








PAMS: Quantized Super-Resolution via Parameterized Max Scale
PAMS:通过参数化最大尺度量化超分辨率, ECCV 2020
paper: https://arxiv.org/pdf/2011.04212.pdf
GitHub: https://github.com/colorjam/PAMS
摘要
深度卷积神经网络(DCNNs)在超分辨率(SR)任务中显示出了卓越的性能。然而,其高昂的内存消耗和计算开销显著限制了其在资源有限设备上的实际部署,这主要源于权重和激活值之间的浮点存储和操作。尽管此前的努力主要依赖于定点操作,但使用固定编码长度量化权重和激活值可能会导致显著的性能下降,尤其是在低比特情况下。具体来说,大多数没有批量归一化的最新SR模型具有较大的动态量化范围,这也是性能下降的另一个原因。为了解决这两个问题,我们提出了一种新的量化方案,称为参数化最大尺度(PAMS),该方案通过应用可训练的截断参数,自适应地探索量化范围的上限。最后,我们引入了结构化知识转移(SKT)损失来微调量化网络。大量实验表明,所提出的PAMS方案能够很好地压缩和加速现有的SR模型,例如EDSR和RDN。值得注意的是,8位的PAMS-EDSR在Set5基准测试中的PSNR从32.095dB提升到32.124dB,压缩比达到2.42倍,创下了新的最先进水平。
简介
之前就有压缩深度SR网络的方法,本质上,这种方法是通过量化方案来加速和压缩超分辨率(SR)网络,具体做法是将全精度权重、激活和梯度转换到低比特。
但作者认为之前的方法存在问题:
量化范围不够普适,导致性能的下降:1. 使用固定编码长度量化权重和激活值,尤其是在低比特情况下;2. 大多数没有批量归一化的最新SR模型具有较大的动态量化范围。
使用全精度激活,计算复杂性仍然显著偏高。相比之下,直接将权重量化应用于激活值会导致一般SR任务中的准确性显著下降,尤其是在没有使用批量归一化的情况下,这主要是由于高动态量化范围造成的。
归一化特征会限制SR模型的表示能力。批量归一化层会使特征变得平滑,从而导致重建的高分辨率图像产生模糊和伪影。另一方面,但缺少批量归一化会引发严重的动态范围问题。例如简单地将激活的上限设置为其最大值,这在SR任务中导致性能显著下降。这是因为固定的最大尺度可能是作为上限的异常值。尽管Choi等人 [3] 提出了PACT,通过可学习参数来剪裁和量化激活值,但它仅关注正范围,忽略了负范围的梯度信息。此外,新型正则化项被添加来自动学习量化控制参数,从而获得准确的低精度模型,但这会增加额外的计算负担和内存占用,这在实际应用中对运行时不友好。
