








简介
题目:《Enhancing Sample Utilization through Sample Adaptive Augmentation in Semi-Supervised Learning》, ICCV’23 Oral
半监督学习中通过样本自适应增强提高样本利用率
日期:2023.9.7
单位:南京大学,悉尼大学,东南大学
论文地址:http://arxiv.org/abs/2309.03598
GitHub:https://github.com/GuanGui-nju/SAA
作者
第一作者找不到
眼熟的第二作者
赵振,个人主页:http://zhaozhen.me/

其他作者(略)
- 摘要
在半监督学习中,可以通过增强和一致性正则化来利用未标记样本。然而,我们观察到某些样本,即使进行了强有力的扩增,仍然可以以高置信度正确分类,导致损失接近于零。这表明这些样本已经很好地学习了,并且没有为模型提供任何额外的优化益处。我们将这些样本称为“朴素样本”。不幸的是,现有的SSL模型忽略了朴素样本的特性,它们只是将相同的学习策略应用于所有样本。为了进一步优化SSL模型,我们强调了关注原始样本并以更多样的方式增强它们的重要性。样本自适应增强(SAA)是为此目的而提出的,它由两个模块组成:1)样本选择模块;2) 样本扩增模块。具体而言,样本选择模块根据每个epoch的历史训练信息挑选出原始样本,然后在样本增强模块中以更多样的方式增强原始样本。由于上述模块的实现非常容易,SAA具有简单和轻量级的优势。我们分别在FixMatch和FlexMatch的基础上添加了SAA,实验表明SAA可以显著改进模型。例如,SAA有助于在具有40个标签的CIFAR-10上将FixMatch的准确率从92.50%提高到94.76%,将FlexMatch的准确性从95.01%提高到95.31%。
然而,并不是所有未标记的样本都有效利用,即使有很强的增强。在图1a中,如果强增强版本被高置信度正确分类,导致损失接近于零,这表明样本已经学习得很好,不能进一步提高模型的性能。换句话说,该样本没有被有效地用于模型训练,我们称该样本为“朴素naive样本”。当训练过程中包含大量朴素样本时,可能会导致模型性能改进缓慢甚至停滞,如图1b所示。

Fig1:(a) 显示了一个朴素样本的示例。其增强版本以高置信度正确分类,导致损失接近0。(b) 显示了FixMatch训练期间的模型性能。性能改进缓慢,甚至在一段时间内停滞不前。
以FixMatch为例,我们分别跟踪了朴素样本和非朴素样本的Loss,如图3所示,不设阈值的原始损失(请注意,显示的是没有阈值的原始损失,以排除置信阈值对损失值的干扰)在大多数epoch,朴素样本的交叉熵损失接近于0,这表明对A(ui)的学习对模型的训练进度没有贡献

