









文章目录
前言
HashMap可以说是一个经常被谈论到的集合类了,笔者也一度考虑是否要写这篇文章。毕竟做源码分析、谈论过HashMap实现的人也很多了。不过为了在未来的文章中更好的讲解ConcurrentHashMap,笔者还是决定为其写一篇基础性的前置知识文章。
HashMap是什么?
万变不离其宗,要理解HashMap的原理和实现,我们必须要知道HashMap是个什么东西。
HashMap是jdk java.util包下的一个集合类。主要是利用散列表(HashTable) 这个 数据结构 来实现 Map接口。
和ArrayList与LinkedList一样,都是用某种特定的技术去实现某个接口,比如这里的List接口前者用数组实现,后者用链表实现。同样实现了Map接口的兄弟类也是存在的,那就是利用 平衡二叉搜索树(BBST) 来实现的 Map接口的 java.util.TreeMap。
所以不难看出,HashMap有两个关键词:散列表 和 Map接,那么我们分别来讲解一下这两个概念。
Map接口
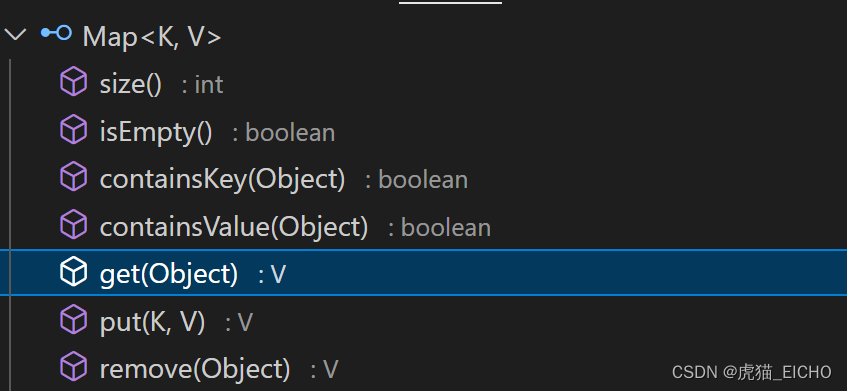
Map接口大家应该都不陌生,大部分编程语言里都提供Map或Dictionary功能,其核心功能是提供键值对(Key-Value Pair)的增删改查。下面截图截取了部分Map接口的方法,其中核心方法有:
- get(Object) : 数据查询
- put(K, V):数据增改
- remove(Object):数据删除
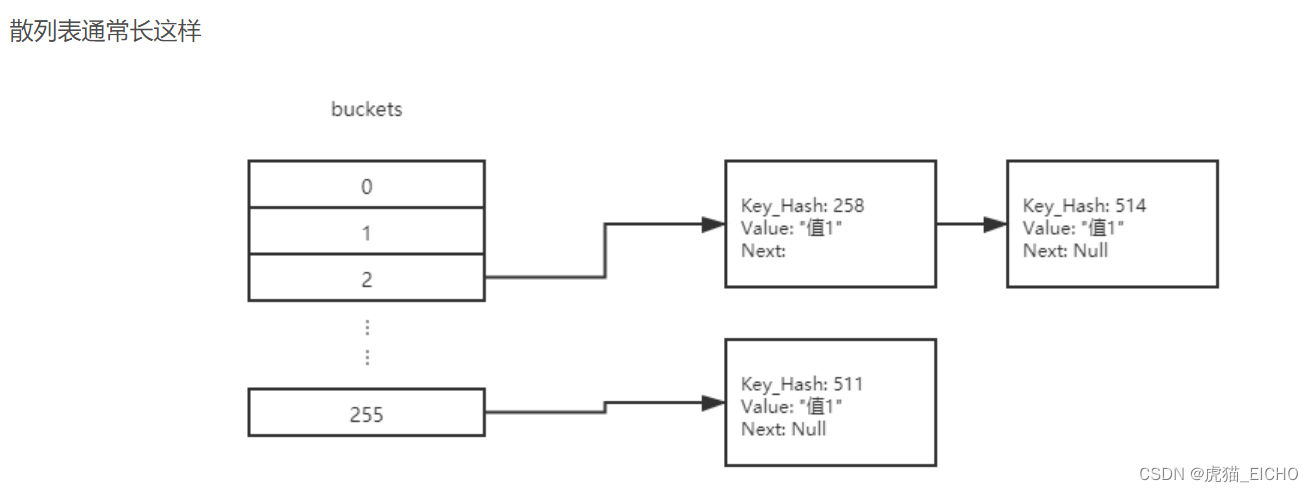
散列表(HashTable)
HashMap的Hash和ArrayList的Array一样,是取自其依赖的底层技术:散列表(HashTable)。散列表的基本思想是把不同Key的哈希值通过取模给放到不同的哈希槽(Hash Slot)里存放。这样下次查询的时候可以再通过哈希值取模快速找到存放数据的哈希槽。这样能大大加快查找和插入数据的效率。
试想一下,假设你有100万条数据,1万个哈希槽,运气很好每个哈希槽平均分到100个数据。这样如果你通过哈希值取模只需要O(1)的时间复杂度就能找到对应的哈希槽,而最坏的遍历整个哈希槽也不过花费O(n)的时间,这里n是100。当然JDK对哈希槽的存储查询还做了优化,肯定不是O(n)的复杂度,提一个关键词:树化,这个我们后面的章节再讨论。
这里笔者也只是简单的介绍了以下散列表是什么。如果想详细了解散料表的,可以看笔者之前写的这篇文章:《数据结构之 - 散列表(Hash table)》
HashMap的扩容机制
HashMap作为一个容器类,绕不开的就是如何进行扩容。那么如何进行扩容这个事儿呢,也就是我们一直提到的扩容机制,亦或是可以理解为扩容策略。
扩容机制?扩谁的容?
