







 现有多模态谣言检测方法很少考虑图像与文字、内容与背景知识的语义不一致性,且难以处理缺失模态问题。本文提出知识引导的双一致性网络,用两个子网络捕获跨模态和内容 - 知识级别的不一致性,还能处理视觉模态缺失,实验表明该框架性能优于基线。
现有多模态谣言检测方法很少考虑图像与文字、内容与背景知识的语义不一致性,且难以处理缺失模态问题。本文提出知识引导的双一致性网络,用两个子网络捕获跨模态和内容 - 知识级别的不一致性,还能处理视觉模态缺失,实验表明该框架性能优于基线。
Inconsistent Matters: A Knowledge-guided Dual-consistency Network for Multi-modal Rumor Detection
摘要
现有方法很少考虑图像和文字之间的语义不一致性且很少发现帖子内容与背景知识不一致的情况。此外,它们通常假设多种模态的完整性,因此无法处理现实场景中缺失的模态。出于社交媒体中的谣言更可能具有不一致语义的直觉,提出了一种新颖的知识引导的双一致性网络来检测多媒体内容的谣言。使用两个一致性检测子网络来同时捕获跨模态级别和内容-知识级别的不一致性。它还可以在不同的缺失视觉模态条件下实现强大的多模态表示学习,使用特殊的标记来区分具有视觉模态的帖子和没有视觉模态的帖子。对三个公共现实世界多媒体数据集的广泛实验表明,我们的框架在完整和不完整模态条件下都可以优于最先进的基线。
关键词:谣言检测、多模态学习、社交媒体分析
引言
现实世界的例子:文字和图片不匹配,因此跨模态不一致性对于多模态谣言检测很重要。谣言检测也可以使用知识图谱(Konwledge Graph KG)进行指导,但过去方法忽略的内容-知识不一致性。因此在本工作中,利用跨模态一致性和内容-知识一致性来进行多模态谣言检测。

