







所在团队主要方向聚焦漏洞挖掘,我在延续区块链共识研究之外,调研了关于漏洞挖掘相关的技术,最终决定从模糊测试入手,作为我的新研究方向,在此记录一些学习笔记。
1 什么是模糊测试
模糊测试(Fuzzting test)的概念最早由Barton Miller等人于1988年提出,它是一种自动化的测试技术,其核心思想是将大量随机产生的非预期的数据输入到目标程序中,同时收集并监视目标程序在测试用例执行中的异常信息,以尽可能地发现导致目标程序错误的非法输入,找到目标程序的脆弱点。
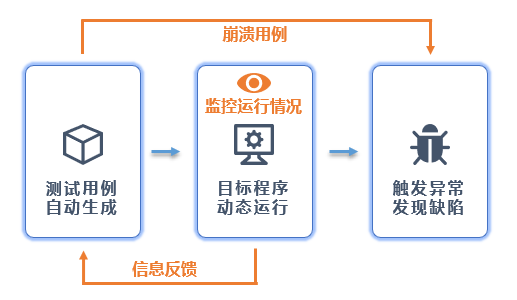
模糊测试与软件测试的相同之处:
- 为了确保软件的质量和稳定性,通过构造输入以测试目标程序。
- 需要运行目标程序并记录程序运行结果,分析导致错误的原因。
模糊测试与软件测试的不同之处:
- 软件测试
- 目的是验证软件的正确性和满足用户需求。
- 人为或自动化地构造程序输入和预期结果,逻辑覆盖即可。
- 期待执行通过,仅关心运行结果,最多到函数调用栈。
- 模糊测试
- 目的是发现程序中的漏洞和引发崩溃错误。
- 自动化地生成非预期或不可能的输入,直到引起故障。
- 期待执行异常,监控程序运行时状态,收集路径空间。
模糊测试提供了一种方法,在理论和实践上都能有效发掘程序漏洞。到目前,模糊测试这种技术已经发现了上千个真实世界中程序的漏洞,包括固件、内核、数据库等。相比于软件测试,模糊测试设计了两个关键模块:程序监控器、输入生成器。
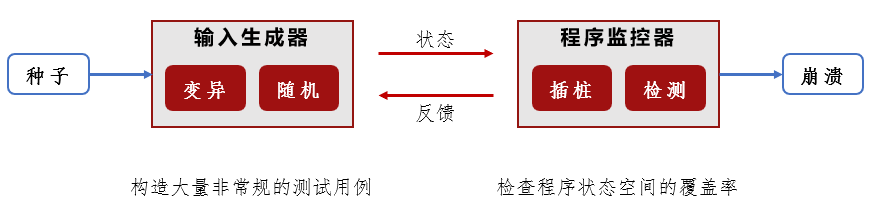
本报告为入门学习笔记,首先从模糊测试的综述文献开始,了解基本概念和研究现状,然后以经典模糊测试工具着手,掌握技术细节和简单使用。
本报告主要阅读和参考以下三篇综述文献:
-
Fuzzing: A Survey (Li2018,tsinghua)
-
Fuzzing: State of the Art (Liang2018,bupt)
-
Fuzzing: A Survey for Roadmap (Zhu2022,swin)

本报告主要学习经典模糊测试工具AFL(American Fuzzy Lop),官方网站为https://lcamtuf.coredump.cx/afl/
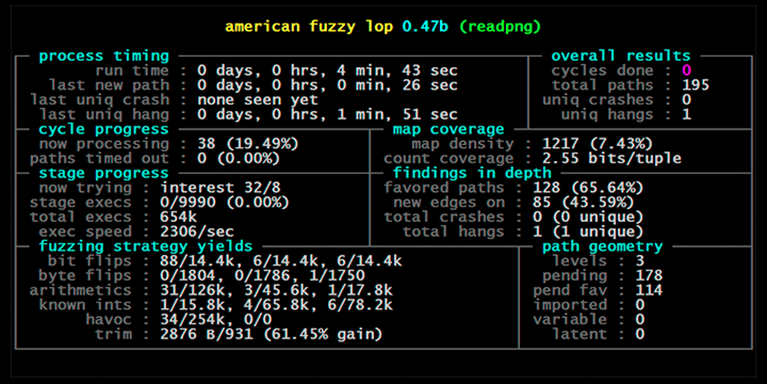
2 综述文献阅读
2.1 Fuzzing: A Survey
Jun Li, Bodong Zhao, Chao Zhang. Fuzzing: a survey[J]. Cybersecurity, 2018, 1(1): 1-13.