如何通过新的学习策略进一步挖掘朴素样本的价值。
样本自适应增强(SAA, Sample Adaptive Augmentation)来识别朴素样本,并增加其增加后的多样性
SAA由两个模块组成:1)样本选择模块和2)样本扩增模块。前者负责在每个epoch中挑选朴素样本,后者对朴素样本采用更多样化的增强策略。
具体来说,在样本选择模块中,首先用指数移动平均线(EMA)更新每个epoch样本的历史损失,然后将这些样本分成两部分。历史损失较小的部分被认为是朴素样本。
而在样本增强模块中,将通过重新组合多个强增强图像来获得更多样化的原始样本的增强版本,并对剩余样本进行原始强增强。
SAA很容易实现,只需要几行代码就可以将我们提出的模块添加到PyTorch中的FixMatch或FlexMatch中。它在内存和计算方面也是轻量级的,即,只需要添加两个额外的向量并在每个epoch更新它们,使其成为改进SSL模型的有效解决方案。
工作重点
- 确定了无效使用的样本,并强调应给予更多关注。在基于数据增广的一致性正则化下,一些强增广版本不利于模型训练,导致这些样本的值没有得到充分利用,使模型性能难以提高。我们将其称为“naive样本”,并强调应采用新的学习策略来学习。
- SAA可以更好地利用朴素样本。为了增加增强版本有利于模型训练的概率,提出了一种简单而有效的方法,即样本自适应增强(SAA),用于识别初始样本并以更多样的方式对其进行增强。
- 在SSL基准测试上验证了SAA的有效性。使用FixMatch和FlexMatch作为基本框架,我们证明了我们的方法可以实现最先进的性能。例如,在具有40个标签的CIFAR-10上,SAA帮助FixMatch将其准确性从92.50%提高到94.76%,并帮助FlexMatch将准确性从95.01%提高到95.31%。
方法
- Overview
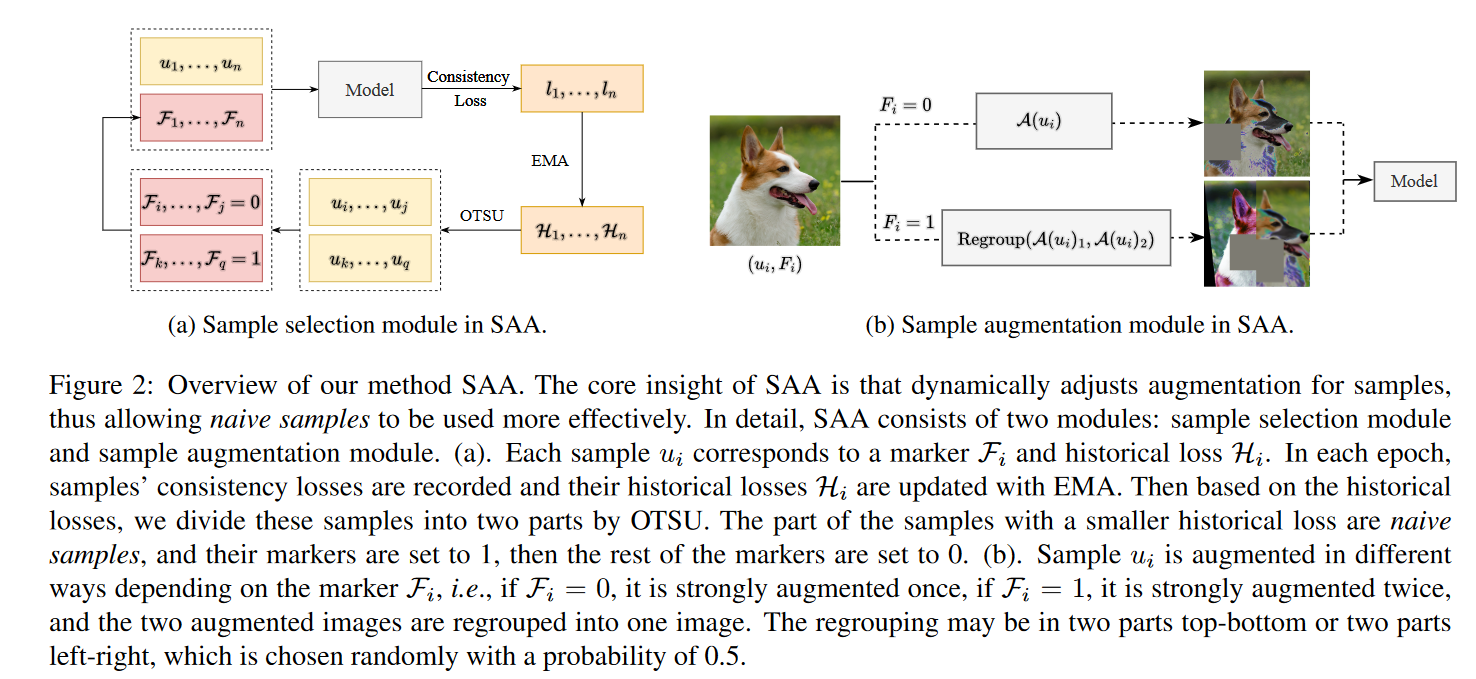
Fig2:SAA的核心见解是动态调整样本的扩增,从而使原始样本能够更有效地使用。具体来说,SAA由两个模块组成:样本选择模块和样本扩充模块。(a) 。每个样本ui对应于标记Fi和历史损失Hi。在每个历元中,记录样本的一致性损失,并用EMA更新其历史损失Hi。然后,根据历史损失,我们将这些样本按OTSU分为两部分。历史损失较小的样本部分是原始样本,其标记设置为1,然后其余标记设置为0。(b) 。根据标记Fi,样本ui以不同的方式被增强,即,如果Fi=0,它被强增强一次,如果Fi=1,它被增强两次,并且两个增强的图像被重新组合成一个图像。重组可以是上下两部分或左右两部分,这是以0.5的概率随机选择的。
部分标记含义:
X:标记集; U:未标记集
α(·):弱增强策略,A(·):强增强策略;pwi和psi分别表示模型对α(ui)和A(ui)的预测
基于一致性正则化的无监督损失:

H(p1, p2):p1和p2之间的标准交叉熵
τc:仅保留高置信度伪标签的预定义阈值
标记样本的监督损失:(p错打为q?)