提出解决方法:
针对上述问题,提出了一种新的量化方案,称为参数化最大尺度(PAMS),用于压缩和加速超分辨率(SR)模型。
不同于以往固定方式量化激活值的方法,PAMS基于梯度使用可训练的截断函数自适应地探索量化范围的上限,从而显著提升了模型的普适性。此外,引入了结构化知识迁移(SKT),将全精度网络中的结构化知识转移到量化网络中,使后者具备更好的视觉感知能力。
首先,我们用PAMS块替换SR模型中的每个基本块。在每个PAMS块中,权重在与输入进行卷积之前被量化,激活值在卷积层输出后使用其可学习的最大尺度进行量化。为了进一步提高量化模型的性能,我们在像素之间对齐全精度模型和对应的低精度量化模型的高层特征。最后,我们采用随机梯度下降(SGD)方法最小化目标函数,该方法利用蒸馏损失对像素级损失进行优化。
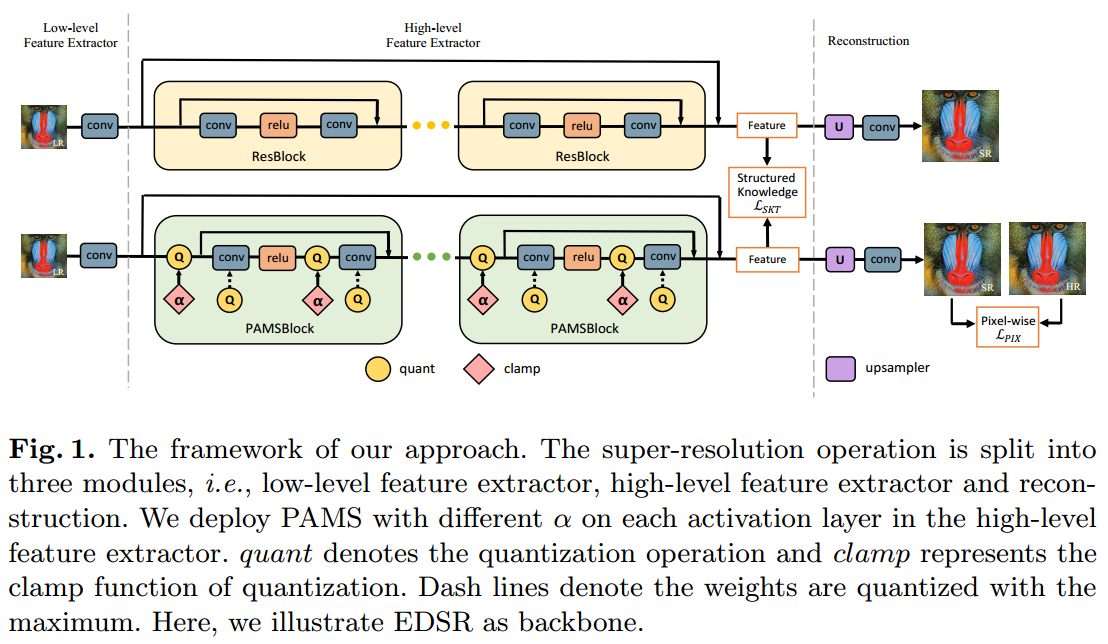
fig1. 我们方法的框架。超分辨率操作被分为三个模块,即低层特征提取器、高层特征提取器和重建。在高层特征提取器的每个激活层中,我们应用了不同α的PAMS。quant表示量化操作,clamp代表量化的截断函数。虚线表示权重被量化到最大值。这里,我们以EDSR作为骨干网络进行说明。
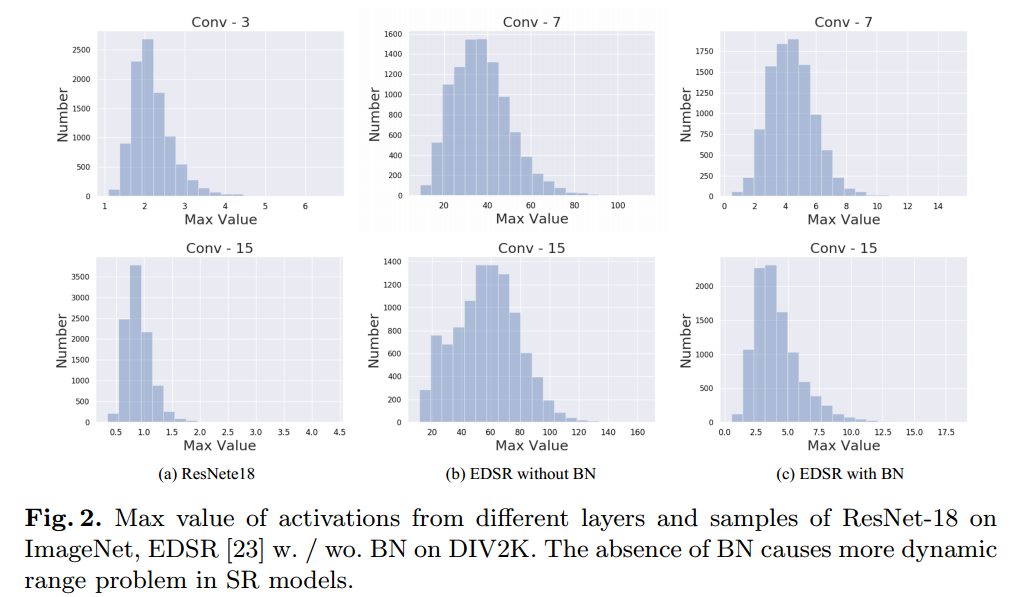
Fig2. ImageNet 上不同层和 ResNet-18样本的激活最大值,EDSR w./wo. BN在DIV2K 数据集上。 BN 的缺失会导致 SR 模型出现更多动态范围问题。
方法
Parameterized Max Scale (PAMS)

优化


实验
数据集: DIV2K
四个标准基准数据集:Set5, Set14, BSD100, Urban100
评估指标: 在输出质量图像和原始 HR 图像之间的 Y 通道上使用 PSNR 和 SSIM
SR 模型和替代方法: 为了验证我们方法的优越性,选择 EDSR 和 RDN 作为主干,并对其使用 8 位和 4 位量化。由于大多数参数存在于高级特征提取模块中,因此我们不会量化低级特征提取和重建模块中的权重和激活,这确保了性能和模型大小之间的权衡。定性比较使用EDSR .