首先,这篇综述在背景章节介绍了4种传统的漏洞挖掘技术。
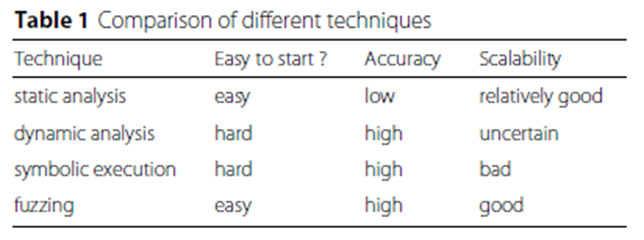
- 静态分析:无需实际运行程序,通常是针对源代码,分析其词法、语法、语义特征、数据流,通过模型检查来发现潜在的漏洞。(错误率高)
- 动态分析:需要实际运行程序或模拟执行,通过监控器了解运行时状态,可以更加精确地发现程序存在的漏洞。(效率较低)
- 符号执行:将程序的输入符号化,对执行路径构建约束集合,通过约束求解来确定能够执行某些路径的输入,定义约束方程来发现漏洞。(状态爆炸)
- 模糊测试:构造大量的正常与非正常的输入,给到目标程序并监测目标程序产生的异常,通过执行状态发现漏洞。(覆盖率低)
然后,这篇综述对模糊测试给出了基本的说明。
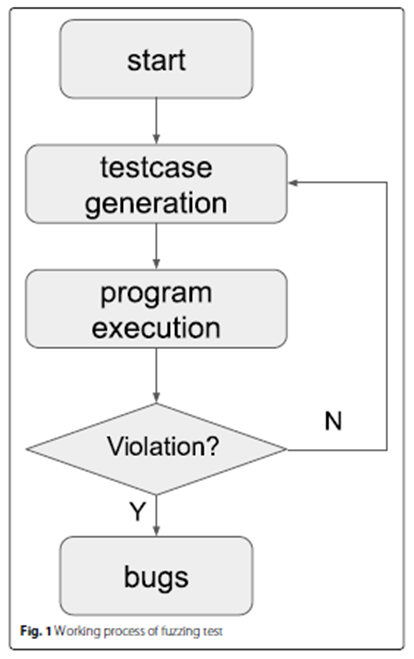
- 模糊测试的工作流程:
- 测试用例生成阶段
- 测试用例运行阶段
- 程序执行状态监控
- 程序执行异常分析
- 模糊测试的类型分类:
- 从程序输入来看,fuzzers可以分为基于生成的和基于变异的
- 从程序源码来看,fuzzers可以分为白盒、灰盒、黑盒
- 从探索策略来看,fuzzers可以分为直接的和基于覆盖的
- 从监控反馈来看,fuzzers可以分为沉默型的和聪明型
接着,这篇综述重点关注基于覆盖的模糊测试。
代码覆盖率计算:计算执行的代码块或者计算基本代码块转移。AFL是一种基于覆盖的模糊测试工具,提供了gcc、llvm和qemu三种模式,其中前两种在编译时插桩,最后一种通过外部插桩。基于覆盖的模糊测试将桩的转移作为边,计算边的命中次数。
最后,这篇综述介绍了其他技术与模糊测试的结合,以及模糊测试更多的应用场景。
智能模糊测试的框架如图:
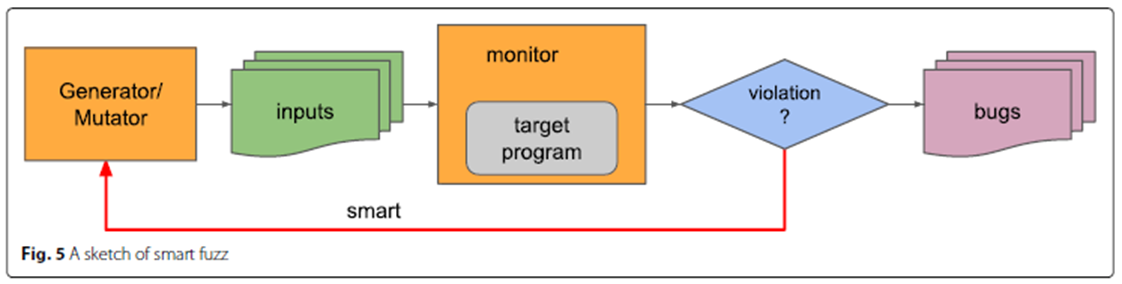
一些传统的技术,如静态分析,污点分析,符号执行,机器学习,等都结合到了模糊测试框架中。
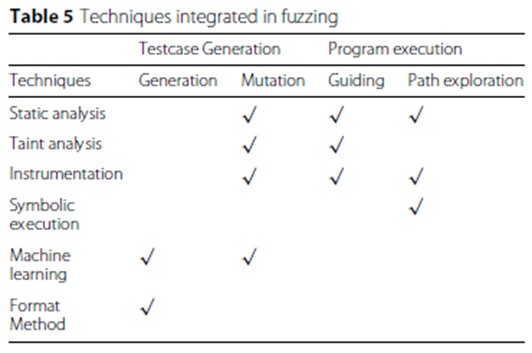
模糊测试一直用于挖掘软件和系统的脆弱性,针对不同的应用开发了不同的工具,策略不同则特点不同。
- 文件格式的模式测试:Peach、Grinder、COMRaider等
- 内核的模糊测试:syzkaller、TriforceAFL、kAFL等
- 网络协议的模糊测试:SPIKE、AutoFuzz、SNOOZE等
2.2 Fuzzing: State of the Art
Hongliang Liang, Xiaoxiao Pei, Xiaodong Jia, Wuwei Shen, Jian Zhang. Fuzzing: State of the art[J]. IEEE Transactions on Reliability, 2018, 67(3): 1199-1218.