对于HashMap这个容器类来说,我们前面也提到了,其内部依赖的数据结构是散列表(HashTable)。散列表本本质是一个数组(一堆哈希槽)。所以其实扩容的中心思想也很简单,对于HashMap来说,扩容的本质就是增加散列表的大小(增加哈希槽数量)。
HashMap的容量(Capacity)属性
既然涉及到扩容(扩展容量),就不得不提HashMap的容量(Capacity)这个属性了。
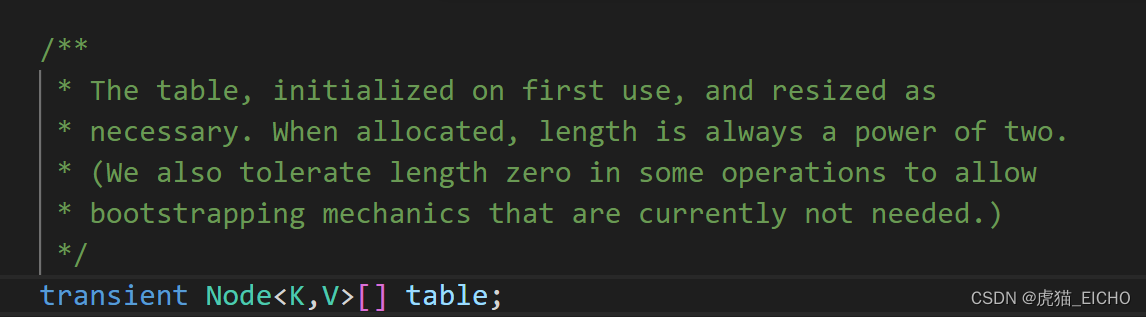
在HashMap中,容量这个属性是由table这个Node数组来保持的。如下图所示,如果想获取容量信息那么直接通过table.length 获取即可,但也因为table这个数组是懒汉初始化的,有可能为null,需要做null判定。

前面我们提到table是懒汉初始化的,意味着在HashMap构造方法里是不会直接去申请table所需内存的。
那么如果我们通过HashMap的构造方法指定了 初始容量(initialCapacity) 会发生什么呢?
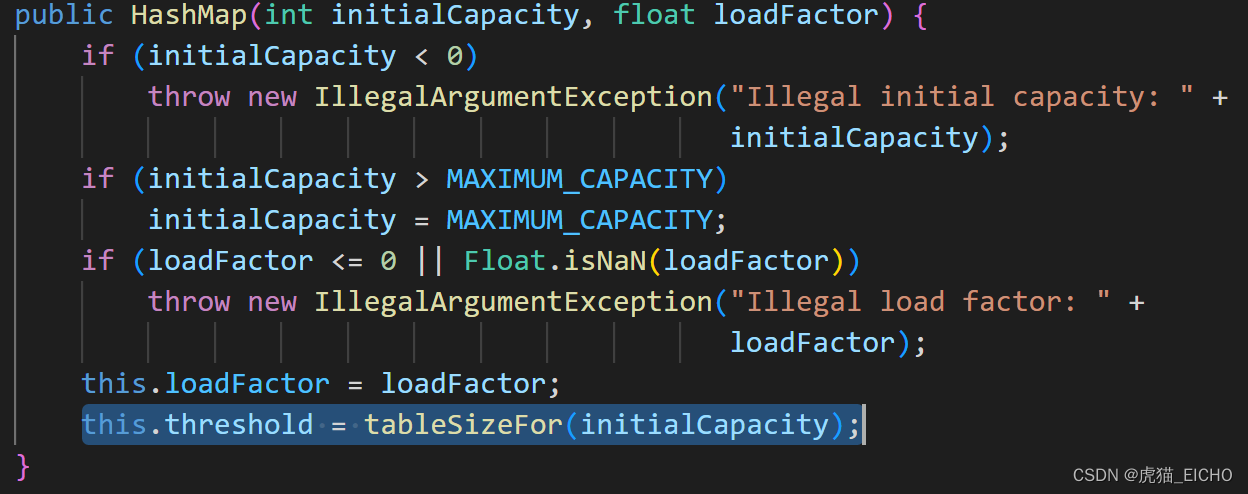
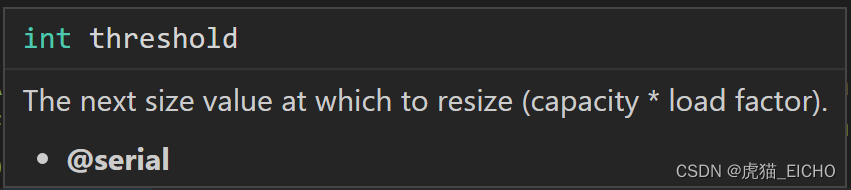
可以看到我们的构造方法利用 tableSizeFor(int) 这个方法去计算了一个容量值存放到了threshold属性里。
