PDF转text
方法一
- 首先,安装一下操作PDF的库pdfplumber。pdfplumber 可以很好的读取 PDF 文件内容和提取 PDF 中的表格,这个库不属于 Python 标准库,需要单独安装。
import pdfplumber
with pdfplumber.open("经济结构、政府债务与地方政...589只地方政府债券的证据.pdf") as p:
page = p.pages[0]
textdata = page.extract_text()
textdata

with pdfplumber.open("经济结构、政府债务与地方政...589只地方政府债券的证据.pdf") as p:
for i in range(13):
page = p.pages[i]
textdata = page.extract_text()
data = open('text.text',"a")
data.write(textdata)
方法二
pip install pdfdocx
from pdfdocx import read_pdf
p_text = read_pdf("经济结构、政府债务与地方政...589只地方政府债券的证据.pdf")
f = open('文本.txt','w',encoding='utf8')
f.write(p_text)
PDF转word
方法一
- 需要安装一下操作Word的库python-docx。
import pdfplumber
from docx import Document
with pdfplumber.open("经济结构、政府债务与地方政...589只地方政府债券的证据.pdf") as p:
page = p.pages[2]
textdata = page.extract_text()
document = Document()
content = document.add_paragraph(textdata)
document.save("word.docx")
方法二
from pdfdocx import read_pdf
textdata = read_pdf("经济结构、政府债务与地方政...589只地方政府债券的证据.pdf")
document = Document()
content = document.add_paragraph(textdata)
document.save('word.docx')
PDF转Excel
- 这里所说的PDF转Excel不是全文转Excel,而是对论文中的部分表格进行格式转换,方便在Excel中对数据进行筛选、计算等操作。
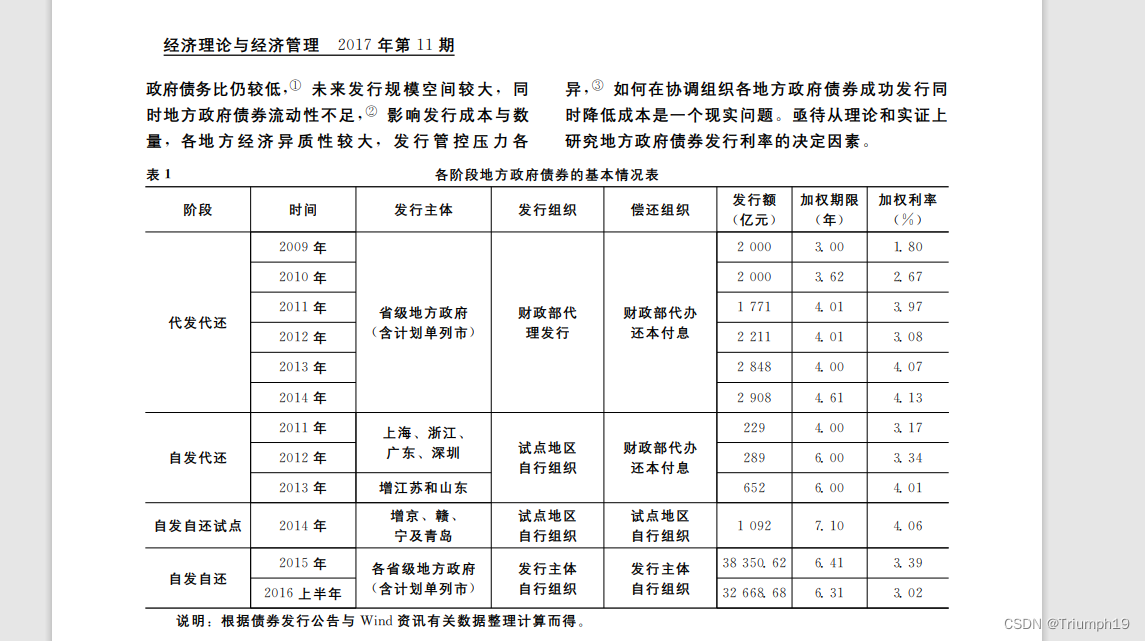
- 本案例PDF论文中第2页为截取部分内容,长这样:
- 首先,安装并导入操作Excel表格的库openpyxl。
import pdfplumber
from openpyxl import Workbook
with pdfplumber.open("经济结构、政府债务与地方政...589只地方政府债券的证据.pdf") as p:
workbook = Workbook()
sheet = workbook.active
page = p.pages[1]
table = page.extract_table()
for row in table:
sheet.append(row)
workbook.save("Excel.xlsx")
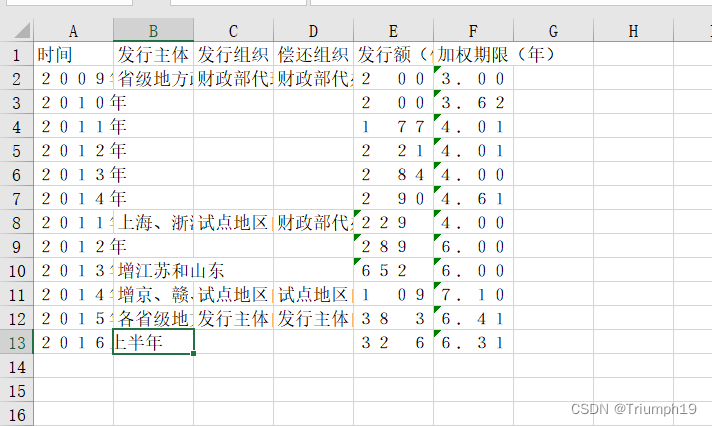
- 结果不尽如人意:























 1248
1248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









