






参考:Python实战:通过微信小程序,获取Manner Coffee全国门店信息
数据接口是找到了,但是在用 Python 的 request 库爬取数据环节,调用接口报 400 错误,但是在 Reqable 上抓包是可以正常使用。
哎 好奇怪。
import requests
import urllib3
# 屏蔽https的证书警告
urllib3.disable_warnings()
url = "https://triangle.wearemanner.com/mp-api/v1/areas/tree?isContainsCountry=false"
headers = {
"Authorization": "",
"User-Agent": "",
"Device-OS": "Windows 10 x64",
"Content-Type":"application/json",
}
response = requests.get(url=url, headers=headers, verify=False)
print(response.status_code)
print(response.text)
看代码没有什么问题,但是返回状态码 400。
今天查找资料,终于解决了问题。
请求的headers里的Content-type写法需要从"application/json"改为"json",请求顺利有返回值了。
返回的状态码 200 也正常了,不报 400 错误了。
headers:{
"Content-Type":"json"
}
分析接口
接口调通了,下面就可以直接调用小程序的接口,获取城市列表和门店列表了。
昨天的文章中获取到:
城市 url 为:https://triangle.wearemanner.com/mp-api/v1/areas/tree?isContainsCountry=false
门店 url 为https://triangle.wearemanner.com/mp-api/v1/shops?isCompact=true&areaCode=320200&level=4
门店 url 中只有areaCode是变化的参数,areaCode可以从城市的response中获取到,可以构造每个城市门店的 url。
获取城市列表
通过上面的分析,接口有了,爬虫代码公众号历史文章写过很多案例了,可以顺手捏来。
获取到城市列表,并保存为 excel 文件。代码如下:
import requests
import pandas as pd
import urllib3
# 屏蔽https的证书警告
urllib3.disable_warnings()
url = "https://triangle.wearemanner.com/mp-api/v1/areas/tree?isContainsCountry=false"
headers = {
"Host": "triangle.wearemanner.com",
"Connection": "keep-alive",
"Client-Platform": "MP-WEIXIN",
"user_no": "",
"Client-Host-Language": "zh_CN",
"Device-Brand": "microsoft",
"Client-Host-Version": "3.9.9",
"Encrypted-Type": "N",
"Client-Version": "0.9.6",
"Authorization": "",
"User-Agent": "",
"Device-OS": "Windows 10 x64",
"Content-Type": "json",
"server-api-version": "1",
"Device-Model": "microsoft",
"xweb_xhr": "1",
"version": "0.1.5",
"Accept": "*/*",
"Sec-Fetch-Site": "cross-site",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "https://servicewechat.com/wx4328af055800c98e/120/page-frame.html",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9"
}
response = requests.get(url=url, headers=headers, verify=False)
print(response.status_code)
print(response.text)
response_json = response.json()
# time.sleep(3)
df = pd.json_normalize(response_json['data']['areas'], meta=['id', 'name', 'code', 'level', 'ab', 'py'],
record_path='areas', record_prefix='areas.', errors='ignore')
# 输出原始的列名
print(df.columns)
# 列重新排序
df = df.loc[:,
['id', 'name', 'code', 'level', 'areas.id', 'areas.name', 'areas.code', 'areas.level', 'areas.areas',
'areas.py', 'areas.ab', 'ab', 'py']]
# 输出重新排序后的列
print(df.columns)
df.to_excel(f'manner coffee有门店的城市.xlsx', index=False)
print("保存成功!")
