与遍历机制,极大地提高了语言识别程序的开发效率。时至今日,仍然是Java世界中实现编译器的不二之选,同时,它也对其他编程语言也提供了支持。
典型应用如下:
1、编程语言处理
识别和处理编程语言是 Antlr 的首要任务,编程语言的处理是一项繁重复杂的任务,为了简化处理,一般的编译技术都将语言处理工作分为前端和后端两个部分。其中前端包括词法分析、语法分析、语义分析、中间代码生成等若干步骤,后端包括目标代码生成和代码优化等步骤。
Antlr 致力于解决编译前端的所有工作。使用 Anltr 的语法可以定义目标语言的词法记号和语法规则,Antlr 自动生成目标语言的词法分析器和语法分析器;此外,如果在语法规则中指定抽象语法树的规则,在生成语法分析器的同时,Antlr 还能够生成抽象语法树;最终使用树分析器遍历抽象语法树,完成语义分析和中间代码生成。整个工作在 Anltr 强大的支持下,将变得非常轻松和愉快。
2、文本处理
当需要文本处理时,首先想到的是正则表达式,使用 Anltr 的词法分析器生成器,可以很容易的完成正则表达式能够完成的所有工作;除此之外使用 Anltr 还可以完成一些正则表达式难以完成的工作,比如识别左括号和右括号的成对匹配等。
传统解析器工作原理是什么?
如果一个程序能够分析计算或者执行语句,我们就把它称之为解释器(interpreter)。解释器需要识别出一门特定的语言的所有的有意义的语句,词组和子词组。识别一个词组意味着我们可以将它从众多的组成部分中辨认和区分出来。
比如我们会把sp=100;识别成赋值语句, 这意味着我们能够辨识出sp是被赋值的目标,100则是要被赋予的值。我们也都知道我们在学习英语的时候,识别英语语句,需要辨认出一段对话的不同部分,例如主谓宾。在识别成功之后,程序还能执行适当的操作。
识别语言的程序被称为语法分析器(parser)或者句法分析器(syntax analyzer),syntax是指约束语言中的各个组成部分之间关系的规则。grammar是一系列规则的集合,每条规则表述出一种词汇结构。ANTLR就是能够将其转成如同经验丰富的开发者手工构建的一般的语法分析器(ANTLR是一个能够生产其他程序的程序)