总损失可表示为:

- 样本选择模块
引入两个向量:
H:记录了每个未标记样本的历史一致性损失信息,F:标记了未标记样本是否为朴素样本(N:未标记样本数)
对于未标记的样本ui,模型计算其弱增广和强增广在第t个epoch的一致性损失lit。然后用指数移动平均线(EMA)更新Hti,可以表示为:

参数α不是超参,由EMA更新
每个epoch的历史损失阈值:
![]()
OTSU(大津法/最大类间方差法):一种常用的阈值分割方法(计算简单、稳定性好、自适应能力强)
OTSU根据历史损失自适应地将样本分成两部分。具有较小历史损失的样本被认为是朴素样本,因为它们对模型提供的帮助较少。然后我们将F更新为:

𝟙:指示函数(indicator function),当输入为True的时候,输出为1,输入为False的时候,输出为0。
初始样本的判定是在每个epoch进行的,样本是否为朴素样本与模型性能有关。可以及时对样本的判定,防止过犹不及的对样本进行增强
为了及时更新样本历史损失H和标记F,我们将每1024次迭代视为一个epoch,即总共训练了1024个epoch。由于增强A′不适合模型的初始训练,我们只在第100 epoch之后使用,而历史损失H从一开始记录。
- 样本扩增模块
对非朴素样本和朴素样本应用不同的增广。前者将使用原来的增广A,而后者将使用新的增广A’,这增加了增广版本的难度。这可以表示为:

通过将几个A(ui)重新组合成一个新图像。形式上,新的增广图像A’(ui)可以表示为:
![]()

我们有两个强增广图像A(ui)1和A(ui)2。为了创建一个新的增强图像A’ (ui),我们以相同的概率随机选择以下两个选项之一:1)上下拼接:我们取A(ui)1的上半部分和A(ui)2的下半部分,并将它们连接起来创建一个新图像。2)左右拼接:我们取A(ui)1的左半部分和A(ui)2的右半部分并连接它们以创建新图像。
在CutMix的情况下,对被切割的图像进行了增强,这可能会导致原始图像的一些信息丢失。相比之下,我们的方法是对整个图像进行增强,从而保留了原始图像的更多信息。这将在本文的实验部分进一步讨论。
- 补充:在FixMatch上应用SAA的伪代码

