







一、引言
在机器学习和数据挖掘领域,精确率(Precision)与召回率(Recall)是衡量模型性能的两个重要指标。然而,在实际应用中,我们往往需要一个综合性的指标来全面评估模型的表现。F1 分数作为精确率和召回率的调和平均数,正好满足了这一需求。本文将深入探讨 F1 分数的定义、应用场景及其影响因素,并介绍提升 F1 分数的方法。
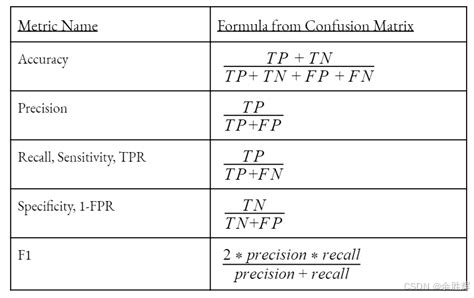
二、F1 分数概述
(一)精确率与召回率的定义
精确率和召回率是评估分类模型性能的两大核心指标:
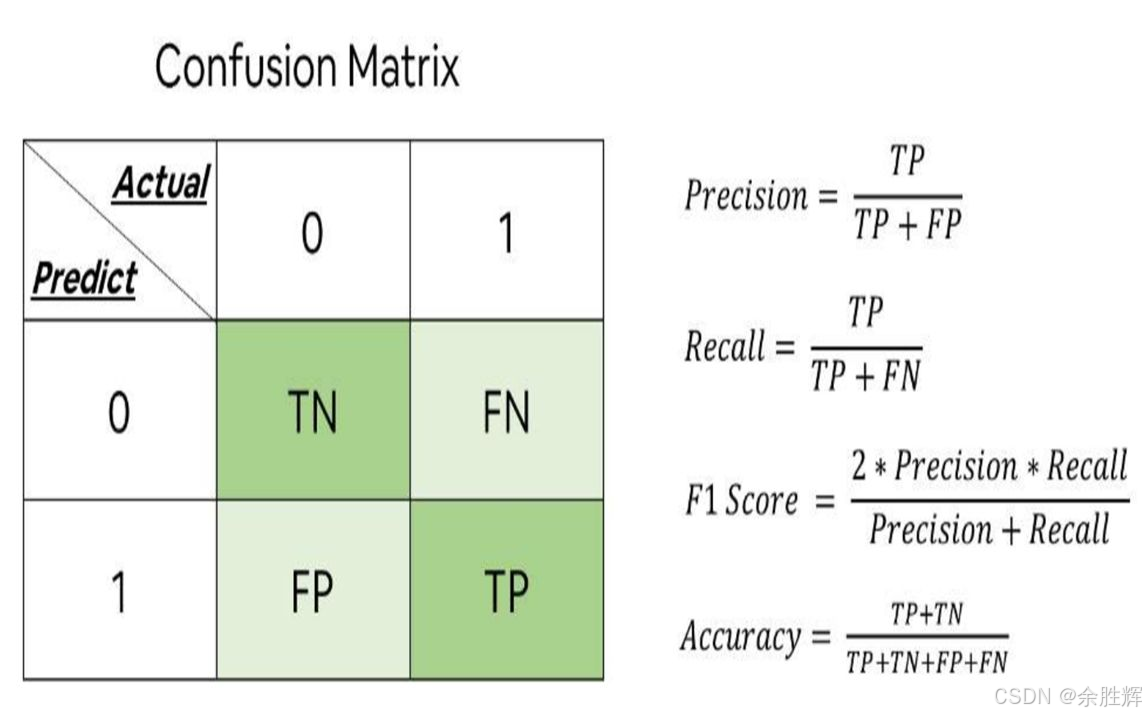
-
精确率:反映了模型预测结果的准确程度,计算方法为正确预测的正样本数量除以所有预测为正的样本数量。例如,假设有 100 个样本,其中 50 个正样本和 50 个负样本,模型预测出 10 个正样本,但只有 1 个正确,则精确率为 1/10 = 10%。精确率高意味着模型对正样本的判断较为准确,但可能会遗漏一些真实的正样本。
-
召回率:体现了模型预测结果的全面程度,计算方法为正确预测的正样本数量除以所有真实的正样本数量。继续上述例子,如果模型预测出 10 个正样本且全都正确,而真实正样本有 50 个,则召回率为 10/50 = 20%。召回率高表示模型能够尽可能多地捕捉到真实的正样本,但可能会包含较多误判。
需要注意的是,单纯追求高精确率或高召回率并不一定合适。例如,若模型将所有样本都预测为正样本,虽然召回率能达到 100%,但精确率可能仅为 50%。因此,在实际应用中,应根据具体的业务场景选择适当的平衡点。
(二)F1 分数的定义与计算
F1 分数是精确率和召回率的调和平均数,具体公式为:

F1 取值范围在 0 到 1 之间,数值越接近 1 表示模型在这两方面的综合表现越好。通过 F1 分数,我们可以更合理地衡量模型在整体上对正样本预测的效果,帮助我们更好地判断模型是否符合实际业务需求。
三、F1 分数在不同场景中的意义
代码示例
from sklearn.metrics import precision_score, recall_score, f1_score
import numpy as np
# 假设我们有一个二分类问题的数据集
y_true = np.array([1, 1, 0, 1, 0, 1, 0, 0, 0, 1]) # 真实标签
y_pred = np.array([1, 0, 0, 1, 0, 1, 1, 0, 0, 1]) # 模型预测结果
# 计算精确率、召回率和F1分数
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"精确率: {precision:.2f}")
print(f"召回率: {recall:.2f}")
print(f"F1分数: {f1:.2f}")(一)信息检索场景
