







常见的构造
HTTP 请求的方式有以下几种:
- 直接通过浏览器地址栏, 输入一个
URL就可以构造出一个GET请求. - 直接点击收藏夹, 得到的也是
GET请求. HTML中的一些特殊标签也会触发GET请求, 如:link, script, img, a…- 还可以通过
form表单标签来实现GET/POST请求的构造. - 通过
JS中的ajax实现各种请求的构造.
最常使用的是通过使用 HTML/JS 来进行请求的构造, 再简单一点还可以使用一些工具, 比如使用 postman 来进行请求的构造.
1. form表单请求构造
使用 form 表单标签构造请求, action 属性中的 URL 指的是接收请求的服务器地址.
基本格式:
<form action="URL" method="http方法类型"></form>
比如我们可以搭配 input 标签来构造HTTP请求:
<form action="URL" method="get">
<input type="text" name="user">
<input type="password" name="password">
<input type="submit" value="提交">
</form>
这里构造的 http 请求, input标签中的 name 属性表示请求键值对中的 key, 用户在输入框输入的内容表示键值对中的value.
要注意使用 form 表单标签构造的请求页面是一定会发生页面的跳转的.
通过 from 表单标签构造的请求方法只支持 get 和 post 两种方法, 无法构造 put, delete, options 等方法的请求, 如果构造的是 get 请求, 那么请求内容在查询字符串 (query string) 中, 如果构造的是 post 请求, 那么请求内容就会在 body 中.
比如使用 get 请求, 我们来给百度搜索官网提交请求, 提交请求后会自动跳转到一个带有查询字符串的页面, 查询字符串的内容就是我们所提交的请求键值对.

可以看到页面跳转并带有了我们传入的 query string, 但是这里的请求, 是没有对应的响应的, 这是正常的, 因为百度并没有针对我们我们的请求设置相应的响应.
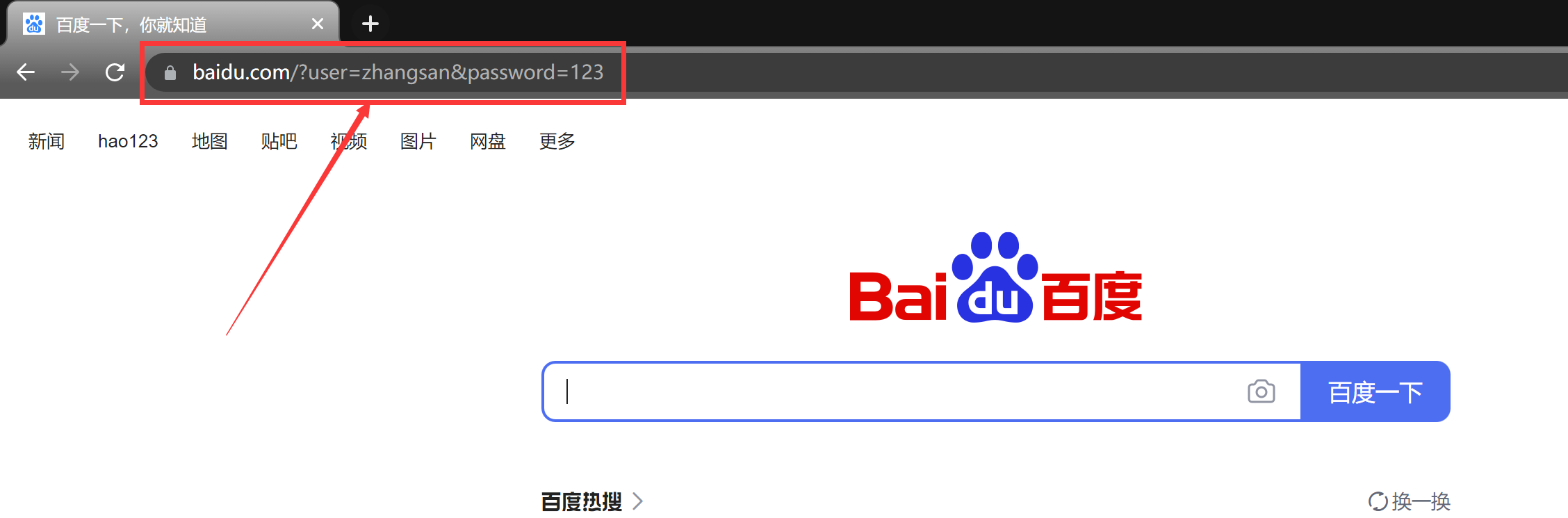
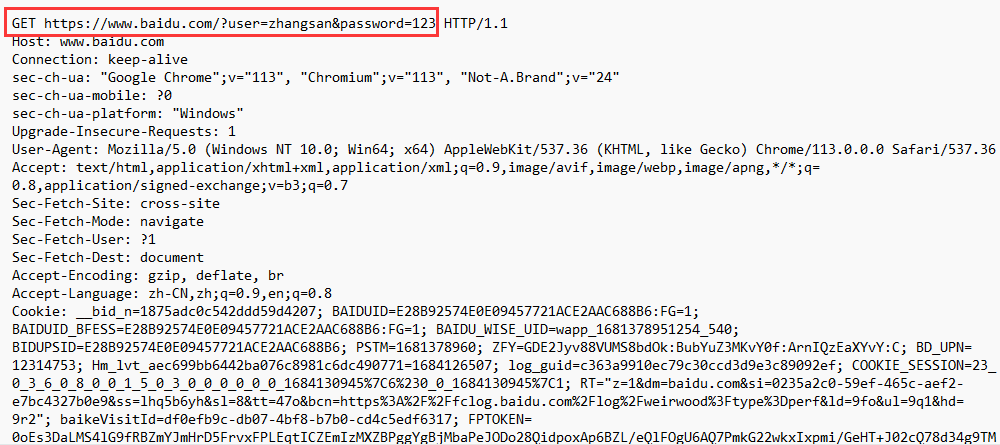
我们在再来使用 fiddler 抓个包看一下;
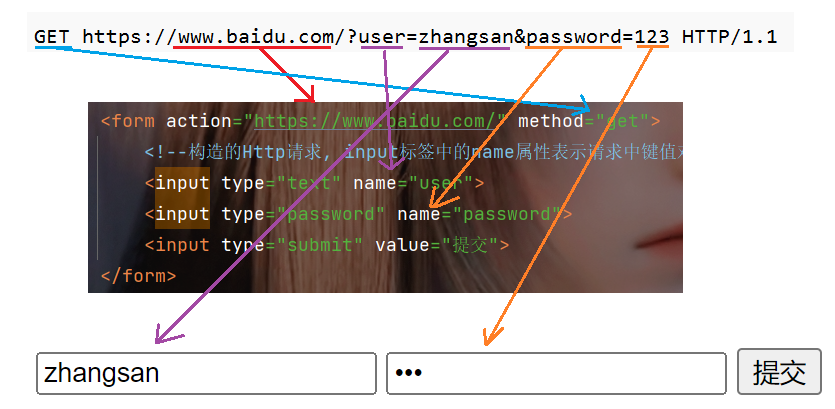
这里的请求和我们代码的对应关系就如下图, 除了首行外, 其他部分都是浏览器自主添加的.
 再来看一下 post 请求.
再来看一下 post 请求.
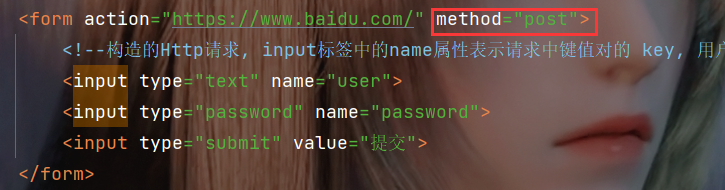
再抓个包看看请求内容是在哪里, 可以看到此时请求内容就出现在了 body 中了, 对于 form 构造的 post 请求来说, body里的数据格式和 query string 是非常相似的, 也是键值对结构, 键值对之间使用 & 来分割, 键和值之间使用 = 来分割.
