










本文主要讲解如何使用Idea开发Spark程序,使用Maven作为依赖管理,当然也可以使用SBT,但是由于一直写Java程序习惯用Maven了,所以这里使用Maven。
1、下载安装Jdk、Scala、Mave
Jdk、Maven安装方法略过,搞Java的应该都会,这里讲一下Scala的安装,其实和Java差不多。
首先下载:https://www.scala-lang.org/download/
按步骤安装,安装完成以后配置Scala的环境变量即可:
SCALA_HOME=D:\scala
PATH=......;%SCALA_HOME%\bin进入CMD输入:scala -version

2、下载Idea并安装Scala插件
下载地址随便上网找一下就可以,不建议官网下载,速度太慢。
老哥用的是2016版本的,需要的在这下载,里面有安装包和破解方法,请叫我雷锋
链接:http://pan.baidu.com/s/1gfvG3R1 密码:9p3y
下载完成以后按照提示进行配置。
偏好暗黑主题
默认
下载Scala插件
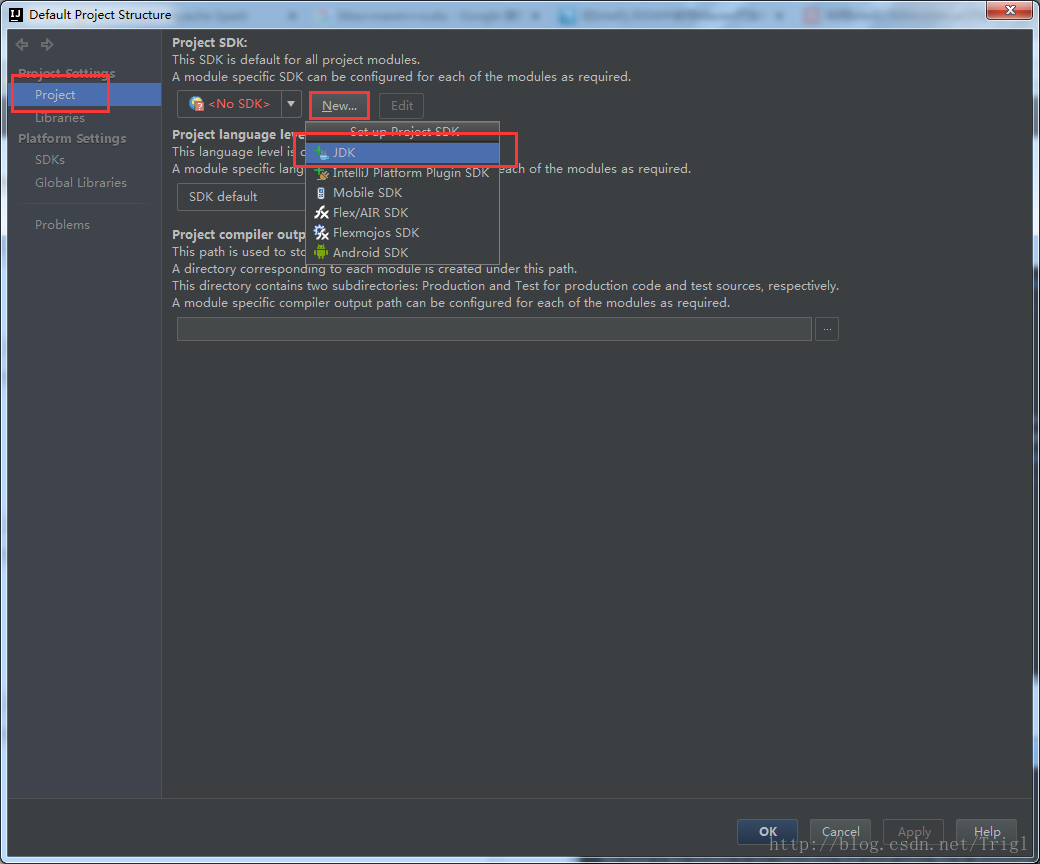
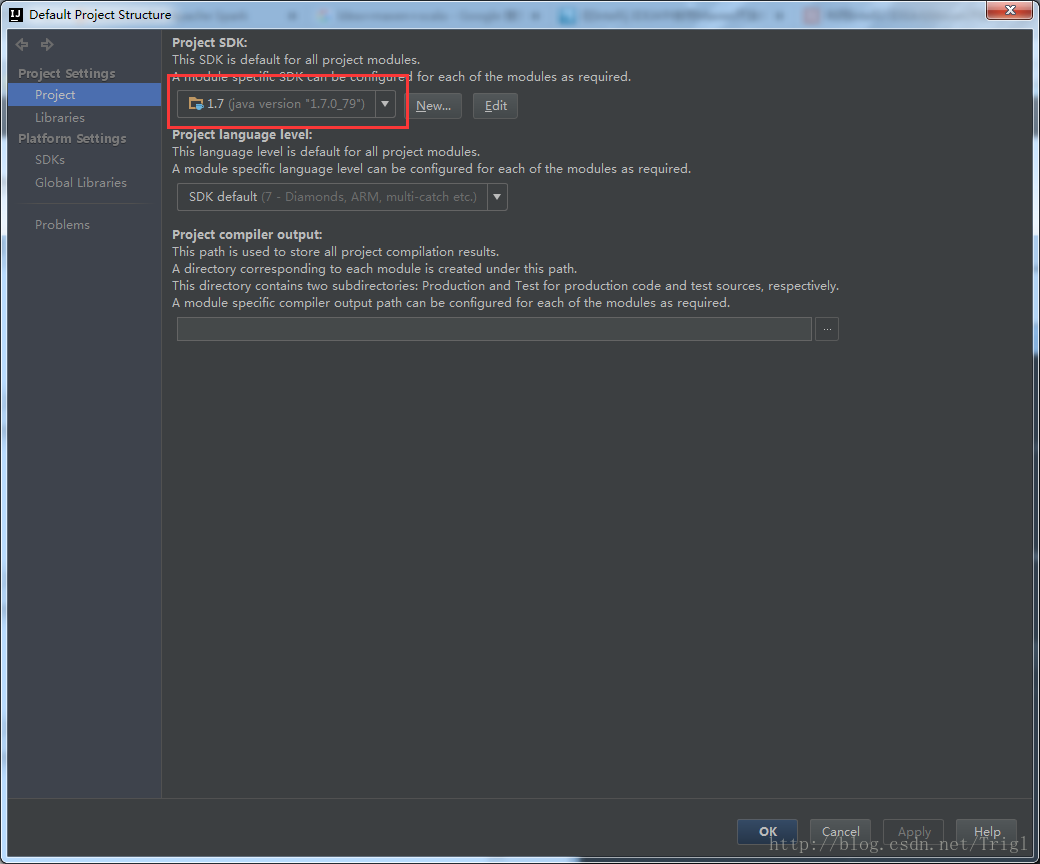
设置Jdk
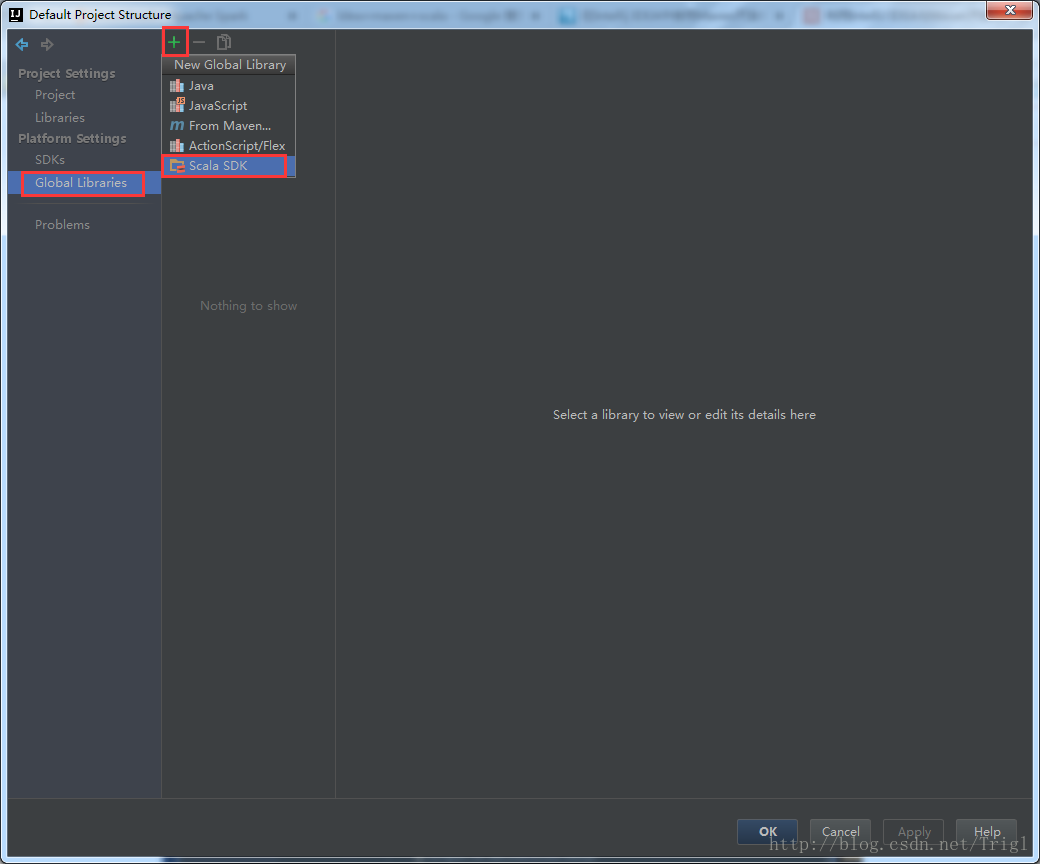
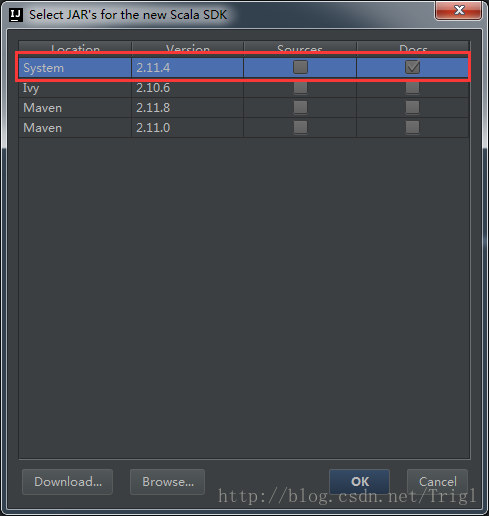
设置Scala
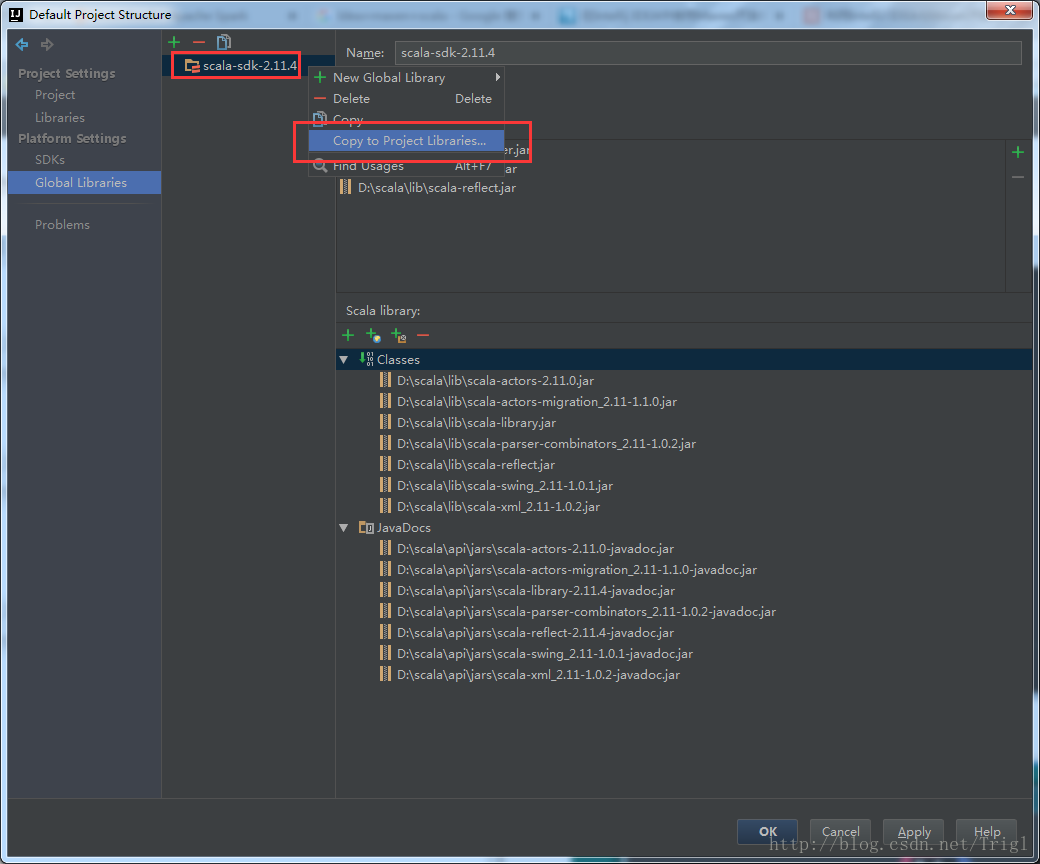
3、创建一个maven-scala工程

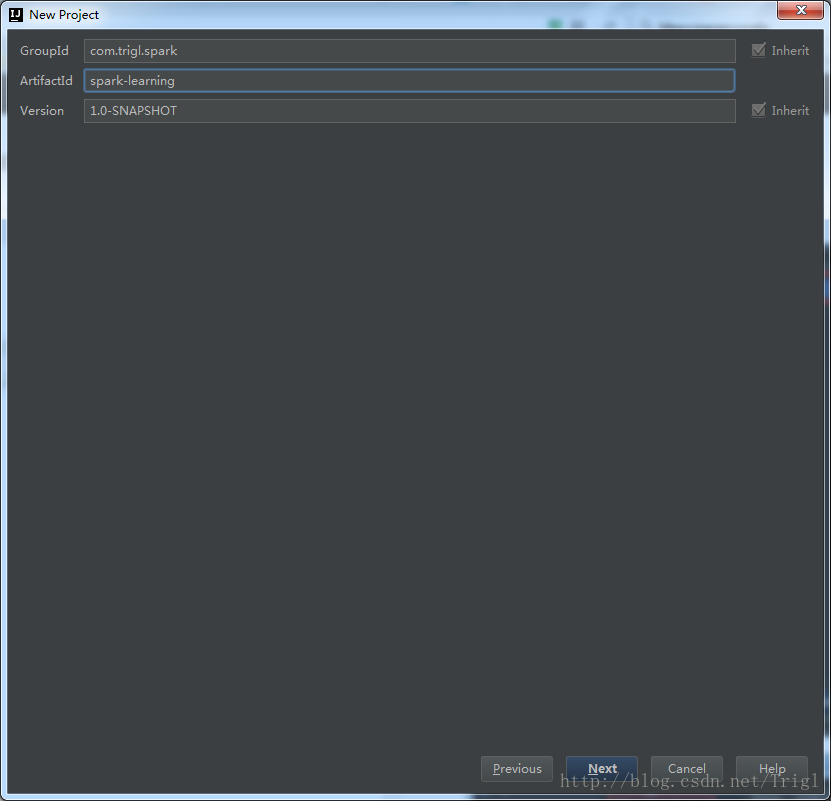
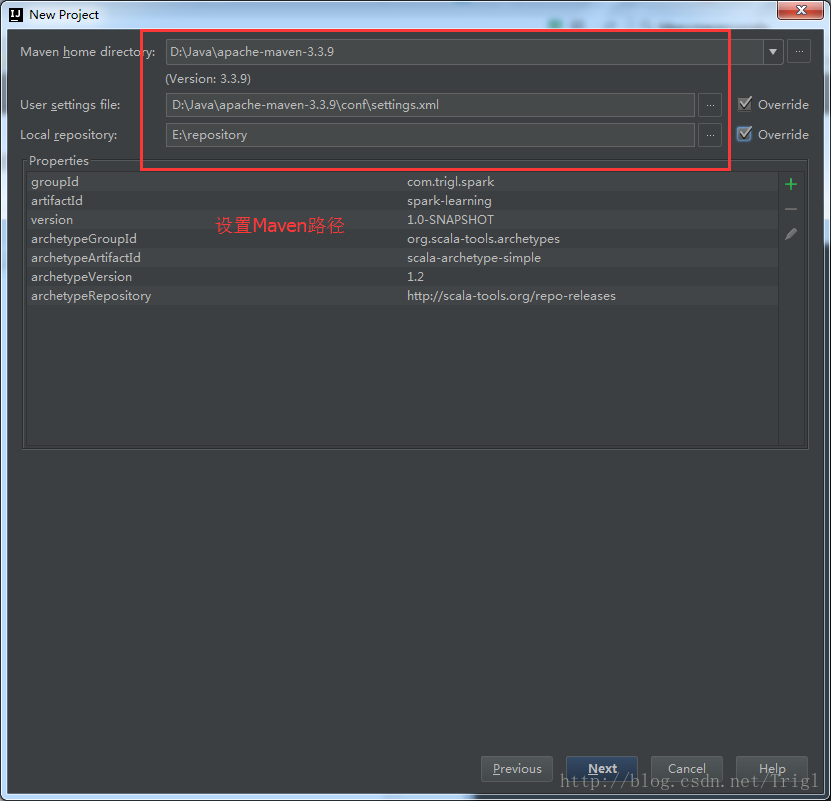
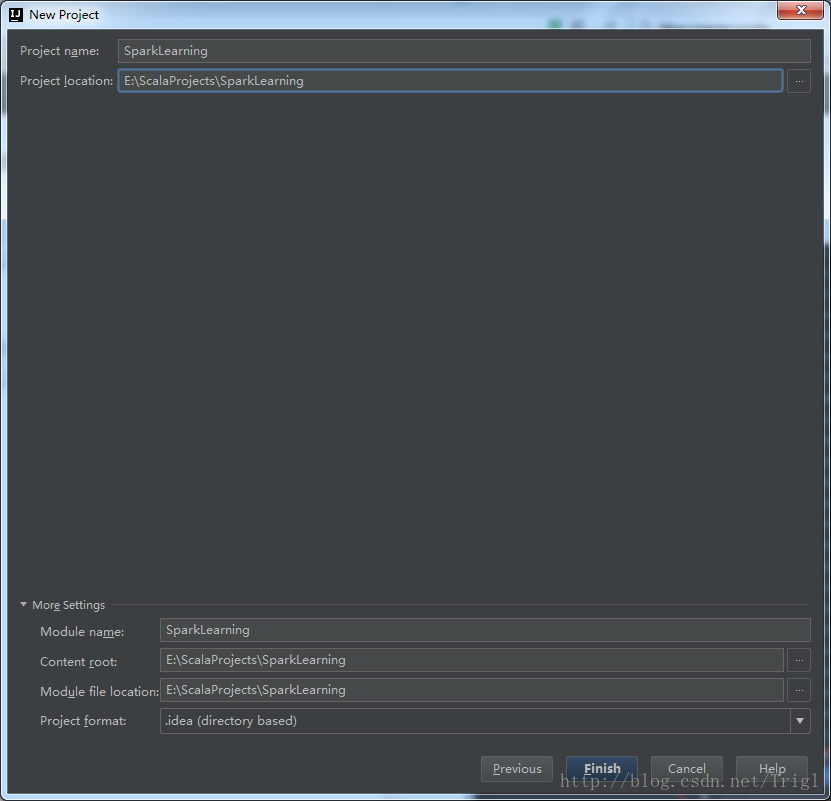
4、修改pom.xml