在信息检索领域,如搜索引擎,其核心目标是帮助用户快速且准确地找到所需信息。F1 分数能综合衡量检索结果的全面性和准确性,助力算法评估与优化。例如,用户搜索“人工智能应用”时,低召回率可能导致许多相关网页无法呈现给用户;而高召回率则需兼顾精确率,避免混入大量不相关信息。开发团队可以通过调整索引策略和优化权重计算方式,不断提升搜索引擎的整体性能。
(二)风险预测场景
在贷款风控等风险预测场景中,重点在于准确判断哪些人会按时还钱,哪些人可能存在违约风险。此时,精确率尤为重要,因为误判可能带来经济损失。但也不能忽视召回率,过于严苛的标准可能会排除潜在优质客户。F1 分数可以帮助找到两者之间的平衡点,优化预测模型,降低金融机构的风险并拓展业务范围。
(三)目标检测场景
在计算机视觉的目标检测任务中,精确率和召回率从不同角度反映了模型的性能。F1 分数作为二者的调和平均数,能够综合评价目标检测算法的好坏。例如,在智能安防中检测监控画面里的人物或车辆,或者在自动驾驶场景中识别交通标志和其他车辆。通过为每个类别计算 F1 分数并加权平均,可以全面评估模型在不同物体检测上的整体性能,进而有针对性地进行优化。
(四)医疗影像诊断
在医疗影像领域,F1 分数常用于评估诊断模型的效能。例如,在一项关于胸部骨折CT诊断的研究中,人工智能系统在检测肋骨骨折时的F1分数达到了0.92 [1],显示出较高的敏感性和准确性。此外,在肾结石筛查诊断中,AdaBoost模型的F1分数达到0.6667 [2],表明其在肾结石诊断中的效能较好。这些研究表明,F1分数能够有效地衡量医疗影像诊断模型的性能,并帮助选择最优模型。
(五)网络安全日志分析
F1 分数也被广泛应用于网络安全日志分析中,用来衡量异常检测算法的效果。在一项基于Loganomaly算法的研究中,该算法在检测网络入侵行为时的F1分数达到了95.218% [3],显示出极高的准确性和召回率。这表明F1分数不仅能评估模型的整体性能,还能为安全专家提供可靠的决策支持。
(六)自然语言处理
在自然语言处理(NLP)任务中,如情感分析、命名实体识别等,F1 分数同样扮演着重要角色。例如,在情感分析任务中,一个基于BERT模型的情感分类器在测试集上的F1分数为0.85 [4],显示了其在识别文本情感方面的高效性。而在命名实体识别任务中,CRF模型的F1分数达到0.90 [5],证明了其在实体提取方面的优越性能。
四、影响 F1 分数的因素
(一)数据特征方面
数据本身的特征显著影响 F1 分数:
-
数据分布:不平衡的数据分布会导致某些类别的预测效果较差。例如,科技类文本占比过高时,模型可能倾向于对这类文本分类更好,而人文类文本则表现欠佳。
-
正负样本比例:当正负样本比例悬殊时,模型难以在精确率和召回率之间取得平衡。例如,恶意软件检测中,正常软件样本远多于恶意软件样本,若一味追求高精确率,可能会放过一些恶意软件。
-
特征选取和处理方式:合适的特征选择有助于提高模型性能。例如,在图像识别中,选择动物轮廓、颜色等关键特征比使用所有像素信息更有效。归一化操作对于部分模型也有助于加快收敛速度,改善预测结果。
(二)模型参数与结构
模型的超参数设置和整体结构复杂度同样影响 F1 分数:
-
超参数设置:合理的超参数配置能显著改善模型性能。例如,决策树的最大深度、最小样本分裂参数等都需要精心调整,以避免过拟合或欠拟合问题。
