







一、文章主旨
在言语分类这项任务中提出了基于rnn和LSTM模型,通过对两个不同的语料库进行实验,比较这两个模型和其他模型。结果:当话语较短时,RNN工作的最好,话语较长时LSTM工作的最好。
二、找出文章的提出与引用
文章提出:①基于递归神经网络和长短期记忆单元的模型、②递归模型比标准前馈网络对未知单词的出现更加敏感
引用别人:以前基础n-gram的分类方法(标准LMs,NNLMs,boosting)
RNN:通过一系列隐藏单元对整个句子进行时间建模可以优于基于马尔科夫假设的模型,很像最初的神经网络语言模型,RNNLM通过函数PV(w)
三、摘要和说明
语言模型:
语言模型就是计算词序列(可以是短语、句子、段落)概率分布的一种模型,它的输入是文本句子,输出是该句子的概率,这个概率表明了这句话的合理程度,即这句话符合人类语言规则的程度。
即从数学上讲,语言模型是一个概率分布模型,目标是评估语言中任意一个字符串的生成概率p(S),其中S=(w1,w2,w3,…,wn),它可以表示一个短语、句子、段落或文档,wi取自词表集合W。利用条件概率及链式法则我们可以将p(S)表示为:
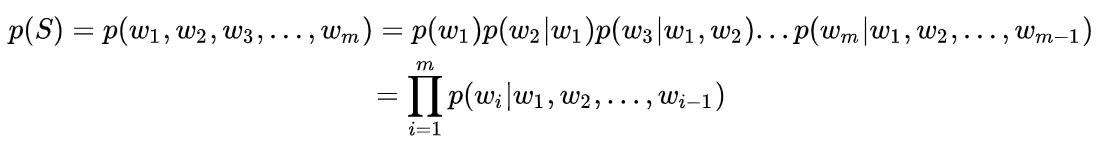
统计语言模型 n-gram语言模型(LMs) | (12条消息) 语言模型(一)—— 统计语言模型n-gram语言模型_知了爱啃代码的博客-CSDN博客_基于统计的语言模型 引入马尔可夫假设,这是一种独立性假设,在这里说的是某一个词语出现的概率只由其前面的n−1个词语所决定,这被称为n元语言模型 ,即n-gram,当n=2时,相应的语言模型就被称为是二元模型。 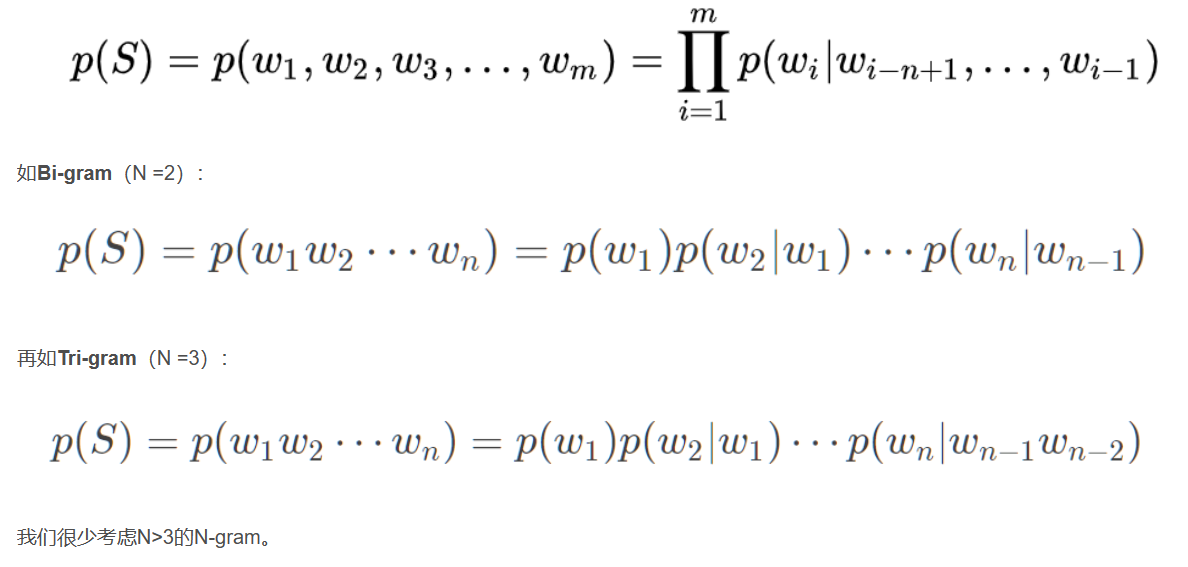
|