首先,这篇综述介绍了作者进行文献综述的方法,通过研究问题引导研究工作开展。
作者搜索模糊测试相关的文献,从1990年1月到2017年6月,收集了超过350篇学术论文,以fuzz testing、fuzzing、fuzzer、random testing、swarm testing为关键字;再通过阅读文献的摘要进行人工筛选,共整理了171篇构成了当前综述。
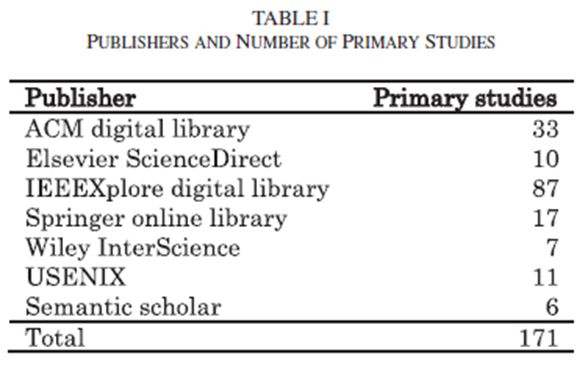
根据学术论文集,分析了这些论文在模糊测试方向,
- 发布趋势:文献量逐年上升,是为研究热点。
- 发布地点:可靠性、安全领域的重要会议更多。
- 地理分布:美国最多,其次中国、德国、英国。
- 作者组织:来自微软研究院、大学、实验室等。
然后,这篇综述介绍模糊测试的通用过程,以及对模糊测试方法的分类。

- 目标程序:执行测试的程序,二进制或源代码。
- 监控器:通常利用代码插桩、污点分析等获取运行时信息。
- 测试用例生成器:主要有基于变异和基于语法来产生输入。
- 漏洞检测器:帮助用户发现潜在的漏洞,记录异常信息。
- 漏洞筛选:聚焦于正确和安全相关的漏洞,筛选能利用的。
模糊测试被划分为黑盒、白盒、灰盒。黑盒即随机测试,代码覆盖率很低;白盒利用了目标程序的内部逻辑知识,结合符号执行、启发式搜索算法等;灰盒通常使用代码插桩,以及污点分析追踪数据流。
接着,这篇综述根据模糊测试的通用过程,列举了针对不同阶段的前人工作。
- 种子生成的选取:给定目标程序,模糊测试需要产生输入,种子的质量决定了测试的效果。
- 输入检验和覆盖:如果目标程序对输入有验证机制,不满足条件的输入会在更早的阶段被拒绝,这类验证包括完整性验证、格式验证、环境验证、输入覆盖。
- 处理引发崩溃的测试用例:造成奔溃的测试用例相当多,对其进行分类、排序和筛选,提供有用的调试信息。
- 利用运行时信息:符号执行和污点分析通常用来使得模糊测试更加智能,发现隐藏的漏洞。而其中面临的问题有路径爆炸、不准确的符号执行、欠污点追踪、过污点追踪。
- 模糊测试扩展性:有大量的应用程序,需要提高扩展性,降低分析的范围。
最后,这篇综述列举了在不同应用领域的比较主流的模糊测试工具。
- 通用目的的Fuzzers:Peach、beSTORM
- 编译和解释的Fuzzers:jsfunfuzz、Csmith、LangFuzz、CLsmith
- 应用软件的Fuzzers:SAGE、AFL、QuickFuzz
- 网络协议的Fuzzers:Sulley、TLS-Attacker
- 操作系统内核的Fuzzers:Trinity、Syzkaller、IOCTL Fuzzer、Kernel-AFL、CAB-FUZZ
- 嵌入式设备的Fuzzers:YMIR、vUSBf
2.3 Fuzzing: A Survey for Roadmap
Xiaogang Zhu, Sheng Wen, Seyit Camtepe, Yang Xiang. Fuzzing: a survey for roadmap[J]. ACM Computing Surveys (CSUR), 2022, 54(11s): 1-36.
首先,这篇综述介绍了在模糊测试领域里的知识gaps,用集合论空间的思想来概括相关研究。
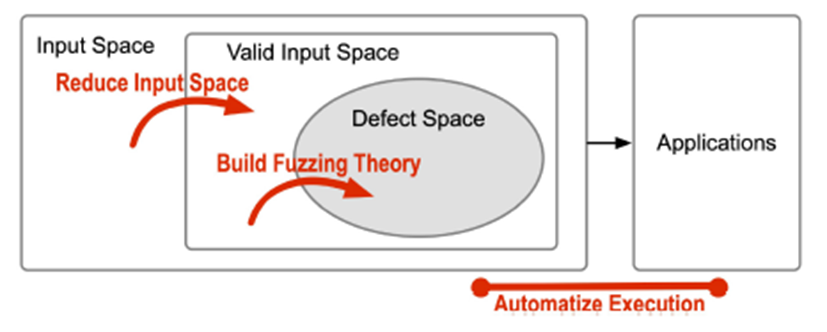
模糊测试产生大量的测试用例重复地输入到目标程序并监控程序异常,其中异常就是潜在的安全漏洞。
- Gap1:稀疏的缺陷空间(构建模糊理论找到缺陷)
- Gap2:严格合法的输入空间(缩小可能的输入集合)
- Gap3:多种目标(自动化执行和检测)
大量的研究都在努力缩小这些gaps,这篇文章按照上述框架展开综述。
然后,这篇综述介绍了模糊测试的通用流程和常用术语。
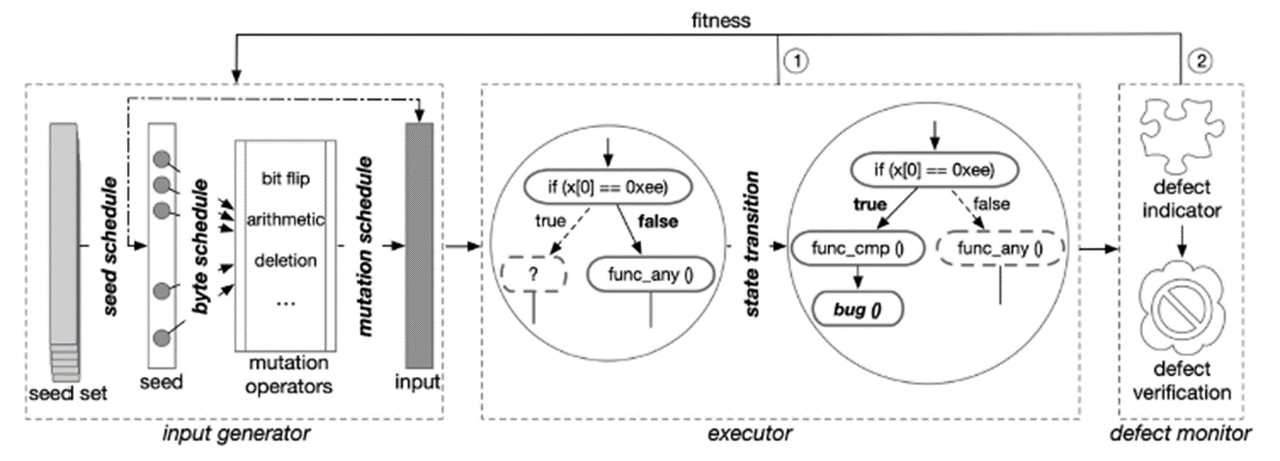
模糊测试由三个组件构成:输入生成器、执行器和缺陷监控器。输入由种子产生,适应度用来衡量种子的质量,能量表示分配模糊测试的变异数量。