1、语法解析器
语法解析器是传统解析器重要组件,语法解析器工作流程包括词法分析和语法分析两个阶段。
词法分析,主要负责将符号文本分组成符号类tokens,把输入的文本转换成词法符号的程序称为词法分析器(lexer);
语法解析,目标就是构建一个语法解析树。语法解析的输入是tokens,输出就是一颗语法解析树。
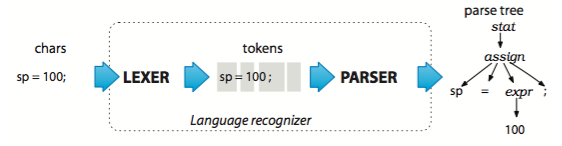
语法分析示例
语法分析树的内部节点是 词组名,这些名字用于识别它们的子节点,并可以将子节点归类。根节点是比较抽象的一个名字,在这里是 stat(statement)。
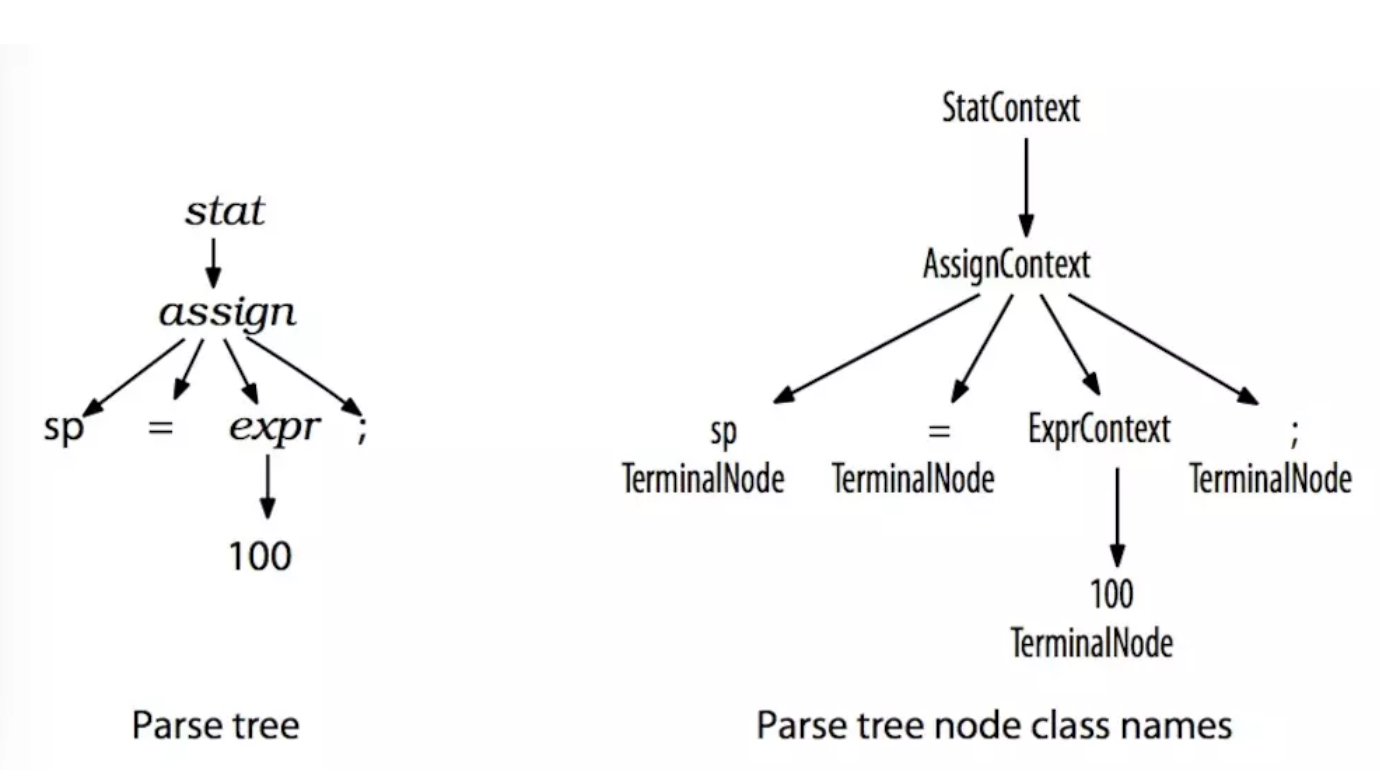
2、解析方法
根据推导策略的不同,语法解析分为LL与LR两种:LR自低向上(bottom-up)的语法分析方法;LL是自顶向下(top-down)的语法分析方法。两类分析器各有其优势,适用不同的场景,很难说谁要更好一些。普遍的说法是LR可以解析的语法形式更多,LL的语法定义更简单易懂。Antrl就是一种自顶向下的解析器;
Antrl 语法规则文件
以一个计算器的规则文件做示例:
grammar Cal;
prog: stat+; //一个程序由至少一条语句组成
/*为了以后的运算的方便性,我们需要给每一步规则打上标签,标签以”#”开头,出现在每一条规则的右边。打上标签后,antlr会为每一个规则都生成一个事件*/
stat: ID'='expr ';'#Assign //变量赋值语句
|'print''('expr ')'';'#printExpr //输出语句
;
expr: expr op=('*'|'/') expr #MulDiv //表达式可以是表达式之间乘除
| expr op=('+'|'-') expr #AddSub //表达式可以是表达式之间加减
| NUM #NUM //表达式可以是一个数字
| ID #ID //表达式可以是一个变脸
|'('expr ')'#parens //表达式可以被括号括起来
;