定量和定性结果
如表1所示,所提出的具有 8 位权重和激活的 PAMS 在不同骨干网上实 现了有竞争力甚至更好的结果。例如,8 位 PAMS-RDN 在比例因子为 ×2 和 ×4 的 Urban100上分别比全精度 RDN 提高了 0.178dB PSNR 和 0.074dB PSNR。与 全精度模型相比,4 位 PAMS-EDSR 在 BSD100上仅遭受 0.24dB PSNR 损失,比 例因子为 ×4。量化 RDN 比 8 位 EDSR 有了显着改进,这表明密集块可能会产生比残差块有更多的冗余。
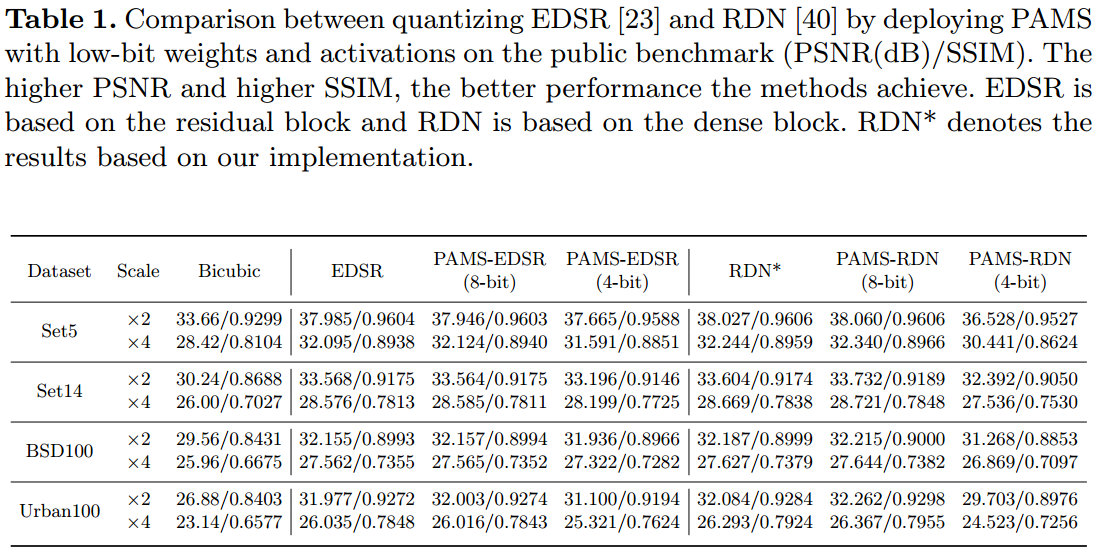
Tab1. 在公开基准测试上,将EDSR [23]和RDN [40]量化后部署PAMS,以低比特权重和激活进行对比(PSNR(dB)/SSIM)。PSNR和SSIM值越高,表示方法的性能越好。EDSR基于残差块,而RDN基于密集块。RDN*表示基于我们实现的结果。
图 3 中的 8 位量化提供了更多定性评估。使用 PAMS 的模型比双三次插值生成的图像在视觉上更自然,并且与其全精度对应模型极其相似。考虑到基于残差的模型被广泛使用,结果也表明了该方法的通用性。


Fig3. 比例因子为 ×4 的 8 位模型和全精度模型之间的定性比较。 (a)和(b)分 别是Set˾́中"barbara"和"zebra"的结果。©是Urban100中"img055"的结果。请注意,使用 PAMS 的量化模型可生成与其全精度 对应模型极其相似甚至更好的 SR 图像,而前者显着降低了模型大小和计算 复杂性。