- 从测试用例来看,fuzzing分为基于生成的和基于变异的
- 从程序执行来看,fuzzing分为黑盒、灰盒、白盒
接着,这篇综述从模糊测试理论来梳理和概括相关工作。
- 种子集选取:COVERSET形式化了一个最小覆盖问题来利用种子生成输入。
- 种子排序:利用漏洞信息和执行状态作为适应度来改进种子;通过状态转移甚至是发现新状态作为适应度来改进种子。
- 字节排序:选择关键的字节进行变异来改进种子;还可以基于深度学习模型评估字节的质量。
- 变异器排序:利用马尔科夫链蒙特卡洛方法来选择变异器;利用粒子群优化方法选择变异器。
- 多信息适应:通常采用遗传算法来寻找可能的输入;提高代码覆盖的敏感度以探索更多路径;使用执行结果、协议状态、安全策略等构造合适的适应度评估。
模糊测试理论有效地降低了从输入空间到缺陷空间的gap,有助于漏洞发现的成功率。
接着,这篇综述从输入的搜索空间来梳理和概括相关工作。
- 字节约束关系:在路径约束中,只有特定字节才会影响程序执行的结果。
- 符号执行:将程序抽象成逻辑树,通过求解可满足问题找到有效输入。
- 程序转换:主要是为了移除一些完整性检查。
- 输入模型:针对特定的应用构造符合要求的格式化输入。
- 片段重组:将输入解析成抽象语法树,将树种的节点打散并重组构造新的输入。
- 格式推理:利用循环神经网络构造语料;通过覆盖信息和编码函数来变异输入。
- 依赖推理:根据数据依赖和函数调用关系来扩大输入的覆盖率。
缩小输入空间以提供有效的输入用于模糊测试,解决gap2中的问题
最后,这篇综述从程序自动化执行来梳理和概括相关工作。
- 自动化程序执行:命令行程序、操作系统内核、物理空间系统、物联网、图形用户接口、网络应用
- 自动化漏洞检查:内存异常漏洞、并发锁漏洞、算法复杂度、幽灵型漏洞、测信道、整数溢出漏洞
- 提升执行效率:二进制分析:LLVM插桩分析、执行进程:运行时追踪、其他应用:系统内核,硬件设备等
自动化执行测试和发现漏洞需要设计相应的检测器,解决gap3中的问题。
3 经典工具学习
3.1 AFL源码分析
AFL(American Fuzzy Lop)是由前Google安全研究员lcamtuf(Michal Zalewski)开发的一款基于覆盖的模糊测试工具。用Understand工具绘出的项目结构图如下,其主要代码编写在afl-fuzz.c文件中。

- 【插桩模块】
- 普通模式:afl-as.h,afl-as.c,afl.gcc.c
- llvm模式:./llvm_mode
- qemu模式:./qemu_mode
- 【fuzzer模块】
- afl-fuzz.c:执行模糊测试的核心逻辑
- 【其他辅助模块】
- afl-analyze.c:对测试用例进行分析,通过分析给定的用例,确定是否可以发现用例中有意义的字段;
- afl-plot.c:生成测试任务的状态图;
- afl-tmin.c:对测试用例进行最小化;
- afl-showmap.c:对单个测试用例进行执行路径跟踪;
- afl-gotcpu.c:查看当前CPU状态,统计CPU占用率。
- libdislocator:简单的内存错误检测工具;
- libtokencap:语法关键字提取并生成字典文件。
参考博客:https://www.freebuf.com/articles/others-articles/290197.html
AFL的设计是在dumb fuzzer之上加了一层基于覆盖率的反馈机制,该过程中AFL会维护一个语料库队列queue,包含了初始测试用例以及变异后有新状态产生的测试用例,变异操作分为确定性策略和随机策略两类。
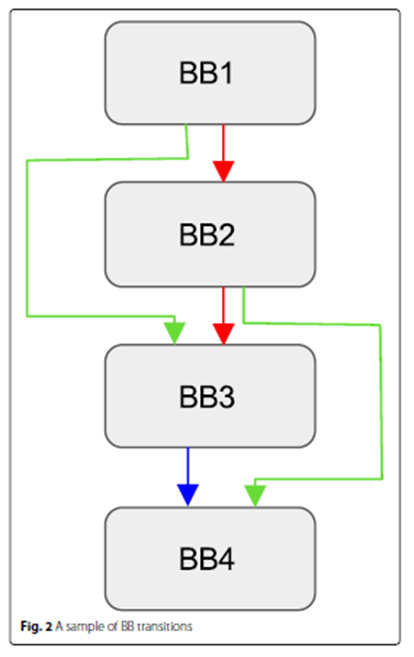
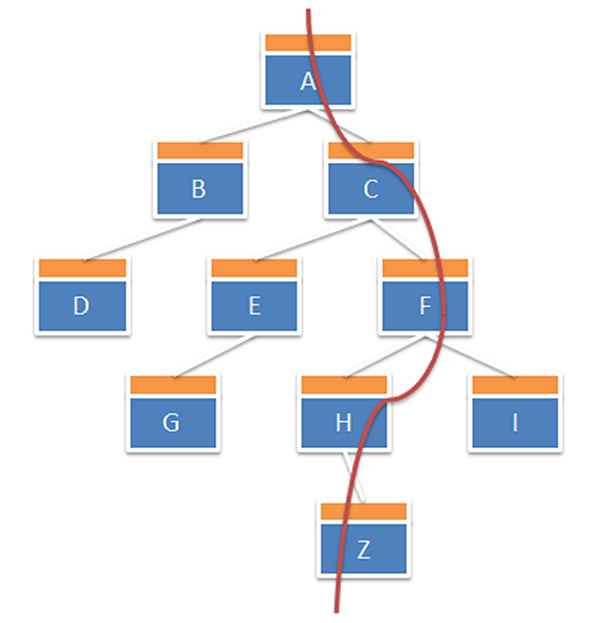
记录程序执行路径,蓝色块是程序基本块,黄色块是探针代码。将源基本块与目的基本块配对组合,下图路径为(AC,CF,FH,HZ)。