首先将scala.version修改成本机安装的Scala版本,其次加入hadoop以及spark所需要的依赖,完整的内容如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trigl.spark</groupId>
<artifactId>spark-learning</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.4</scala.version>
<spark.version>2.0.0</spark.version>
<spark.artifact>2.11</spark.artifact>
<hbase.version>1.2.2</hbase.version>
<dependency.scope>compile</dependency.scope>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${spark.artifact}</artifactId>
<version>${spark.version}</version>
<scope>${dependency.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${spark.artifact}</artifactId>
<version>${spark.version}</version>
<scope>${dependency.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${spark.artifact}</artifactId>
<version>${spark.version}</version>
<scope>${dependency.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${spark.artifact}</artifactId>
<version>${spark.version}</version>
<scope>${dependency.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>${spark.version}</version>
<scope>${dependency.scope}</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>5、写Spark测试程序
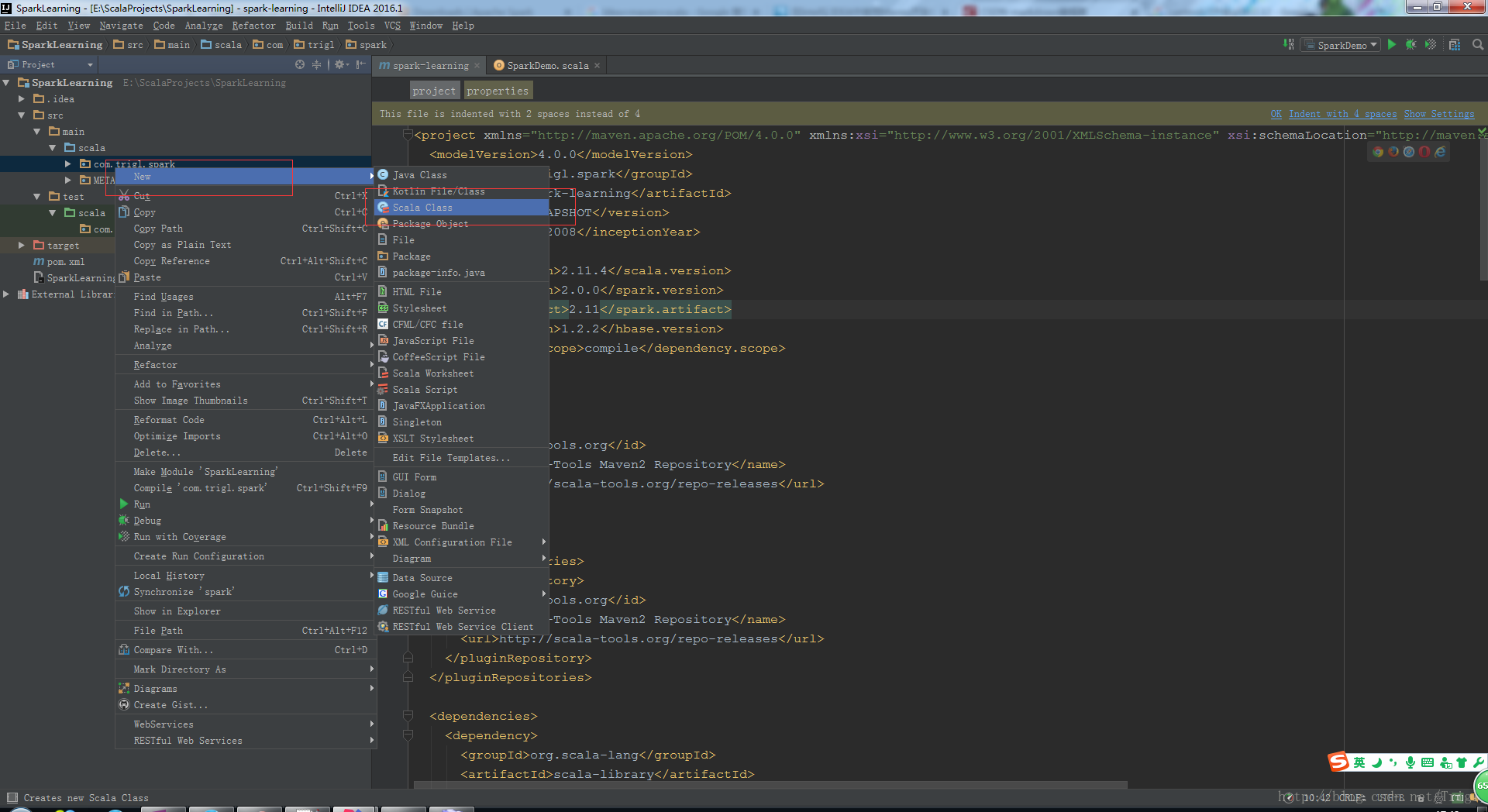
将系统生成的Scala代码删除,我们自己新建一个Scala Object
SparkDemo.scala代码如下:
package com.trigl.spark
import org.apache.spark.{SparkConf, SparkContext}
/**
* 统计hdfs文件行数
* Created by Trigl on 2017/4/20.