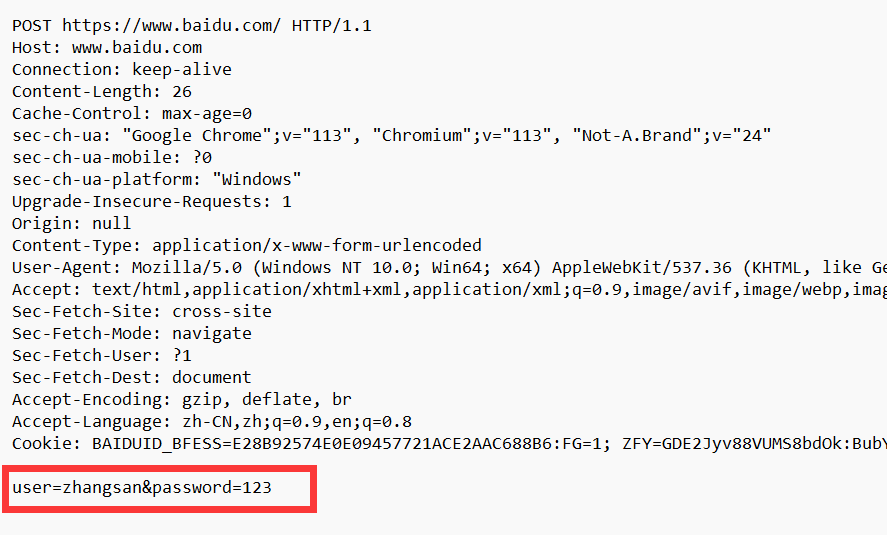
2. ajax请求构造
使用 ajax 构造 HTTP 请求, 其实是在使用 js 代码来构造 HTTP 请求, 然后可以使用 js 代码来处理请求和响应.
ajax = Asynchronous JavaScript and XML (异步的 JavaScript 和 XML), ajax 是基于异步等待来实现的, 是前端和后端异步交互的一种方式, 除了异步等待这个概念之外, 还有同步等待的概念, asynchronous 表示异步,synchronized 表示同步, 这里补充一下异步等待与同步等待的区别, 为了便于理解, 这里的区分我们使用一些生活中的例子来解释,
同步等待包含同步阻塞等待和同步非阻塞等待,
假设你去饭馆吃饭, 你跟老板说来份蛋炒饭, 老板收到你的请求后, 就去厨房做饭去了, 你此时就坐在座位上, 等老板把蛋炒饭做好, 如果你坐在座位上什么也不干, 就干等着, 然后等到老板做好了, 你再把饭端走, 这个过程相当于就是同步阻塞等待.
但是如果你是点了餐后, 你去做其他事情了, 比如刷抖音, 聊天, 打游戏什么的, 然后隔一会儿就去看一下饭有没有好, 看了几次后, 你发现饭好了, 就自己端上来吃, 这个就相当于同步非阻塞等待.
但如果点餐后, 你去做别的事, 等着老板把饭给你端过来, 然后你直接吃, 这个就相当于异步等待.
异步等待与同步等待最大的区别就是请求的发起者是否主动关注响应结果, 同步等待就是请求的发起者自己主动关注获取响应, 而异步等待就是请求的发起者并不去关注响应结果, 是由被被请求的这一方构造好响应之后, 把响应推送给发起者.
js 中提供了原生的 ajax 的 api, 但使用起来比较麻烦, 所以我们这里使用 jQuery (对原生 api 进行了封装, 相对简单)中的 ajax 来进行构造, 所以我们需要先需要引入 jQuery, 然后使用 $/jQuery 对象(全局对象, jquery 的 api 都可以使用 $ 得到)调用 ajax 函数, 这个函数只有一个参数, 是一个 js 对象, 这个对象里面需要包含一些属性, 常见的属性有 type 表示请求方法, url 表示访问路径, success 是得到 http 响应之后需要做的事情, 是一个函数, error 表示请求失败后要做的事情, 也是一个函数.
