







 本文介绍了常见的反爬虫策略,包括通过Headers、用户行为和动态加载数据。针对这些策略,提出了使用代理IP和降低请求频率的方法,并详细展示了如何爬取哔哩哔哩网站的视频信息,包括设置请求头、随机选择代理IP和设置请求间隔。同时,文章涵盖了数据的抓取、清洗和导出过程。
本文介绍了常见的反爬虫策略,包括通过Headers、用户行为和动态加载数据。针对这些策略,提出了使用代理IP和降低请求频率的方法,并详细展示了如何爬取哔哩哔哩网站的视频信息,包括设置请求头、随机选择代理IP和设置请求间隔。同时,文章涵盖了数据的抓取、清洗和导出过程。
常见的反爬虫策略
1.通过Headers反爬虫
- 通过识别用户请求的Headers来反爬虫是网站最常用的反爬虫策略。很多网站都会对HTTP请求头部的User-Agent进行检测(判断是否为浏览器访问);有一部分网站会对Refer进行检测(一些资源网站的防盗链接);还有一部分会对Cookie进行检测(需要登录才能获取更多数据)。
2.基于用户行为反爬虫
- 通过检测用户行为来判断请求是否来自爬虫程序也是一种常用的反爬虫策略。例如,同一IP地址短时间内多次访问,或者同一账户短时间内多次进行相同操作,都有可能使网站采取反爬虫措施。
3.采用动态加载数据反爬虫
- 有一些网站的网页是通过JavaScript动态生成的,无法直接爬取当前网页获取所需数据,这样对爬虫程序的直接爬取造成了一些困难。
应对反爬虫的措施
1.使用代理IP
- 针对网站检测IP访问的反爬虫策略,可以使用代理IP。代理IP是代理用户取得网络信息的IP地址,它可以帮助爬虫程序掩藏真实身份,突破IP访问的限制,隐藏爬虫程序的真实IP,从而避免被网站的反爬虫程序禁止。
- requests库实现使用代理IP非常方便,只需要构造一个代理IP的字典,然后在发送HTTP请求时,使用proxies参数添加代理IP的字典即可。如果需要使用多个代理IP,可将所有的代理IP字典构成列表,然后从列表中随机选择代理IP。
爬取Python中文开发者社区首页
- 网址为()
import requests
url = 'https://www.pythontab.com/'
proxys = [
{
'http':'http://123.162.7.173:41025'},
{
'http':'http://182.34.207.53:45826'} #最后几位数是端口值(port)
]
for proxy in proxys:
try:
r = requests.get(url,proxies=proxy)
except:
print('ip不可用')
finally:
print('此ip可用',proxy)
print(r.status_code)
- 结果表明,这两个ip都可以用。
2.降低请求频率
- 爬虫程序运行得太频繁,一方面对网站极不友好,另一方面十分容易触发网站的反爬虫。因此,当运行爬虫程序时,可以设置两次请求之间的时间间隔来降低请求频率(通过time库设置程序休眠时间来实现)。
- 如果时间间隔设置为一个固定数字,可能使爬虫程序不太像正常用户的行为,所以可通过设置random库设置随机数来设置随机时间间隔。
爬取Python中文开发者首页
- 设置两次请求之间的随机时间间隔,输出时间间隔。
import time
import random
import requests
url = 'https://www.pythontab.com/'
for i in range(1,10):
t1 = time.time() #获取当前时间
r = requests.get(url) #发送HTTP请求
# 设置随机休眠时间
sleep_time = random.randint(0,2) + random.random()
time.sleep(sleep_time) #程序休眠sleep_time
t2 = time.time() #获取当前时间
print('两次请求时间间隔:',t2-t1) #输出两次请求时间间隔
- 程序的运行结果如图5-3所示。
两次请求时间间隔: 3.34877347946167
两次请求时间间隔: 1.0061814785003662
两次请求时间间隔: 2.963703155517578
两次请求时间间隔: 2.935718536376953
两次请求时间间隔: 0.701591968536377
两次请求时间间隔: 3.2397284507751465
两次请求时间间隔: 1.4753754138946533
两次请求时间间隔: 0.4822564125061035
两次请求时间间隔: 0.6728301048278809