神经网络语言模型NNLM | (12条消息) 语言模型(二)—— 神经网络语言模型(NNLM)_知了爱啃代码的博客-CSDN博客_神经网络语言模型结构 |
循环神经网络语言模型RNNLM | (12条消息) 语言模型(三)—— 循环神经网络语言模型(RNNLM)与语言模型评价指标_知了爱啃代码的博客-CSDN博客_rnnlm |
boosting分类器 | Adaboost的基本分类器的损失函数为指数函数,推导过程就是围绕最小化损失函数展开的。主要目的是推导出样本权值的更新公式、基本分类器的权值计算公式。 |
传统感知机MLP | |
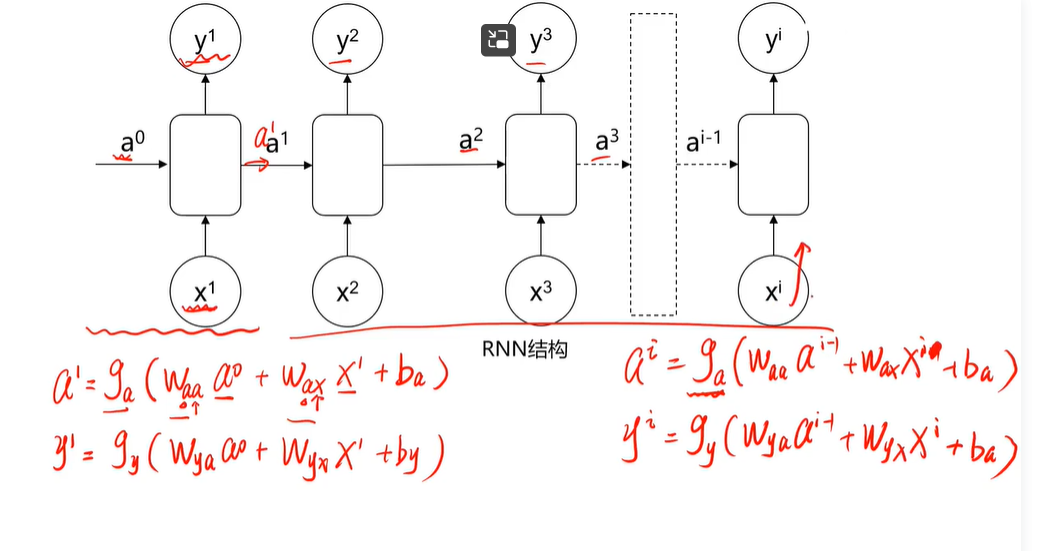
RNN | RNN的前向传播过程 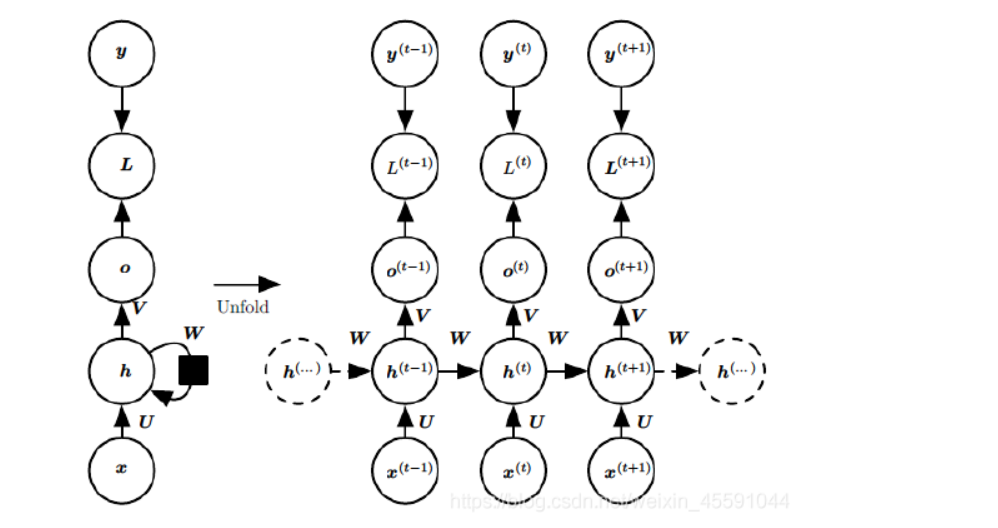
|
分布式单词表示 | |
简单的前馈神经网络FNN |
四、拟建系统中的说明
