






毕业设计:基于YOLOv8和卷积神经网络的车牌识别
本文介绍的系统的优势
本文介绍的系统是挂载在驱动云的云GPU上的,大部分的云GPU都是需要花钱的,但是驱动云这个GPU你注册会送给你160元的额度(记得跑完代码就关掉,别让其额度一直跑),对于跑毕业设计的我们来说是够了,这样就免去了环境的配置,所以说跟着本文完整的做下来是能够识别车牌,并且识别车牌上的字符,还能识别车牌的颜色,对于做毕业设计来说是够够的了。
一、车牌识别是什么?
车牌识别就是输入一张图片,能够把其中的车牌识别出来,并且识别车牌中的文字,方便我们进行车牌的管理。
二、运行步骤步骤
驱动云网址:https://account.virtaicloud.com/gemini_web/auth/login
注册一个账号,然后登陆进去就好了。
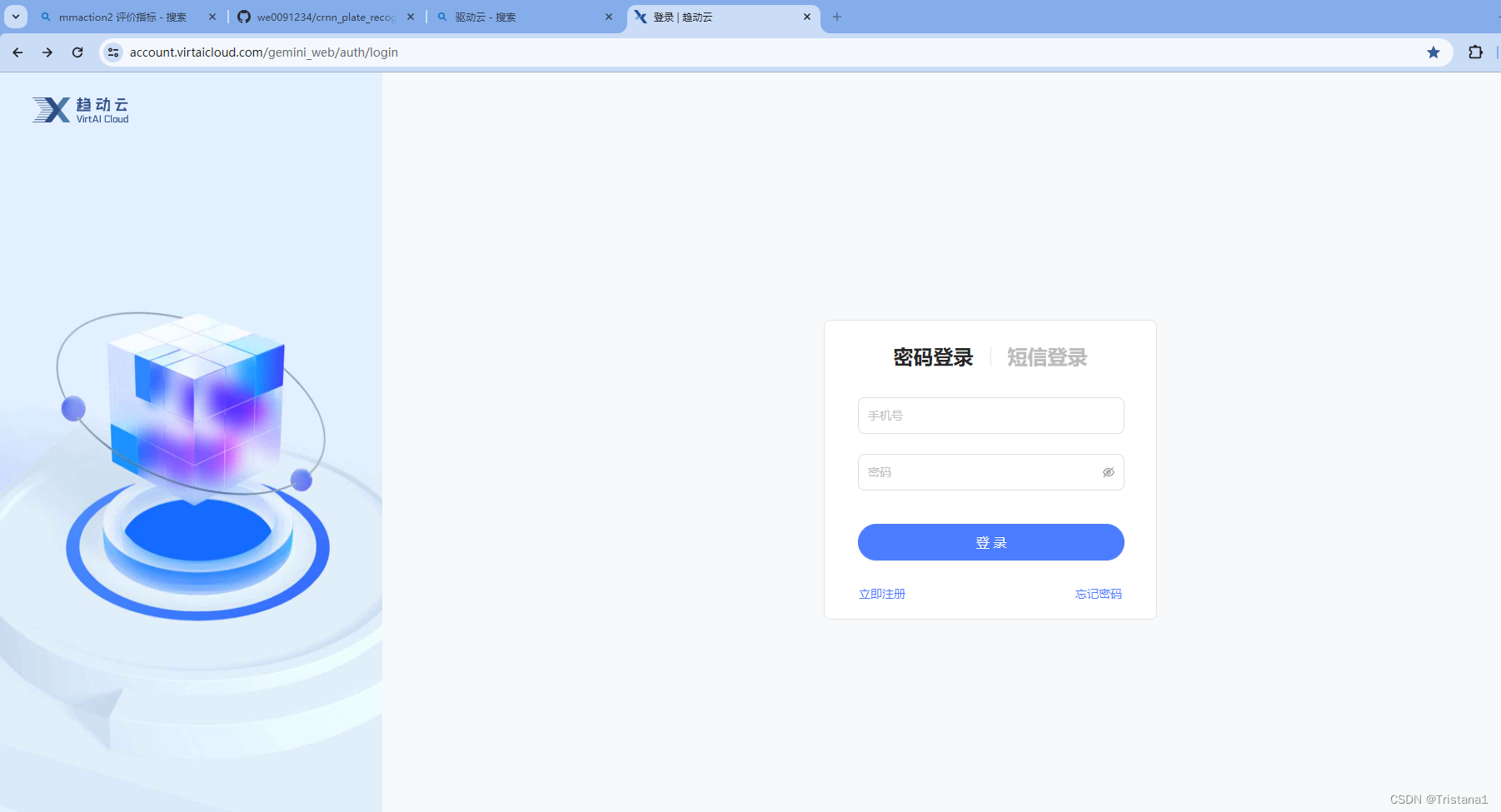
登录进来之后进入项目的界面,如果你们是新注册的账号的话应该是空的。
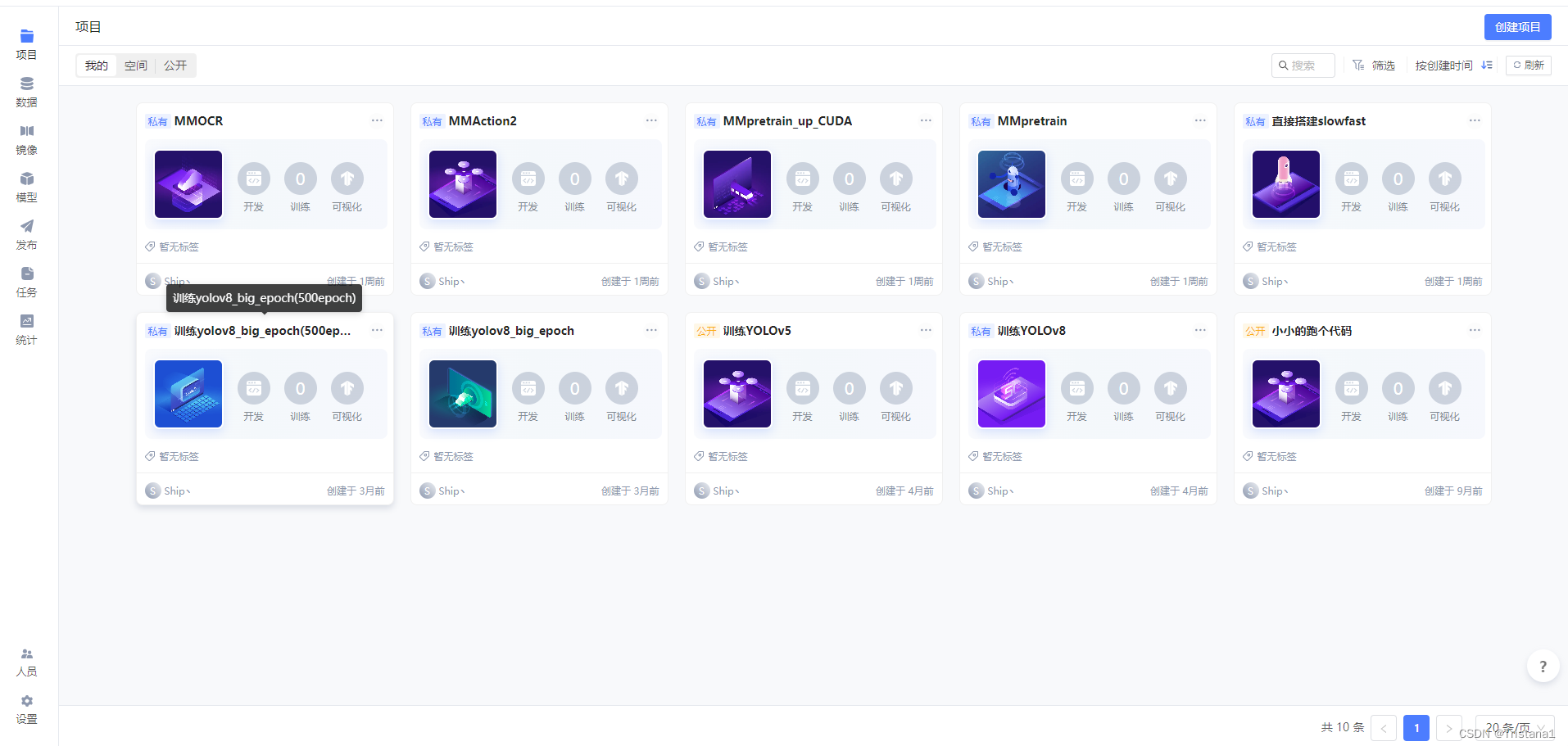
然后点击右上角的创建项目,然后项目名称和项目描述就可以随便写一写
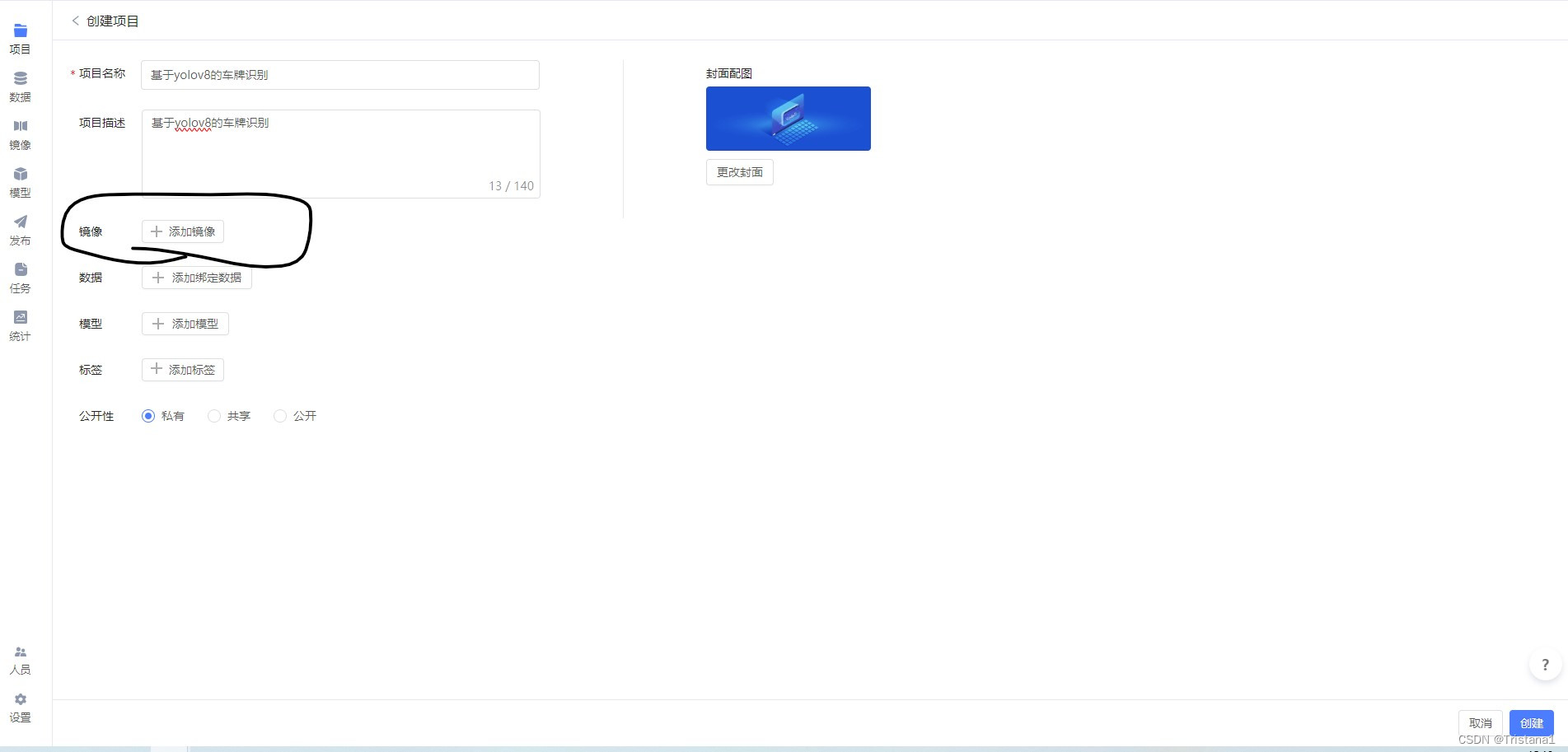