*/
object SparkDemo {
// args:/test/test.log
def main(args: Array[String]) {
// 设置Spark的序列化方式
System.setProperty("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 初始化Spark
val sparkConf = new SparkConf().setAppName("CountDemo")
val sc = new SparkContext(sparkConf)
// 读取文件
val rdd = sc.textFile(args(0))
println(args(0) + "的行数为:" + rdd.count())
sc.stop()
}
}6、打包运行
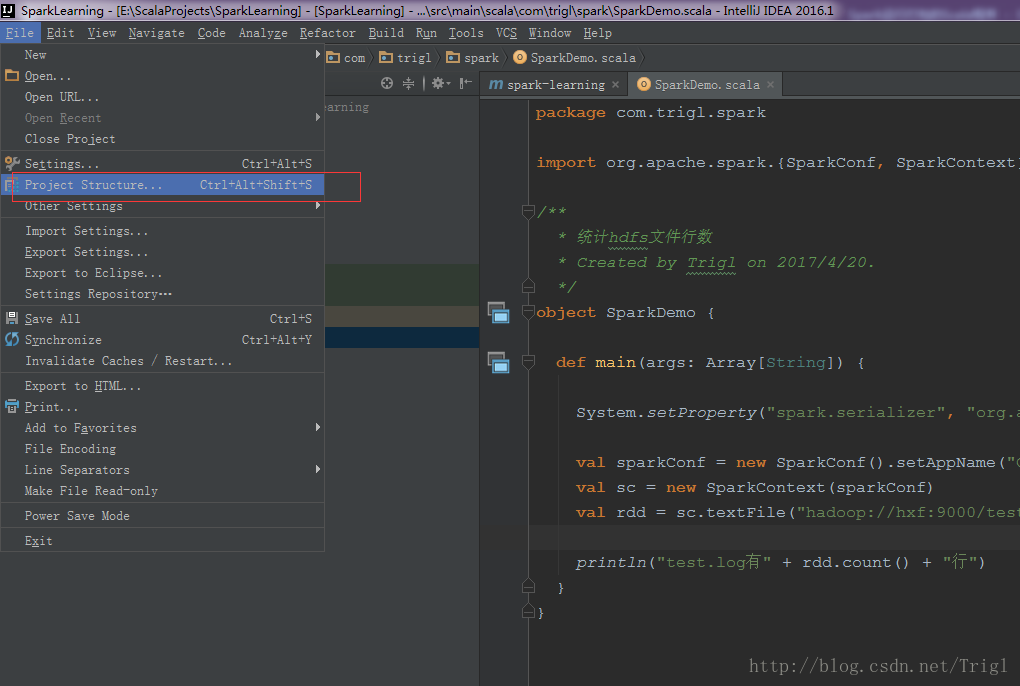
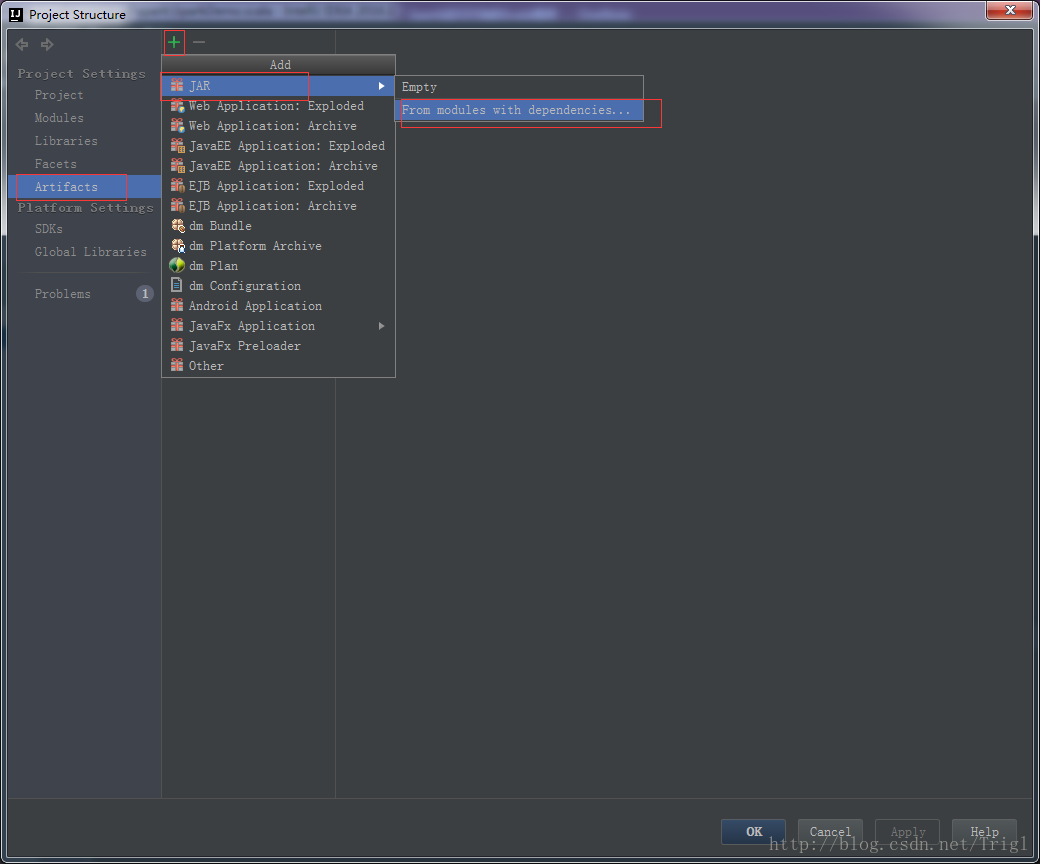
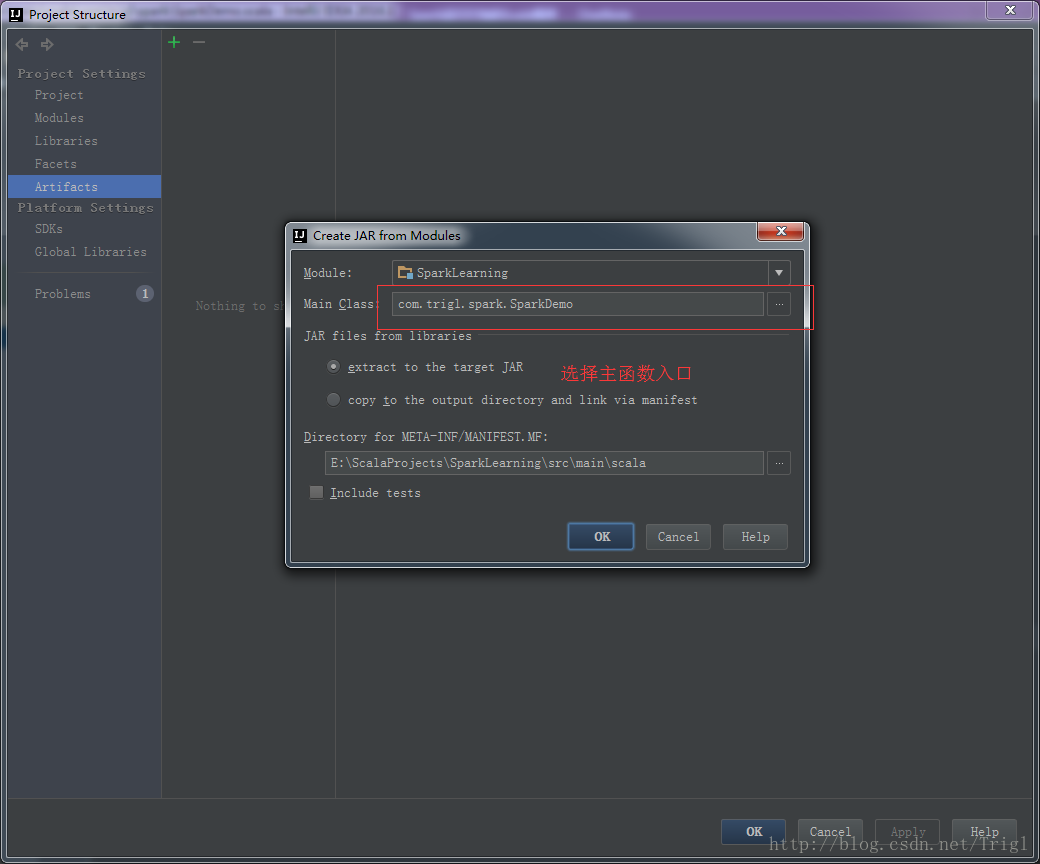
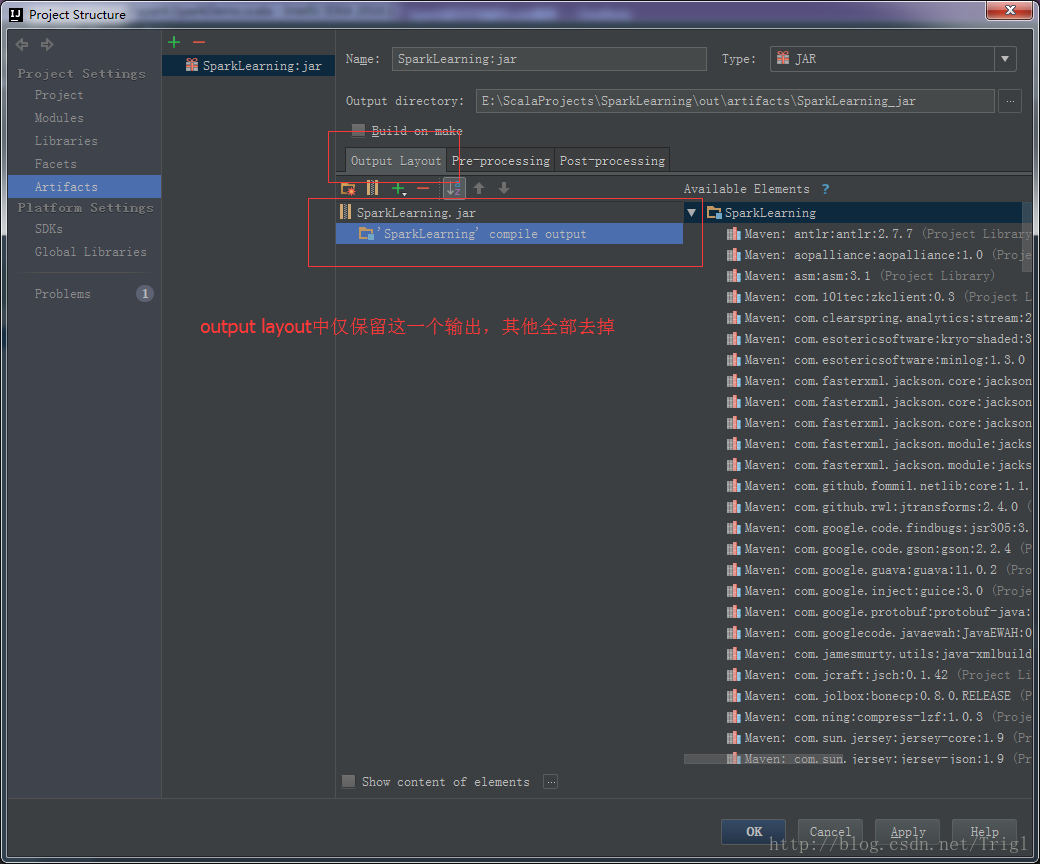
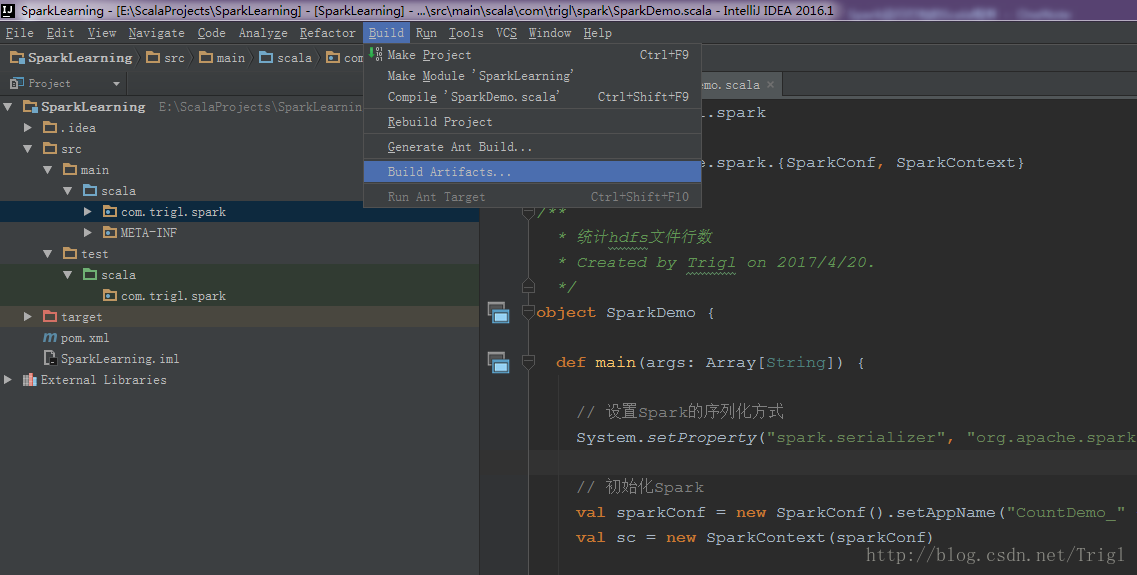
输出打包文件:点击菜单Build->Build Artifacts,弹出选择动作,选择Build或者Rebuild动作
打包后的jar包在项目的out目录下面,将此jar包复制到运行Spark所在的主机上,然后在该机器执行以下命令即可:
nohup /data/install/spark-2.0.0-bin-hadoop2.7/bin/spark-submit --master