







R语言:时间序列分析完整过程
包括:时序图趋势信息查看、平稳性检验、对非平稳序列进行差分、纯随机性检验、模型定阶、模型建立、模型显著性检验、模型优化、模型预测。
库与数据导入
library(readxl)
library(aTSA)
library(zoo)
library(forecast)
library(tseries)
data <- read.csv("tielu.csv")
数据为我国铁路年运输量数据,部分信息如下:
year trans
1 1949 5589
2 1950 9983
3 1951 11083
4 1952 13217
5 1953 16131
6 1954 19288
7 1955 19376
8 1956 24605
9 1957 27421
10 1958 38109
数据集构建
因后期预测需要,这里使用部分数据作为训练集,剩余部分作为测试集判断预测效果
#------------------构建数据集--------------------------------
#构建全集
full <- ts(data$trans,start = 1949,end = 2008)
#构建训练集
xunlian <-window(full,start=1949,end =1998 )
#构建测试集
ceshi <- window(full,start = 1999,end = 2008)
时序图趋势信息查看
做时间序列的分析一般要保证序列属于平稳的非白噪声序列这里可以先使用时序图判断序列的平稳性
#绘制时序图
plot(xunlian,type = 'o',col = 'blue')
#时序图清晰的显示,1阶差分运算成功的从原序列中提取出线性趋势,差分后序列呈现出非常平稳的波动特征
#1阶差分后若仍呈现长期递增或递减趋势则再次进行2阶差分。
dif2 <- diff(xunlian,1,2)
plot(dif2,type = 'o',col = 'red')
时序图如下:
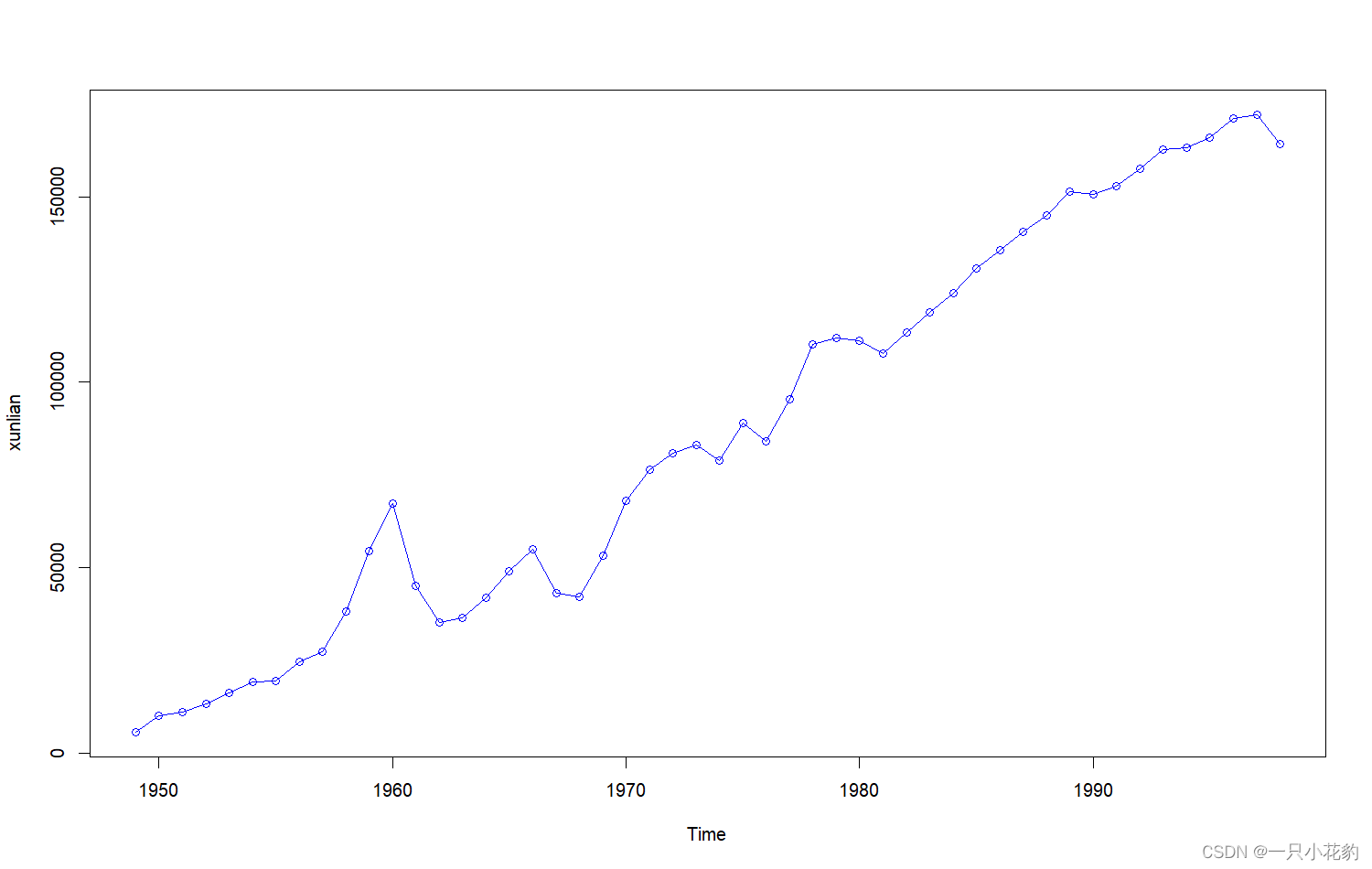
可以看出序列具有显著的线性递增趋势,而我们需要数据呈现波动,可以通过差分提取线性趋势信息实现趋势平稳
首先进行1阶差分并绘制时序图
dif1 <- diff(xunlian,1,1) #1阶差分
plot(dif1,type = 'o',col = 'red') #绘制时序图
1阶差分后时序图如下:
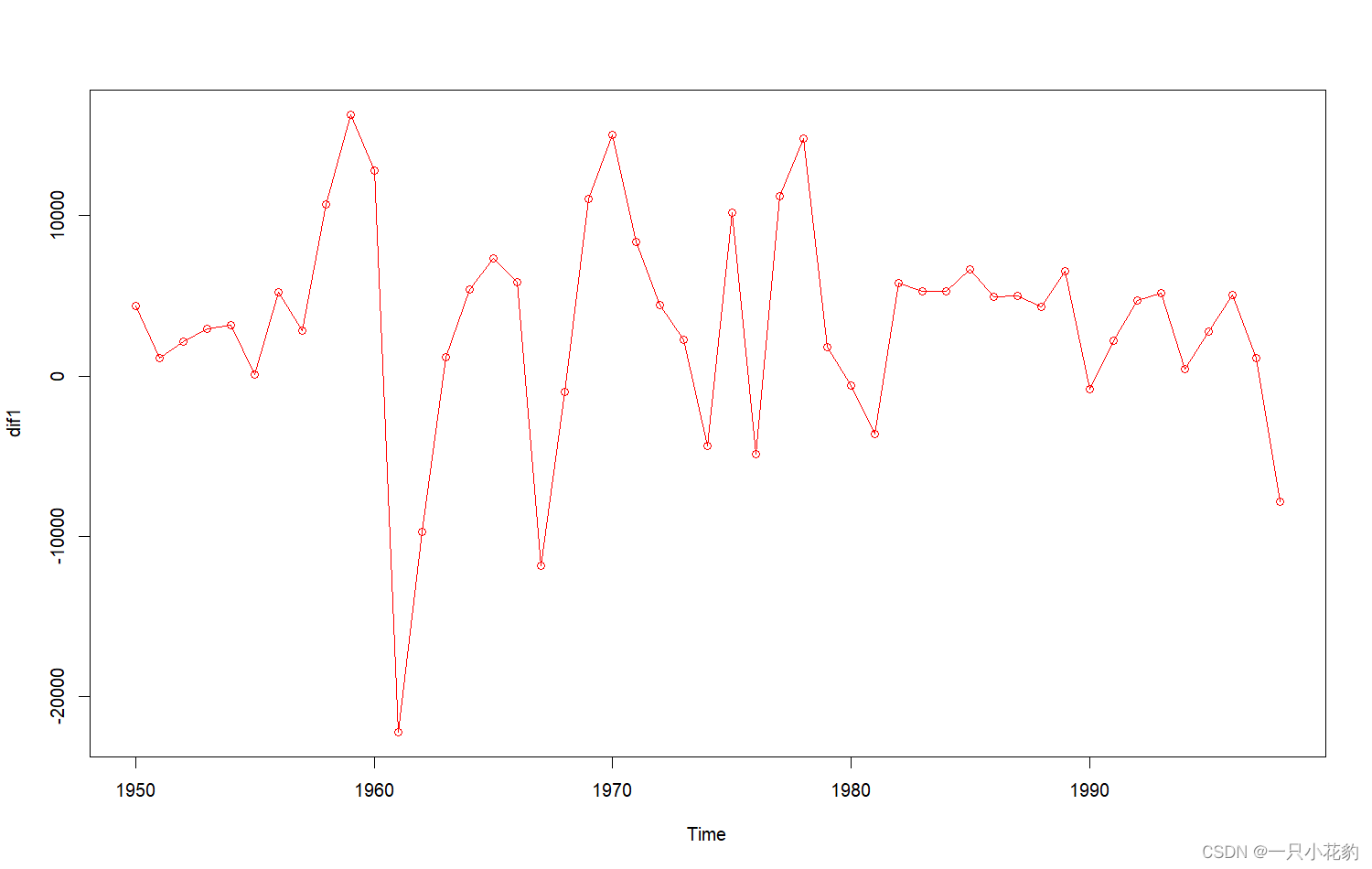
可以看出时序图呈现出了波动,不过是否平稳主观来看可能会产生差错下面通过ADF检验用数值反应平稳性。
如果此时数据仍呈现递增趋势可已通过再次差分的方法实现趋势平稳。
dif2 <- diff(xunlian,1,1,2) #1阶差分
plot(dif2,type = 'o',col = 'red') #绘制时序图
平稳性检验
平稳性检验除了上述时序图判断外还可以使用ADF检验
adf.test(dif1)#p值小于0.05序列平稳
结果如下
Augmented Dickey-Fuller Test
data: dif1
Dickey-Fuller = -4.6849, Lag order = 3, p-value = 0.01