AFL中的三种插桩模式是针对目标程序提供源码的情况来选择的,编译级的llvm模式插桩包含更多优化,汇编级的普通插桩模式覆盖原有的编译器,针对二进制文件的目标程序则需要借助qemu模式。
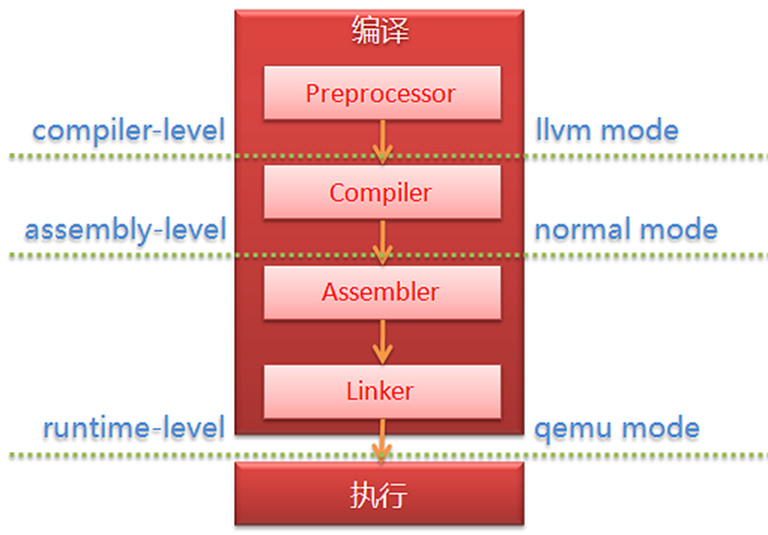
本报告主要介绍普通模式下的插桩,掌握插桩的技术细节和程序实现,在AFL中插桩的用途为
- 记录程序执行的覆盖路径计数
- 初始操作以及维护一个forkserver
参考博客:https://bbs.kanxue.com/thread-249912.htm
3.2 AFL代码插桩
在普通模式中,AFL将源文件编译为汇编代码后,通过afl-as完成,插桩的内容在afl-as.h中。
static const u8* trampoline_fmt_32 =
"\n"
"/* --- AFL TRAMPOLINE (32-BIT) --- */\n"
"\n"
".align 4\n"
"\n"
"leal -16(%%esp), %%esp\n"
"movl %%edi, 0(%%esp)\n"
"movl %%edx, 4(%%esp)\n"
"movl %%ecx, 8(%%esp)\n"
"movl %%eax, 12(%%esp)\n"
"movl $0x%08x, %%ecx\n"
"call __afl_maybe_log\n"
"movl 12(%%esp), %%eax\n"
"movl 8(%%esp), %%ecx\n"
"movl 4(%%esp), %%edx\n"
"movl 0(%%esp), %%edi\n"
"leal 16(%%esp), %%esp\n"
"\n"
"/* --- END --- */\n"
"\n";
这段代码的主要操作是调用__afl_maybe_log方法,将保存在%ecx中的值传入到该方法中。
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE));
ins_lines++;
插入的值在afl-as.c文件中由add_instrumentation函数完成,插入一个0到64K之间的随机数。
参考博客:https://rk700.github.io/2017/12/28/afl-internals/
fork server机制
AFL实现了一套fork server机制,在启动目标程序后,运行一个服务器,fuzzer不负责创建子进程来执行程序,而是与这个服务器通信,由服务器完成子进程创建和测试执行,其目的是为了减少execve()系统调用,提高性能。
在afl-fuzz.c文件中,初始化过程创建2个管道,用于fuzzer与server间通信,st_pipe传递状态,ctl_pipe传递命令。之后,执行目标程序启动server。
EXP_ST void init_forkserver(char** argv) {
static struct itimerval it;
int st_pipe[2], ctl_pipe[2];
int status;
s32 rlen;
ACTF("Spinning up the fork server...");
if (pipe(st_pipe) || pipe(ctl_pipe)) PFATAL("pipe() failed");
forksrv_pid = fork();
...
execv(target_path, argv);
...
}
fork server也是以插桩的方式插入到汇编代码中。
static const u8* main_payload_32 =
"\n"
"/* --- AFL MAIN PAYLOAD (32-BIT) --- */\n"
"\n"
".text\n"
".att_syntax\n"
".code32\n"
".align 8\n"
"\n"
...