而这个属性呢,一般是代表触发下一次扩容的阈值(the next size value at which to resize),这个值一般是容器 x 扩容因子(capacity * load factor)。但因为懒汉初始化,在第一次申请table数组内存之前,被临时征用用于存储初始化容量信息,也就是第一次申请table数组的大小。
而tableSizeFor(int)方法,作为计算容量的方法,一定会返回一个2的N次方的容量值(Returns a power of two size for the given target capacity)。
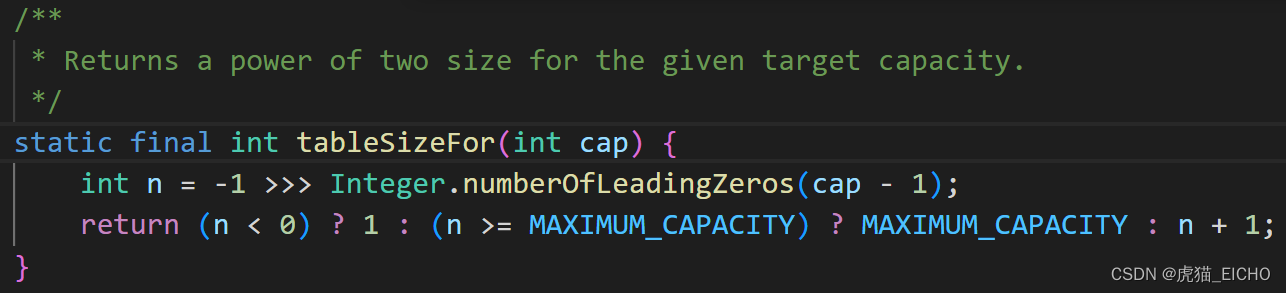
对位运算不熟悉的朋友们呢,可以这么理解 -1 的二进制是 0b11111111_11111111_11111111_11111111。上面的运算是右移(容器减一)的先导零(Leading zero)次,笔者做了个表来方便大家理解。
| cap | cap - 1 | 先导零 | n | 返回值 |
|---|---|---|---|---|
| 16 (0b00000000_00000000_00000000_00010000) | 15(0b00000000_00000000_00000000_00001111) | 28个 | 15 | 16 |
| 20 (0b00000000_00000000_00000000_00010100) | 19(0b00000000_00000000_00000000_00010011) | 27个 | 31 | 32 |