第一步, 引入 jQuery, 搜索 jQuery cdn, 找到一个 jQuery cdn 文件的 URL, 我们选择 min 版本的, 比如我这里得到的是 https://cdn.bootcdn.net/ajax/libs/jquery/3.6.4/jquery.min.js.
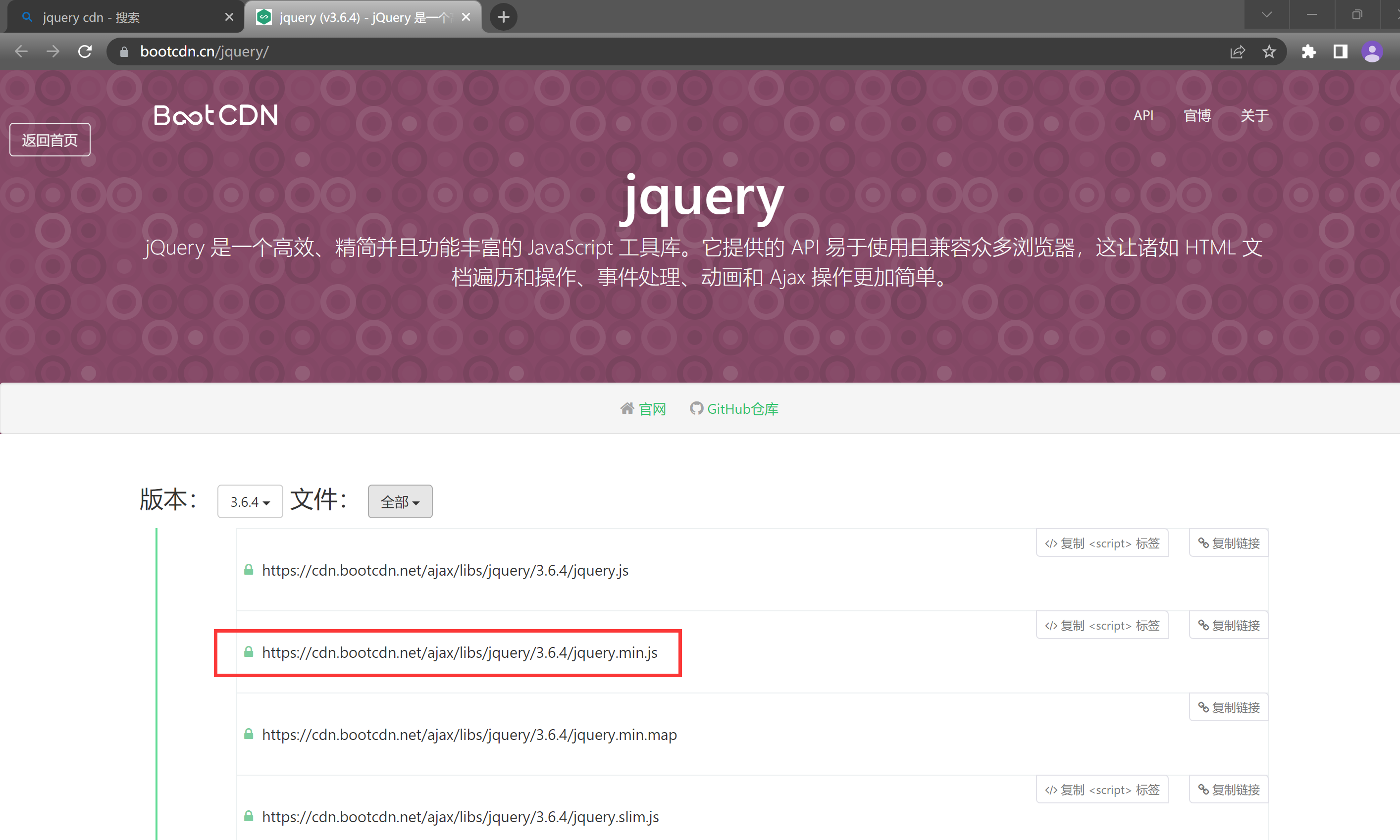
我们可以访问这个 URL, 将页面的所有的内容拷贝到一个js文件中.