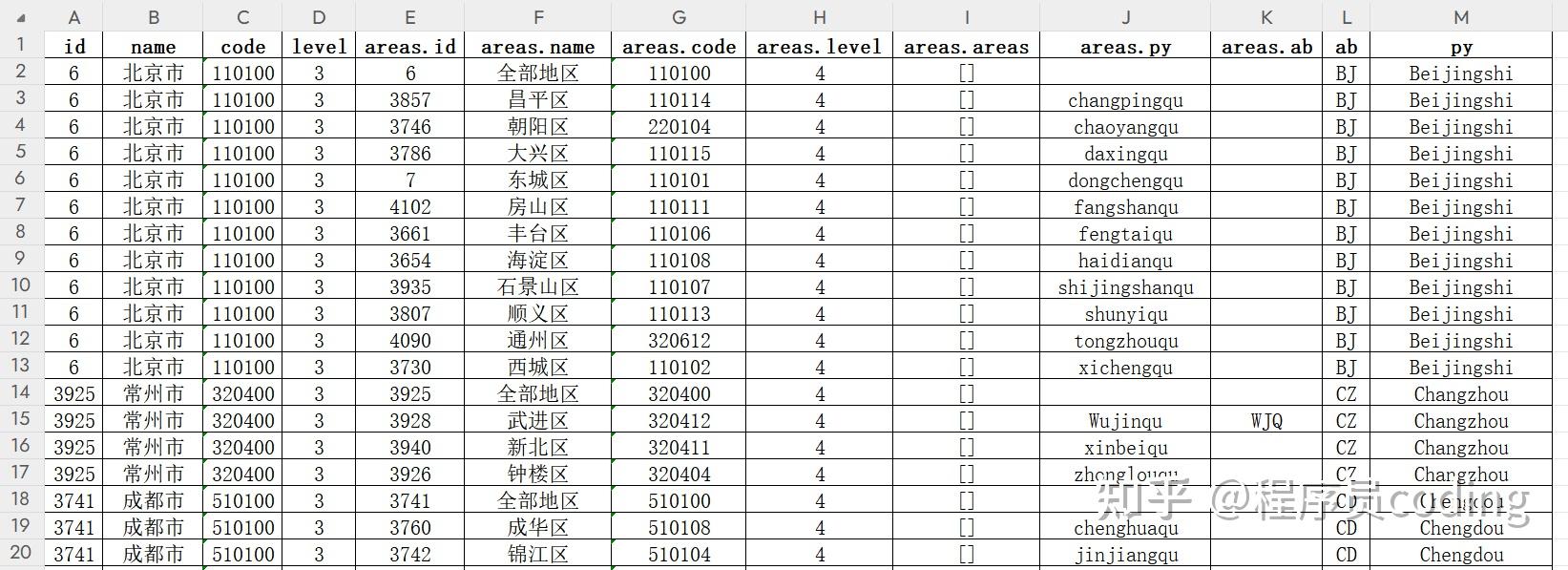
城市保存为 excel 文件,截图如下:
获取门店列表
有了上面的城市列表 excel 文件,就可以获取到areaCode参数,构造门店接口 url 了。同样的,爬虫代码实现顺手捏来。
获取每个城市的门店,保存为一个 excel 文件。全国的门店保存为一个总的 excel 文件。整合代码完美运行,完整代码如下:
import requests
import pandas as pd
import time
from tqdm import tqdm
import urllib3
# 屏蔽https的证书警告
urllib3.disable_warnings()
def get_shops(code, name):
global all_shops
areaCode = code
url = f"https://triangle.wearemanner.com/mp-api/v1/shops?isCompact=true&areaCode={areaCode}&level=4"
headers = {
"Host": "triangle.wearemanner.com",
"Connection": "keep-alive",
"Client-Platform": "MP-WEIXIN",
"user_no": "",
"Client-Host-Language": "zh_CN",
"Device-Brand": "microsoft",
"Client-Host-Version": "3.9.9",
"Encrypted-Type": "N",
"Client-Version": "0.9.6",
"Authorization": "",