| 31 (0b00000000_00000000_00000000_00011111) | 30(0b00000000_00000000_00000000_00011110) | 27个 | 31 | 32 |
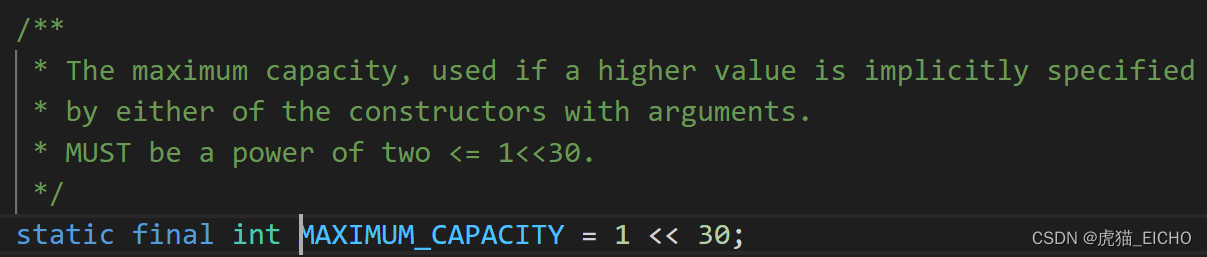
可以看出,我们在构造器中设置的initialCapacity值最终都会变成其最匹配的2的N次方的值。当然如果值大于最大容量(MAXIMUM_CAPACITY)限制则会返回MAXIMUM_CAPACITY,这个值是2的30次方,大约是10亿多,也就是实际上我们HashMap的容量一定是2的N次方。
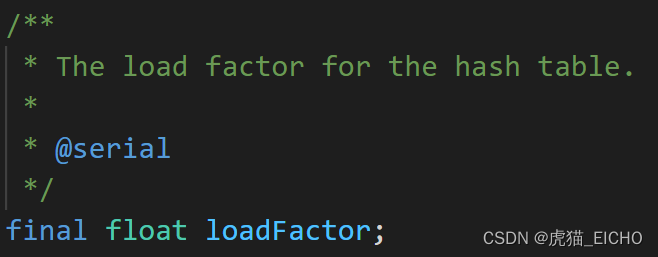
HashMap的扩容因子(load factor)属性
HashMap只有在达到某种条件下,才会触发扩容处理,而这个条件就和扩容因子有关。
前面的章节我们提到了threshold(扩容阈值)属性,这个属性的值则是通过 capacity * loadFactor 这个公式来计算出来的,这个在我们的resize()方法中能够看到,笔者截取其中一段:
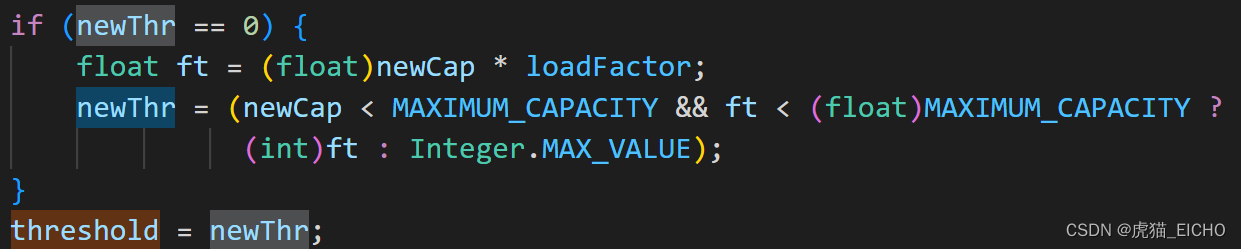
可以看到这段代码:threshold = newThr = ft = newCap * loadFactor;