最后将这个 js 文件导入到需要使用 ajax 的 HTML 代码中即可, 或者可以直接在 HTML 代码中使用jQuery 的网络路径也可以, 但这样可能就不稳定, 毕竟 jQuery cdn 路径随时都有可能失效.
第二步, 使用 $ 对象中的 ajax 函数, 传入一个 js 对象作为参数, 这个对象里面需要包含 HTTP 方法类型 type, 请求的 url, 请求成功后该做什么 success, 失败后该做什么 error 当然完整的参数属性不止这一些, 这里仅列举了一些必要的属性, 更多属性可以参考这里 https://www.w3school.com.cn/jquery/ajax_ajax.asp.
<!-- // 引入jQuery -->
<script src="jquery路径"></script>
<script>
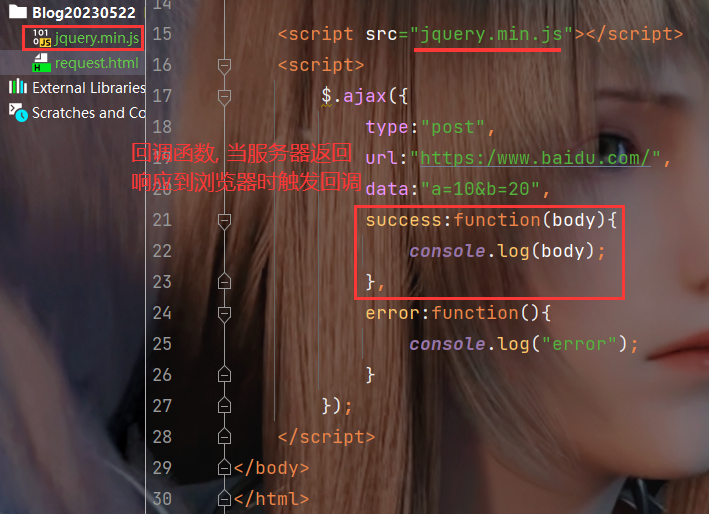
$.ajax({
// 方法类型
type:"HTTP方法类型",
url:"请求页面路径",
//此处 success就声明了一个回调函数,就会在服务器响应返回到浏览器的时候触发该回调
//正是此处的回调体现了 "异步"
success: function(){
// 请求处理这个后,该做什么
},
error:function(){
// 请求失败后,该做什么
}
})
</script>
就是说当 $.ajax(…) 这一行代码执行 “发送请求” 操作之后, 不必等待服务器响应回来, 就可以立即先往下执行后序的代码, 当服务器的响应回来了之后, 再由浏览器通知到代码中的 success 来处理拿到的响应.
我们这里使用 ajax 给百度发送请求, 此时是无法有相应的响应返回的, 但是这里可以抓包, 来看看发送的请求内容.
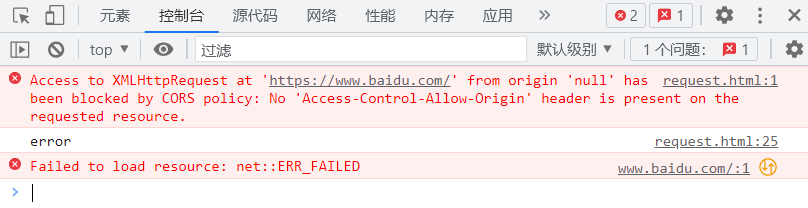
这里的报错是属于 ajax 的一个非常典型的跨域问题, 这是浏览器为了限制安全问题引入的保护机制, 要求现在运行ajax 代码的页面的域名和 ajax 里的请求访问的域名要保持一致, 如果这两个域名不一致的话, 哪怕服务器返回了响应了数据, 浏览器也是不能处理的, 即有了上面的报错, 但使用 from 表单标签构造是可以跨域访问的, 即 a 网站的页面可以请求 b 网站的数据.