然后就是添加镜像了,这里我们选择相应的PyTorch的框架就可以了,如果是小白什么都不懂的话直接和我用一样的就行了,直接选中左边的筛选,然后选择最上面这个就可以了,这样就跳过了繁琐的配置PyTorch的过程。然后直接点击创建,然后就等待配置环境。
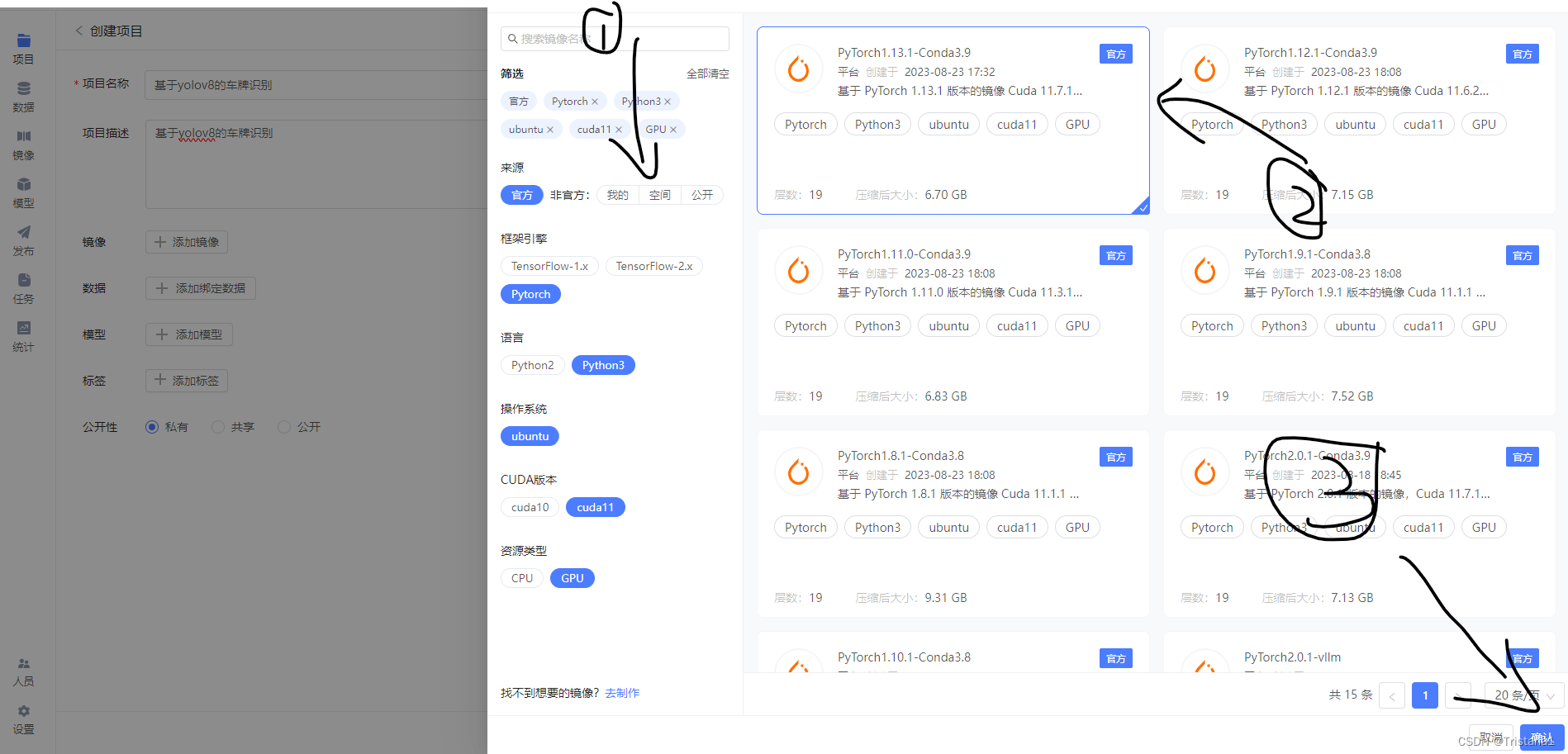
然后直接创建就可以了,别的就不用选了,公开性选择私有把,如果是公开的话别能就能看到你的程序了,后续你想做一些调式什么的也就暴露在别人的视野之下了。
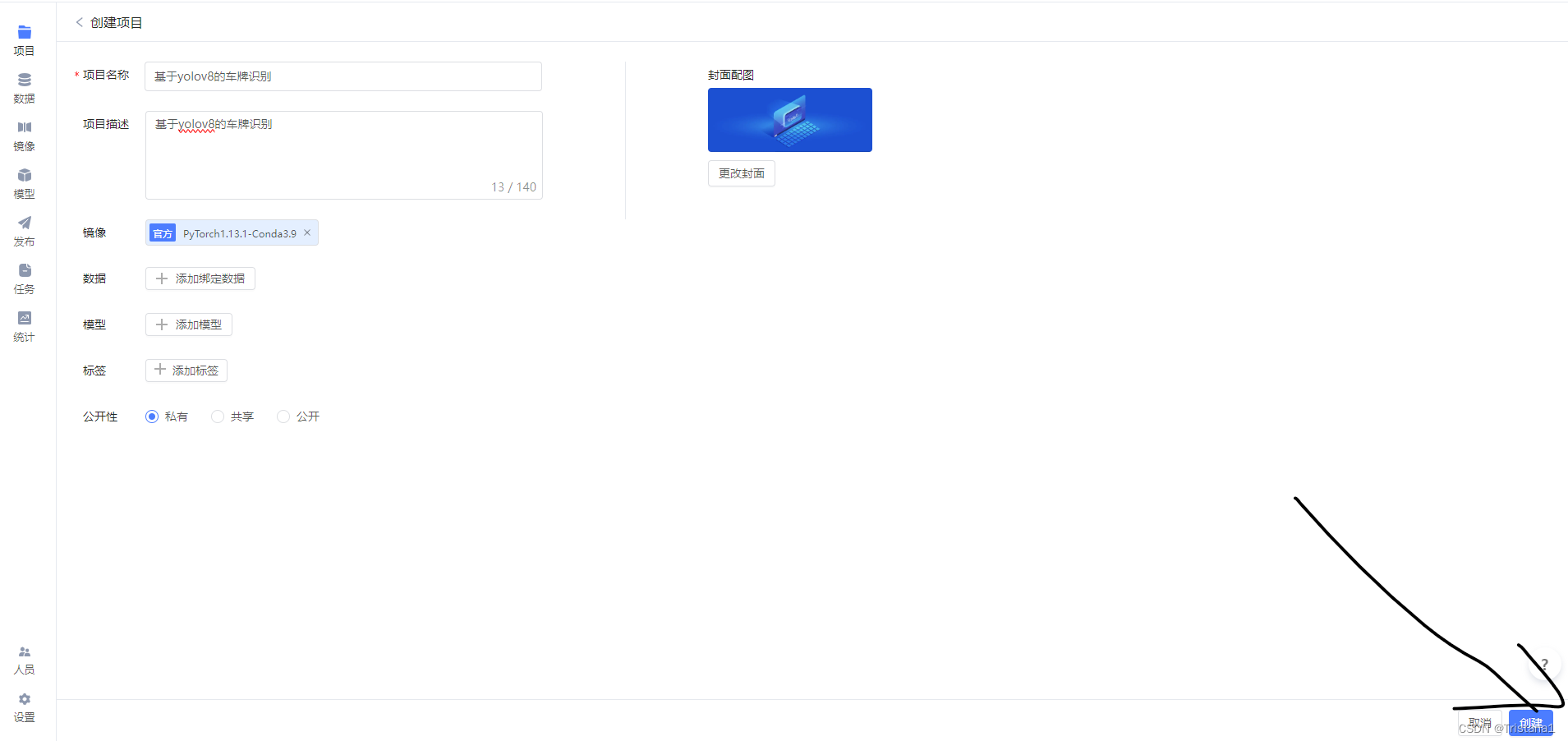
然后直接把我们的代码文件拖入进来,等他进行上传成功之后点击确定。