为了更好的比较,我们在 EDSR 上重新实现了 Dorefa、 Tensorflow Lite 和 PACT。我们使用与 PAMS-EDSR 相同的初始化方法并对每个残差块中的权重和激活进行量化。对于Dorefa ,为了公平比较,我们不量化梯度。桌子。图2显示了8位和4位EDSR的结 果。与所有基线相比,我们的方法实现了更好的性能。例如,8 位 PAMSEDSR 在 Set14和 Urban100上分别优于 8 位 Dorefa-EDSR 1.288dB PSNR 和 1.796dB PSNR。
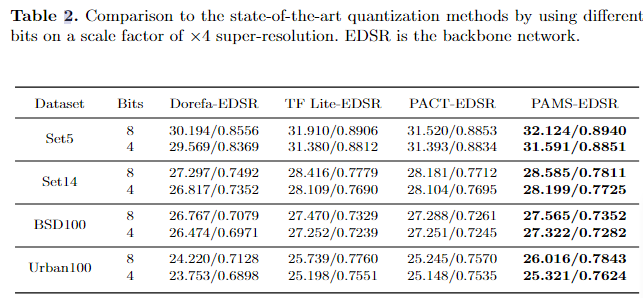
Tab2. 在 ×4 超分辨率比例因子上使用不同位与最先进的量化方法进行比较。 EDSR是骨干网络。
重建结果进一步如图4所示。与其他方法相 比,使用PAMS的输出(SR图像)看起来更好,边缘清晰,细节丰富。综 上所述,具有可训练截断参数的 PAMS 依赖于后向,获得了更好的泛化能 力。

Fig4. 我们的方法与其他量化方法在 ×4 比例因子上的定性比较。
压缩比
EDSR 和 RDN 的模型大小和压缩比如表 3 所示。特别地,全精度网络使用单精度浮点表示。全精度网络的模型在量化后尺寸大大减小。请注意,我们仅量化高级特征提取器模块中的权重和激活,以便 根据网络的总参数和高级特征提取器中的参数计算压缩比。尽管 PAMS 引 入了可训练参数α,但它仍然产生 50%-90% 的压缩比,因为它直接取决于主干和位数。可以看出,4 位权重和激活比 8 位模型导致更多的性能下降。但较低比特量化的网络可以显着降低存储需求。
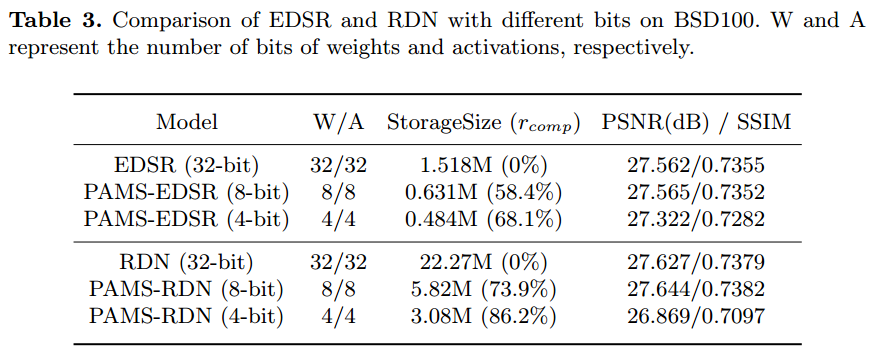
Tab3. BSD100上不同位的 EDSR 和 RDN 的比较。 W 和 A 分别表示权重和激活的位数。
α的收敛性