抓包结果:
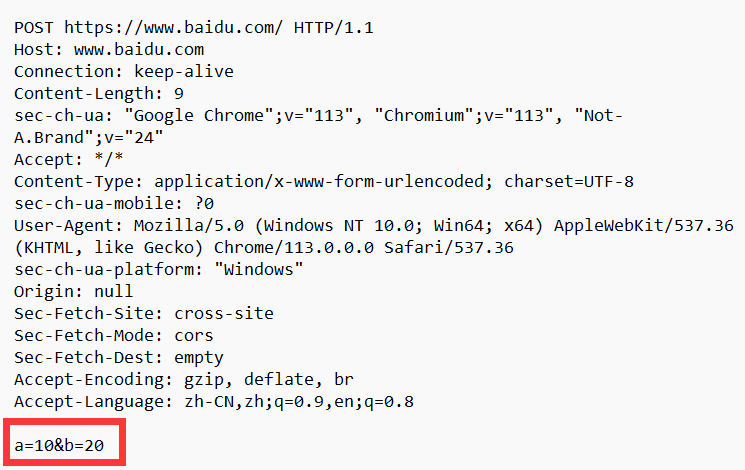
ajax 相比于 form 标签功能更强, 构造请求更加灵活, form 只支持 get 和 post 请求的构造, 而 ajax 还支持 put, delete等, ajax 还可以灵活的设置 header 和body.
3. Postman的简单使用
Postman是谷歌的一款接口测试插件, 它使用简单, 支持用例管理, 支持get, post, 文件上传, 响应验证, 变量管理, 环境参数管理等功能, 可以批量运行, 并支持用例导出, 导入.
可以去 postman 官网去下载 https://www.postman.com/
下载好后可去’使用邮箱去注册一个账号进行登录, 下面是登录成功的初始界面
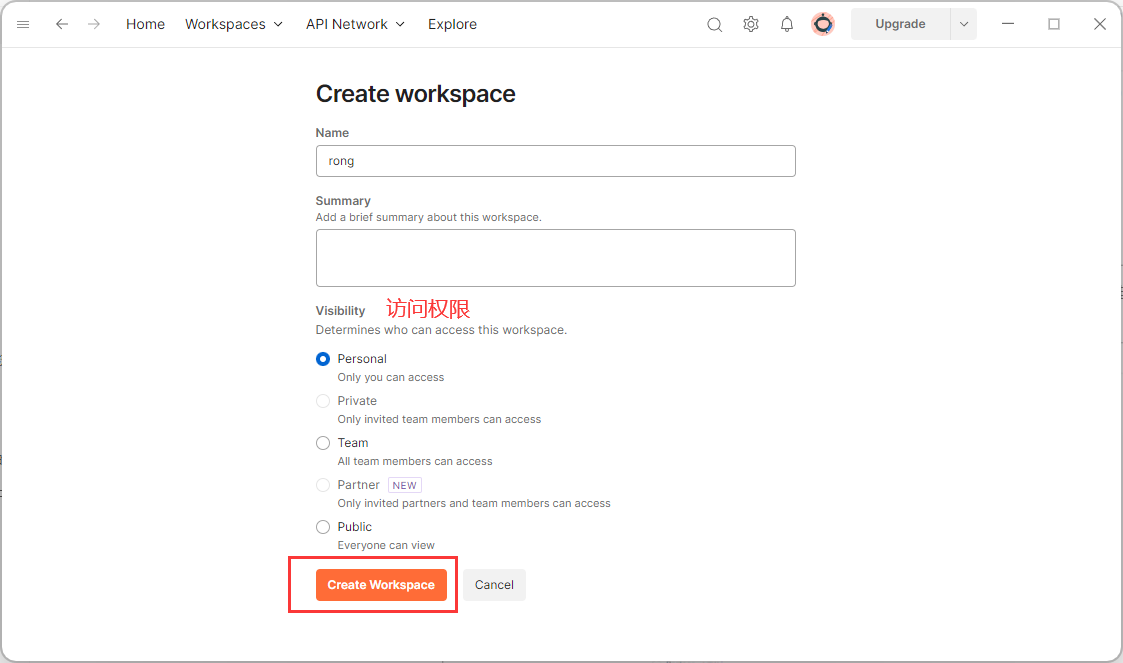
我们首先需要创建一个工作空间, 用于测试以及将我们的测试数据保存到云端, 这样可以保证数据不会丢失.
