







 机器学习中,样本量不足可能导致学习到的规则错误。通过Hoeffding不等式可以估计样本量,通常样本数量约等于10倍的VC维。深度学习的VC维高,表示其表达能力强,但也需要大量样本防止过拟合。现代深度学习通过模型结构优化和正则化降低了VC维,同时增加训练数据量和使用数据增强等方法提升泛化能力。
机器学习中,样本量不足可能导致学习到的规则错误。通过Hoeffding不等式可以估计样本量,通常样本数量约等于10倍的VC维。深度学习的VC维高,表示其表达能力强,但也需要大量样本防止过拟合。现代深度学习通过模型结构优化和正则化降低了VC维,同时增加训练数据量和使用数据增强等方法提升泛化能力。
在机器学习中,如果样本量不足,我们利用模型学习到的结果就有可能是错误的,因为样本不足的情况下,规则会有很多。也就是我们如果用f表示真是的规则,用g表示利用模型学习到的规则。那么我们希望g和f越接近越好,可是我们并不知道f到底是什么?如果样本不足,机器是没法学习的。
例如:
给你123,输出为246。有人会说那就是对应元素乘以2,这是一种规则。还有别的规则,第一个数字是原来数的第二位,后面两位分别是原来数字后两位乘以2.还有很多别的规则,规则不唯一,学习就会失效,我们可以利用hoeffding inequality不等式来估计一下学习到的g和f很接近的概率有多大。
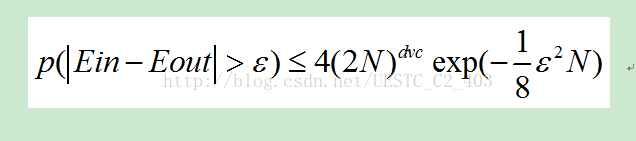
Ein就是采用g假设时候误差,Eout就是采用f时候的误差。从这个不等式可以知道,样本越大,得到g和f接近的概率就越大,样本越小,就越小。可以用这个公式大概计算一下样本的数量。dvc也是一个重要的参数,也不能太大,如果太大,样本就需要更多。
一般情况下,样本数量大约等于10dvc就可以了,但是上面的公式计算的结果就会大很多。
dvc就是表示VC dimension。感知机算法的dvc等于d+1,d就是数据的维度。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