挑战:
① 由于文本、图像和KG数据具有不同的格式和结构,如何将它们整合到统一的框架中来检测谣言
②没有直接的方法来衡量和捕捉上述不一致之处
②有效的检测器预计能够稳健地适应不同的视觉模态缺失模式:训练数据、测试数据或两者中的模态缺失
为解决以上挑战,提出新型知识引导的双重一致性网络(KDCN) 可以同时捕获跨模态层面和内容知识层面的不一致信息。为了验证我们的动机,即不一致对于谣言检测很重要,我们分析了谣言数据集,并观察到上述两种类型的不一致信息在谣言和非谣言帖子之间呈现出统计上的显着区别(详见第 4.3 节)。
根据这一观察,我们的框架主要由两个子神经网络组成:一个是提取图像和文本之间的跨模态差异,另一个是通过测量实体对的 KG 表示来识别帖子内容中实体对的异常共现距离。两个子神经网络紧密耦合,使两个不一致信息来源互补,即使其中一个来源不可用或不可靠,也可以提高谣言检测的鲁棒性。此外,为了使我们的框架能够处理不完整的模式,我们利用伪图像作为补充,并用特殊的标记来表明它不是真实的,简单且可以使我们的框架不改变以与完整模态数据相同的过程处理不完整模态数据,同时在不同的视觉模态缺失情况下提供稳定的性能。
贡献:
-
提出新型的知识引导的双重一致性网络,以同时捕获跨模式不一致和内容知识不一致。它旨在检测具有多模态内容的谣言,但也可以适应视觉模态缺失的情况。
-
第一个揭露谣言帖子往往包含在 KG 上比非谣言帖子更远的实体对。这一观察可以作为区分谣言和非谣言的有用信号。
-
对三个现实世界数据集的广泛实验表明,我们的框架比最先进的基线能够更好地检测谣言。即使在非常严重的缺失情况下,它也有利于在不同的视觉模态缺失模式下提供稳定和鲁棒的性能。
相关工作
1 谣言检测
谣言检测模型依赖于从多模式社交媒体数据中提取的各种特征,包括帖子文本、社交上下文、附加图像和相关知识图谱。因此,我们从以下四个类别回顾现有的工作:基于文本和社交上下文的方法、多媒体方法、知识图谱事实检查和知识增强方法。
1.1 文本和社交上下文谣言检测
大多数谣言检测模型依赖于文本特征。传统的基于机器学习的模型基于以特征工程方式从文本帖子中提取的特征[2]、[15]。最近的研究提出了深度学习模型来捕获高级文本语义,优于传统的基于机器学习的模型。提出了一种基于循环神经网络(RNN)的模型来捕获相关帖子的上下文信息随时间的变化[4]。 [16]提出了一种基于用户注意力的卷积神经网络(CNN)模型,具有对抗性跨语言学习框架,以捕获特定于语言和独立于语言的特征。 [5]提出了一种基于CNN的错误信息识别卷积方法来提取关键文本特征。 [17]提出多通道网络从语义、情感和文体角度对新闻片段进行建模。
社交上下文特征代表用户在社交媒体上的参与度,例如转发和评论行为。社交上下文特征可以提供区分谣言与非谣言的重要线索。 [18]开发了一个句子评论共同注意子网络,利用新闻内容和用户评论来共同捕获重要句子和用户评论作为支持检测结果的解释。 [19]提出了一种基于量子概率的签名注意网络,利用帖子内容和相关评论来检测虚假信息。这两项研究都利用转发和评论内容。 [20]提出了一种基于转发的早期谣言检测模型,将帖子的所有转发视为一个序列。 [21]提出了一种基于图核的混合SVM分类器来捕获高阶传播模式。本研究使用网络结构作为社交上下文特征。然而,社交上下文特征在新闻传播的早期阶段通常是不可用的。
1.2 多模态谣言检测
最近的几个模型开始探索视觉信息的作用。 [22]提出了一种循环神经网络来提取并融合多模态和社会情境特征与注意机制。 EANN [10] 通过利用文本和视觉信息来学习帖子表示,使用对抗性方法来删除特定于事件的特征以使新到达的事件受益。 [11]提出了一种用于谣言检测的多模态变分自动编码器,以从两种模态中学习共享特征。编码器将文本和图像中的信息编码为潜在向量,而解码器则重建原始图像和文本。 [12]通过引入姿态任务设计了多模态多任务学习框架。然而,这些研究并没有多模态信息之间的一致性。虽然 SAFE [9] 和 MCNN [8] 考虑了文本和视觉信息之间的相关性,但我们的工作与他们的工作有所不同,因为我们以不同的方式捕获跨模式的不一致,并对内容和外部知识之间的不一致进行建模。此外,这些研究没有涉及模态缺失问题,这在现实世界的多模态谣言检测中很常见。 COSMOS [23] 专注于一项新任务,即通过将来自两个不同新闻源的图像和两个相应的标题作为输入来预测图像是否被断章取义。如果两个标题引用图像中的同一对象,但语义不同,则表明图像脱离上下文使用,与这项工作有不同的问题设置。
1.3 与 KG 进行事实检查
一些研究[24]、[25]、[26]、[27]从帖子内容中提取结构化三元组(头、关系、尾),并用 KG 中的忠实三元组对它们进行事实检查。这种方法的局限性在于,知识图谱通常不完整或不精确,无法以从帖子中提取的三元组的形式覆盖复杂关系。考虑一个提取的三元组(Anthony Weiner,合作,FBI)有两个具有“合作”关系的实体,其中两个实体在 KG 中都可用,但关系不是 [26]。对于这种情况,结构化三元组方法无法做出可靠的预测。相比之下,我们的方法还是适用的。
1.4 知识增强检测
一些研究使用外部知识来补充帖子内容,以获得更好的谣言检测表征。通过合并医学知识图并通过知识路径传播节点嵌入,学习知识引导的文章嵌入用于医疗保健错误信息检测[28]。多模态知识感知表示和事件不变特征一起学习,形成[13]中的事件表示,并将其输入深度神经网络进行谣言检测。提出了一种知识驱动的多模态图卷积网络(KMGCN)[14]来对文本、图像和知识概念之间的全局结构进行建模,以获得全面的语义表示。 [29]提出了一种实体增强的多模态融合框架,该框架对实体不一致、相互增强和文本互补的相关性进行建模,以检测多模态谣言。 [30]提出了一种图神经模型,通过实体将新闻与知识库(KB)进行比较,以进行假新闻检测。然而,这些方法没有考虑内容知识的不一致。此外,KMGCN 是传导性的,要求推断节点在训练时存在,并且由于图的构建和学习而非常耗时。
2 缺失模态的多模态学习
多模态学习任务中可能会部分缺失模态。例如,由于光照或遮挡问题,在情感识别任务中并不总是能够检测到人脸[31],从而导致模态缺失。该问题的一种解决方案是数据增强,其中通过随机消融输入来模拟缺失的模态情况[32]。另一种常见的解决方案是使用生成方法。给定可用的模态,直接预测缺失的模态[33]、[34]、[35]、[36]。一些研究从这些模态中学习联合多模态表示 [31]、[37]、[38]、[39]、[40]。
大多数现有方法都是针对完整模态确实存在但由于各种限制而无法访问的场景而设计的。然而,对于谣言检测任务,由于根本不存在任何相应的图像,因此视觉模态大多缺失。因此,先前的方法(例如生成方法)可能会产生不必要的计算成本并带来较大的噪声。据我们所知,现有研究尚未涵盖如何解决多模态谣言检测的图像不完整性问题。此外,由于社交媒体上的帖子数量巨大,一种轻量级的方式有望为不同的缺失案例提供卓越而稳健的性能。
理论
1 问题定义
数据集包含两个模态: D = { D f , D t } D=\{D^f,D^t\} D={Df,Dt}, D f = { T i , I i , y i } D^f=\{T_i,I_i,y_i\} Df={Ti,Ii,yi}表示完整模态数据, D t = { T i , y i } D^t=\{T_i,y_i\} Dt={Ti,yi}表示缺失视觉模态数据,可能出现在训练数据或测试数据。
2 架构