"User-Agent": "",
"Device-OS": "Windows 10 x64",
"Content-Type": "json",
"server-api-version": "1",
"Device-Model": "microsoft",
"xweb_xhr": "1",
"version": "0.1.5",
"Accept": "*/*",
"Sec-Fetch-Site": "cross-site",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "https://servicewechat.com/wx4328af055800c98e/120/page-frame.html",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9"
}
response = requests.get(url=url, headers=headers, verify=False)
print(response.status_code)
print(response.text)
shop_json = response.json()
shop_df = pd.json_normalize(shop_json['data'], errors='ignore')
try:
# 列重新排序
shop_df = shop_df.loc[:, ['ac', 'i', 'n', 'a', 'te', 'lo', 'la', 'iw', 'bh', 'sl', 'f',
'q.qc', 'q.mp', 'q.oc', 'q.mc', 'q.wt', 'ta']]
# 部分列重命名
shop_df = shop_df.rename(columns={'a': 'address',
'te': 'telephone',
'ac': 'area_code',
'lo': 'lon',
'la': 'lat',
'n': 'name',
'bh': 'business_hours',
'iw': 'is_work', })
except:
pass
all_shops = pd.concat([all_shops, shop_df])
print(name, "城市有", shop_df.shape[0], "个门店,全国总计有", all_shops.shape[0], "个门店")
shop_df.to_excel(f'manner coffee门店-{name}-{shop_df.shape[0]}个.xlsx', index=False)
time.sleep(3)
return all_shops
if __name__ == '__main__':
all_shops = pd.DataFrame()
city_df = pd.read_excel("manner coffee有门店的城市.xlsx")
# mask标记'areas.name'等于'全部地区'的行
mask = city_df['areas.name'] == '全部地区'
# city_code_name筛选'areas.name'等于'全部地区的datafram
city_code_name = city_df[mask]
# tqdm显示进度条
tqdm.pandas(desc='获取manner coffee门店进度条', unit="请求")