alternative hypothesis: stationary
Warning message:
In adf.test(dif1) : p-value smaller than printed p-value
可以看出p值显示为0.01小于0.05,可以认为序列平稳,
下方的警告信息仅显示p值小于显示数据,不是程序报错不用太过担心。
当然如果数据不差分就呈现出平稳性,只需将adf.test(x)中的x该为差分前的数据就可以了如下:
adf.test(xunlian)#p值小于0.05序列平稳
纯随机性检验
在进行数据的平稳性检验之后,还需对数据进行纯随机性检验,以确保数据为平稳的非白噪声序列,纯随机性检验也是使用p值判断数据的纯随机性,原假设为数据为白噪声序列,备择假设为数据为非白噪声序列,实现方法为R中的Box.test()函数:
Box.test(dif1,lag = 6,type = 'Ljung-Box')
结果如下:
Box-Ljung test
data: dif1
X-squared = 18.934, df = 6, p-value = 0.004277
由上述结果可以看出p值小于0.05,则拒绝原假设认为数据为非白噪声序列。
至此该序列为平稳的非白噪声序列,可进行后续的建模与预测。
模型定阶
时间序列模型分为:AR、MA(q)、ARMA(p,q),ARIMA(p,d,q)等,其中p为自相关系数的阶数,q为移动平均系数的阶数,若p为0则ARMA(p,q)模型退化为MA(q)模型,若q为0则ARMA(p,q)模型退化AR模型,所以只要确定了模型阶数,就可以确定建立哪一种预测模型,具体的实现方法为R中的 auto.arima()函数:
auto.arima(xunlian,ic = 'bic')#自动定阶使用bic准则,bic越小越优
结果如下:
Series: xunlian
ARIMA(0,1,0) with drift
Coefficients:
drift
3239.1837
s.e. 979.1344
sigma^2 = 47954995: log likelihood = -502.32
AIC=1008.65 AICc=1008.91 BIC=1012.43
其中:
ARIMA(0,1,0) 为选出的相对最优模型
with drift 为带漂移项
AIC AICc BIC为检验准则,数值越小越优
auto.arima()函数可以自动对序列进行模型定阶,并选出相对最优模型,从上述结果可以看出该模型的相对最优模型为带漂移项的ARIMA(p,d,q)模型,差分为1,p与q均为零,即ARIMA(0,1,0)模型,该模型又称为随机游走模型或醉汉模型。
模型建立
定阶完成后即可建立模型,由于前文对数据进行了差分所以我们需要拟合差分平稳序列,实现方法为R中的Arima()函数,该函数的order()中包括三个参数(p,d,q)其中d为阶数前文以定阶为1,include.drift为漂移项,加上后可以是预测结果更贴合实际,为了直观展现二者差异下面建立两个模型进行后续对比,这所以最终的建模如下:
fit1 <- Arima(xunlian,order=c(0,1,0),include.drift = F)#不考虑漂移项
fit2 <- Arima(xunlian,order = c(0,1,0),include.drift = T)#考虑漂移项的模型