框架包含四个组件:①预处理组件用于获得实体和其表示②跨模态一致性子网络用于捕捉每个推文文字和图片之间的一致性③内容-知识一致性子网络用于通过内容和KG之间的实体距离来捕捉一致性④分类层 聚合多种特征进行分类
首先抽取文字/图片的实体并得到其表示,送入内容-知识一致性自网络来得到知识级不一致性特征。同时,对于特定的帖子,引入特殊标记[CMT]作为指示符来确定该帖子是属于模态完整子集 D f D^f Df还是纯文本子集 D t D^t Dt。如果帖子属于纯文本子集,因为它缺乏视觉数据,我们用伪图像补充帖子,使其与跨模态一致性子网络兼容。然后将图像和文本数据以及令牌输入到跨模态一致性子网络中,以产生跨模态不一致特征和模态共享特征。经过上述两个一致性子网络后,所获得的特征被融合并输入分类层以产生最终标签。在以下部分中,我们将详细描述每个组件。
3 多模态帖子预处理
对于文本内容,我们使用实体链接解决方案TAGME2 [41]和Shuyantech3 [42]来提取文本中的歧义实体,并将其分别链接到英文和中文文本的知识图谱中的相应实体。对于视觉内容,我们利用现成的预训练 YOLOv3 [43] 将语义对象提取为视觉单词。检测到的对象(例如人和狗)的标签被视为实体提及。这些提及与 KG 中的实体相关联。
然后,文本模态中的实体链接到 KG 中的实体。在本文中,我们以Freebase作为参考KG。我们选择 Freebase 作为知识源的原因有两个:(1)Freebase 比 Probase 和 Yago 拥有更大规模的实体集,这将有利于谣言检测任务。 (2) 有现成的预训练实体嵌入可以直接被我们的模型使用。从公开可用的 OpenKE6 中获取预训练的实体表示,这些实体表示在 Freebase 上使用 TransE [44] 进行训练。实体表示嵌入维度为 50。因此,我们的模型接受四重输入{文本、图像、实体集、预训练 KG}。
4 跨模态一致性网络
跨模态一致性子网络旨在捕获图像和文本之间的不一致并处理视觉模态缺失问题。它由两个单独的文本和图像编码器、一个用于获得相应模态唯一特征和模态共享特征的分解层以及一个用于产生跨模态不一致特征的融合层组成。
4.1 文字和图片编码
将文本和图像映射到特征表示中。对于文本信息,我们使用 BERT 预训练的初始词嵌入,并利用双向长短期记忆(Bi-LSTM)网络按照[45]中的过程将每个文本序列编码为向量。特别是,它将单词嵌入
w
j
w_j
wj 映射到其隐藏状态
h
j
∈
R
d
0
h_j∈ R^{d_0}
hj∈Rd0 ,其中
w
j
∈
R
d
w
w_j∈ R^{d_w}
wj∈Rdw 表示长度为 M 的单词序列中第 j 个单词的预训练嵌入。我们连接
h
0
→
\overset{\rightarrow}{h_0}
h0→和
h
M
←
\overset{\leftarrow}{h_M}
hM← 以获得文本内容
h
∈
R
2
d
0
h ∈ R^{2d_0}
h∈R2d0 的隐藏状态。之后,我们将文本表示编码为 d 维向量
H
T
H_T
HT :
类似地,我们使用预训练的 CNN 将图像编码为 d 维向量 H ^ I \hat H_I H^I