在具体扩容的判定时,当 size 大于扩容阈值就会触发扩容。size呢则是元素(键值对)的个数了。也就是说假设你有64个哈希槽,你只用了1个哈希槽,里面有超过48个元素(默认扩容因子计算得出阈值是48)时,也会触发扩容,而不是说你用了48个哈希槽才会触发扩容。

HashMap为我们提供了默认的扩容因子,其值为 0.75f 。也就是说如果你不设置扩容因子使用默认扩容因子时,当你HashMap内键值对数量超过容量的 75% 时就会触发扩容。

HashMap的树化机制
在了解HashMap是如何实现扩容之前我们还需要了解,HashMap的树化机制。前面我们简要提到了哈希槽(Hash Slot)的概念,对于Key的哈希值取模后,会把数据放到对应的哈希槽里。而这个哈希槽,也需要用某种数据结构来存储键值对数据。
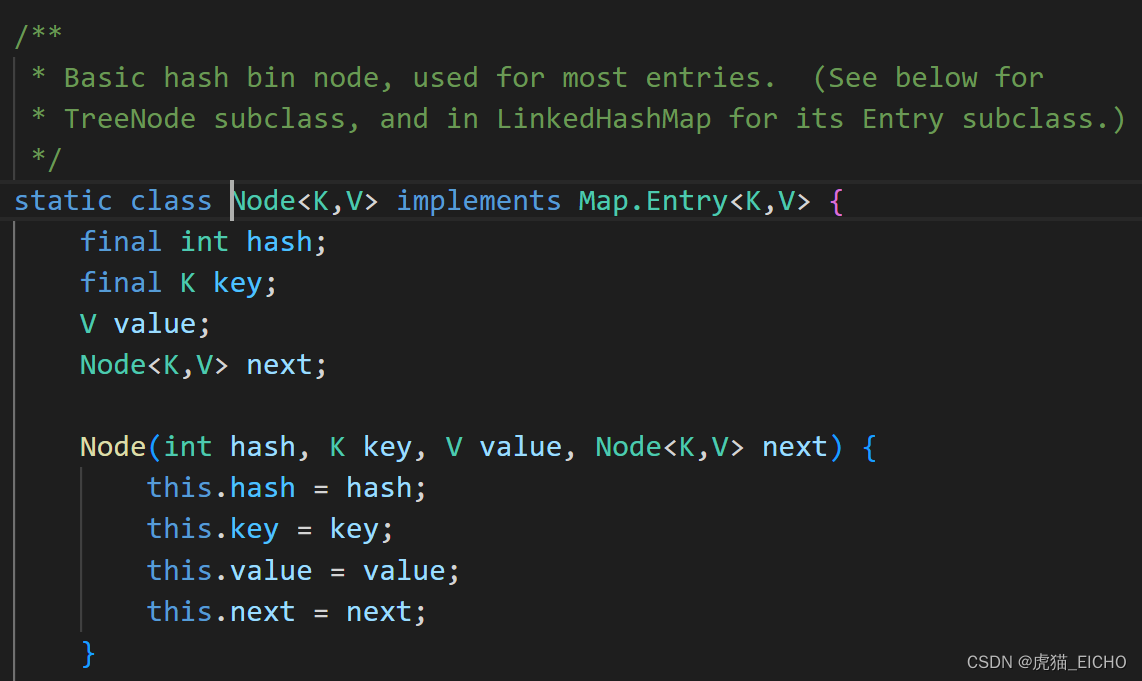
在哈希槽内数据量比较小的时候,HashMap会用链表来存储同一个哈希槽内的数据。链表的Node类定义如下,不难看出其是一个单向链表(仅有next指针):
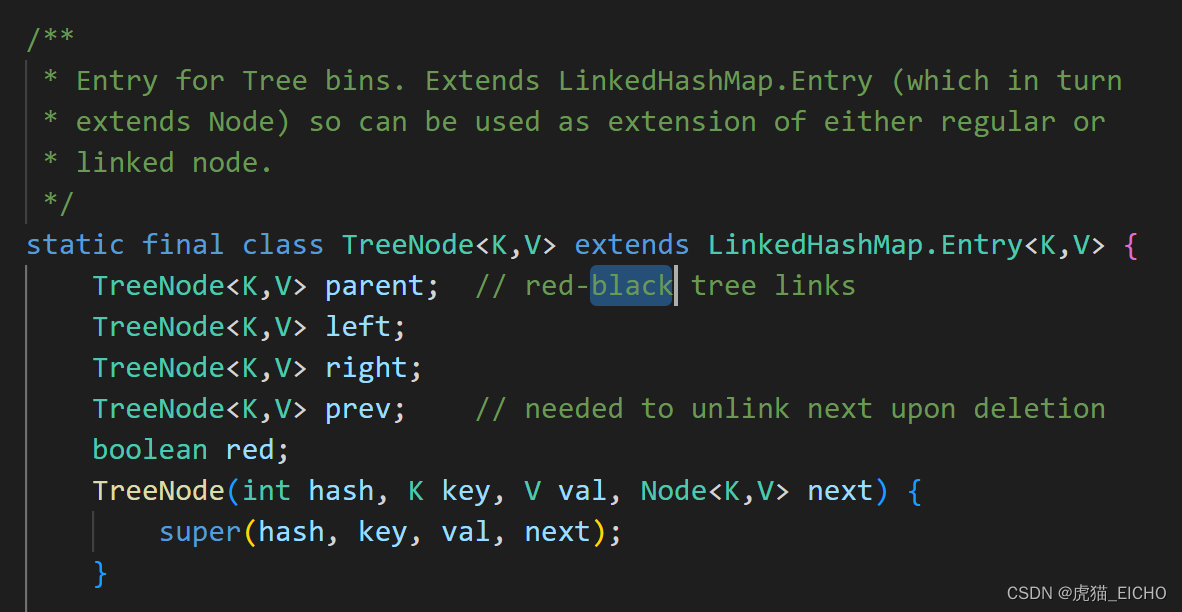
而哈希槽内数据比较大的时候,HashMap会用红黑树(一种平衡二叉搜索树) 来存储哈希槽内的数据,以便提升数据查询和插入等操作的性能(从O(n)优化到O(log n))。树化后的TreeNode类定义如下:
触发树化机制的条件
和扩容机制一样,触发树化机制也需要有一定的条件。主要是两点,
- 一是哈希槽内数量量需要达到一定规模(槽内数据量(bin count) >= TREEIFY_THRESHOLD)。
