







该爬虫知识仅供参考与学习,大家不要利用技术做不好的事情哦!
在使用前需要先安装google浏览器,然后装一下Google驱动详见:如何下载谷歌浏览器最新驱动(ChromeDriver)
如果没有Google浏览器也没关系,后面会说解决方法。
系统界面:

输入URL与要爬取的页数(1页=14个视频信息),爬取完成数据保存到csv文件中。视频数据包括(标题,作者,链接,点赞数,评论数,发布时间,)
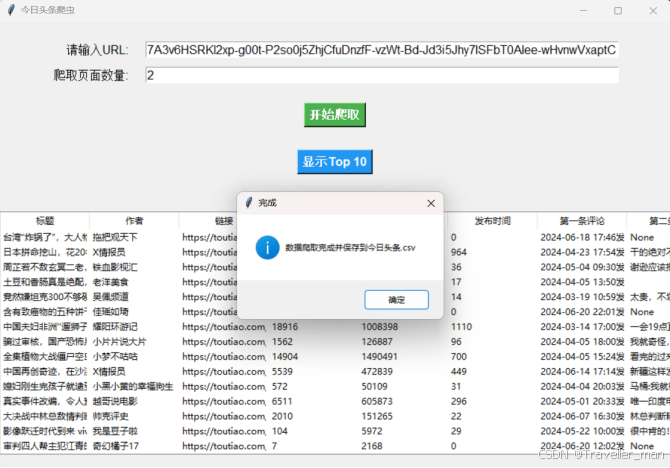
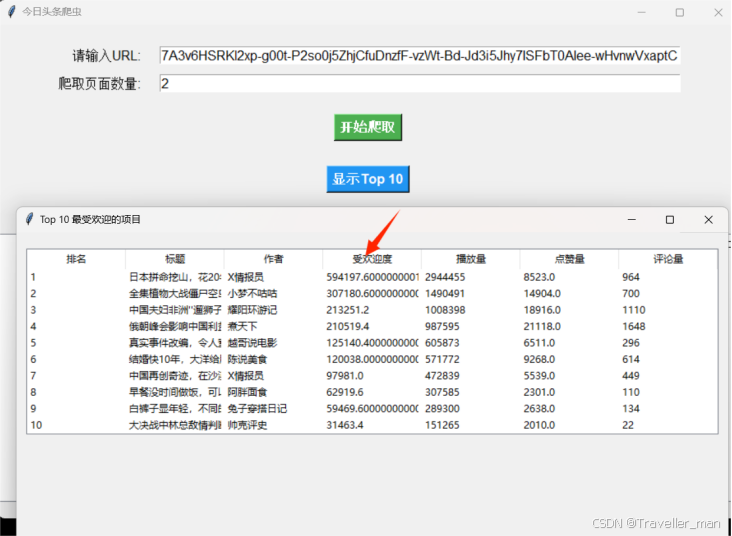
点击“显示TOP10”,项目会根据所采集的数据信息分析评分,得出受欢迎度数值,然后排序显示前10名视频数据。
详细代码如下,在下面代码中说实话有点小小瑕疵哈,比如在显示界面的标题部分少加了,导致看起来有点错位(不影响使用哈,但博主有点小懒不想改啦!)还有就是在使用过程中因为要用到Google,使用避免不了一些东西(狗头保护),大家其实也可以去使用火hu浏览器哈,然后下载对应驱动(不过需要稍稍改动代码哈)。希望大家都有收获!
import tkinter as tk
from tkinter import messagebox, ttk
import requests
import csv
import time
import threading
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException
import pandas as pd
# 定义爬取函数
def scrape_data(url, page_count, tree):
def update_treeview(data):
tree.insert("", tk.END, values=data)
tree.update_idletasks()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2404
2404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









