






 AutoFuzz是一款开源框架,用于自动化理解网络协议并进行模糊测试。它通过构建有限状态自动机(FSA)来理解协议,并利用生物信息学算法构建通用报文序列(GMSs),以区分静态与动态数据字段。此外,AutoFuzz还包含了一个SOCKSv5代理服务器,用于记录和编辑流量。
AutoFuzz是一款开源框架,用于自动化理解网络协议并进行模糊测试。它通过构建有限状态自动机(FSA)来理解协议,并利用生物信息学算法构建通用报文序列(GMSs),以区分静态与动态数据字段。此外,AutoFuzz还包含了一个SOCKSv5代理服务器,用于记录和编辑流量。
1.Basic Description
AutoFuzz是一个开源的框架,提供了一些核心方法,用来自动化理解网络协议,并且对协议实现进行模糊测试。主要分成两个部分:提取协议规范和模糊测试。通过构建Finite State Automaton(FSA)并且利用网络流量提取报文语法结构,以此理解网络协议。FSA用来指导模糊测试过程,,fuzzer会将 报文语法结构信息存储在GMSs(通用报文序列)中,所谓的GMSs也是利用生物信息学算法比如全局或者局部序列比对算法构建的。GMSs会将static data field与dynamic data field区分开来,每一个动态数据域都会有一个关联的类型信息。
个人感觉还是英文讲得比较清楚,但是看着英文又觉得比较麻烦,为了好理解,附上英文如下:(The FSA is used to guide the fuzzer through the communication process between two nodes and to keep an overall “picture” of the fuzzing progress. The fuzzer stores individual message syntax information in Generic Message Sequences (GMSs). GMSs are constructed using algorithms of bioinformatics such as global and local alignment.)
2.Basic information
- AutoFuzz通过对通信节点之间的流量进行改变来实现模糊测试。为了达到这一目的,AutoFuzz有一个内置的SOCKS v5代理服务器,是基于Java Socks Server的,但是已经被修改了可以用来记录和编辑traffic。目前还不支持加密协议。
- AutoFuzz可以指定想要使用的fuzz方法,也可以自己添加自定义的模糊方法。
- 为了让AutoFuzz能够对所有的状态转换进行模糊,并且能够基本实现所有的模糊方法,必须要能够从获取足够的流量。
- 一旦Fuzzing成功,可以回溯fuzzer的转换序列,或者从fuzzing日志中寻找fuzzed报文。
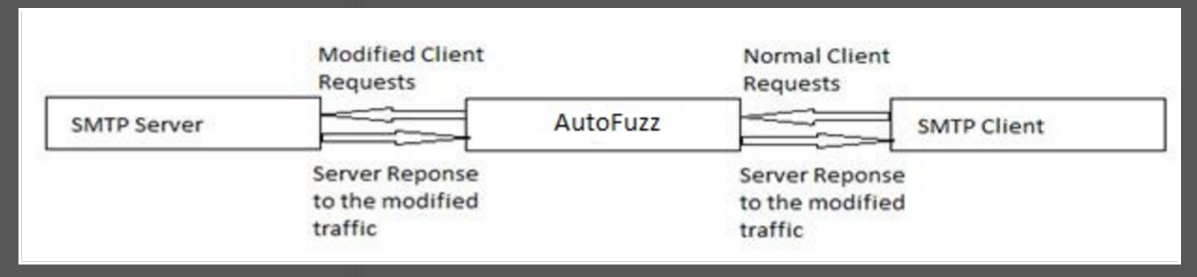
个人感觉和SecFuzz有点像,通过代理,监控客户端和服务端之间的流量,对流量进行更改进行模糊测试,但是不同点在于这里用到了协议逆向技术,通过对流量的分析获取协议格式以及FSA,用这个来指导Fuzzer如何进行模糊。
3.Usage
其实大概流程中具体用的方法还是不太清楚,因为刚看,后面应该会写到,这里只是说一下整体的流程。
至于技术细节,留着后面再写吧,刚开始看。PS:觉得写博客是个好习惯,如果自己看的东西自己能够很清楚的写下来,说明自己起码看懂了,如果写的过程中,半信半疑,为了写好一个博客,就会再回去仔细翻看一下是怎么回事,希望能够坚持下去。















 2345
2345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