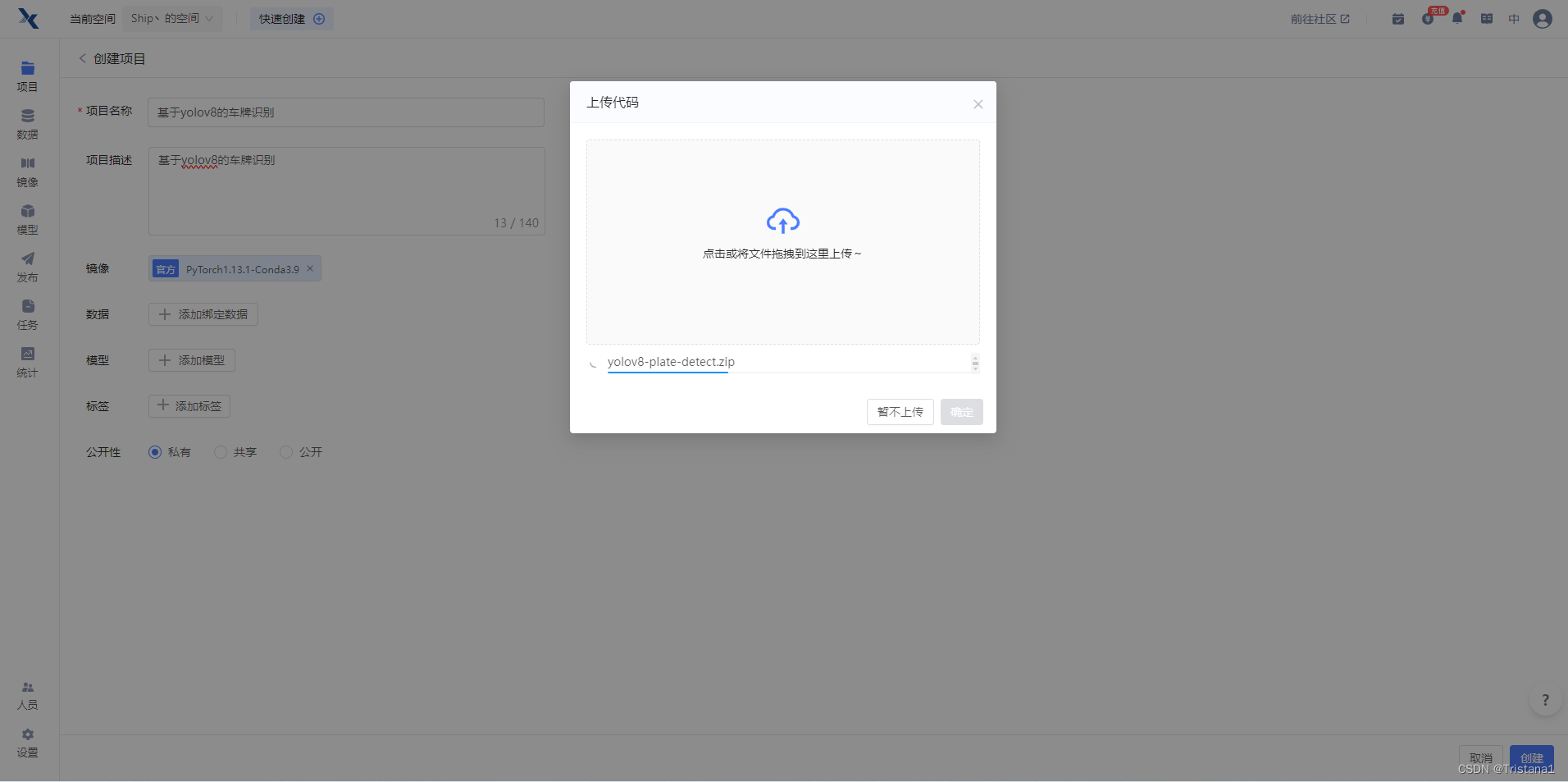
然后进入到下面的界面之中,点击运行代码,让实例环境展开
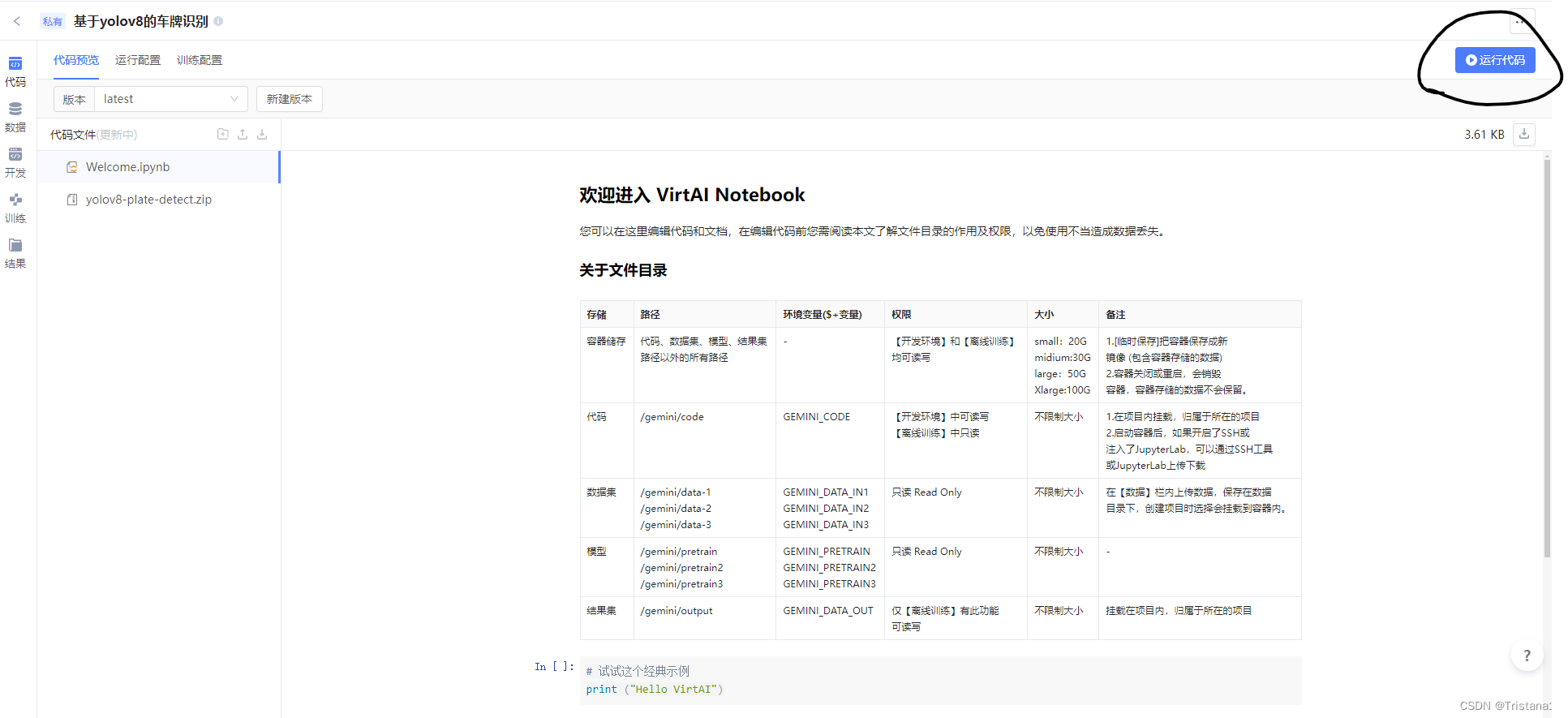
然后选择资源配置,我们选择最下的这一个就好了,然后点击确定。
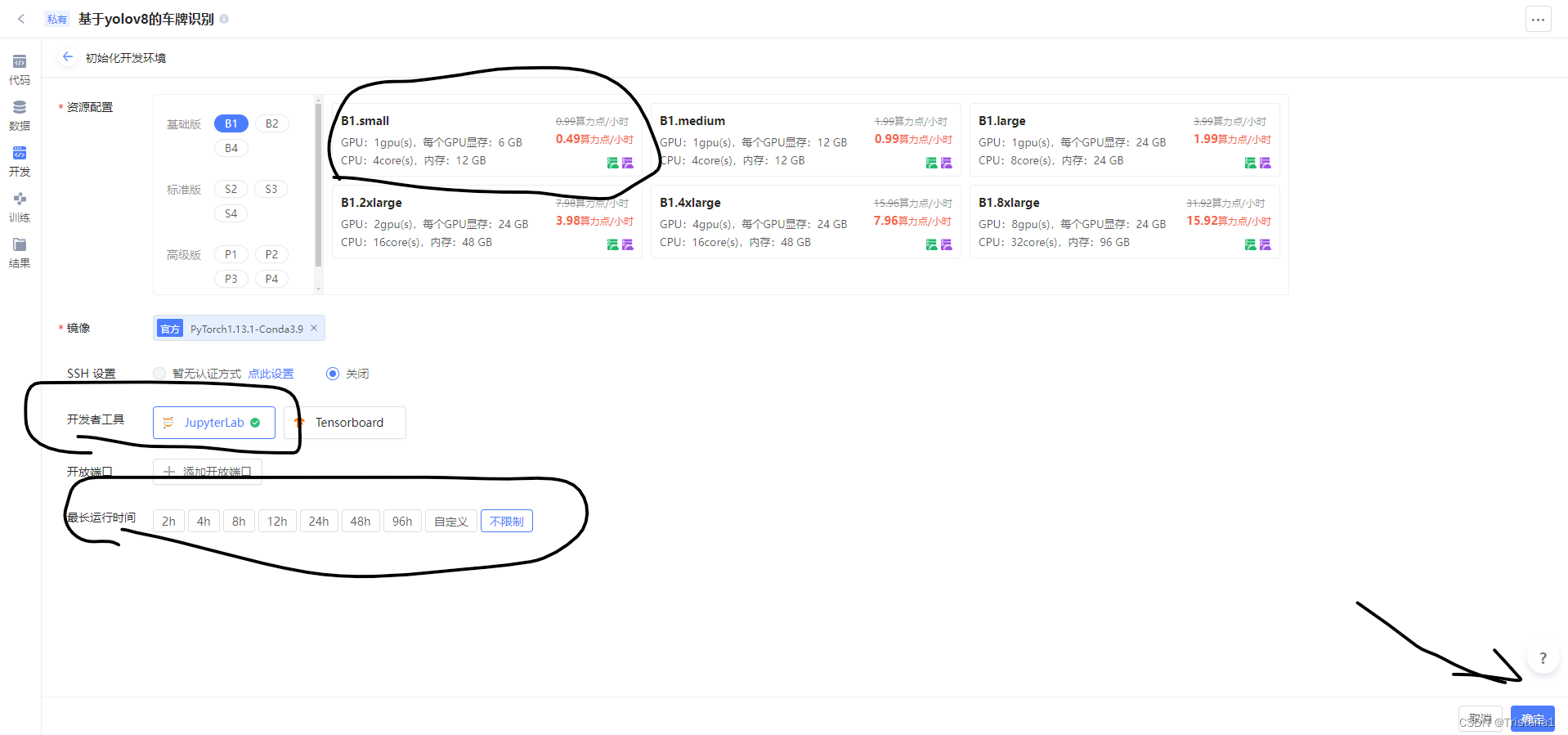
然后我们就会进入开发实例界面,等待一会,然后就会进入下面的界面,等到右上角的进入开发环境装载好,我们点击进入开发环境。
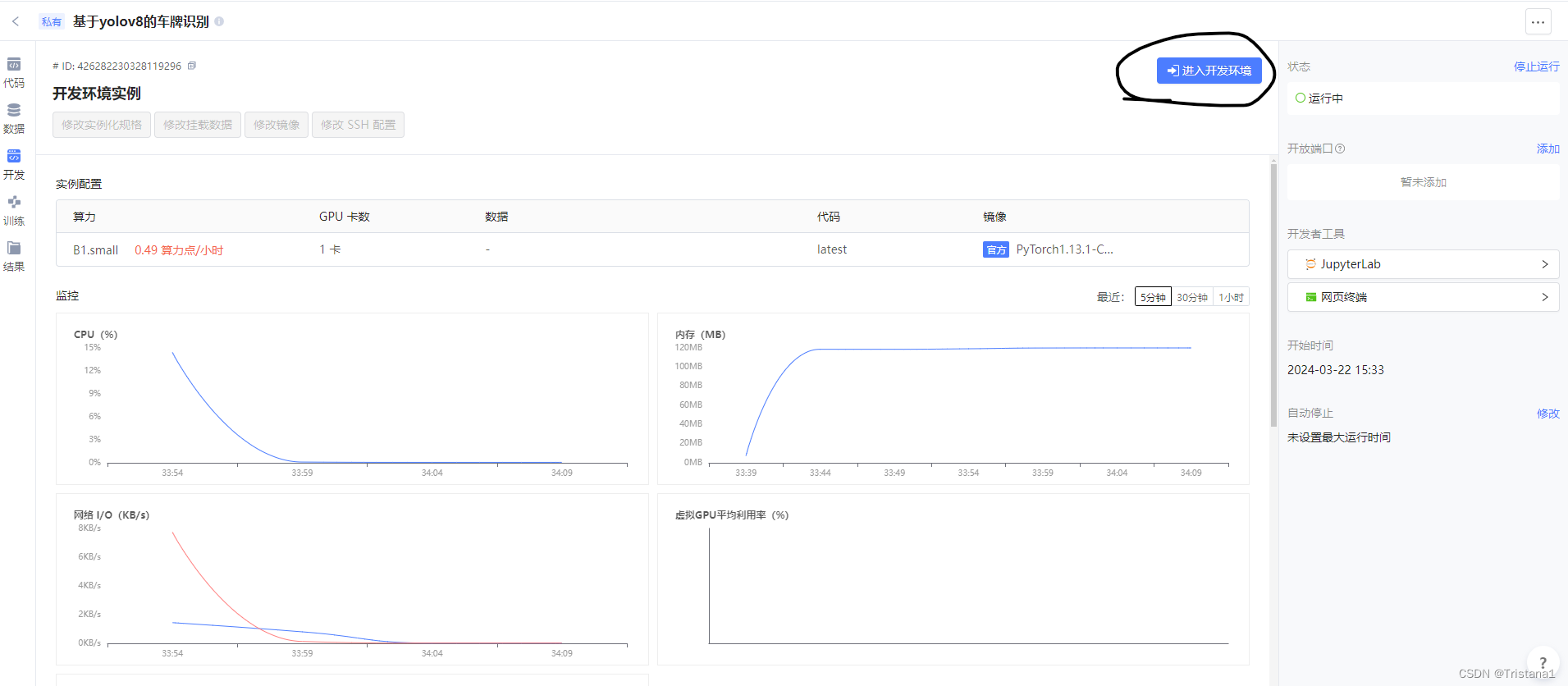