- 二是整个HashMap的容量需要达到最小树化阈值(Capacity >= MIN_TREEIFY_CAPACITY)
哈希槽内触发树化机制的阈值 TREEIFY_THRESHOLD 的值是 8。也就是当哈希槽内数据量大于等于8时就会触发树化判定机制。
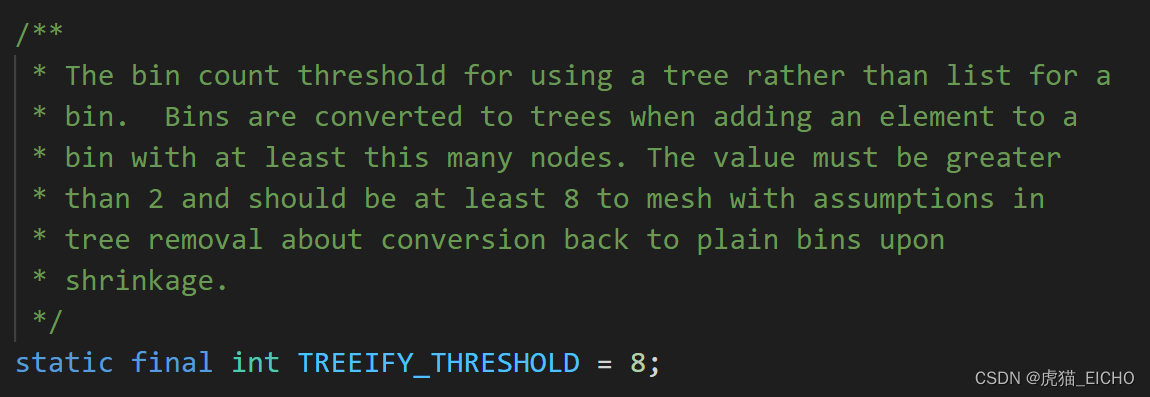
当触发了树化判定机制后,HashMap会检查HashMap容量是否达到最小树化阈值 (MIN_TREEIFY_CAPACITY,值为64),如果达到了这个条件就把当前哈希槽的数据结构从链表树化为红黑树,如果达不到这个条件就会触发扩容。

相关源码如下,如果binCount > 8 (binCount是从0开始计数,实际树化条件是 >= 8)。

在treeifyBin方法(树化判定方法),最初还会进行一次容量条件的检查,容量不达标就会进行扩容(resize),容量达标则进行树化处理。
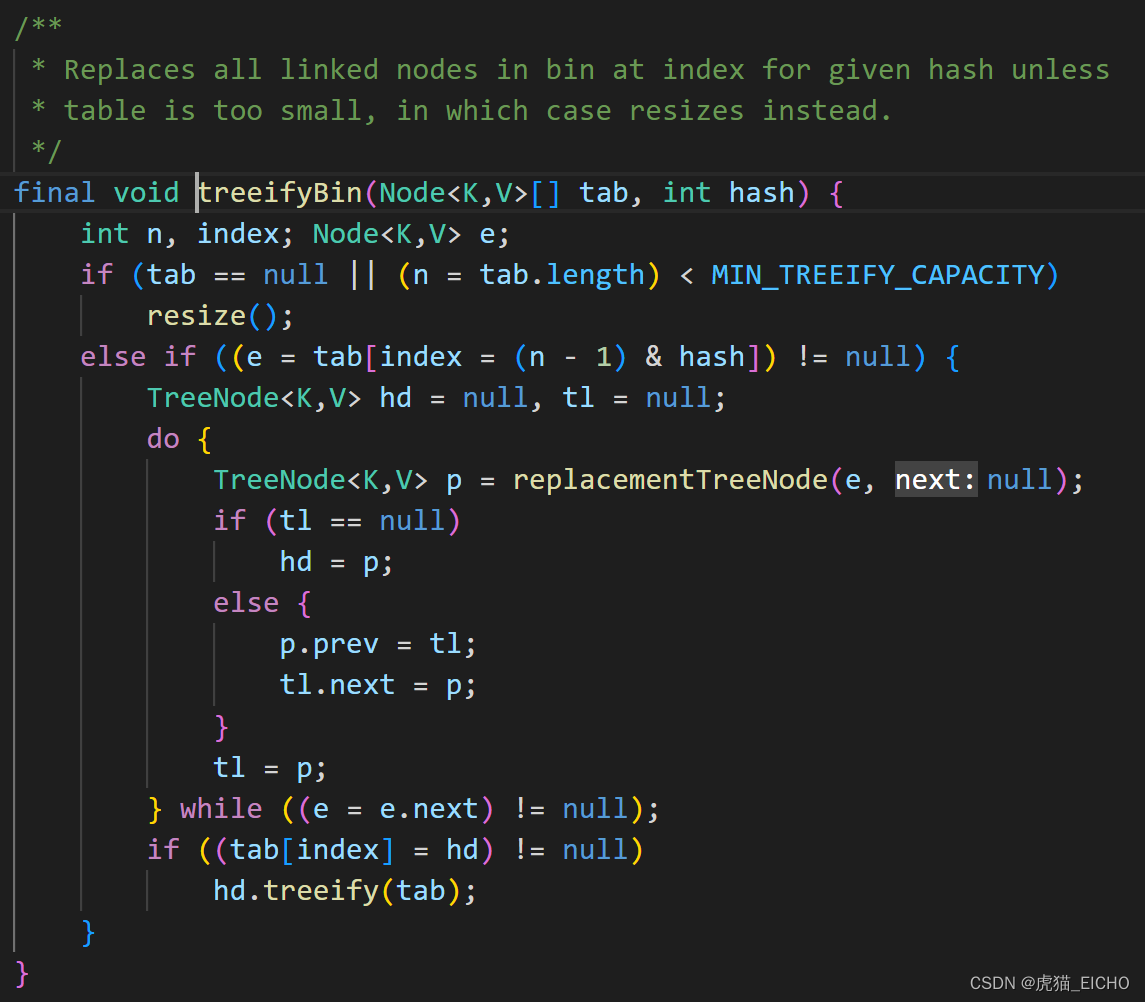
反树化机制
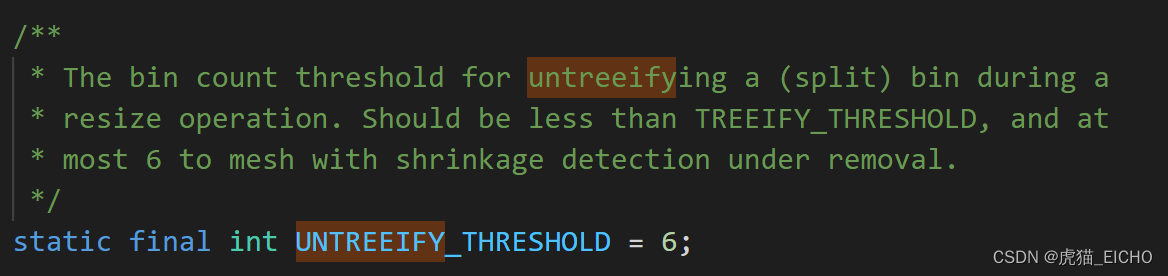
其实除了数据量变大后会有树化机制之外,我们的HashMap里的特定哈希槽里的数据是可以增加也可以减少的(删减数据 或 扩容)。那么当红黑树的数据量减少到一定程度时,也会触发反树化机制。与树化机制类似,也用常量定义了反树化阈值(UNTREEIFY_THRESHOLD),其值为6。
HashMap是如何实现扩容的?