4.1基于循环神经网络的话语分类
循环神经网络语言模型RNNLM |
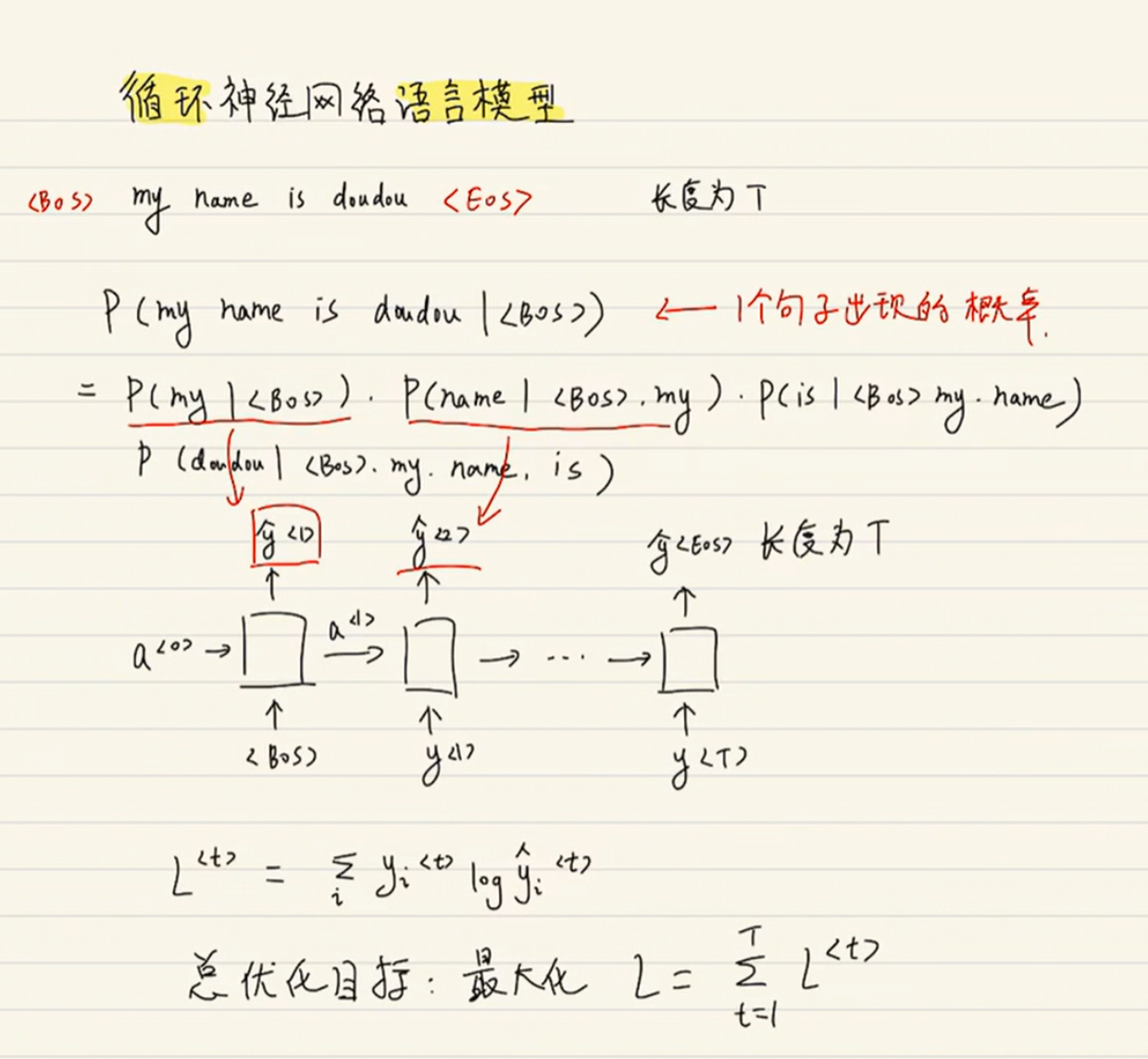
(12条消息) 语言模型(三)—— 循环神经网络语言模型(RNNLM)与语言模型评价指标_知了爱啃代码的博客-CSDN博客_rnnlm 隐藏状态Ht是当前嵌入、先前隐藏状态和偏差函数: t是输入,h是隐层单元,o是输出,L为损失函数,Y为训练集的标签,右上角的t表示在t时刻的状态。V、W、U是权值。激活函数:改变之前数据的线性关系, 如果网络中全部是线性变换,则多层网络可以通过矩阵变换,直接转换成一层神经网络。 第一个公式是前向传播(input,经过一层层的layer,不断计算每一层的z和a,最后得到输出y^ 的过程,计算出了y^,就可以根据它和真实值y的差别来计算损失(loss)。),一般选择tanH函数,b为偏置(增加函数的灵活性、提高神经元的拟合能力); 然后反向求梯度 第二个公式是输出; 第三个公式是模型的预测结果。 