然后就会进入到下面的界面
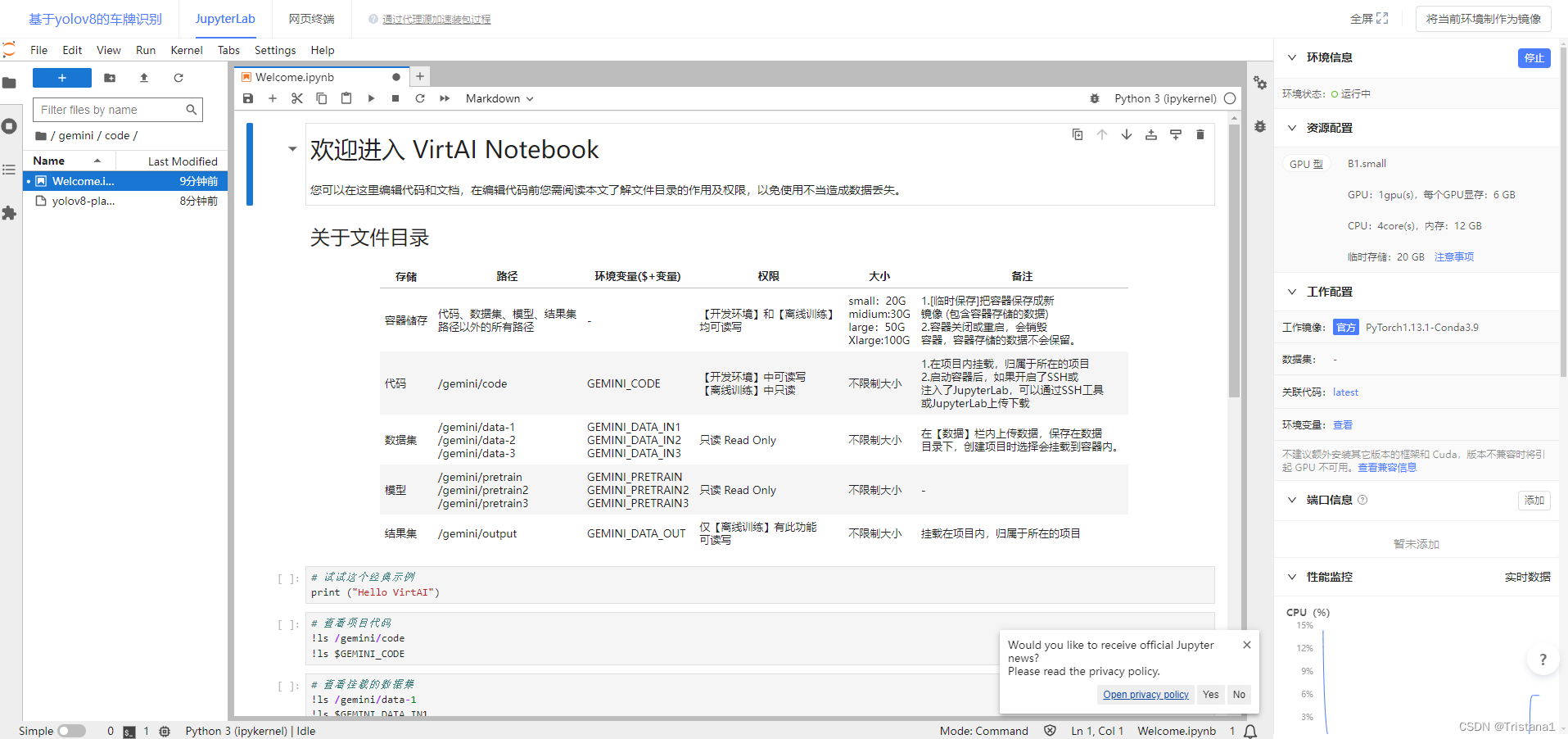
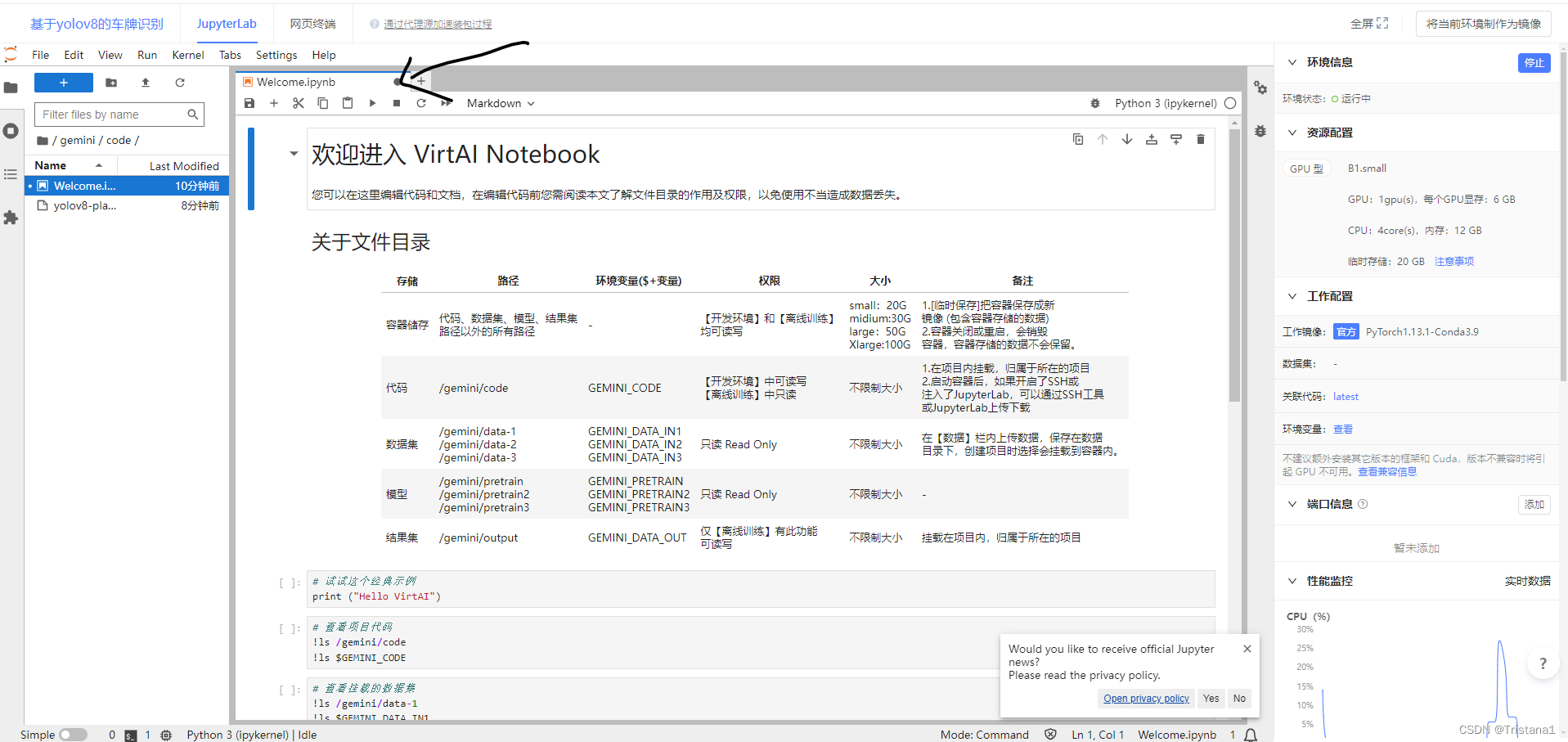
然后把这个welcome关掉,我们自己新写一个Notebook
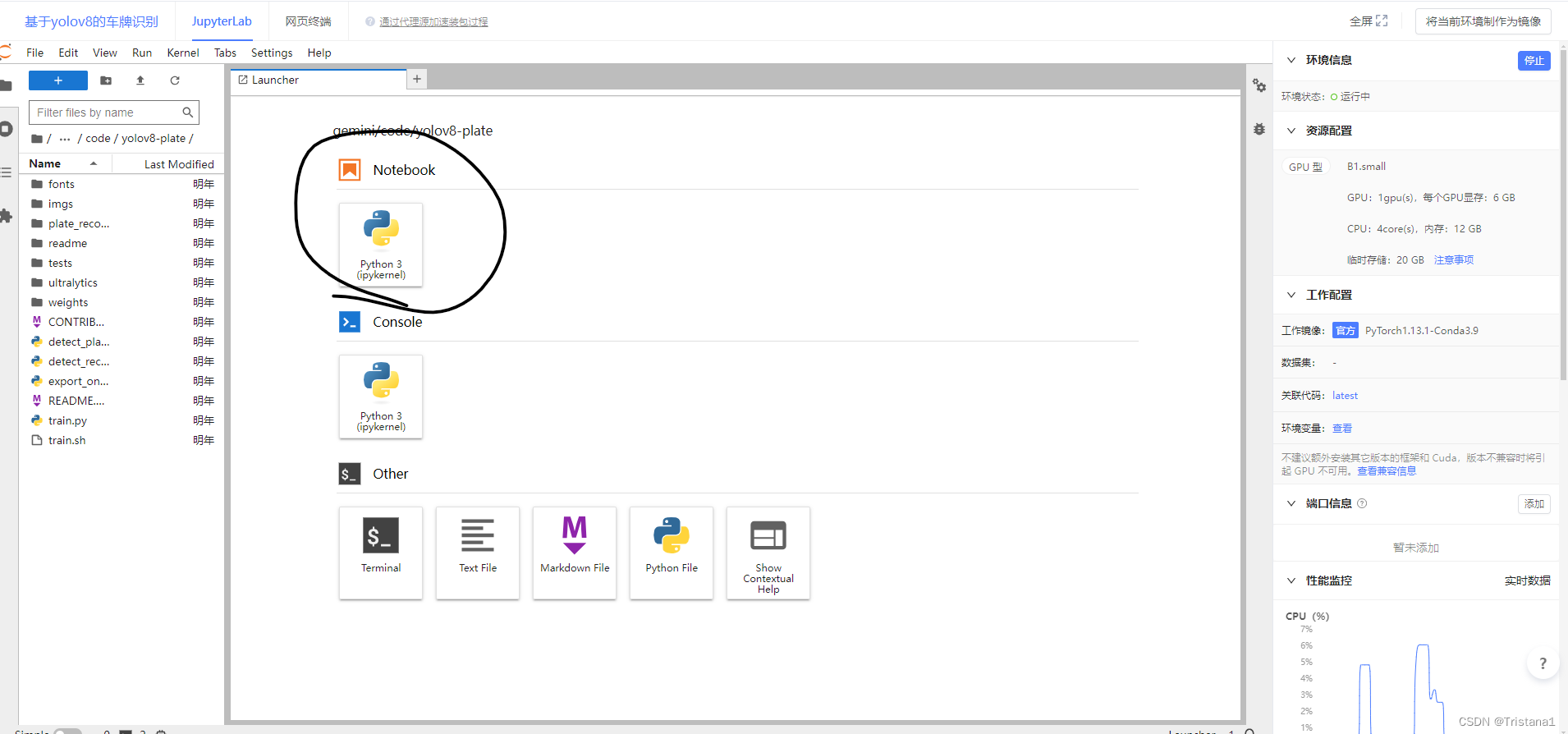
点击Notebook上面的Python3来创建一个Notebook
在里面写上上面的命令,然后Ctrl+回车解压当前的压缩包
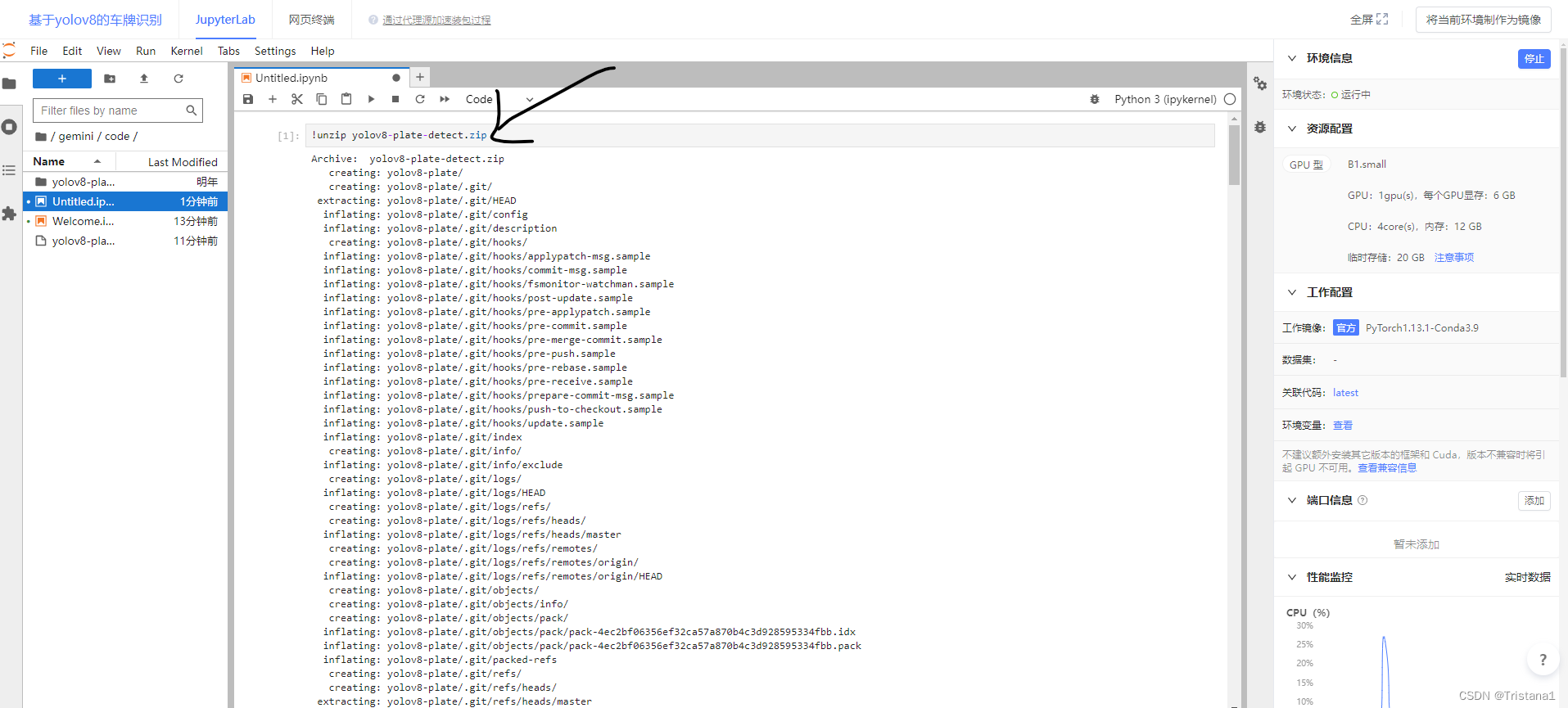
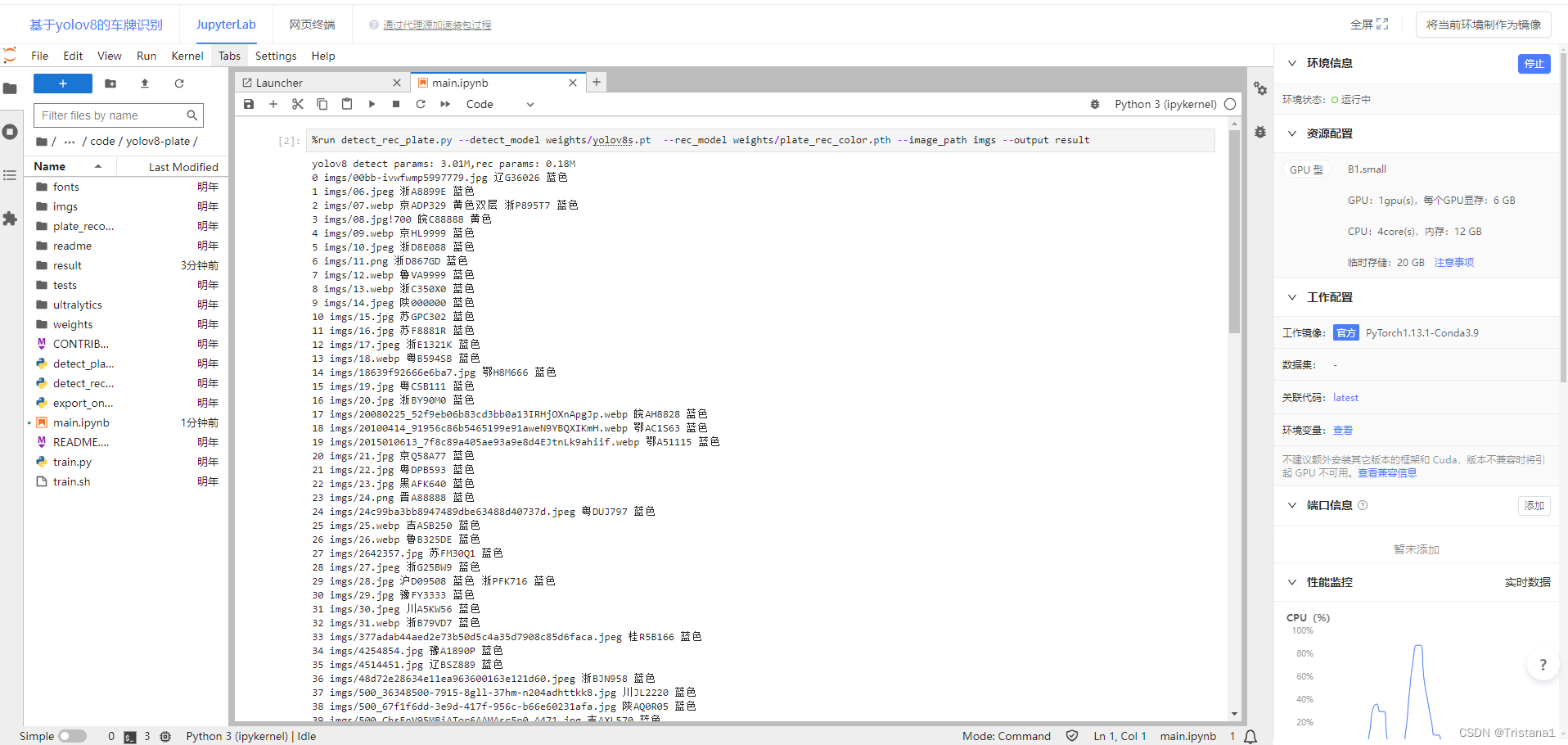