# 调用函数,批量获取每个城市的门店,使用tqdm时,将pandas中apply操作替换为progress_apply,并且每个单独的progress_apply前要先执行tqdm.pandas()
city_code_name.progress_apply(lambda x: get_shops(x['code'], x['name']), axis=1)
print(f'获取到manner coffee{all_shops.shape[0]}个全国门店')
all_shops.to_excel(f'manner coffee全国门店-{all_shops.shape[0]}个.xlsx', index=False)
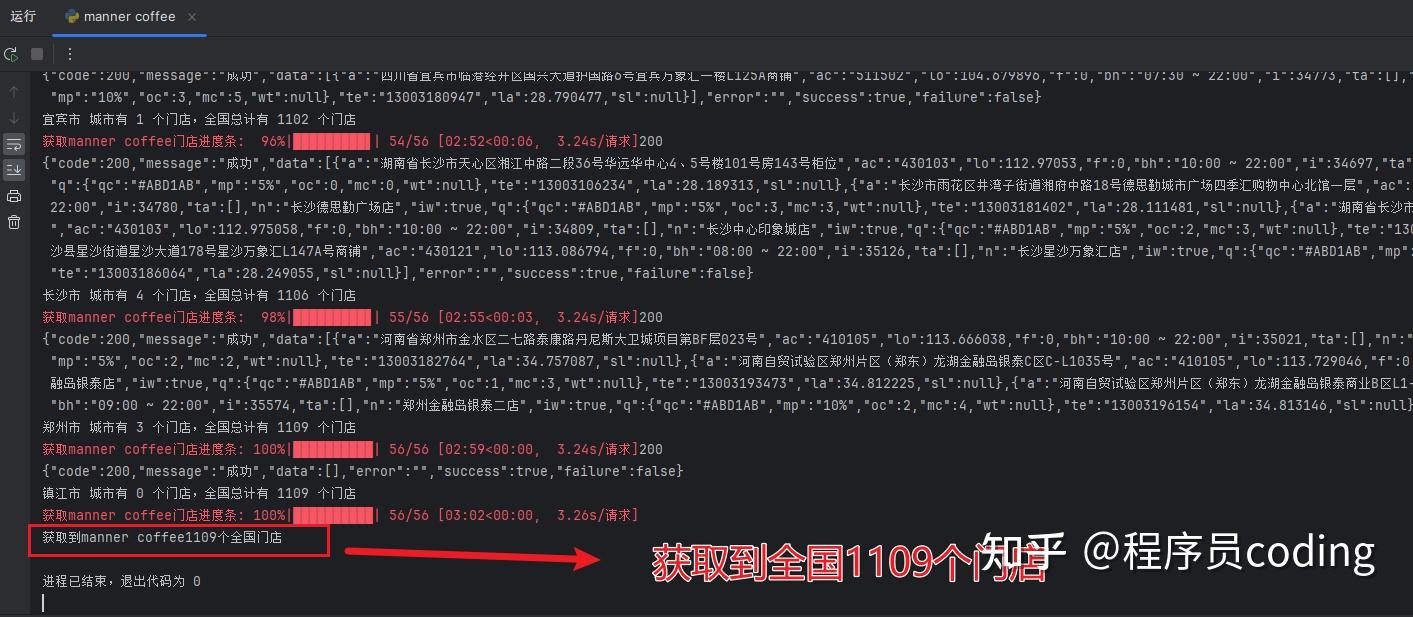
pycharm 控制台输出如下,用时 3 分钟,通过 56 次请求,获取到全国 1109 个门店:
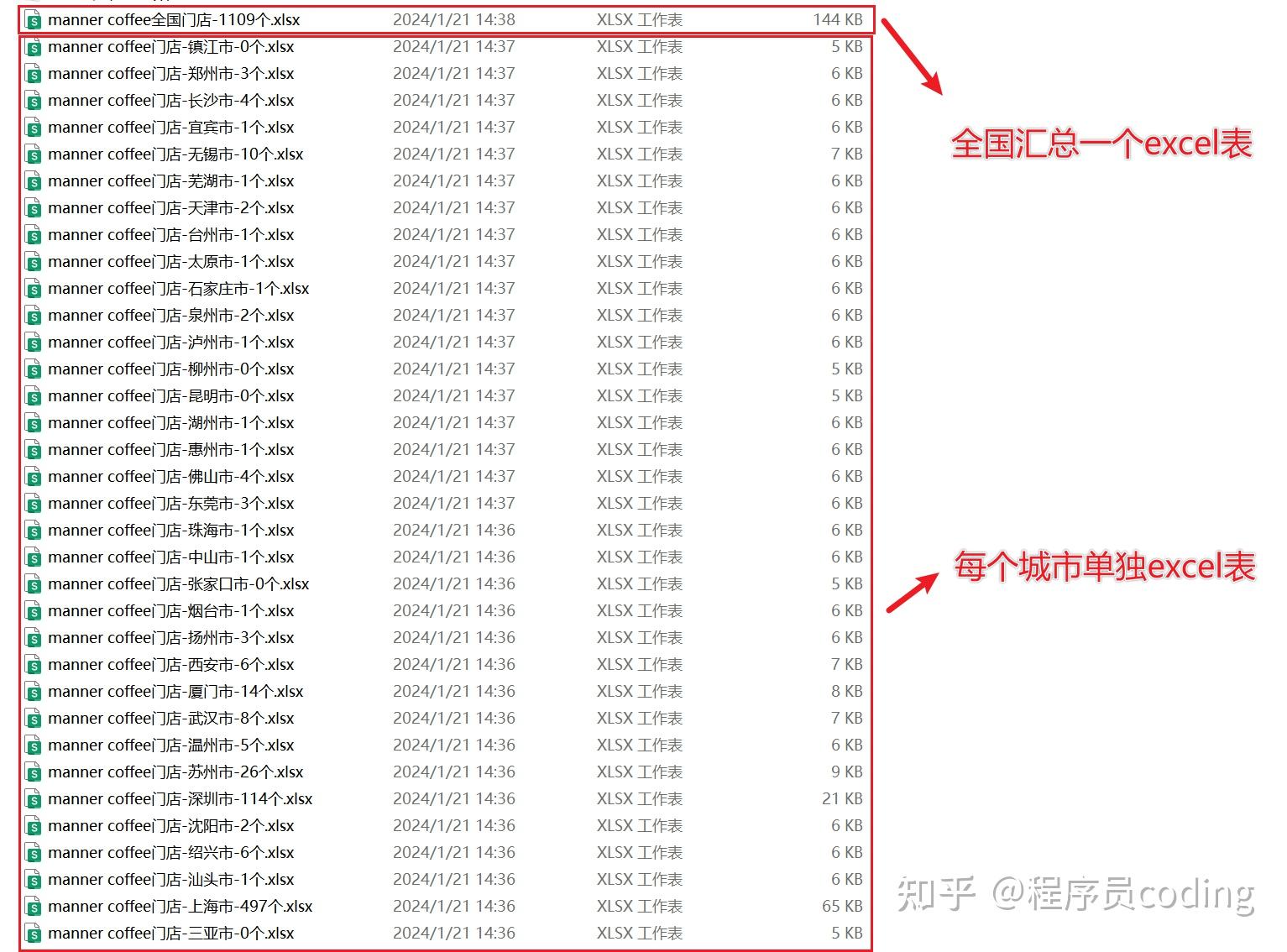
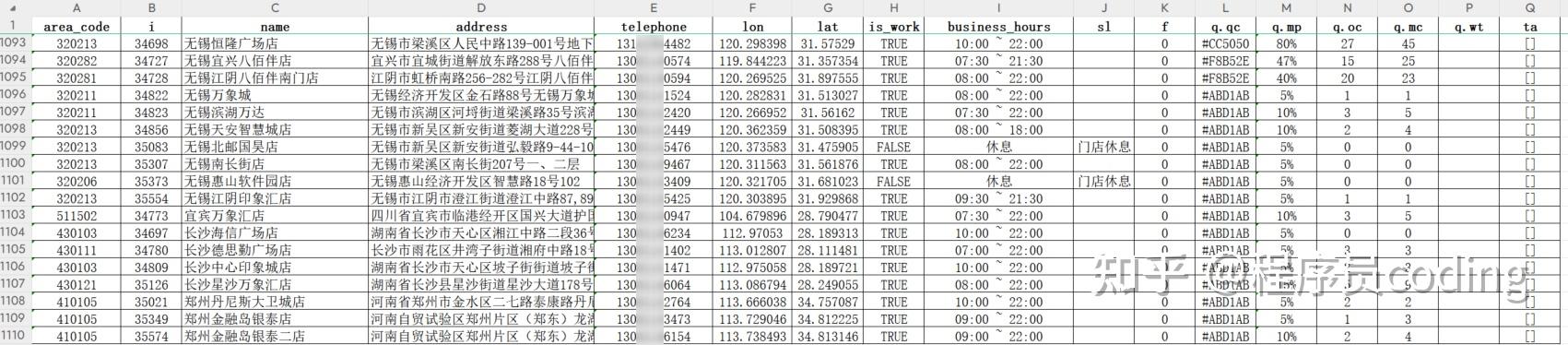
生成的 excel 表如下,每个城市单独保存一个 excel 表,全国汇总成一个 excel 表。
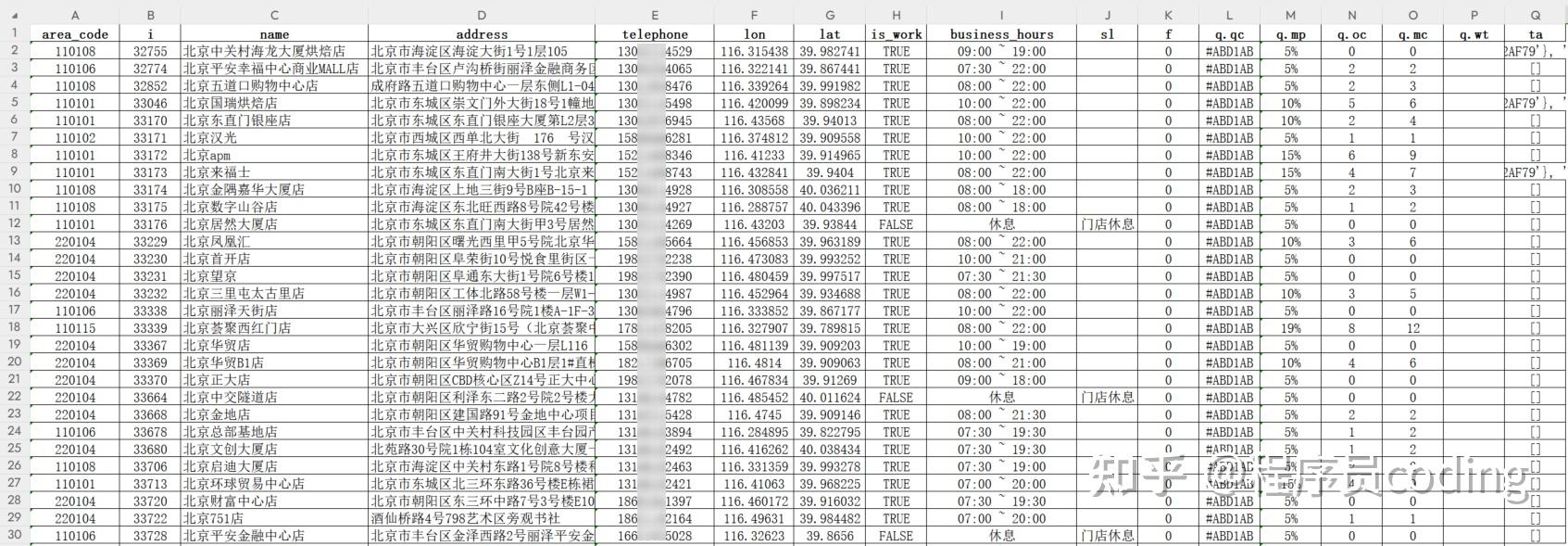
在生成每个 excel 表前,通过代码做了字段排序和重命名。截图如下:
总结
写程序是一个不断 debug 的过程,需要多查找资料,多尝试。
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。
数据集已经上传到公众号,后台回复“Manner Coffee”可以自取。
以上就是“Python实战:解决了小程序抓包返回400状态码问题”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