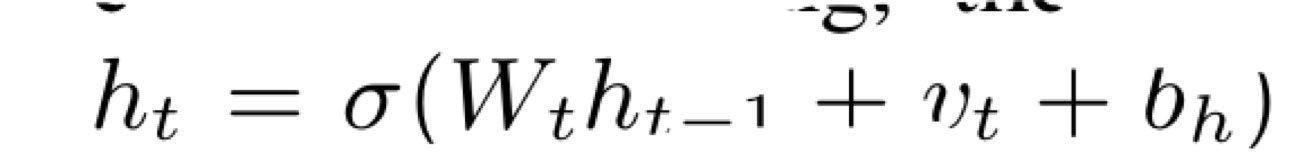
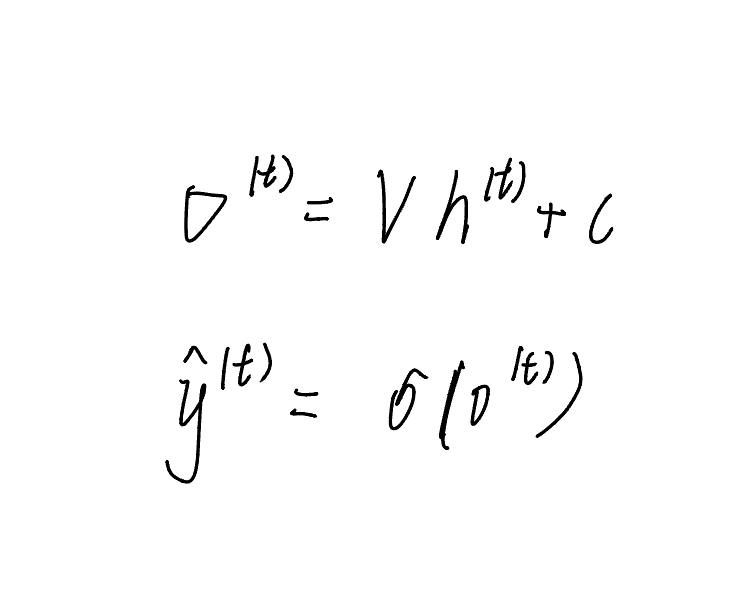
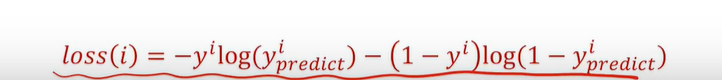
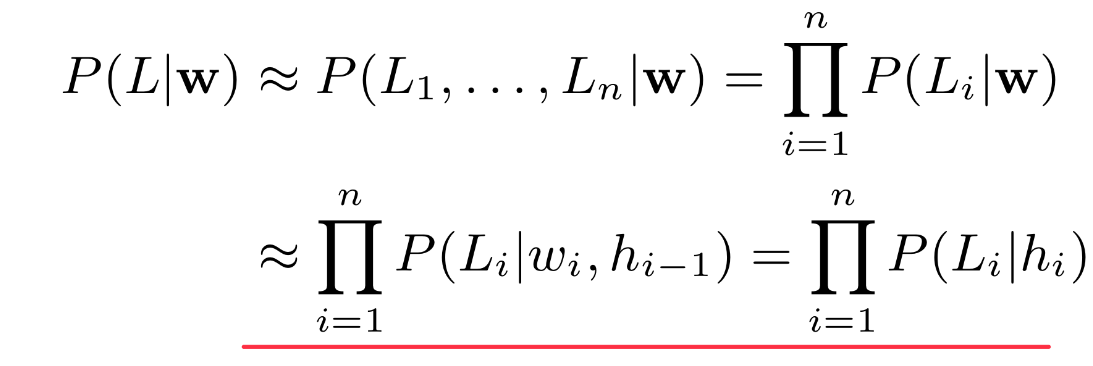
函数Pvw将一个一维|V|维向量w映射到一个密集的n维单词嵌入V,其中w的一个维度是1,其余维度是0,|V|是词汇的大小 |
4.2基于LSTM话语分类器
长短期记忆LSTM模型 | (12条消息) LSTM公式及理解_Geek_of_csdn的博客-CSDN博客_lstm公式 避免长期依赖,三个门,保护细胞状态,区分货物是否放入传送带 