4.2 缺少视觉形态的伪图像
对于谣言检测任务,源帖子中通常不存在视觉模态,因此根本没有必要生成图像。此外,基于可用的文本模态生成图像将在处理社交网络上的大量帖子时产生大量的计算成本。为了解决这个问题,提出使用带有特殊标记的伪图像来补充这些数据实例。可以在不改变框架架构的情况下解决模态在灵活性方面不完整的问题(缺少训练、测试或两者的模态)。它在效率方面也有优势,因为不需要额外的训练或生成开销。此外,与丢弃模态缺失的数据实例的传统方法不同,它可以充分利用训练数据,从而更好地推广到测试数据。
具体来说,对于纯文本子集 D t = { T j , y j } j D_t = \{T_j, y_j\}_j Dt={Tj,yj}j 中的每个帖子,文本模态的处理方式与第 2 节中描述的模态完整帖子相同。为了解决视觉数据丢失问题,用伪图像填充视觉数据的位置。具体来说,我们使用白色图像(RGB (255, 255, 255 )作为伪视觉数据。为了将其与真实图像区分开,引入了特殊的完整模态token([CMT])。 [ C M T ] = { 0 , 1 } [CMT]=\{0 ,1\} [CMT]={0,1},其中 0 表示帖子来自纯文本子集,1 表示来自模态完整子集。
之后模型接受五元组输入:模态完整子集 D f D_f Df 的 { T e x t , I m a g e , E n t i t y s e t , P r e t r a i n e d K G , [ C M T ] = 1 } \{Text,Image,Entity set,Pretrained KG,[CMT] = 1\} {Text,Image,Entityset,PretrainedKG,[CMT]=1} 和 { T e x t , p s e u d o I m a g e , E n t i t y s e t , P r e t r a i n e d K G , [ C M T ] = 0 } \{Text,pseudo Image,Entity set,Pretrained KG,[CMT]= 0\} {Text,pseudoImage,Entityset,PretrainedKG,[CMT]=0} 为纯文本子集 D t D_t Dt 。
改进式(2)中的图像编码方法使其同时容纳真实图像和伪图像。具体来说,我们在每个图像表示之后放置相应的完整模态标记 [CMT]。它们被拼接并映射到低 d 维空间

4.3 多模态分解
受到将多模态表示投影到不同空间的想法的启发[46],我们将原始视觉和文本表示分解为模态唯一空间和模态共享空间。提出了跨模态共享层来提取模态不变共享特征,使用图像特定层和文本特定层来提取相应的模态独特特征:
其中
H
I
H_I
HI 和
H
T
H_T
HT 是上一小节中获得的编码视觉和文本特征,
W
s
h
a
r
e
d
∈
R
d
s
×
d
W_{shared} ∈ R^{d_s×d}
Wshared∈Rds×d 和
{
P
I
,
P
T
}
∈
R
d
u
×
d
\{P_I , P_T \} ∈ R^{d_u×d}
{PI,PT}∈Rdu×d 分别是模态共享空间和模态独特空间的投影矩阵。
I
s
I_s
Is和
I
u
I_u
Iu分别是分解的模态共享和模态独特的图像特征,而
T
s
T_s
Ts和
T
u
T_u
Tu分别是分解的模态共享和模态独特的文本特征。

为了确保分解的模态共享空间与模态唯一空间无关,引入正交约束:

可以转化为以下正交损失,
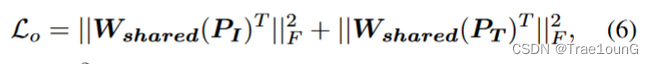
在获得两个模态独特特征和两个模态共享特征后, 我们将它们组合为跨模态不一致性表示 f u n i q u e f_{unique} funique 和整体模态共享表示 f s h a r e f_{share} fshare,即
其中 ⊙ 表示逐元素乘法运算, f u n i q u e ∈ R 3 d u f_{unique} ∈ R^{3d_u} funique∈R3du 用于度量模态之间的不一致信息, f s h a r e ∈ R 3 d s f_{share} ∈ R^{3d_s} fshare∈R3ds 用于表示模态之间的共享信息。获得跨模态对比特征的类似想法也可以在[46]中找到。但与它只关注不同模态之间的对立不同,我们还保留模态共享内容以保留全面的多模态语义。然后 f u n i q u e f_{unique} funique和 f s h a r e f_{share} fshare 都将作为最终分类层的输入的一部分,如式(10)所示。当最终的分类目标优化时,图像特征和文本特征将被强制投影到相同的语义空间中,并且在该空间中通过测量Tu−Iu的差异来评估它们的跨模态对比度。此外,模态共享内容还将与内容知识一致性子网络中的知识信息融合。
5 内容-知识一致性子网络
5.1 实体对排序
进行预处理后,得到的实体表示记为 e l ∈ R d e e_l ∈ R^{d_e} el∈Rde 。我们测量帖子中每对实体表示的曼哈顿距离,并保留距离最大的前 k (k = 5) 个实体对及其相应的距离值。请注意,对于实体数量小于 4 的帖子,实体对的数量不能达到 5( C 4 2 = 6 C^2_4 = 6 C42=6, C 3 2 = 3 C^2_3 = 3 C32=3)。为了解决这个问题,我们用伪实体进行补充,其表示是随机向量。我们连接成对的实体表示以获得实体对表示 E P i ∈ R 2 d e EP_i ∈ R^{2d_e} EPi∈R2de (i ∈ [1, k])。我们还得到实体对距离 d i s i ∈ R dis^i ∈ R disi∈R (i ∈ [1, k])
5.2 具有距离感知符号注意力的内容知识融合【distance-ware signed attention】
为了将知识图谱与帖子内容结合起来,将前 k 个最大距离实体对与模态共享内容与注意力机制融合起来。提出了一种新颖的方法,使用模态共享内容作为查询 Q,使用实体对表示 EP 作为值和键,并使用距离感知的符号注意力机制来学习最相关的融合部分。通过采用这种方法,我们可以解决内容知识一致性建模问题并捕获它们复杂的语义关系。这与注意力机制中查询、值和键的传统用法不同,因为还可以捕获查询和键之间的负相关性。此外,与[19]中最初签名的注意力不同,考虑了另一个因素(即实体距离)来调整软权重,以更好地获得内容知识不一致特征。
在传统的注意力机制中,如果查询和键之间的相关性为负(即它们的兼容性(例如点积)值为负),将认为它是无关紧要的。然而,这种负相关可能代表相反的语义,这可能有利于谣言检测任务。相反,符号注意力机制添加了一个“-Softmax”操作,使用查询和键之间相反的兼容性值作为 Softmax 函数的输入,以放大负相关性。因此,兼容性值将通过两个通道,即传统的Softmax(即“+Softmax”)和“-Softmax”函数,以捕获模态共享内容与顶部之间的正向和负向关系。 k 个最大距离实体对。由此我们得到了两个通道对应的两个注意力权重,即

模态共享特征 Q 是图像和文本的模态共享特征的串联。 α p o s i α^i_{pos} αposi 和 α n e g i α^i_{neg} αnegi 均表示第 i 个实体对的注意力权重,但分别反映正相关性和负相关性。较大的 α p o s i α^i_{pos} αposi (或 α n e g i α^i_{neg} αnegi)意味着实体对与内容在语义上更正(或负)相关。
同时,实体距离较大的实体对对学习对象的影响应该更显著。遵循这种直觉,我们通过考虑这两个因素来设计每个实体对的最终注意力权重,使用权重来计算没对实体对表示的加权和

其中 disi (i ∈ [1, k]) 表示第 i 个实体对的实体距离, β ∗ i β^i_∗ β∗i (∗ ∈ {pos, neg}) 是距离感知的符号注意力权重, f k g ∗ f^∗_{kg} fkg∗ (∗ ε { pos, neg}) 是基于符号注意力权重的正/负实体对嵌入, f k g ∈ R 4 d e f_{kg} ∈ R^{4d_e} fkg∈R4de 表示代表内容知识不一致特征的最终语义向量。
6 谣言分类层

最后,将跨模态不一致特征、内容知识不一致特征和模态共享特征连接起来,并将其输入到具有 Sigmoid 激活函数的全连接层中,以获得实例 i 的预测概率,即
损失:

实验
略
结论
我们提出了一种用于多模态谣言检测的知识引导双一致性网络,其中涉及一个框架中的跨模态不一致和内容知识不一致信息。此外,我们的框架还可以处理现实检测场景中的视觉模态问题。对三个数据集的广泛实验证明了我们的建议在捕获和融合两种类型的不一致特征方面的有效性,以在模态完整和模态不完整的条件下实现最佳性能。请注意,我们的框架捕获的不一致特征可以轻松插入其他谣言检测框架中,以进一步提高其性能。在未来的工作中,我们计划探索更有效的不一致特征,并设计一个更可解释和更稳健的模型

















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