当server成功启动后,会利用状态管道通知fuzzer,然后进入等待状态_afl_fork_wait_loop,读取命令管道。
"__afl_forkserver:\n"
"\n"
" /* Enter the fork server mode to avoid the overhead of execve() calls. */\n"
"\n"
" pushl %eax\n"
" pushl %ecx\n"
" pushl %edx\n"
"\n"
" /* Phone home and tell the parent that we're OK. (Note that signals with\n"
" no SA_RESTART will mess it up). If this fails, assume that the fd is\n"
" closed because we were execve()d from an instrumented binary, or because\n"
" the parent doesn't want to use the fork server. */\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_temp /* data */\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n"
" call write\n"
" addl $12, %esp\n"
"\n"
" cmpl $4, %eax\n"
" jne __afl_fork_resume\n"
"\n"
一旦接收到fuzzer的信息,则fork子进程去执行目标程序。
"__afl_fork_wait_loop:\n"
"\n"
" /* Wait for parent by reading from the pipe. Abort if read fails. */\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_temp /* data */\n"
" pushl $" STRINGIFY(FORKSRV_FD) " /* file desc */\n"
" call read\n"
" addl $12, %esp\n"
"\n"
" cmpl $4, %eax\n"
" jne __afl_die\n"
"\n"
" /* Once woken up, create a clone of our process. This is an excellent use\n"
" case for syscall(__NR_clone, 0, CLONE_PARENT), but glibc boneheadedly\n"
" caches getpid() results and offers no way to update the value, breaking\n"
" abort(), raise(), and a bunch of other things :-( */\n"
"\n"
" call fork\n"
"\n"
" cmpl $0, %eax\n"
" jl __afl_die\n"
" je __afl_fork_resume\n"
"\n"
父进程会将子进程的pid通过状态管道发给fuzzer,等待子进程执行完毕再将其结束状态发给fuzzer,之后再次进行等待_afl_fork_wait_loop。
" /* In parent process: write PID to pipe, then wait for child. */\n"
"\n"
" movl %eax, __afl_fork_pid\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_fork_pid /* data */\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n"
" call write\n"
" addl $12, %esp\n"
"\n"
" pushl $0 /* no flags */\n"
" pushl $__afl_temp /* status */\n"
" pushl __afl_fork_pid /* PID */\n"
" call waitpid\n"
" addl $12, %esp\n"
"\n"
" cmpl $0, %eax\n"
" jle __afl_die\n"
"\n"
" /* Relay wait status to pipe, then loop back. */\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_temp /* data */\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n"
" call write\n"
" addl $12, %esp\n"
"\n"
" jmp __afl_fork_wait_loop\n"
"\n"
fuzzer会调用run_target函数来执行某个测试用例,命令管道通知server,状态管道获取子进程pid。
s32 res;
/* In non-dumb mode, we have the fork server up and running, so simply
tell it to have at it, and then read back PID. */
if ((res = write(fsrv_ctl_fd, &prev_timed_out, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to request new process from fork server (OOM?)");
}
if ((res = read(fsrv_st_fd, &child_pid, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to request new process from fork server (OOM?)");
}
if (child_pid <= 0) FATAL("Fork server is misbehaving (OOM?)");
再次读取状态管理,获得子进程退出状态
s32 res;
if ((res = read(fsrv_st_fd, &status, 4)) != 4) {
if (stop_soon) return 0;
RPFATAL(res, "Unable to communicate with fork server (OOM?)");
}
共享内存机制
插桩执行的代码主要在__afl_maybe_log方法中,server通过共享内存与fuzzer完成程序执行时分支信息的记录。
EXP_ST void setup_shm(void) {
u8* shm_str;
if (!in_bitmap) memset(virgin_bits, 255, MAP_SIZE);
memset(virgin_tmout, 255, MAP_SIZE);
memset(virgin_crash, 255, MAP_SIZE);
shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600);
if (shm_id < 0) PFATAL("shmget() failed");
atexit(remove_shm);
shm_str = alloc_printf("%d", shm_id);
/* If somebody is asking us to fuzz instrumented binaries in dumb mode,
we don't want them to detect instrumentation, since we won't be sending
fork server commands. This should be replaced with better auto-detection
later on, perhaps? */
if (!dumb_mode) setenv(SHM_ENV_VAR, shm_str, 1);
ck_free(shm_str);
trace_bits = shmat(shm_id, NULL, 0);
if (!trace_bits) PFATAL("shmat() failed");
}
在setup_shm函数中调用shmget方法分配64K大小的内存空间,并将内存地址写入环境变量,fuzzer本身使用变量trace_bits来保存内存地址。fuzzer每次在执行测试用例之前,都会对共享内存做清零操作。
memset(trace_bits, 0, MAP_SIZE);
MEM_BARRIER();
server在执行__afl_maybe_log方法时,首先检查共享内存是否映射完成。
"__afl_maybe_log:\n"
"\n"
" lahf\n"
" seto %al\n"
"\n"
" /* Check if SHM region is already mapped. */\n"
"\n"
" movl __afl_area_ptr, %edx\n"
" testl %edx, %edx\n"
" je __afl_setup\n"
"\n"
从环境变量AFL_SHM_ENV中获取共享内存地址。
"__afl_setup:\n"
"\n"
" /* Do not retry setup if we had previous failures. */\n"
"\n"
" cmpb $0, __afl_setup_failure\n"
" jne __afl_return\n"
"\n"
" /* Map SHM, jumping to __afl_setup_abort if something goes wrong.\n"
" We do not save FPU/MMX/SSE registers here, but hopefully, nobody\n"
" will notice this early in the game. */\n"
"\n"
" pushl %eax\n"
" pushl %ecx\n"
"\n"