激活层:输出0-1之间的数值,0:完全保留1:直接丢弃 输入:决定那些层数放到传送带 更新状态: 确定输出:基于状态 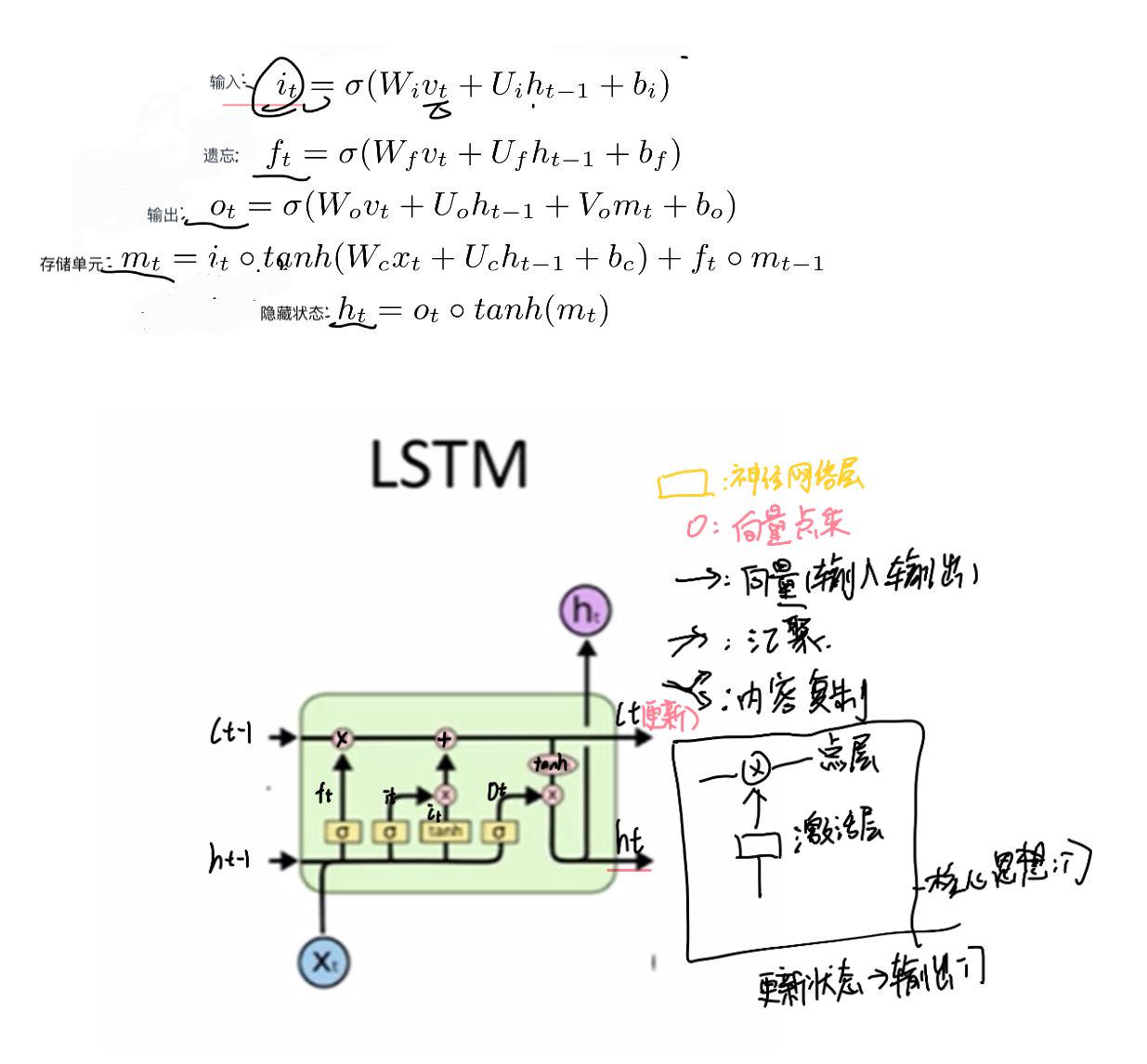
|
五、方法与结果
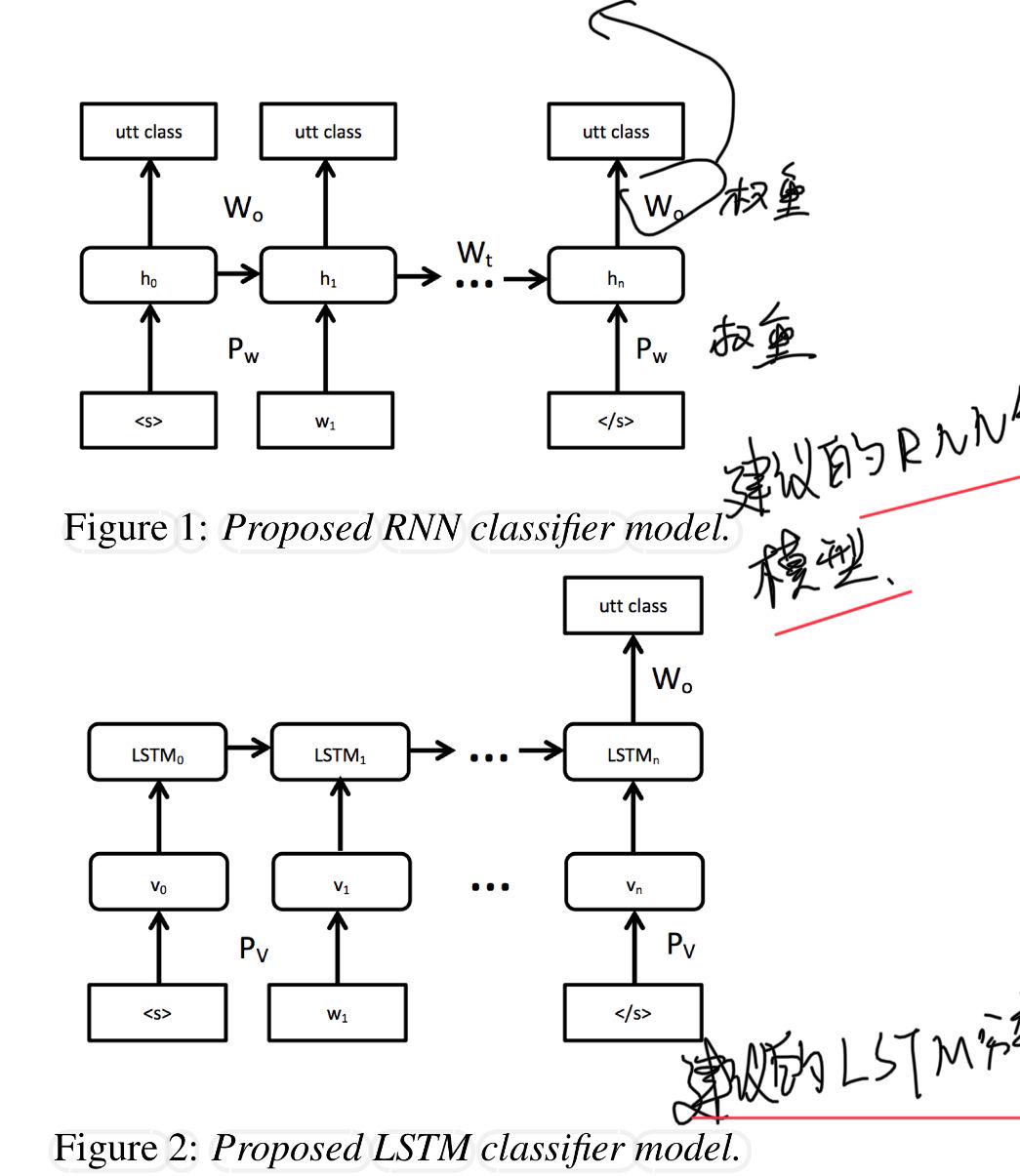
文章中给出的建议的RNN分类器和LSTM分类器模型
5.1.1意图分类任务的方法
语料库中有17种不同的意图,将其映射为二进制任务“飞行”“其他”,测试中使用了ASR输出
5.1.2会话浏览器收件人分类的方法
用的是CB语料库,两个用户使用口语输入与对话系统进行交互,训练和测试基于识别器输出,单词的错误率约为20%。
5.2结果
显示两种系统的结果,使用多个语料库和任务来评估模型:
对于ATIS语料库,RNN和LSTM模型都优于最大熵语言模型(ME)。LSTM优于增强模型。特别是,LSTM模型在单词设置时比增强的单词ngram系统好45.2%,当某些类(例如数字和命名实体)被自动标记时,LSTM更好40.1%。RNN模型在仅使用单词时不会击败增强的ngram基线系统,但在自动标记设置中可以。最后,在任何情况下,单词哈希都不会超过标准的单词嵌入基线。如表一所示

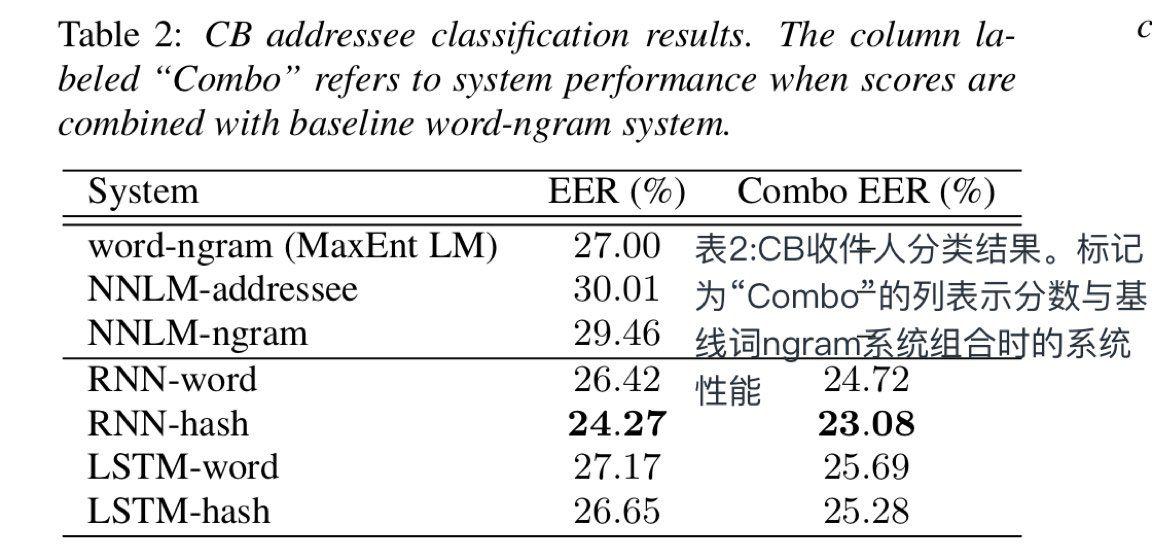
对于对话浏览器语料库,如表2所示。这里,LSTM模型比基线稍差。然而,RNN模型的绝对值比标准词的ngram基线高0.58%。此外,哈希为LSTM和RNN模型提供了实质性的增益。RNN单词哈希值比ngram基线的绝对值高1.73%,组合起来高3.92%。2所有模型都优于以前的前馈神经网络语言模型。
是什么原因导致LSTM在ATIS上的性能优于RNN和基线模型,而在CB上的性能较差,以及单词哈希在CB上优于单词嵌入,而在ATIS中的性能较差?