在前面章节我们了解了HashMap扩容相关的关键属性(扩容阈值threshold、容量capacity与扩容因子load factor)、触发扩容的条件(size > threshold)以及树化/反树化机制。现在我们来看一看到底HashMap是如何实现扩容的。
那么其实HashMap扩容的目标其实很简单,就是把内部散列表的大小倍增。倍增了之后哈希槽的数量随之倍增,原本分布在这些老哈希槽内的数据也需要被重新调整至新的哈希槽内。因为哈希槽的数据结构有链表和红黑树两种,倍增后红黑树的大小也大概率会减小,因此伴随着还有反树化处理。
所以实际上扩容就是以下几个处理:
- 新申请一个两倍大数组(下图newTab)用于替换原数组(下图oldTab)。
- 把原数组的链表 或 红黑树数据放到新数组的链表 或 红黑树里。
- 新红黑树数据结构如果数据量太小,则对其做反树化。
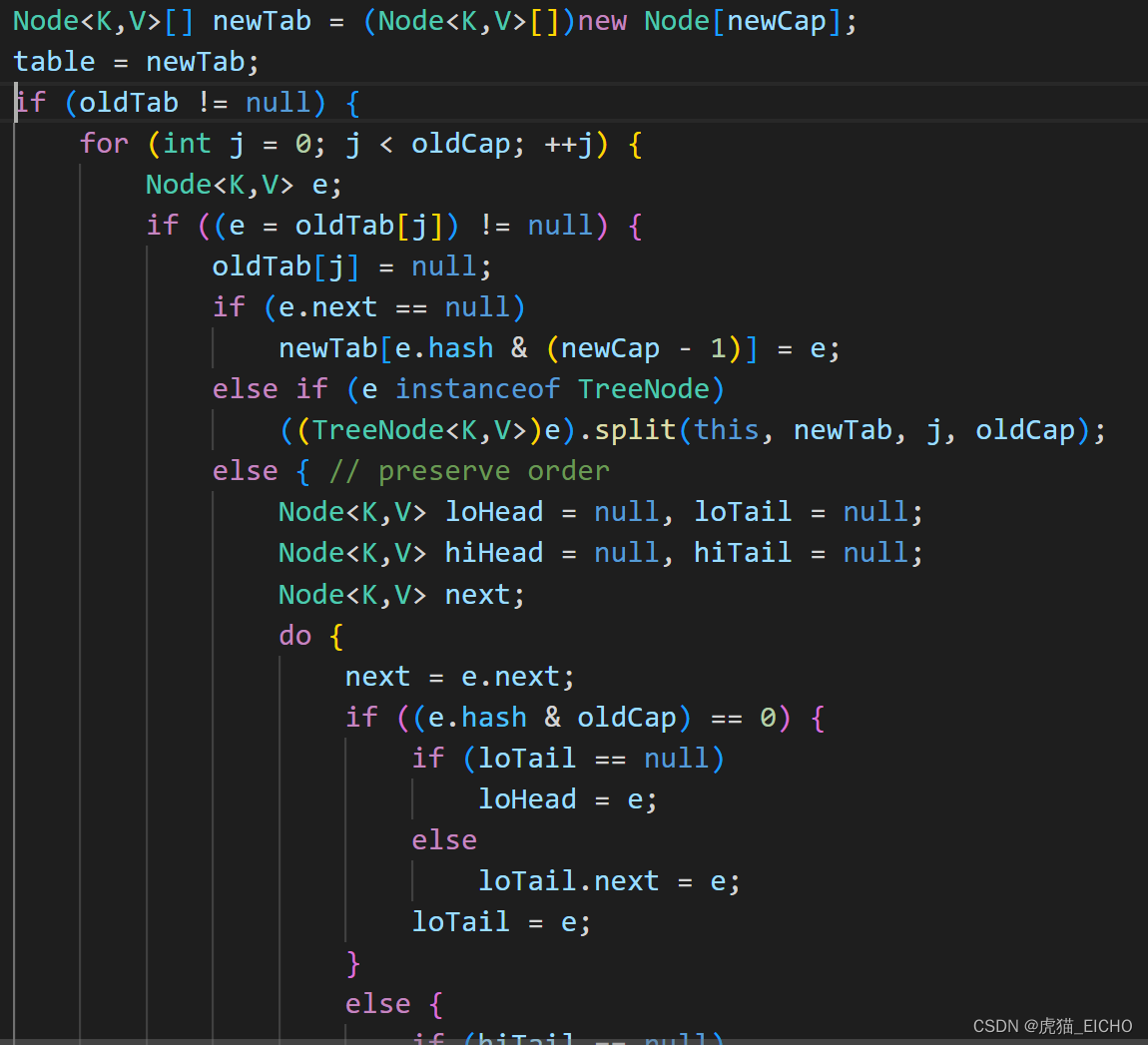
为什么HashMap的容量一定是2的N次方?
