







linux select()函数实现分析
int select(int n,fd_set * readfds,fd_set * writefds,fd_set * exceptfds,struct timeval * timeout);
select()函数是linux下实现异步I/O的一种机制,最重要的使用场合是高效的网络编程。在这里不谈论select()
的具体用法,而是看看select()机制的内部实现。
我个人认为把select()看成是建立在linux文件系统的一个库函数更合适,虽然select()的代码位于内核(文件系统部分),但是和内核本身的联系还是很小的。
我们从函数的定义入手,先看看函数的参数,第一个是一个进程内的文件描述符数组最大下标加1,第二个参数实际是一个无符号长整型数组。
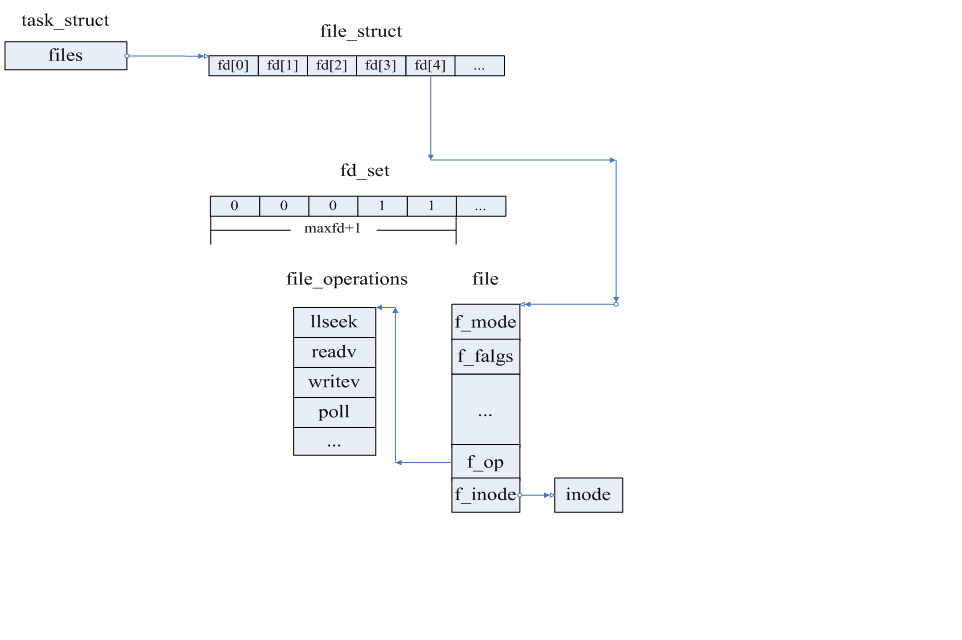
以上的图描述了第一个参数maxfd,和fd_set的作用。file_struct是文件描述符指针数组,0-2分别是输入,输出和出错文件描述符。所以在
你添加第一要监听的描述符的时候,它的下标是3,也就是第四个。select的工作原理是循环的扫描文件描述符,就是从[0,maxfd+1),凡是
fd_set中所对应的位被置 1(最终循环的时候fd_set的结果是后三个参数的合集),select都会调用相应的poll()函数(fd[4]->file->f_op-
>file_operations->poll()),poll是具体文件相关的函数,对于TCP就是tcp_poll().tcp_poll()会返回被监听socket的状态,比如可写或可读
。然后返回相关的状态给应用程序。之后应用程序就可以通过相关的宏来检测文件描述符的状态是否有被改变了。
上图是select()函数的程序执行流程。从中可以看出,select()是先轮循了所有的描述符后才判断时间的,为了比较好的控制select()在循
环中所花费的时间,循环的次数一定不能太大,这也就是最大循环次数被定为1024的原因。
我们总结下select()所存在的一些问题。
1.每次调用时要重复地从用户态读入参数。
fd_set * readfds,fd_set * writefds,fd_set * exceptfds 这三个参数其实都是长整型数组,每次 调用的时候都会从用户空间拷贝
置内存空间。这也是一个比较耗费时间的操作。
2.每次调用时要重复地扫描文件描述符。
其实在很多时候,大部分的文件描述符的状态是没有改变的,但是还是进行了相应的poll()操作,这里也浪费了不必要的时间。
3.每次在调用开始时,要把当前进程放入各个文件描述符的等待队列。在调用结束后,又把进程从各个等待 队列中删除。
对于这点我们可以看看下面的图。task1的开了n个文件。现在它要监听file4-file9,那么操作系统就会把task1连接进要监听的文件的等待
队列中。在阻塞模式下,只要其中一个文件的状态改变,改进程就会被唤醒,投入运行,所以这个时候,又会将该进程从所有的等待对列中移
出。从源代码的执行看,即使是非阻塞模式下,这中情况还是会发生,因为,连入的操作是在文件相关的poll()函数中进行的,而每次循环都
会执行poll().
针对以上的缺点,linux上引入了epoll.(请看下篇)















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