为了证明我们方法的收敛性,我们在训练期间直接验证 α 的收敛性。结果 如图 5 所示。第一列和第二列分别显示了 Block 8 和 Block 13 层上的 PAMS-EDSR 的 α。第三列和第四列分别显示了PAMS-RDN在RDB 0和 RDB 13中的α(RDB表示Residual Dense Block)。这说明不同层中的α 不仅具有不同的值,而且具有不同的演化方向。例如,PAMS -EDSR Block 8(图5(a))和PAMS-RDN RDB 0(图5(c))作用方向相同, 而PAMS-EDSR Block 13(图5(b))和PAMS-RDN RDB 13(图 5(d))的趋势相反。我们还发现α可以促进EDSR和RDN收敛到稳定值, 这表明了我们方法的有效性。
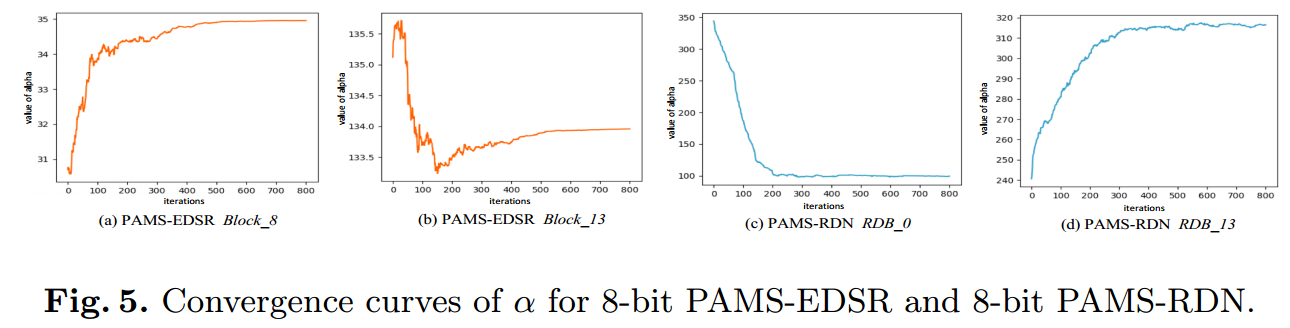
Fig5. 8 位 PAMS-EDSR 和 8 位 PAMS-RDN 的 α 收敛曲线。
消融实验
BN 在 SR 模型中的影响。为了研究量化归一化特征的效果,我们使用 PACT 来量化有 BN 和没有 BN 的 EDSR。如表4所示,不 带BN的量化EDSR之间的性能差距比带BN的量化EDSR更大。例如,不带 BN 的 8 位 PACT-EDSR 在 Urban100上的差距为 0.790dB PSNR,大于带 BN 的 PACT-EDSR(0.354 dB PSNR)。这表明,在较低精度的SR模型中,非归一化特征的性能下降更为明显,而且, PAMS-EDSR可以为非归一化权重和激活保存更多重要信息,从而大大缩小性能差距。可学习α的影响。我们将可学习最大尺度 (PAMS) 与量 化激活的固定最大值 (TF Lite) 进行比较。定量和定性结果示于表中。 分别如图2和图4。与 TF Lite-EDSR 相比,PAMS-EDSR 获得了更好 的分数,因为它产生更清晰的图像和更真实的纹理。这表明我们的方 法可以学习到更合适的量化范围,该范围包含更多关于全精度模型的 信息并减少量化误差。
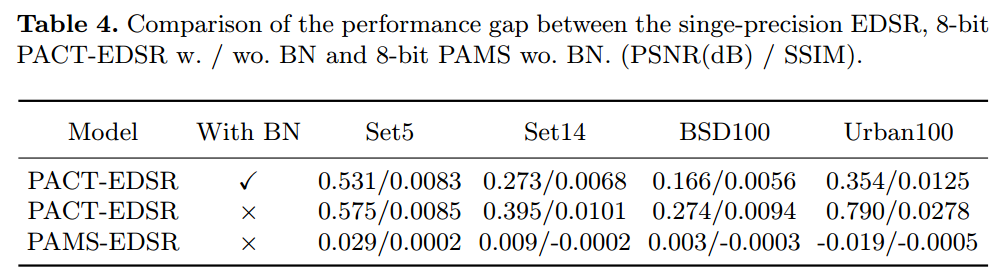