工作空间创建好后, 点击 + 新建一个标签页, 就可以进行请求的构造和测试了.

熟悉一下界面, 这里以 get 请求的构造为例.

我们每次请求后, 可以按 Save 或者 Ctrl + S 将我们的测试记录保存到云端, 以便下次的查看和使用.
当然也可以构造其他请求.
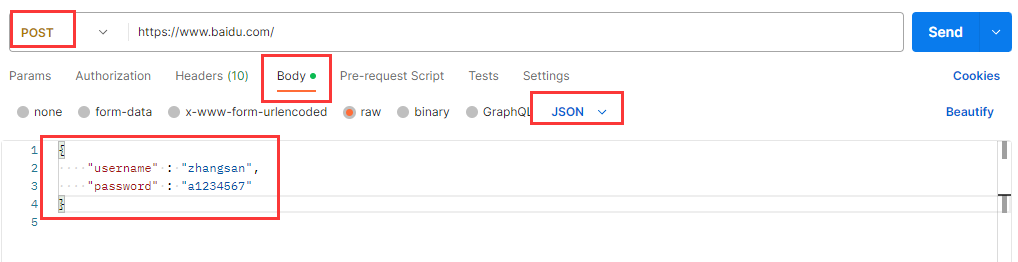
Postman还有一个非常好用的功能, 就是可以直接把请求转化成代码, 方便我们在自己的程序中集成, 提高效率.
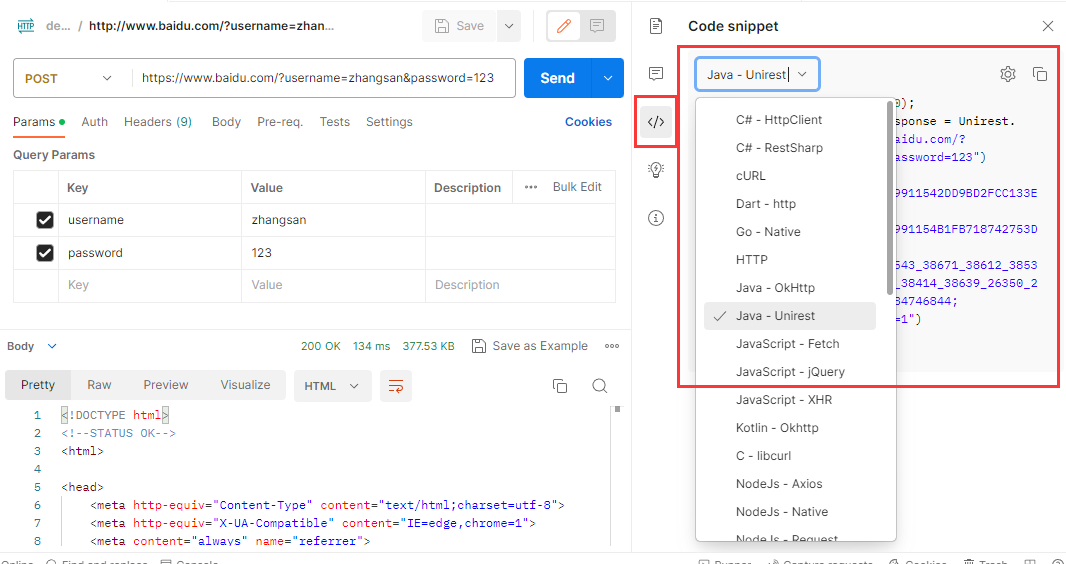
在工具内构造好请求后想要转化成代码很简单, 只需要点击一下旁边的代码 (code) 按钮, 在下拉列表中选择自己需要转化的编程语言和对应的代码包, 然后就可以把代码直接复制到我们的项目中.
















 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