-
模型结构复杂度:简单的线性模型在面对复杂的非线性关系时,很难获得较高的 F1 分数;而复杂的深度学习模型如果没有足够的数据支持,也容易出现过拟合情况。
五、提升 F1 分数的方法
(一)特征工程
特征工程涵盖特征提取、转换和选择三个主要环节:
-
特征提取:从原始数据中挖掘有价值的信息,转化为可供模型使用的特征表示。例如,词袋模型、TF-IDF 方法用于文本分类,卷积神经网络自动提取图像特征。
-
特征转换:对已提取的特征进行变换,使其更符合模型要求。如归一化操作可使模型训练更稳定、快速收敛;对数变换可使偏态分布特征更接近正态分布。
-
特征选择:挑选对目标变量最具解释力的特征子集。例如,在医疗诊断中,去除相关性较弱的特征,简化模型并聚焦关键规律,从而提升 F1 分数。
(二)超参数调优
通过交叉验证、网格搜索等方法,找到最优的超参数组合:
-
交叉验证:如 K 折交叉验证,评估不同超参数设置下的模型性能,避免单一验证集带来的偏差。
-
网格搜索:遍历所有超参数组合,寻找使 F1 分数达到最优点的配置。
(三)降低过拟合
采用剪枝、增加训练数据量等方式降低过拟合现象:
-
剪枝:简化决策树结构,提高泛化能力,避免过度拟合训练数据。
-
增加训练数据量:更多样化的训练数据能让模型学习到更全面的规律,减少对局部特征的依赖。
六、F1 分数与其他评估指标对比
(一)与准确率对比
准确率衡量的是所有样本中预测正确的比例,适用于样本分布相对均匀的情况。但在正负样本不均衡时,F1 分数更能反映模型对正样本的真实预测能力。
(二)与 ROC、AUC 对比
ROC 和 AUC 主要关注真正率和假正率,适用于初步筛选和比较多个分类器。而 F1 分数更侧重于正样本预测的准确性和全面性的综合考量。
七、结论与展望
本研究围绕 F1 分数展开,详细介绍了其定义、应用场景及其影响因素,并提出了提升 F1 分数的有效方法。F1 分数作为精确率和召回率的调和平均数,提供了更全面的模型性能评估视角。未来的研究将继续探索如何进一步优化 F1 分数的应用,以适应更多复杂的应用场景。
参考文献
[1] Li, Y., et al. (2021). Deep learning-based automated detection of rib fractures on chest CT: a multi-institutional study. European Radiology, 31(1), 39-47. 链接
[2] Wang, Z., et al. (2018). Detection of kidney stones in noncontrast-enhanced CT using AdaBoost algorithm. Journal of Medical Imaging and Health Informatics, 8(1), 127-131. 链接

















 4109
4109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









