







 超级会员免费看
超级会员免费看

P.S.代码之后传到github , blog里只总结方法。
- 数据集路径
- 载入数据 (这里可以封装函数def load_dataset)
- 空值处理
- 无用字符清理
- 切词
1. 分词方法选择
除了jieba分词,还有哈工大的等。下为jieba分词的例子,可以使用jieba.load_userdict(‘user_dict.txt’)载入自定义词典(一词一行),避免被分词。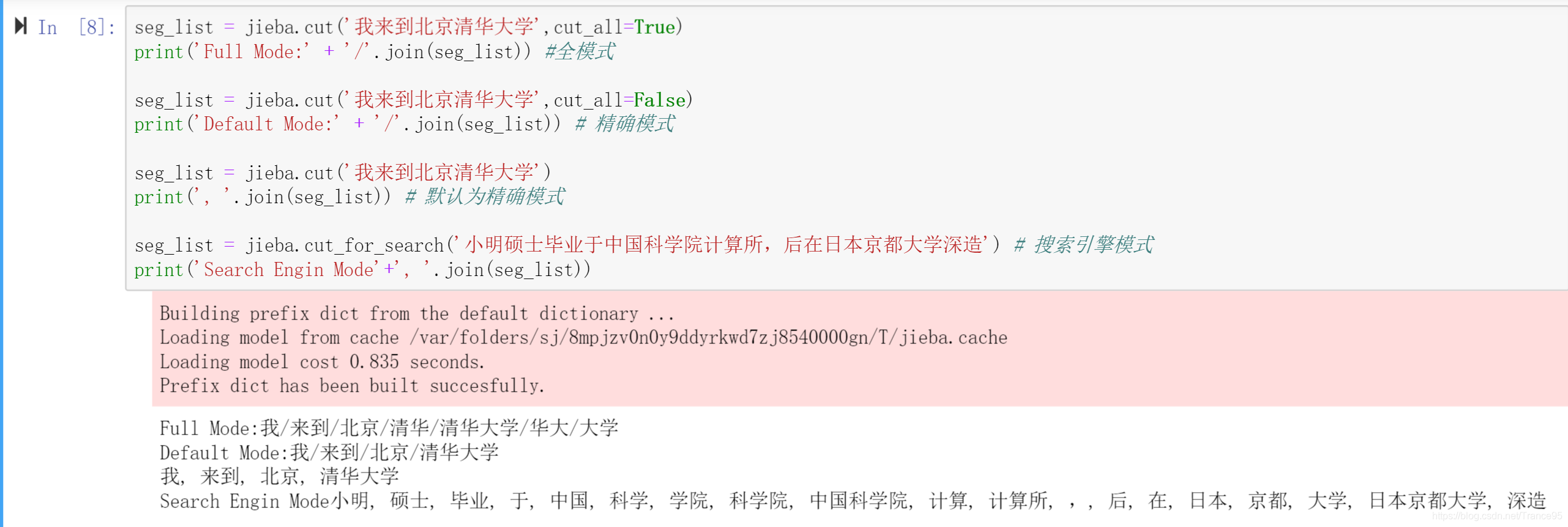
2.切词后再清理
sentence='2010款的宝马X1,2011年出厂,2.0排量'</
P.S.代码之后传到github , blog里只总结方法。
sentence='2010款的宝马X1,2011年出厂,2.0排量'</ 897
228
2443
897
228
2443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文























