







最左前缀原则
最左前缀法则:查询从联合索引的最左索引列开始,不跳过联合索引中的任意索引列,才能保证联合索引能够完整生效。如果跳过某一列,那么从跳过的这一列开始,后面的字段索引将全部失效。
- 思考:现有user表存在四个字段:id、age、status、name。并user表仅存在 `age` 字段与 `status` 字段与 `name` 字段的联合索引: `idx_user_age_status_name `,那么以下哪个SQL语句用到了索引?
SELECT * FROM user WHERE age = 18;SELECT * FROM user WHERE age = 18 AND status = 0 AND name = '张三';SELECT * FROM user WHERE name = '张三' AND age = 2 AND status = 0;SELECT * FROM user WHERE name = '张三' AND status = 0;SELECT * FROM user WHERE age = 1 AND name = '张三';SELECT * FROM user WHERE age = 1 AND status > 0 AND name = '李四'
-
答案:1、2、3、5、6五条SQL语句都用到了索引,并且它们在执行时分别利用到的索引长度为a、b、c、d、e,存在关系:
a = d < e < b = c。 -
分析:
① 第1条SQL语句使用到了联合索引的部分索引:查询 `age` 字段时,由于 `age` 字段属于联合索引 `idx_user_age_status_name ` 的第一个索引列,没有跳过任何索引列,所以符合最左前缀原则。SQL在执行时利用到了联合索引中的 `age` 部分的索引;
② 第二条SQL语句使用到了联合索引的全部索引:通过 `age` 、 `name` 和 `stauts` 三个字段查询数据。按照最左前缀法则, `age` 、 `name` 和 `stauts` 三个数据段都是联合索引`idx_user_age_status_name ` 的索引段,所以在查询时可以利用到完整的联合索引进行搜索。完整的索引长度必定大于第一条SQL语句利用到的部分索引长度,所以存在a < b;
③ 第三条SQL语句使用到了联合索引的全部索引:它在执行时与第二条SQL语句相同,只是WHERE关键字筛选的字段先后顺序不一致。按照最左前缀法则,查询从索引的最左列开始(`age`),到后面的列(`name` 和 `status`),都没有跳过,所以与第二条SQL语句相同,第三条SQL语句也能利用到完整的联合索引。存在b = c;
④ 第四条SQL语句在执行时无法利用任何索引:,数据库通过 `name` 和 `status` 字段筛选数据。但由于联合索引 `idx_user_age_status_name ` 最左侧的索引列为 `age`,而 `age` 并不存在于SQL语句中,所以第四条SQL语句不符合最左前缀原则,无法利用到联合索引;
⑤ 第五条SQL语句使用到了联合索引的部分索引:因为 `age` 列是联合索引 `idx_user_age_status_name ` 最左侧的索引列,所以在第五条SQL中,可以利用到联合索引中的age索引部分。但由于SQL语句在执行时跳过了 `status` 索引列,所以从 `status` 索引列开始,到最后一个索引列 `name` 全部失效。所以第五条SQL语句利用到的索引长度与第一条SQL语句利用到的索引长度一致,都是联合索引中 `age ` 部分的索引;
⑥ 第六条SQL语句使用到了联合索引的部分索引:因为第六条SQL语句使用了范围查询 “>” ,这会导致使用了范围查询的索引列(`status`)后面的索引列(`name`)全部失效,所以在第六条SQL语句执行时,使用到的是联合索引中`age`和`status`部分的索引,该索引比第一条SQL与第五条SQL利用到的索引更长一些。 -
范围查询导致后续索引失效的规避方案:
如上文提到的第六条SQL,导致部分索引失效,可以通过将范围查询 “>” 改为 “>=” ,让索引避免生效。
即:在使用联合索引时,范围查询尽量使用 “>=” 和 “<=” 防止索引失效。
导致索引失效的情况
- 对索引列进行运算
不要在索引列上进行运算操作,否则索引将失效。 - 字符串不加引号
字符串类型的字段在使用时不加引号,Mysql查询时会进行隐式类型转换,导致索引失效。 - 头部模糊匹配
模糊匹配如果仅仅是尾部模糊匹配,索引不会失效,如果是头部模糊匹配,则索引失效。 - or 连接的条件存在无索引的列
如果用or分割的条件,一侧有索引,另一侧没有索引,那么涉及的索引都不会被用到。 - Mysql全表扫描效率大于索引扫描效率
在这种情况下,是根据Mysql的评估来决定是否使用索引。
示例:① 当需要查找的数据是全表数据时,Mysql评估全表扫描的效率更高,会放弃索引扫描。② 当查找的数据绝大部分为NOT NULL的时候对该字段查询IS NOT NULL,Mysql也会评估全表扫描的效率更高。
SQL提示
- 建议使用索引(USE INDEX)
作用:建议Mysql执行该条SQL语句时使用某个索引,通常用于手动优化sql。但是仅仅是对Mysql提出建议,具体执行时是否使用建议的索引还需要Mysql评估决定
SELECT * FROM table_name USE INDEX(index_name) WHERE ...