这个和HashMap的扩容机制实现有关了,HashMap的实现是倍增。意味着原本容量n的散料表的第i个哈希槽内的数据,倍增扩容为2n大小后,原本第i个哈希槽内的数据一定会落在第i个哈希槽或第i + n个哈希槽内。2的N次方有助于HashMap扩容的简单实现而不用考虑扩容后新哈希槽内数据分配不均,也能避免额外的树化处理开销等,同时链表对于的新哈希槽数据结构一定是链表,红黑树对应的新哈希槽数据结构也一定是红黑树,简化了HashMap的实现代码。
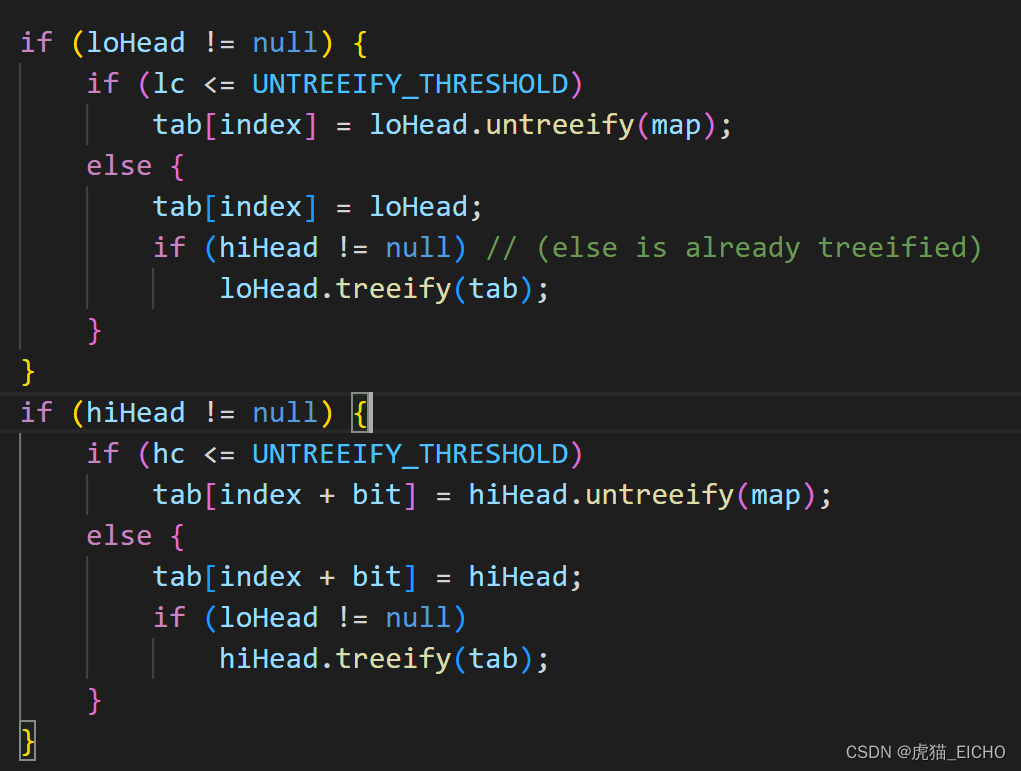
具体可以看下图的newTab[j] 和 newTab[j + oldCap]部分:
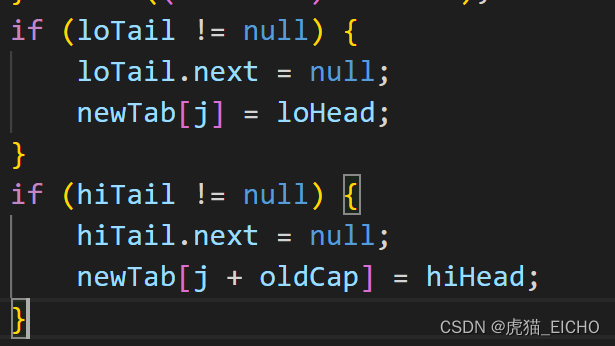
这是链表部分的处理,红黑树部分的处理(tab[index] 和 tab[index + bit])也是一样:
结语
总的来说,HashMap的实现逻辑还是比较简单的,内部是散列表,散列表本质则是数组,散列表数组内的每一个元素都是一个哈希槽,多个哈希值取模后相同的数据会被存储在相同的哈希槽内,为了存储这些数据HashMap使用了链表和红黑树这两种数据结构,它们在数据量变化时通过树化反树化机制来互相转换。而扩容机制则是把HashMap内部的散列表进行倍增的一种处理。
我是虎猫,希望本文能对你有所帮助。(=・ω・=)















 7826
7826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