MUL:'*';
DIV:'/';
ADD:'+';
SUB:'-';
ID: [a-zA-Z][a-zA-Z0-9]*; //变量可以是数字和字母,但必须以字母开头
//负数必须要用"()"括起来
NUM: [0-9]+ //正整数
|'(''-'[0-9]+ ')'//负整数
| [0-9]+'.'[0-9]+ //正浮点数
|'(''-'[0-9]+'.'[0-9]+ ')'//负浮点数
;
WS: [ \t\r\n] -> skip; //跳过空格、制表符、回车、换行
Antlr文法概念中的一些关键概念。文法由一组描述语法的规则组成。其中包括词法与语法规则。语法规则是以小写字母组成。如prog,stat。词法规则由大写字母组成。如ID:[a-z A-Z]+。通过使用 | 运算符来将不同的规则分割,还可以使用括号构成子规则。
ANTLR两种遍历分析树的机制
默认情况下,ANTLR使用内建的遍历器访问生成的语法分析树,并为每个遍历时可能触发的事件生成一个语法分析树监听器接口 (ANTLR generates a parse-tree listener interface) 。除了监听器的方式,还有一种遍历语法分析树的方式:访问者模式(vistor pattern);
Parse-Tree Listeners
为了将遍历树时触发的事件转化为监听器的调用,ANTLR提供ParseTreeWalker类。我们可以自行实现ParseTreeListener的接口,在其中填充自己的逻辑。ANTLR为每个语法文件生成一个ParseTreeListener的子类,在该类中,语法的每条规则都有对应的enter方法和exit方法。
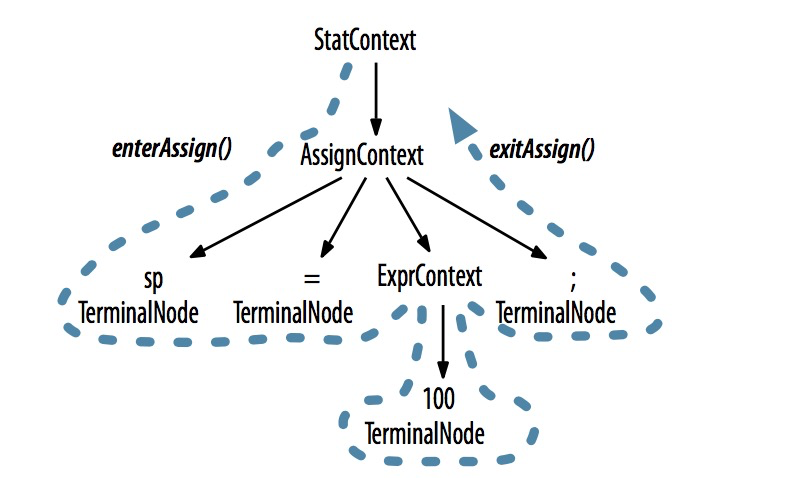
层次遍历(先序遍历)访问
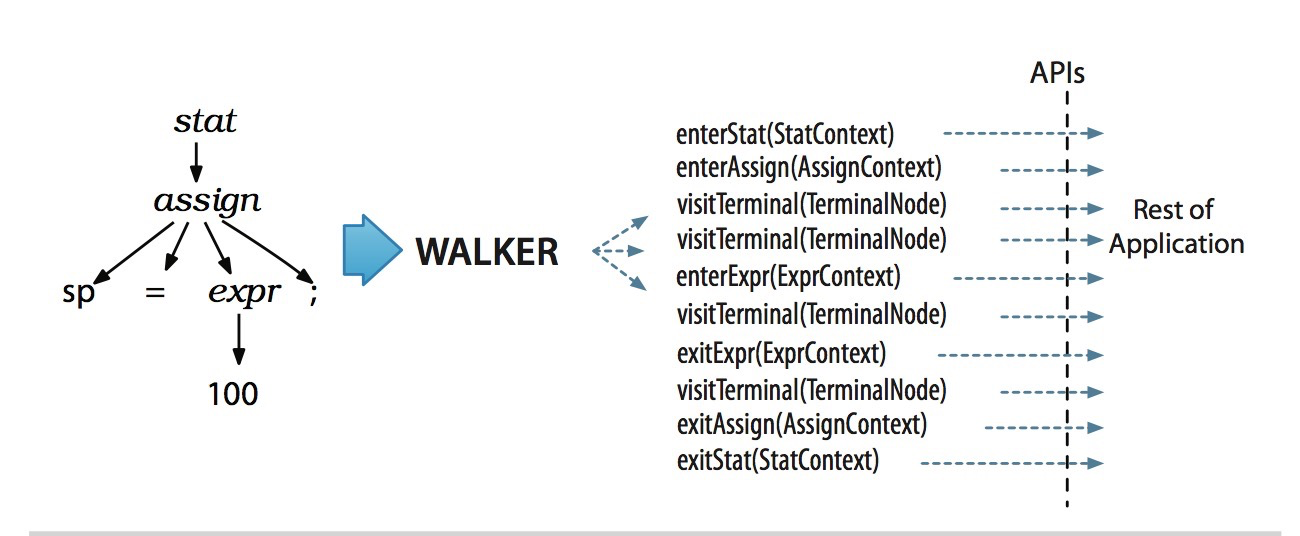
层次遍历(先序遍历)访问
监听器方式的优点在于,回调是自动进行的。我们不需要编写对语法分析树的遍历代码,也不需要让我们的监听器显式地访问子节点
Parse-Tree Visitors:
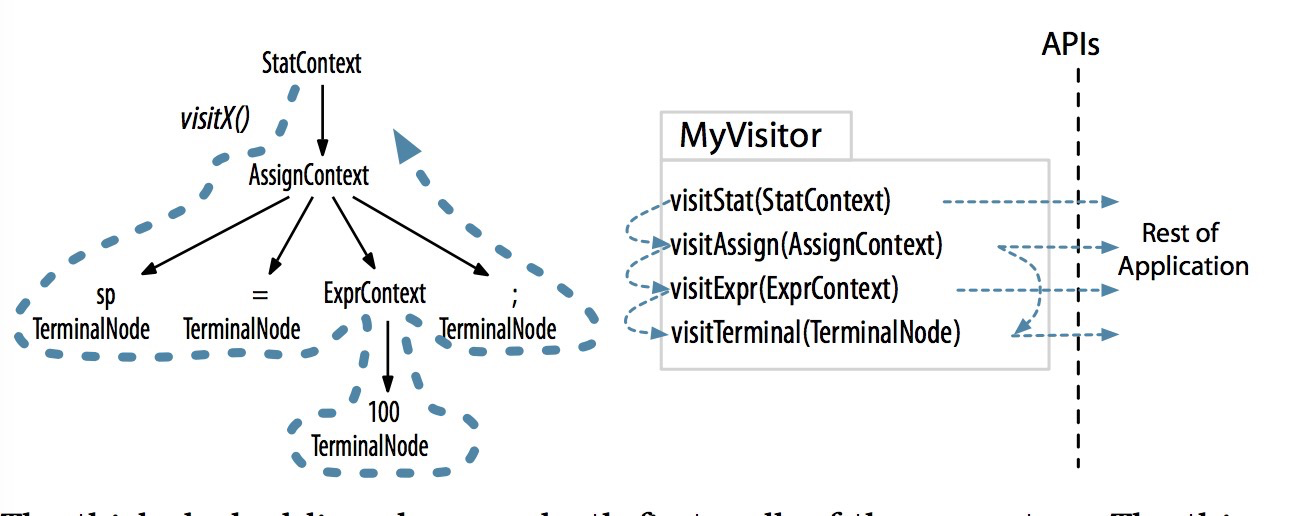
有时候,我们希望控制遍历语法分析树的过程,通过显式的方法调用来访问子节点。语法中的每条规则对应接口中的一个visit方法。
代码demo
ParseTree tree = ... ;// tree is result of parsingMyVisitor v =newMyVisitor();v.visit(tree);
ANTLR内部为访问者模式提供的支持代码会在根节点处调用visitStat方法,接下来,visitStat方法的实现将会调用visit方法,并将所用的子节点作为参数传递给它,从而继续遍历的过程;
Parse-Tree Visitor
为了更好的使用访问者模式我们用以下针对每个规则加了标签的语法文件来说明:
grammar LabeledExpr;//rename to distinguish from Expr.g4
prog:stat+ ;
stat : expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr : expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
|'('expr')' # parens
;
MUL :'*'; //assigns token name to'*'used aboveingrammar
DIV :'/';
ADD :'+';
SUB :'-';
ID : [a-zA-Z]+ ;//match identifiers
INT : [0-9]+ ;//match integers
NEWLINE:'\r'?'\n';//returnnewlines to parser (isend-statement signal)
WS : [ \t]+ -> skip ;//toss out whitespace














 3253
3253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









