







刚开始一直在寻找PRISMA的相关文档,感觉很少,结果后面才发现在下载包中的vignettes以及inst文件下面,有对它的详细介绍以及示例展示,还是自己不够细心,导致浪费了很长一段时间。QAQ
Introduction
- PRISMA可以高效地处理sally输出文件,很快地处理n-gram过程;
- Testing-based feature dimension reduction(降维);
最优矩阵分解
整体流程图:
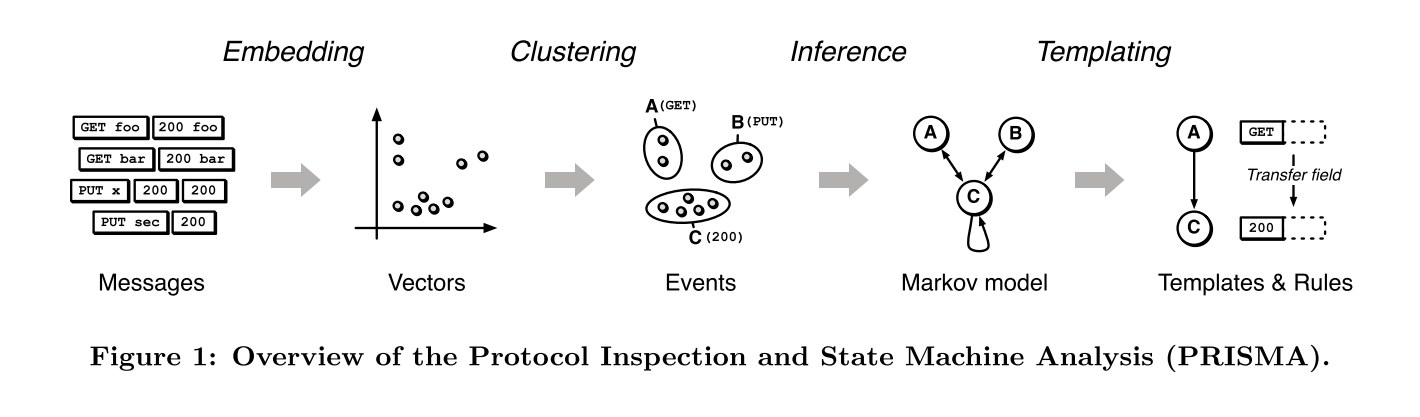
Loading the Data
首先需要 获得“.sally”文件,就是通过sally对原始网络流量进行处理;
在目录/inst/extdata中有提供测试数据集asap,其中原始数据asap.raw如图所示:

asap.cfg是Sally的配置文件,通过如下命令得到PRISMA输入。
sally -c asap.cfg asap.raw asap.sally
python sallyProcessing.py asap.sally asap.fsally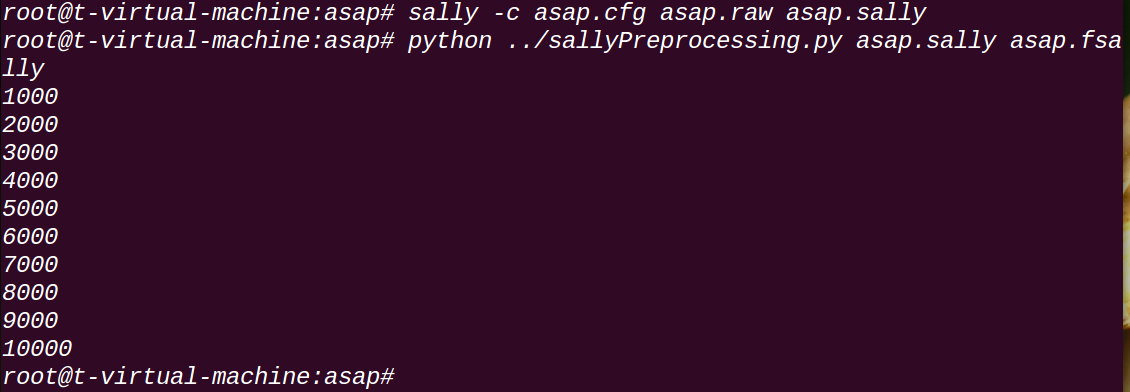
这里笔者想说一下很重要的一点,就是sally是干嘛的(之前很久没有弄懂,终于看了源码以及帮助文档之后弄懂了)。
下面以granularity为tokens,输出格式为“text”为例:
- 首先sally会根据配置文件中设定的“ngram_delim”来对原始的“.raw”数据进行划分,当然这里还会有一个自动对URI进行解码的过程。划分了之后,就得到了很多的tokens,把所有的报文序列中分割得到的tokens都作为一个特征,也作为初始矩阵的一维,所以才会有图中的“16777216”这么大的维数,很显然这是一个稀疏矩阵,选择用这种格式输出其实也可以看做是用最简单的方法来存储结果,因为真的用矩阵存会相当大,所以就只记录下来“value”为“1”的项;

- 然后,对于这些token一个一个的在报文序列中进行匹配,如果哪里有匹配的就会做一个记录,也就是下面的这种形式
417718110:NT:1,528173057:admin.php:1,542593949:5.1:1,709591711:Windows:1,1070264077:NeBkxkA0rw:1,1070607007:HTTP:1,1220141225:action:1,1369927740:de:1,1710609481:U:1,1720296684:GET:1,1920966484:9 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