用户实际浏览网页的过程中,会浏览一个网页一定的时间后浏览其他网页,然后过一段时间继续回来浏览。因此,爬虫程序在爬取一定的页数后休眠更长的时间(如设置每爬取5次数据休息10秒)。
爬取Python中文开发者社区Python高级教程网页
- 网址为:https://www.pythontab.com/html/pythonhexinbiancheng/,输出所有页面的URL、响应状态和请求头。
import time
import random
import requests
# 定义base_url字符串
base_url = 'https://www.pythontab.com/html/pythonhexinbiancheng/'
headersvalue = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36'}
# 定义IP
proxy = {
'http':'http://123.162.7.173:41025'}
for i in range(1,28):
if i > 1:
url = base_url + str(i) + '.html' #组合网页URL
else:
url = base_url #第一页URL
print(url) #输出每个页面的URL
try:
# 设置代理IP,发送HTTP请求
r = requests.get(url,headers=headersvalue,proxies=proxy)
except:
print('请求失败') #请求错误,输出“请求失败”
else:
print(r.status_code) #输出状态码
print(r.request.headers) #输出请求头
# 设置随机休眠时间
sleep_time = random.randint(0,2) + random.random()
time.sleep(sleep_time) #程序休眠sleep_time
- 程序运行结果如图5-4所示。
https://www.pythontab.com/html/pythonhexinbiancheng/
200
{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
https://www.pythontab.com/html/pythonhexinbiancheng/2.html
200
{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
https://www.pythontab.com/html/pythonhexinbiancheng/3.html
200
{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
爬取哔哩哔哩网站视频信息
1.实战目的
- (1)练习使用设置请求头、使用代理IP和降低频率等措施应对发爬虫。
- (2)练习使用beautifulsoup库解析爬取的网页内容。
- (3)练习将获取的数据保存至CSV文件。
2.实战内容
- 爬取哔哩哔哩网站的内容,输入搜索关键字解析网页,获取所有视频信息,包括视频标题、视频市场、观看次数、上传时间、up主和视频链接,输出正在爬取的页码提示,并将爬取到的视频信息保存到以搜索关键字命名的CSV文件。
3.实战分析
- 使用Google Chrome 浏览器打开哔哩哔哩网站,搜索关键字(如“努力”),打开网页(https://search.bilibili.com/all?keyword=努力&page=2),可以看到每一页只显示30个视频信息(共34页)。
- 防止爬虫程序在爬取网站过程中被反爬虫程序识别和禁止,可使用下面的措施。设置Headers参数的User-Agent信息,模拟浏览器信息;在爬虫程序中定义代理IP列表,每次发送HTTP请求时随机选取代理IP;每爬取一页内容,程序休眠随机时间。
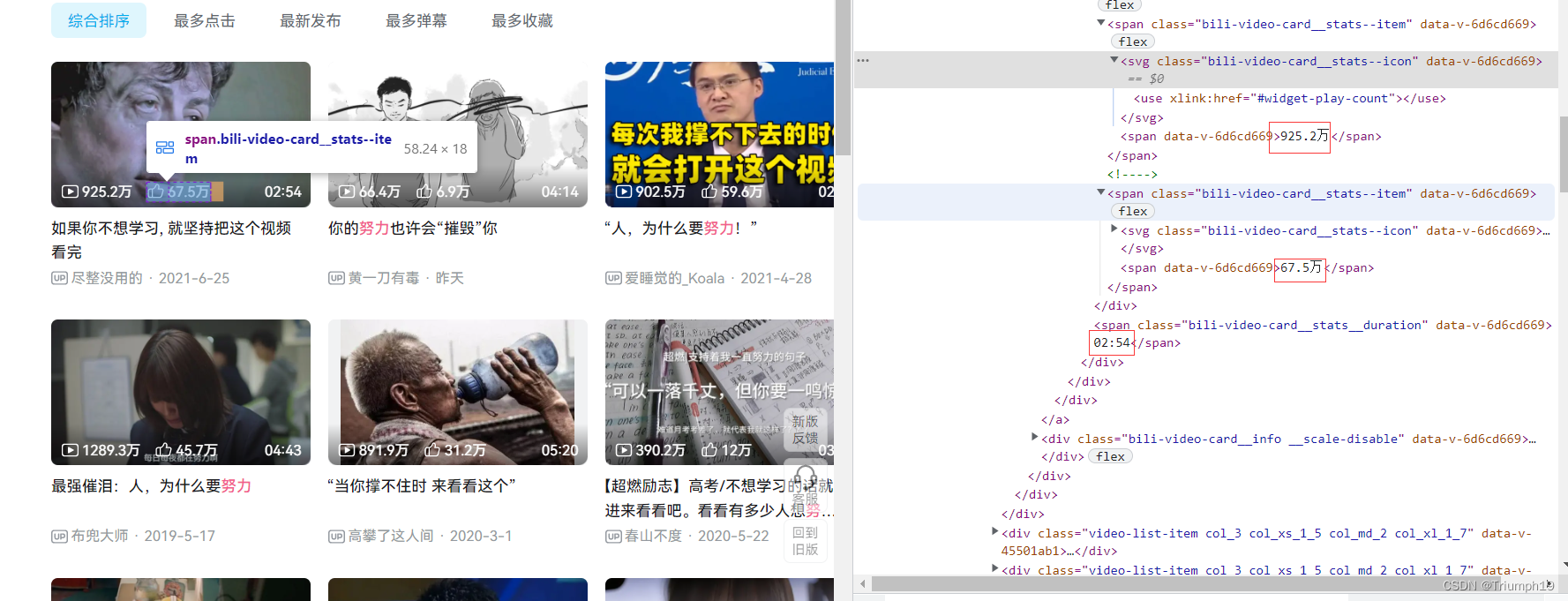
获取页面源代码、直接通过url获取失败
- 课本上是直接打开这个url就能获取标题等信息,笔者通过如下代码长时候发现,通过这个url并不能获取视频相关信息。
import requests
from bs4 import BeautifulSoup
base_url = 'https://search.bilibili.com/all?vt=51793106&keyword=努力'
headersvalue = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