然后进入main的jupyter的界面,我们运行程序。同样的,用鼠标点第一个单元格,然后Ctrl+回车进行运行,等待他进行运行。
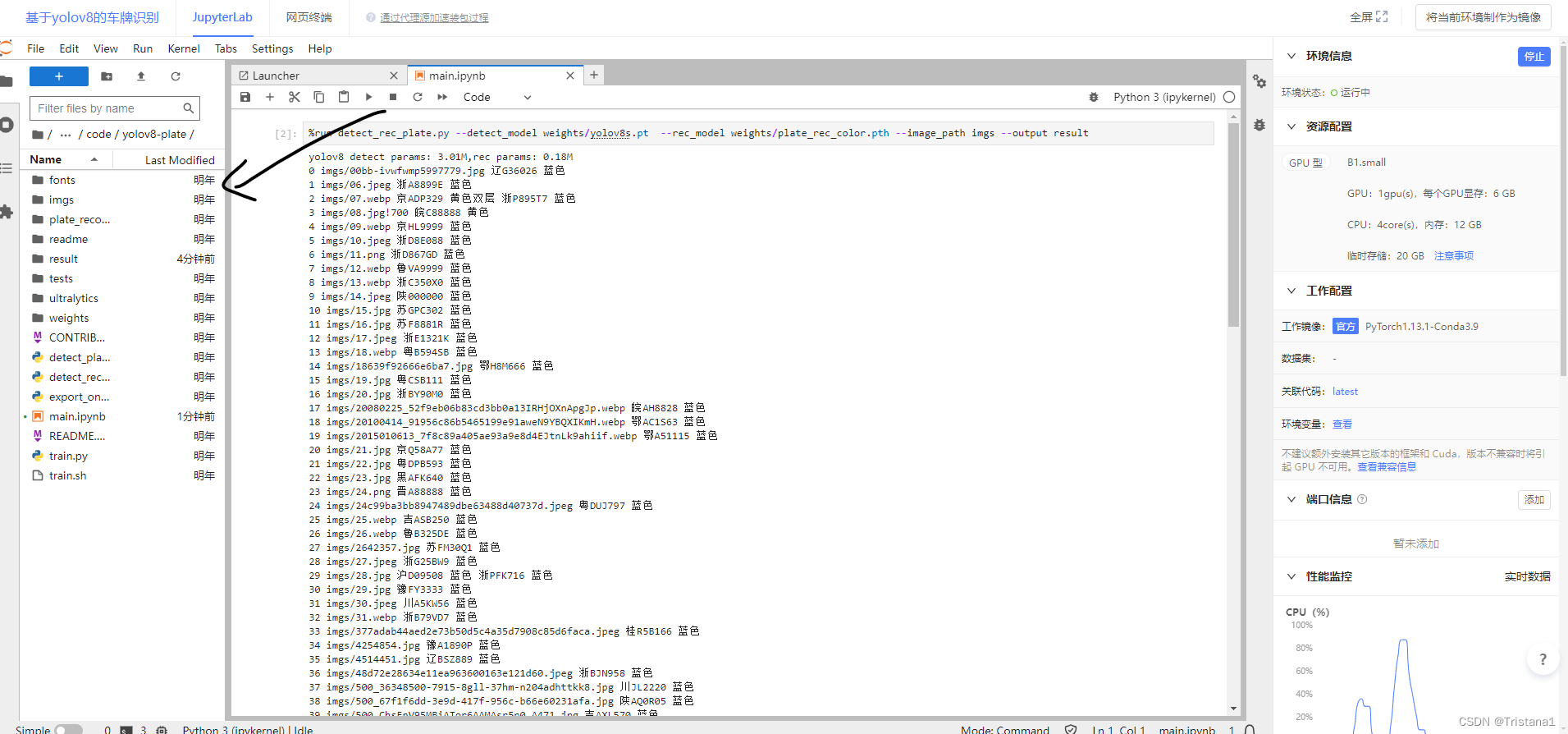
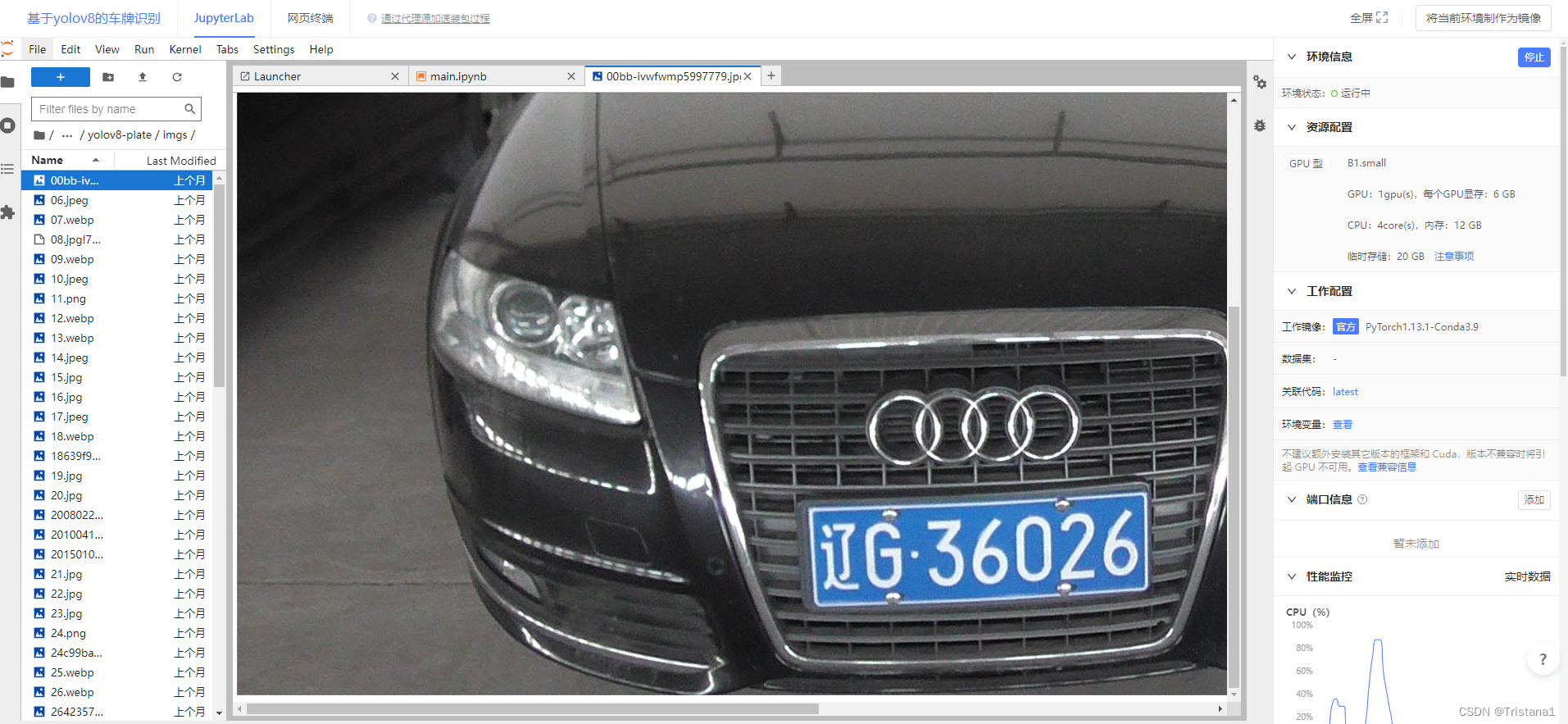
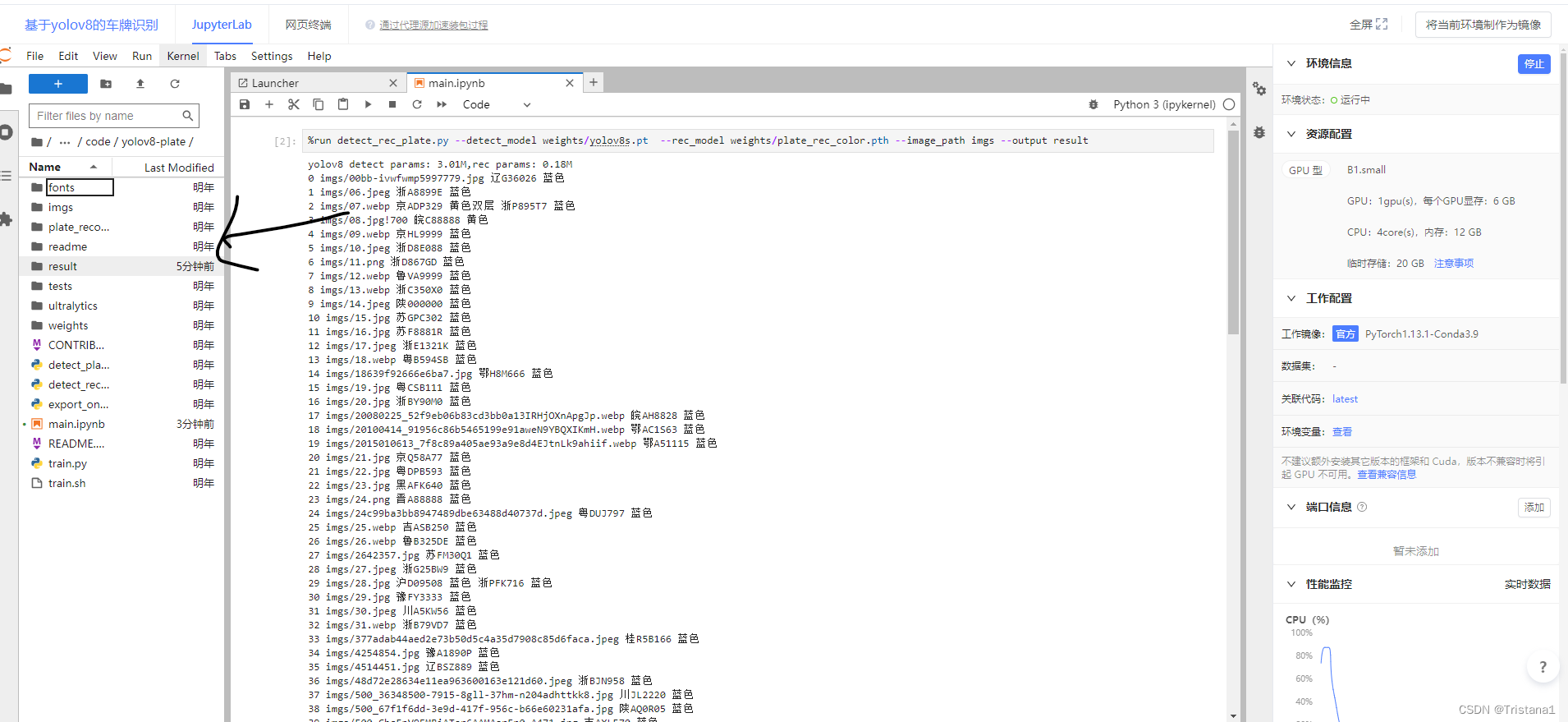
然后我们解释一下,其实原来的待处理的图片是放在了img的里面,如下图所示
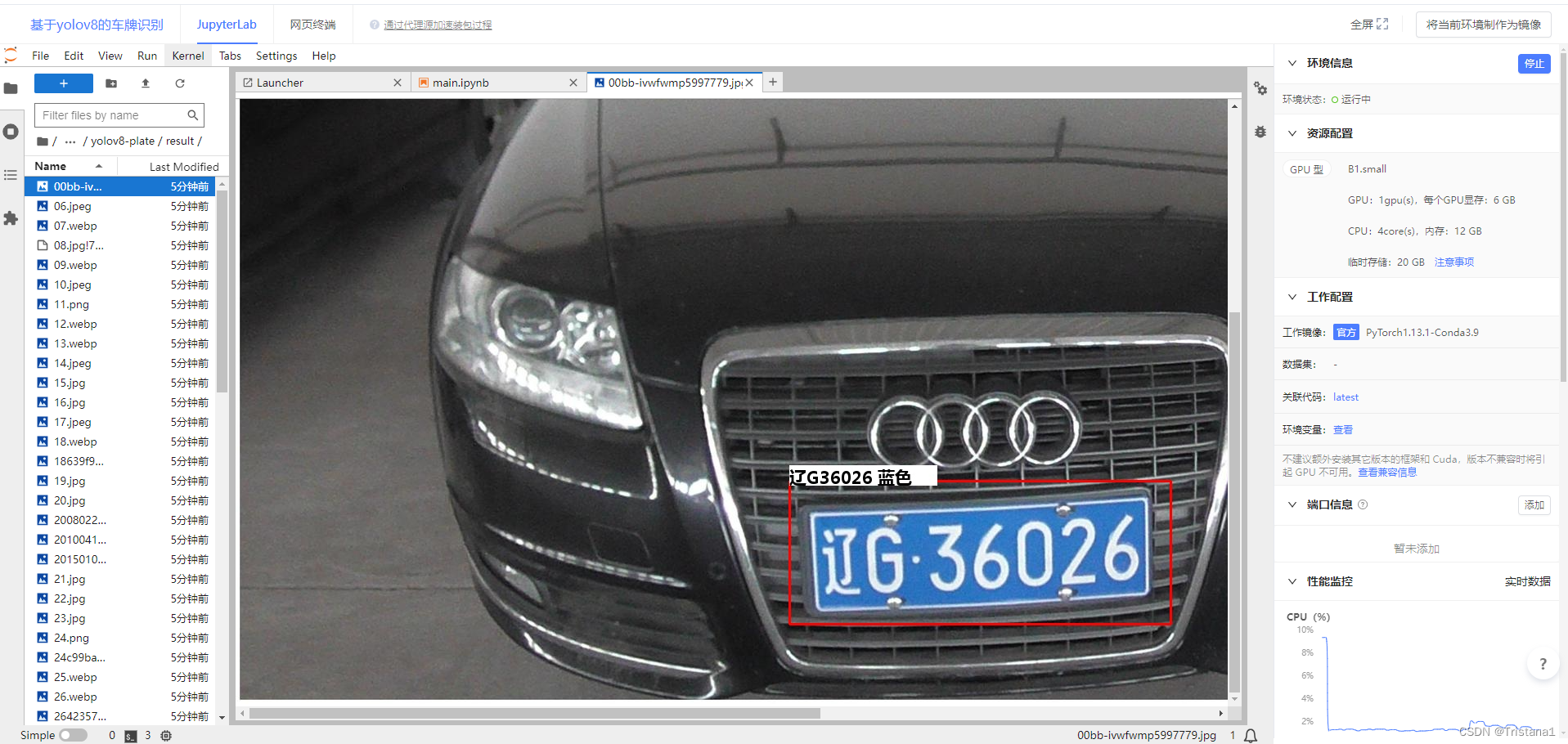