- 忽略索引(IGNORE INDEX)
作用:提示Mysql忽略掉某个索引,不使用它。
SELECT * FROM table_name IGNORE INDEX(index_name) WHERE ...
- 强制使用索引(FORCE INDEX)
作用:与建议使用索引不同,该方法是强制Mysql执行该条SQL语句时强制使用某个索引。
SELECT * FROM table_name FORCE INDEX(index_name) WHERE ...
覆盖索引
覆盖索引:查询中使用了索引,并且需要返回的列,在该索引中已经全部能够找到。
好处:使用覆盖索引避免Mysql查询时的回表操作,提高查询效率。
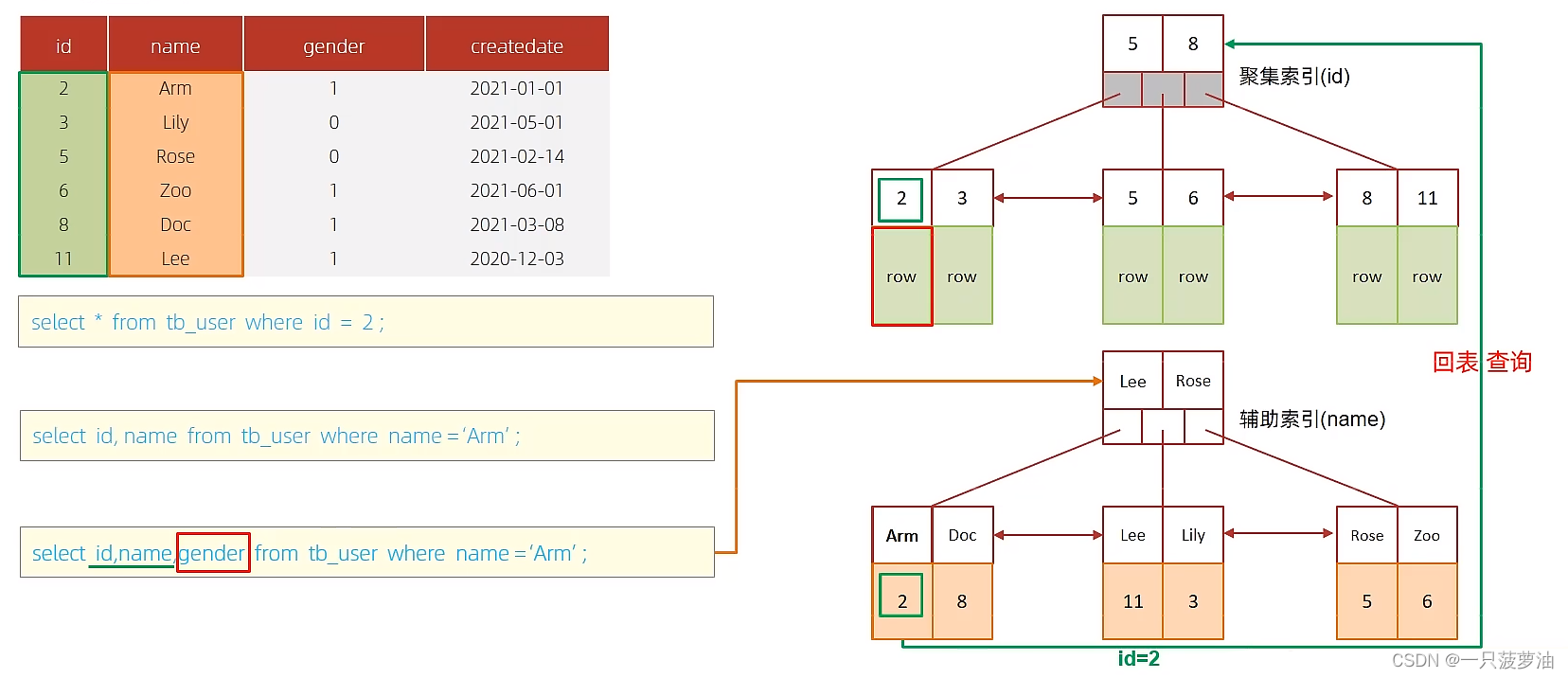
回表操作如下图所示:
查询数据时利用 `name` 字段的索引,可以一次性搜索到 `id` 与 `name` 字段的数据,但是由于 `gender` 字段的数据不在索引中,所以需要通过获取的主键id再次查找拿到到完整的行数据,才能获取 `gender` 字段的数据。这个过程就是回表。
回表查询相比于覆盖索引的查询多做了一次聚集索引查询,效率相对来说更低。
前缀索引
- 场景:
当字段类型为字符串(varchar,text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时浪费大量的磁盘IO,影响查询效率。 - 解决方案:
引入“前缀索引”,只将字符串的一部分前缀建立索引,可以大大节约索引空间,从而提高索引效率。 - 语法
# n 为前缀索引的长度
CREATE INDEX index_name on table_name (column(n));
-
如何确定前缀索引的长度?
可以根据索引的选择性来决定。选择性是指不重复的索引值(基数)和数据表记录的总数的比值。
索引选择性越高,则查询效率越高,唯一索引的选择性是1,是最好的索引选择性,性能也是最好的。 -
获取索引选择性示例:
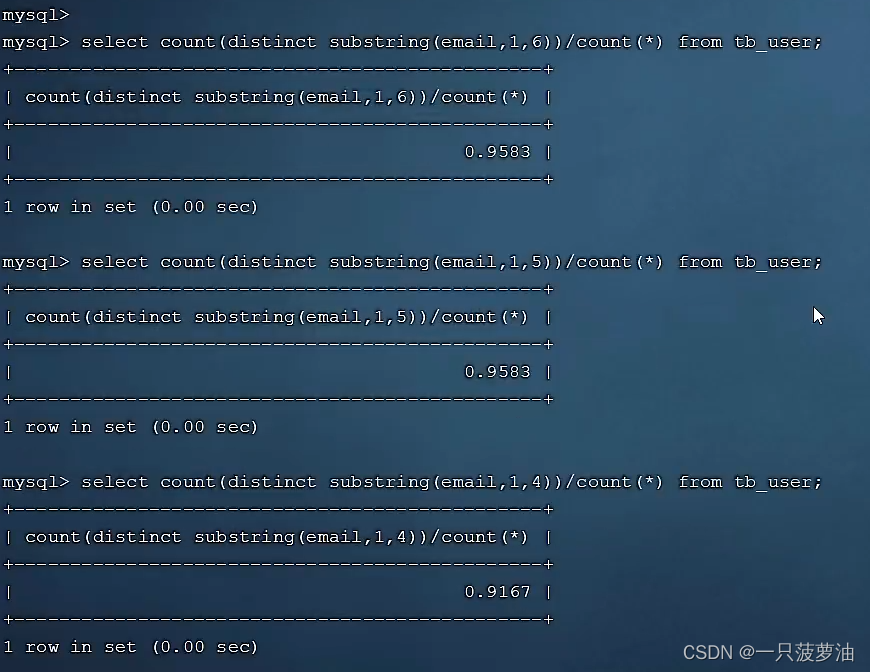
# 可以通过COUNT(DISTINCT ....) 与 总条数的比值来查看email内容的区分度
SELECT COUNT(DISTINCT email) / COUNT(*) FROM user
# 截取email字段的第一个字符开始,前5个字符,获取前五个字符的选择性
SELECT COUNT(DISTINCT SUBSTRING(email,1,5)) / COUNT(*) FROM user
如下图,当索引长度为5的时候数据有了较好的选择性,所以可以选择前缀索引的长度为5