" pushl $.AFL_SHM_ENV\n"
" call getenv\n"
" addl $4, %esp\n"
"\n"
" testl %eax, %eax\n"
" je __afl_setup_abort\n"
"\n"
调用shmat函数将共享内存映射到进程中,地址保存在__afl_area_ptr。
"\n"
" pushl $0 /* shmat flags */\n"
" pushl $0 /* requested addr */\n"
" pushl %eax /* SHM ID */\n"
" call shmat\n"
" addl $12, %esp\n"
"\n"
" cmpl $-1, %eax\n"
" je __afl_setup_abort\n"
"\n"
" /* Store the address of the SHM region. */\n"
"\n"
" movl %eax, __afl_area_ptr\n"
" movl %eax, %edx\n"
"\n"
" popl %ecx\n"
" popl %eax\n"
"\n"
分支信息记录
在AFL的官方文档中,程序根据源基本块到目的基本块的二元组来记录程序执行的分支信息,从而计算代码覆盖情况,伪代码描述如下:
cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
对应到程序实现中,该过程由server调用_afl_store方法完成,随机数右移一位之后作为程序执行的位置信息。
"__afl_store:\n"
"\n"
" /* Calculate and store hit for the code location specified in ecx. There\n"
" is a double-XOR way of doing this without tainting another register,\n"
" and we use it on 64-bit systems; but it's slower for 32-bit ones. */\n"
"\n"
#ifndef COVERAGE_ONLY
" movl __afl_prev_loc, %edi\n"
" xorl %ecx, %edi\n"
" shrl $1, %ecx\n"
" movl %ecx, __afl_prev_loc\n"
#else
" movl %ecx, %edi\n"
#endif /* ^!COVERAGE_ONLY */
"\n"
#ifdef SKIP_COUNTS
" orb $1, (%edx, %edi, 1)\n"
#else
" incb (%edx, %edi, 1)\n"
#endif /* ^SKIP_COUNTS */
"\n"
然后在共享内存中对应的位置进行自增计数(存在一定的碰撞概率)。在server执行完一次目标程序之后,fuzzer会对共享内存进行预处理。
tb4 = *(u32*)trace_bits;
#ifdef __x86_64__
classify_counts((u64*)trace_bits);
#else
classify_counts((u32*)trace_bits);
#endif /* ^__x86_64__ */
具体地,每个分支的执行次数用1个自己来存储而fuzzer更进一步把执行册数归入下面的桶中,在一定程度上缓解了状态爆炸的情况。
static const u8 count_class_lookup8[256] = {
[0] = 0,
[1] = 1,
[2] = 2,
[3] = 4,
[4 ... 7] = 8,
[8 ... 15] = 16,
[16 ... 31] = 32,
[32 ... 127] = 64,
[128 ... 255] = 128
};
当一次测试用例执行完成后,fuzzer会检查是否有新的执行路径,通过计算共享内存的哈希值来比对实现。新的路径将被重点关注,用于后续对输入文件的变异操作。
cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST);
3.3 AFL输入变异
在fuzzer的主程序中,AFL维护一个队列queue,循环更新该队列并执行fuzz_one函数来做输入文件的变异操作并获得模糊测试结果。变异操作的主要类型如下:
- bitflip:简单的按位翻转,1->0,0->1。
- arithmetic:整数加/减算术运算。
- interest:替换一些特殊内容到原文件中。
- dictionary:用户提供或自动生成的token替换/插入到原文件中。
- havoc:中文意思是“大破坏”,此阶段会对原文件进行大量变异。
- splice:中文意思是“绞接”,此阶段会将两个文件拼接起来得到一个新的文件。
参考博客:https://rk700.github.io/2018/01/04/afl-mutations/
bitflip通过宏定义翻转特定比特位置。根据翻转量/步长进行多种不同的翻转,按照顺序依次为:
#define FLIP_BIT(_ar, _b) do { \
u8* _arf = (u8*)(_ar); \
u32 _bf = (_b); \
_arf[(_bf) >> 3] ^= (128 >> ((_bf) & 7)); \
} while (0)
bitflip 1/1:每次翻转1个bit,步长1个bit
FLIP_BIT(out_buf, stage_cur);
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
FLIP_BIT(out_buf, stage_cur);
bitflip 2/1:每次翻转相邻2个bit,步长1个bit
FLIP_BIT(out_buf, stage_cur);
FLIP_BIT(out_buf, stage_cur + 1);
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
FLIP_BIT(out_buf, stage_cur);
FLIP_BIT(out_buf, stage_cur + 1);
bitflip 4/1:每次翻转相邻4个bit,步长1个bit
FLIP_BIT(out_buf, stage_cur);
FLIP_BIT(out_buf, stage_cur + 1);
FLIP_BIT(out_buf, stage_cur + 2);
FLIP_BIT(out_buf, stage_cur + 3);
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
FLIP_BIT(out_buf, stage_cur);
FLIP_BIT(out_buf, stage_cur + 1);
FLIP_BIT(out_buf, stage_cur + 2);
FLIP_BIT(out_buf, stage_cur + 3);
bitflip 8/8:每次翻转相邻8个bit,步长8个bit,即对byte做翻转
out_buf[stage_cur] ^= 0xFF;
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
...
out_buf[stage_cur] ^= 0xFF;
bitflip 16/8:每次翻转相邻16个bit,步长8个bit,即对word做翻转
*(u16*)(out_buf + i) ^= 0xFFFF;
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
*(u16*)(out_buf + i) ^= 0xFFFF;
bitflip 32/8:每次翻转相邻32个bit,步长8个bit,即对dword做翻转
*(u32*)(out_buf + i) ^= 0xFFFFFFFF;
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
*(u32*)(out_buf + i) ^= 0xFFFFFFFF;
在bitflip变异完成后,便进入arithmetic阶段,根据目标大小不同,也分为了多个子阶段:
arith 8/8:每次对8个bit进行加减运算,步长8个bit,即对byte进行整数加减变异
for (j = 1; j <= ARITH_MAX; j++) {
u8 r = orig ^ (orig + j);
/* Do arithmetic operations only if the result couldn't be a product
of a bitflip. */
if (!could_be_bitflip(r)) {
stage_cur_val = j;
out_buf[i] = orig + j;
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
} else stage_max--;
...
}
arith 16/8:每次对16个bit进行加减运算,步长8个bit,即对word进行整数加减变异
for (j = 1; j <= ARITH_MAX; j++) {
u16 r1 = orig ^ (orig + j),
r2 = orig ^ (orig - j),
r3 = orig ^ SWAP16(SWAP16(orig) + j),
r4 = orig ^ SWAP16(SWAP16(orig) - j);
/* Try little endian addition and subtraction first. Do it only
if the operation would affect more than one byte (hence the
& 0xff overflow checks) and if it couldn't be a product of
a bitflip. */
stage_val_type = STAGE_VAL_LE;
if ((orig & 0xff) + j > 0xff && !could_be_bitflip(r1)) {
stage_cur_val = j;
*(u16*)(out_buf + i) = orig + j;
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
} else stage_max--;
...