实验
SAA在所有设置下都成功地提高了FixMatch和FlexMatch的测试精度。
对于STL-10, SAA帮助FixMatch提高了2.65%的准确率,FlexMatch提高了1.70%。
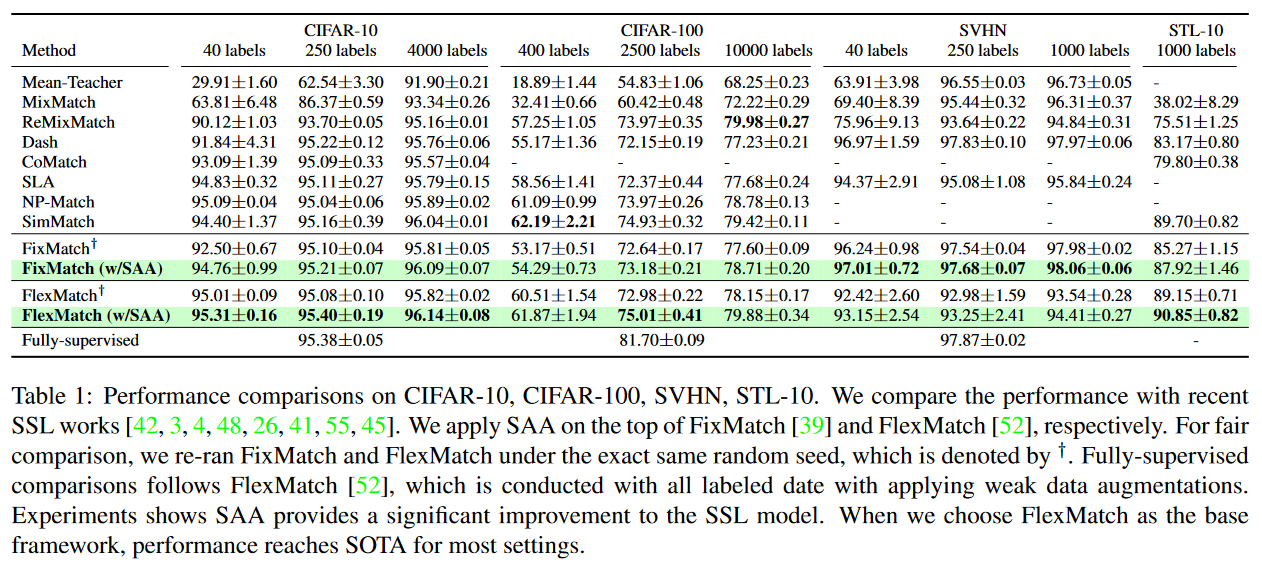
Tab1:CIFAR-10、CIFAR-100、SVHN、STL-10的性能比较。我们将性能与最近的SSL工作进行了比较。我们分别在FixMatch和FlexMatch应用SAA。为了公平比较,我们在完全相同的随机seed下重新运行FixMatch和FlexMatch,用†表示。完全监督的比较遵循FlexMatch,该方法使用所有标记的日期进行,并应用弱数据增强。实验表明SAA为SSL模型提供了显著的改进。当我们选择FlexMatch作为基本框架时,大多数设置的性能都达到了SOTA。
一些分析:FlexMatch在SVHN任务下表现不佳的原因:对于不平衡的数据集,FlexMatch对每个类的阈值估计可能会产生很大的偏差。SVHN是一项简单的任务,所以FixMatch中固定的高阈值更为有利。
如图5a所示,SAA在所有5个seed下都能增强FixMatch,但SAA对模型的助推作用在不同的seed下是不同的。
SAA加速了模型性能的改进。图5b为相同种子下模型训练的性能曲线。
FixMatch在大约200k到600k次迭代之间遇到性能停滞。这是因为在此期间,模型学习了大量对模型性能改进无用的强增强版本,而我们提出的SAA通过改变原始样本的增强成功地避免了这种现象。
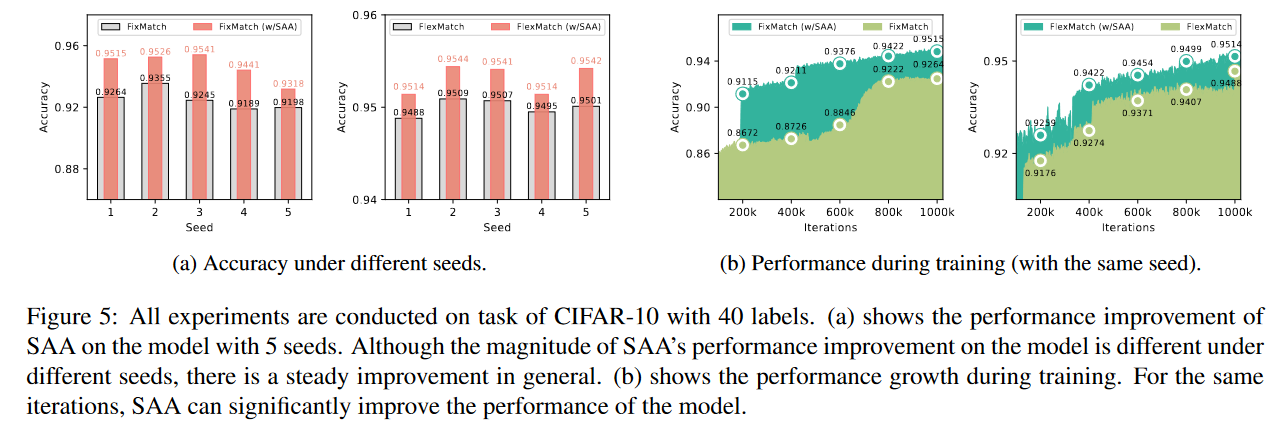
Fig5:所有实验都是在具有40个标签的CIFAR-10的任务上进行的。(a) 显示了SAA在具有5个种子的模型上的性能改进。尽管在不同的种子下,SAA对模型的性能改进幅度不同,但总体上是稳步改进的。(b) 显示了训练期间的表现增长。对于相同的迭代,SAA可以显著提高模型的性能。
- Discussion(有点消融实验的感觉)
更多样化的增广并不适用于所有的样本。如表2所示,使用Baseline-1和
Baseline-2:对所有样本应用不同的增强会导致不稳定,并降低某些任务的性能。这说明在增强A′下,一些图像有太多的语义信息被破坏,导致错误的积累。
Baseline-3:每个epoch随机选择50%的样本应用A ',模型的平均检验精度略有提高,但仍然不稳定。
得出,更多样化的增加是必要的,但只能用于朴素的样本,以更好地工作。
关于阈值的选择,固定阈值和固定尺度方法对模型有增强作用,但效果不稳定,OTSU不仅可以更好地适应跨数据集任务,而且可以随着模型的训练进行调整