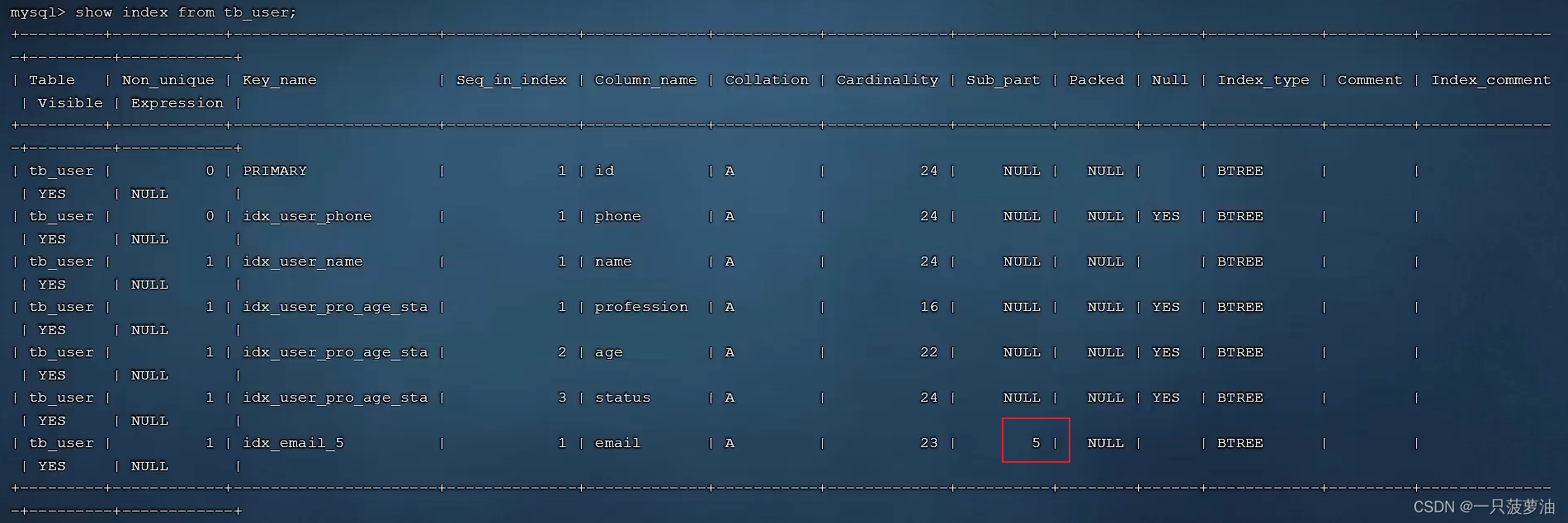
建立好索引后,可以使用 SHOW INDEX FROM table_name查看索引,前缀索引在 Sub_part 列会有值,值即为设置的前缀索引长度
索引的设计原则
- 针对数据量较大(单表百万数据以上都是较大数据量),且查询比较频繁的表建立索引;
- 针对常作为查询条件(WHERE)、排序(ORDER BY)、分组(GROUP BY)操作的字段建立索引;
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高;
- 如果是字符串类型的字段,字段的长度较长,可针对字段的特点建立前缀索引;
- 尽量使用联合索引,减少单列索引。查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率;
- 要控制索引的数量,索引不是多多益善,索引越多,维护索引结构的代价就越大,会影响增删改查的效率;
- 如果索引不存储NULL值,创表的时候使用NOT NULL约束它。当优化器知道列是否包含NULL时,可以更好地确定哪个索引更利于查询。
















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