}
arith 32/8:每次对32个bit进行加减运算,步长8个bit,即对dword进行整数加减变异
for (j = 1; j <= ARITH_MAX; j++) {
u32 r1 = orig ^ (orig + j),
r2 = orig ^ (orig - j),
r3 = orig ^ SWAP32(SWAP32(orig) + j),
r4 = orig ^ SWAP32(SWAP32(orig) - j);
/* Little endian first. Same deal as with 16-bit: we only want to
try if the operation would have effect on more than two bytes. */
stage_val_type = STAGE_VAL_LE;
if ((orig & 0xffff) + j > 0xffff && !could_be_bitflip(r1)) {
stage_cur_val = j;
*(u32*)(out_buf + i) = orig + j;
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
} else stage_max--;
...
}
在config.h文件中对ARITH_MAX做了宏定义,默认为35。所以会对目标整数进行+1, +2, …, +35, -1, -2, …, -35的变异。
/* Maximum offset for integer addition / subtraction stages: */
#define ARITH_MAX 35
在下一阶段是interest,也分为多个子阶段:
interest 8/8,每次对8个bit进行替换,步长8个bit,即对文件的byte进行替换
stage_cur_val = interesting_8[j];
out_buf[i] = interesting_8[j];
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
out_buf[i] = orig;
stage_cur++;
interest 16/8,每次对16个bit进行替换,步长8个bit,即对文件的word进行替换
*(u16*)(out_buf + i) = interesting_16[j];
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
interest 32/8,每次对32个bit进行替换,步长8个bit,即对文件的dword进行替换
*(u32*)(out_buf + i) = interesting_32[j];
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
用于替换的interesting values是由AFL预设的一些数
/* Interesting values, as per config.h */
static s8 interesting_8[] = { INTERESTING_8 };
static s16 interesting_16[] = { INTERESTING_8, INTERESTING_16 };
static s32 interesting_32[] = { INTERESTING_8, INTERESTING_16, INTERESTING_32 };
/* List of interesting values to use in fuzzing. */
#define INTERESTING_8 \
-128, /* Overflow signed 8-bit when decremented */ \
-1, /* */ \
0, /* */ \
1, /* */ \
16, /* One-off with common buffer size */ \
32, /* One-off with common buffer size */ \
64, /* One-off with common buffer size */ \
100, /* One-off with common buffer size */ \
127 /* Overflow signed 8-bit when incremented */
#define INTERESTING_16 \
-32768, /* Overflow signed 16-bit when decremented */ \
-129, /* Overflow signed 8-bit */ \
128, /* Overflow signed 8-bit */ \
255, /* Overflow unsig 8-bit when incremented */ \
256, /* Overflow unsig 8-bit */ \
512, /* One-off with common buffer size */ \
1000, /* One-off with common buffer size */ \
1024, /* One-off with common buffer size */ \
4096, /* One-off with common buffer size */ \
32767 /* Overflow signed 16-bit when incremented */
#define INTERESTING_32 \
-2147483648LL, /* Overflow signed 32-bit when decremented */ \
-100663046, /* Large negative number (endian-agnostic) */ \
-32769, /* Overflow signed 16-bit */ \
32768, /* Overflow signed 16-bit */ \
65535, /* Overflow unsig 16-bit when incremented */ \
65536, /* Overflow unsig 16 bit */ \
100663045, /* Large positive number (endian-agnostic) */ \
2147483647 /* Overflow signed 32-bit when incremented */
dictionary阶段是确定性变异的最后一个阶段,分为以下几种方式:
user extras (over):将用户提供的tokens依次替换到原文件中
last_len = extras[j].len;
memcpy(out_buf + i, extras[j].data, last_len);
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
user extras (insert):将用户提供的tokens依次插入到原文件中
/* Insert token */
memcpy(ex_tmp + i, extras[j].data, extras[j].len);
/* Copy tail */
memcpy(ex_tmp + i + extras[j].len, out_buf + i, len - i);
if (common_fuzz_stuff(argv, ex_tmp, len + extras[j].len)) {
ck_free(ex_tmp);
goto abandon_entry;
}
stage_cur++;
auto extras (over):将自动检测的tokens依次替换到原文件中
last_len = a_extras[j].len;
memcpy(out_buf + i, a_extras[j].data, last_len);
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
此外,在进行字节翻转时,AFL还维护了一个effector map用来检测某个位置的字节变化是否会带来程序执行路径的变化,如果没有则对其进行标记,在随后的变异中跳过以节省资源。
/* Effector map setup. These macros calculate:
EFF_APOS - position of a particular file offset in the map.
EFF_ALEN - length of a map with a particular number of bytes.
EFF_SPAN_ALEN - map span for a sequence of bytes.
*/
#define EFF_APOS(_p) ((_p) >> EFF_MAP_SCALE2)
#define EFF_REM(_x) ((_x) & ((1 << EFF_MAP_SCALE2) - 1))
#define EFF_ALEN(_l) (EFF_APOS(_l) + !!EFF_REM(_l))
#define EFF_SPAN_ALEN(_p, _l) (EFF_APOS((_p) + (_l) - 1) - EFF_APOS(_p) + 1)
4 学习笔记
模糊测试作为一种自动化测试技术,它提供了一种框架来帮助系统寻找潜在的脆弱性。一方面,模糊测试可以结合静态分析、符号执行、机器学习等技术来丰富其框架。另一方面、模糊测试也不局限于应用在软件系统等,还能扩展到车辆、工业等硬件上。
对于模糊测试,可研究的核心问题主要有三条路径:
- 输入文件的生成变异:如何产生大量的测试用例以挖掘出潜在漏洞。
- 模糊测试的流程框架:如何结合更先进的技术以提高模糊测试效率。
- 错误检测的工具指标:如何设计准确的崩溃检测有目的的挖掘漏洞。

















 2878
2878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