Tab4. 单精度 EDSR、8 位PACT-EDSR 和 EDSR 之间的性能差距比较。 / 沃。 BN 和 8 位 PAMS wo。 国阵。 (PSNR(dB)/SSIM)。
α初始化的效果。我们使用 EDSR 上的随机初始 化(比例因子为 ×4)来评估 EMA 初始化。对于随机模式,我们在激活量化层中使用0到128之间的随机数来初始化α,这确保了α可以在不 同层中独立地初始化为更大的值。如表5所示EMA初始化在所有 基准数据集上取得了更好的性能。解释一下,EMA 通过 α 实现了更好 的统计分布,这可以进一步帮助提高 SR 性能。
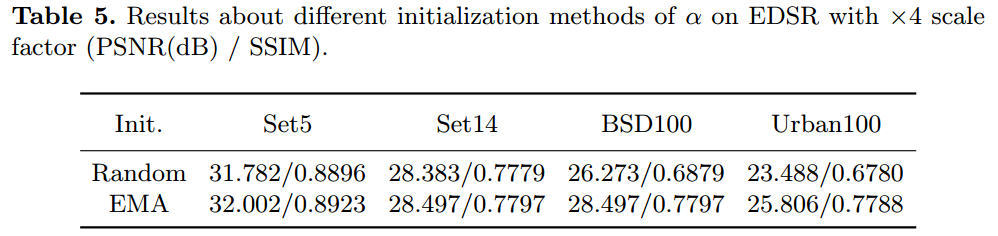
Tab5. EDSR 上 α 的不同初始化方法与 ×4 比例因子 (PSNR(dB) / SSIM) 的结果。
研究 SKT 损失。为了 研究 SKT 的有效性,我们进一步比较了有和没有 SKT 的量化模型。如表6所示,使用 SKT 优化的 PAMS-EDSR 优于相应的同类产品。特别是,我们的 方法在较低位上获得了更好的性能。例如,与Urban100上不带LSKT 的PAMS-EDSR相比,带L SKT的4位PAMS-EDSR获得0.071dB PSNR,而具有相同优化的8位PAMS-EDSR仅获得0.032dB PSNR。它还表明全精度模型的特征图可以帮助低精度模型更好地捕获图像的空间相关性。
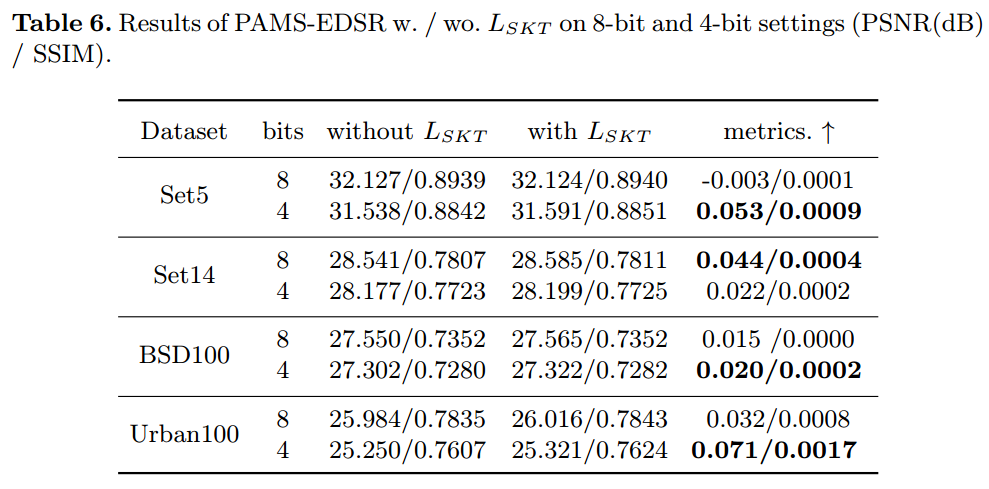
Tab6. PAMS-EDSR w./ wo.。 8 位和 4 位设置上的 LSKT(PSNR(dB)/SSIM)。














 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