识别之后的结果是放在了result里面,
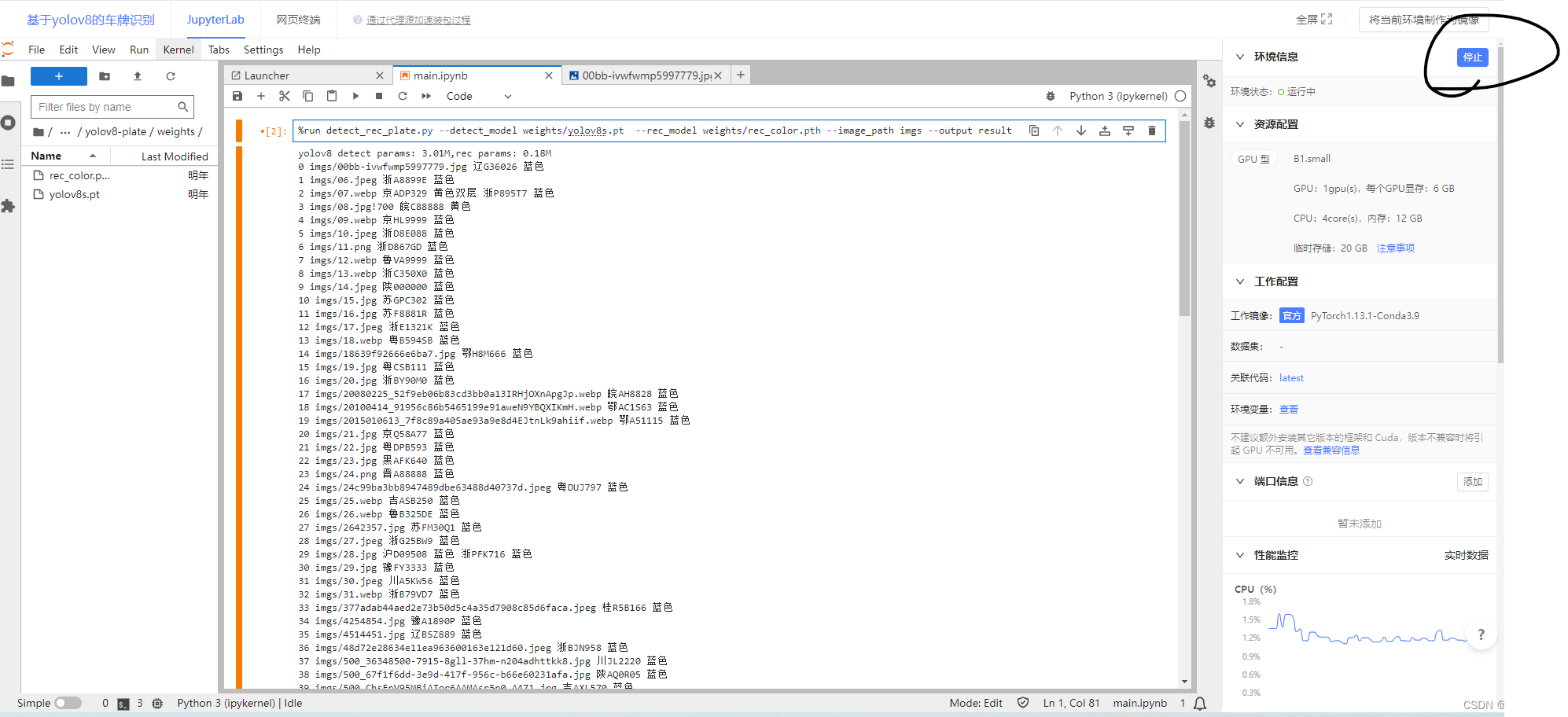
然后别忘了停止,减少计费
大家也可以替换一下img里面的图片,换成自己的图片
然后我们来解释一下命令行代码
%run detect_rec_plate.py --detect_model weights/yolov8s.pt --rec_model weights/rec_color.pth --image_path imgs --output result
detect_rec_plate.py就是我们运行的代码,weights/yolov8s.pt就是放在weights下面的yolov8s,pt的模型,我已经训练好的模型,weights/rec_color.pth是储存在weights下的对车牌颜色的识别的预训练模型,imgs是储存输入图像的文件夹,result是储存输出图像的文件夹。
总结
代码获取链接如下,如果有疑问或者有其他想法的可以私信我,我尽力帮大家解决。
https://mbd.pub/o/bread/mbd-ZZ2Tm5lx















 1871
1871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