spark://hxf:7077 --executor-memory 1G --executor-cores 4 --class com.trigl.spark.SparkDemo /home/hadoop/jar/SparkLearning.jar /test/test.log >> /home/hadoop/logs/sparkDemo.log &结果如下:
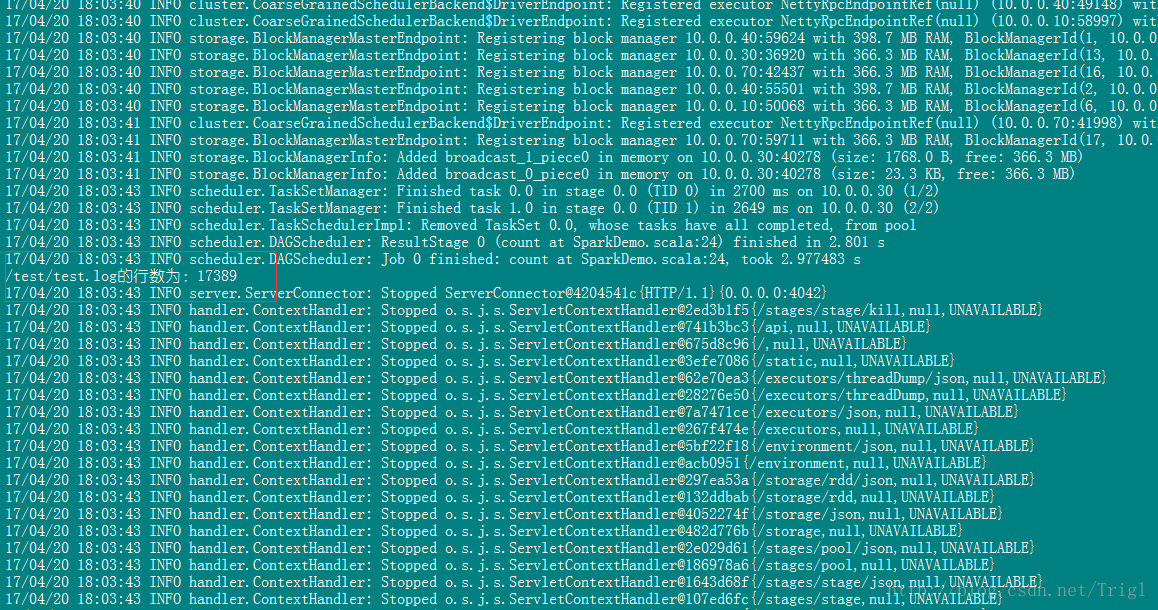
这就是我们编写的第一个Spark程序,非常简单,大牛勿喷,但这是万里长征第一步,至少程序已经能跑了不是吗?后续我会循序渐进介绍Spark的知识,欢迎交流指正。















 5410
5410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