ATIS的平均话语长度远高于CB。CB数据的大多数话语长度小于5个单词,而ATIS的中值大于10个单词。数据集的差异也解释了单词哈希的不同性能。ATIS的单态词数量(映射到训练集中的未知单词)约为30%,而CB的数量为60%。
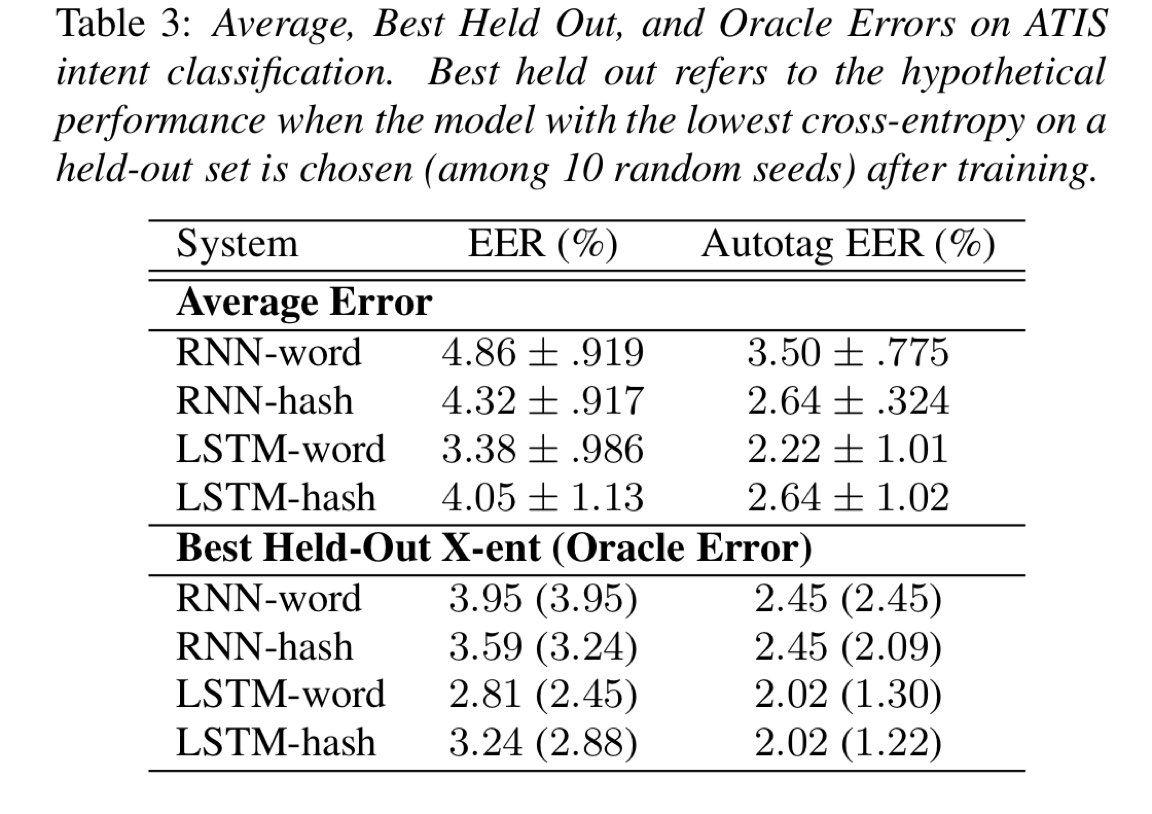
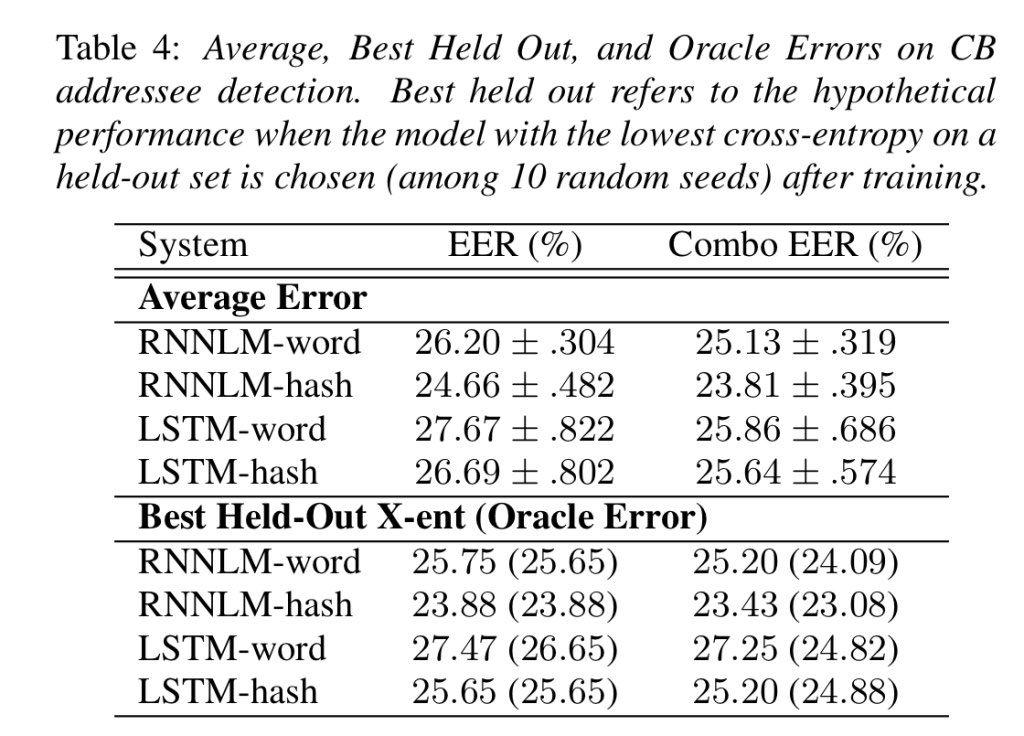
表3和表4显示了10种不同随机种子的平均性能和标准偏差。平均而言,结果优于基线,但平均结果通常比选择最佳初始交叉熵差一点。值得注意的反例是ATIS数据集上基于单词的RNN系统。此外,似乎LSTM通常具有比RNN更高的误差


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