建模结果
> fit1
Series: xunlian
ARIMA(0,1,0)
sigma^2 = 57468633: log likelihood = -507.26
AIC=1016.53 AICc=1016.61 BIC=1018.42
> fit2
Series: xunlian
ARIMA(0,1,0) with drift
Coefficients:
drift
3239.1837
s.e. 979.1344
sigma^2 = 47954995: log likelihood = -502.32
AIC=1008.65 AICc=1008.91 BIC=1012.43
>
可以看出带漂移项的模型要优一些
模型显著性检验
模型的显著性检验主要是为了检验模型的有效性,一个模型是否显著有效主要看它提取的信息是否充分,实现方法为R中的tsdiag()函数(注:如果建模函数为arima()则使用ts.diag()函数进行检验):
tsdiag(fit2)
结果如下:
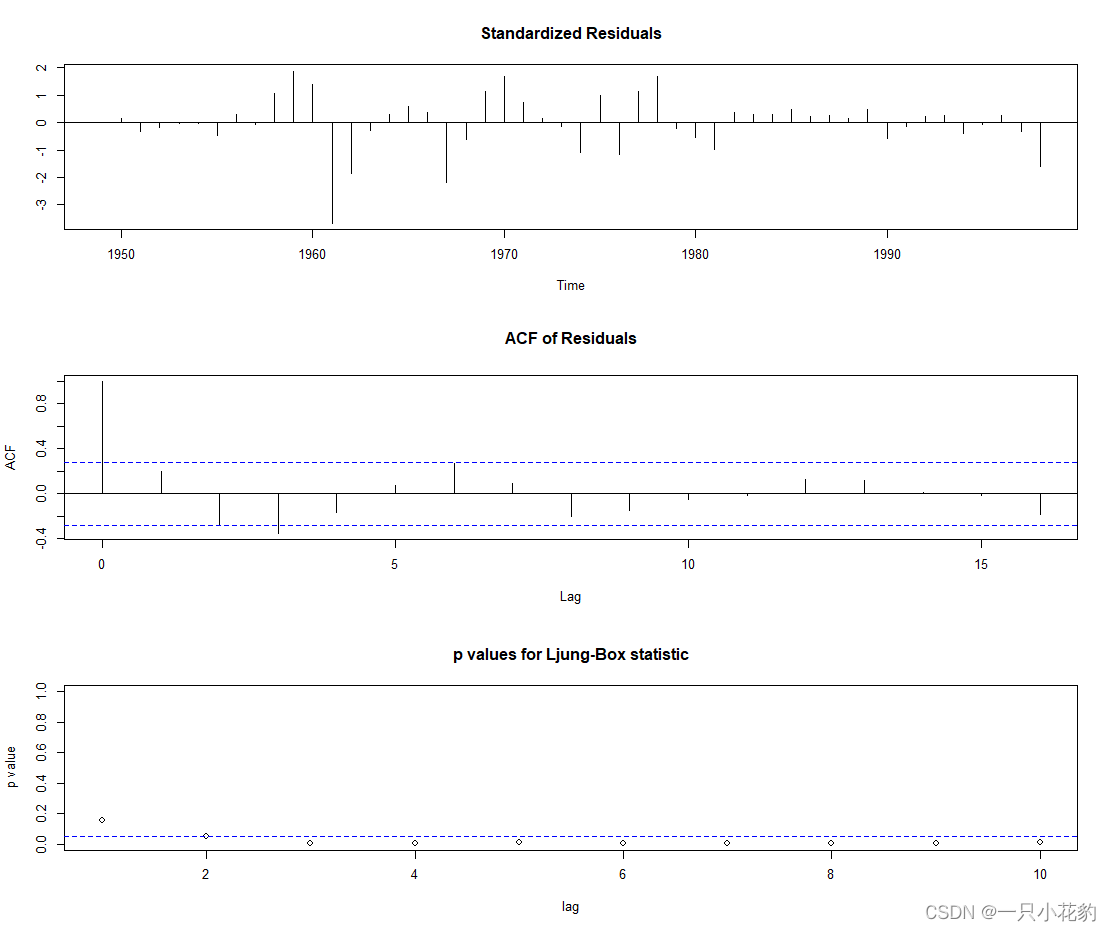
由上图结果中的白噪声检验结果图(第三个)可看出各阶延迟下白噪声检验统计量的P值都显著小于0.05,所以可以认为这个拟合模型的残差序列不属于白噪声序列,即该拟合模型不显著,这是因为auto.arima()函数虽然可以进行自动定阶,但其没有考虑系数不显著需要剔除的问题,所以其提供的模型可以供参考使用,但不是最优,下面本文将结合自相关图,偏自相关图,显著性检验等多方面信息再次定阶拟合模型
模型优化