Tab2:选择应用A′的样品的不同方法。实验在FixMatch的基础上进行。有三种方法可以设置H的阈值:1)固定值;2) 排序H的百分位;3) OTSU自动划分。
图6a显示了不同迭代下OTSU方法划分的朴素样本比例。我们可以发现朴素样本不仅与任务难度有关,而且与模型性能有关。对于更简单的数据集,朴素样本的比例更大,随着模型性能的提高,更多的样本也被视为朴素样本。
图6b比较了FixMatch中带SAA和不带SAA的朴素样本的训练损失。
在没有SAA的情况下,在第100 epoch之后的大部分时间里,朴素样本的损失仍然接近于0,这表明强增强版本对模型训练没有帮助。
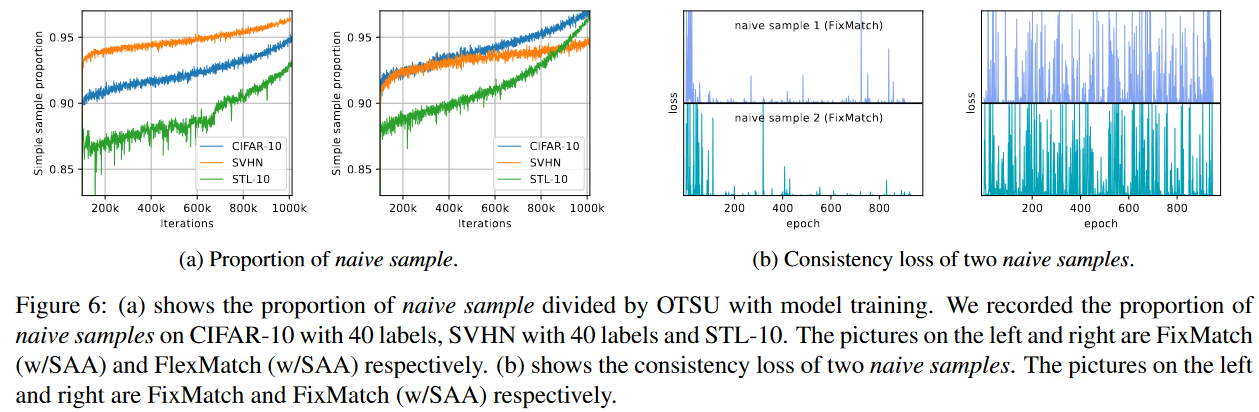
Fig6:(a) 显示了OTSU通过模型训练划分的原始样本的比例。我们在具有40个标签的CIFAR-10、具有40个标记的SVHN和STL-10上记录了初始样本的比例。左边和右边的图片分别是FixMatch(w/SAA)和FlexMatch(w/SAA)。(b) 显示了两个原始样本的一致性损失。左边和右边的图片分别是FixMatch和FixMatch(w/SAA)
Fig7:模型预热。在具有40个标签的CIFAR-10上进行实验。使用100k次迭代(总迭代的10%)进行模型预热的效果最好。
Fig8:对再增强A’方法的讨论,先切割为crop再强增强还是先强增强再切割
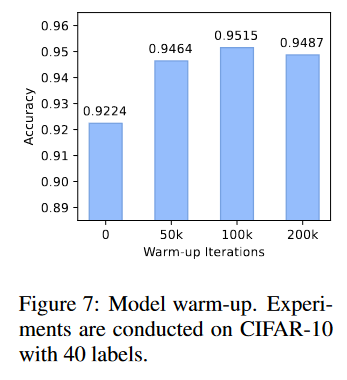
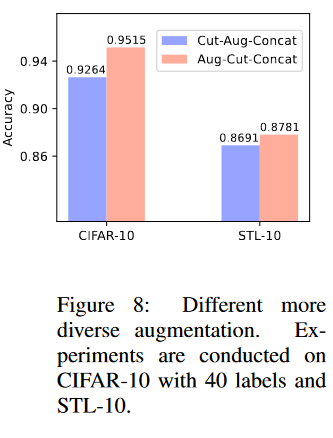
Fig7:模型预热。在具有40个标签的CIFAR-10上进行实验
Fig8:不同的更多样的扩增。实验在具有40个标签的CIFAR-10和STL-10上进行
总结
- conclusion
在本文中,我们首先讨论了原始样本的特征及其对模型训练的影响,并强调这些样本应该受到关注,以发现更多的价值。我们提出了SAA来实现这一目标,它实时识别原始样本,并动态调整其增强策略,以便它们能够为模型训练做出贡献。我们的实验结果表明,SAA显著提高了SSL方法(如FixMatch和FlexMatch)在各种数据集上的性能。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









