






下面是一个十分简陋的html网页,今天我们就爬取其中所有唐诗的部分作为练习
下面我们鼠标点击右键,点击“检查”
就会看到其网页代码
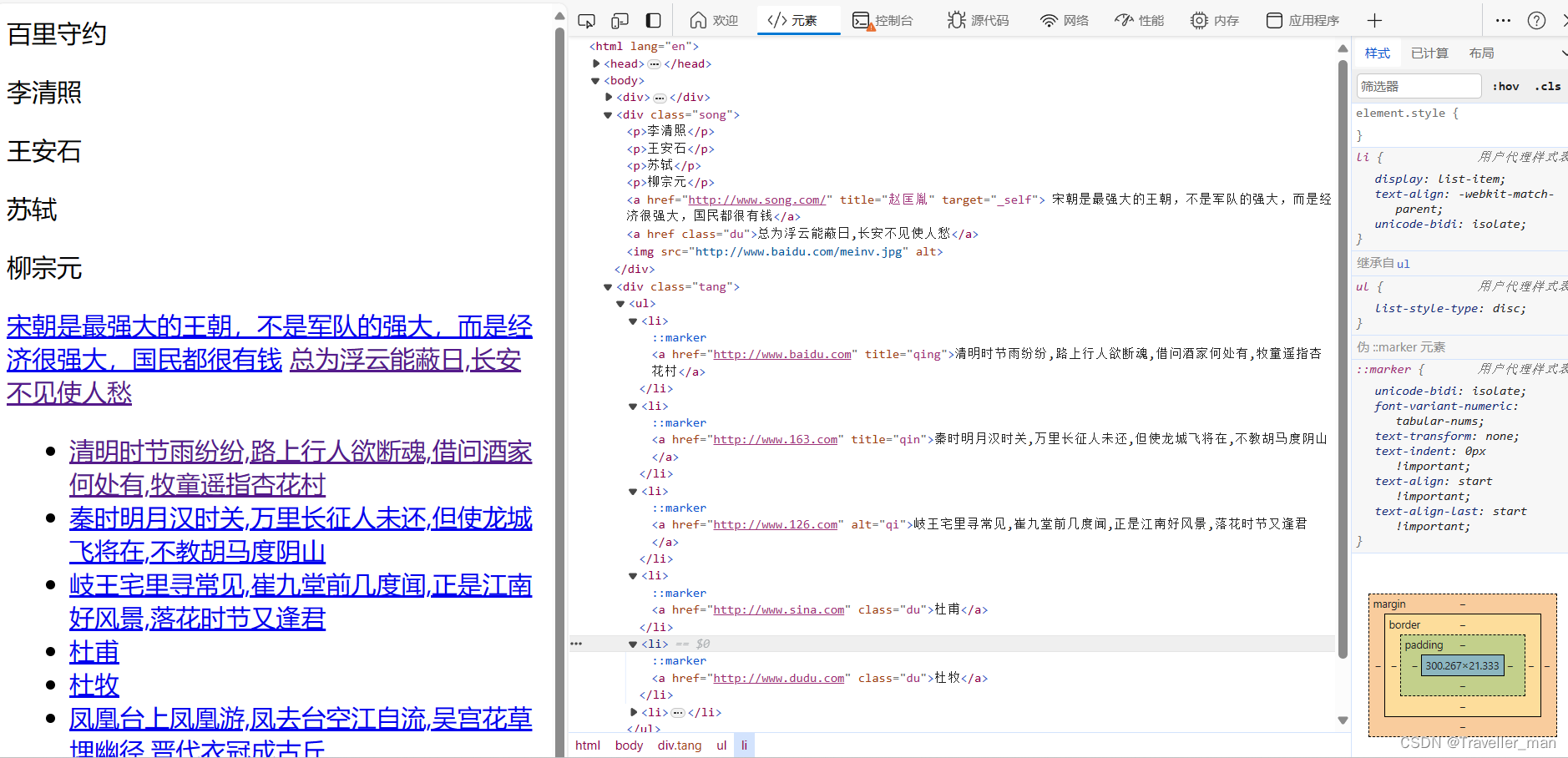
观察代码我们所需要的唐诗部分藏在哪里呢?
原来都藏在div.tang ul 下所有li中了(这里可能需要了解一点html部分知识,大家可以去看看上面两篇文章)
#解析本地文件使用 etree.parse
from lxml import etree
#使用lxml库的parse()函数解析了名为'xpath.html'的XML文件
tree = etree.parse('file:///C:/Users/admin/Downloads/xpath.html')
#这行代码使用XPath表达式
list1 = tree.xpath('//body/div[3]/ul/li/a/text()')
#循环遍历了XPath查询结果的列表,并打印每个项的文本内容。
for item in list1:
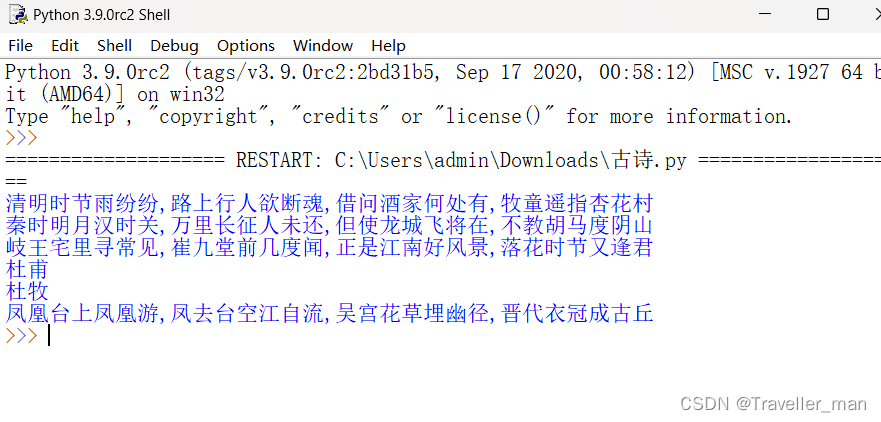
print(item)运行结果如下















 3381
3381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