通过自相关与偏自相关图能判断序列的截尾与拖尾等特征从而判断模型阶数,其标准为
自相关系数k阶截尾—>MA(k)模型 order=c(0,0,k)
偏自相关系数k阶截尾---->AR(k)模型 order=c(k,0,0)
实现方法为R中的acf()与pacf()函数:
acf(dif1,lag.max = 30) #自相关图
pacf(dif1,lag.max = 30) #偏自相关图
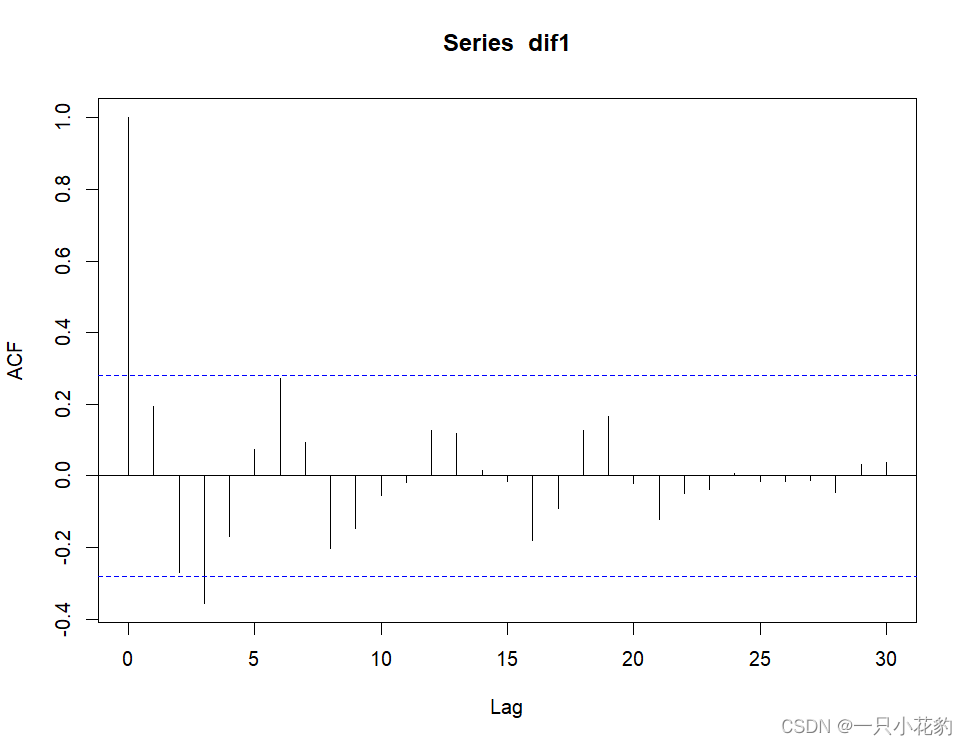
由上面的自相关图可以看出数据呈现1阶截尾(断崖式的降入两倍标准差以内)可以考虑MA(1)模型,即q为1
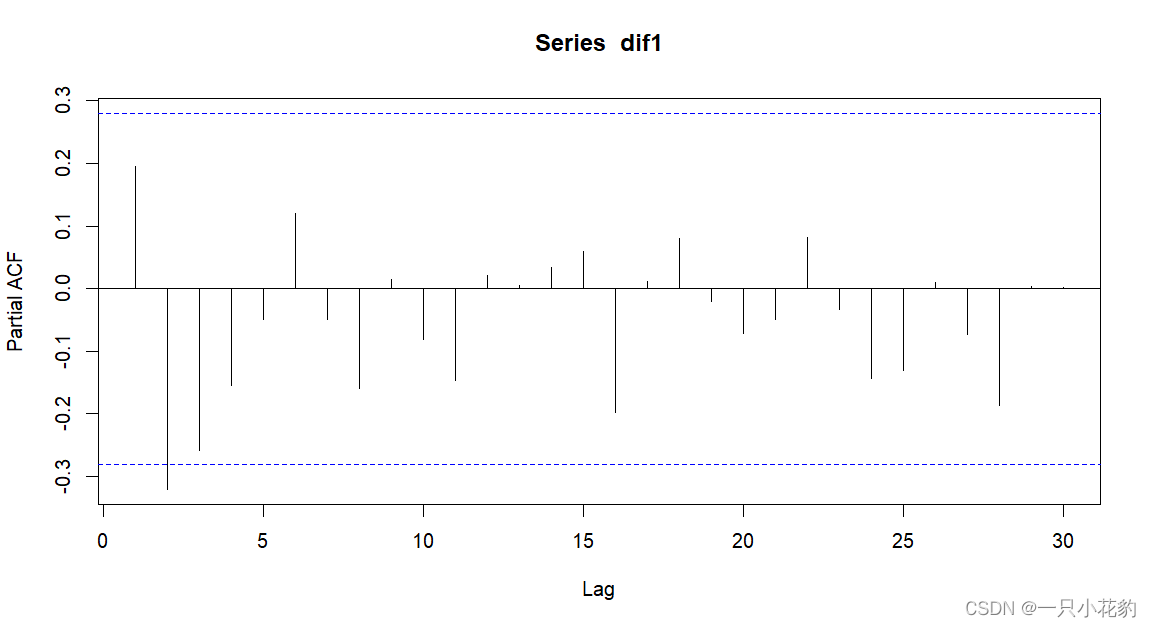
由上面的偏自相关图可以看出数据呈现拖尾(缓步降入两倍标准差以内)。
经过上述判断现定阶为ARIMA(0,1,1)模型。
下面建立模型fit3
fit3 <- Arima(xunlian,order = c(0,1,1),include.drift = T)
结果如下:
Series: xunlian
ARIMA(0,1,1) with drift
Coefficients:
ma1 drift
0.3097 3186.485
s.e. 0.1421 1230.725
sigma^2 = 45533719: log likelihood = -500.59
AIC=1007.18 AICc=1007.71 BIC=1012.85
可以看出这里的BIC值略大于fit2,但由于fit2不显著所以我们不予考虑,下面对fit3进行显著性检验
tsdiag(fit3)
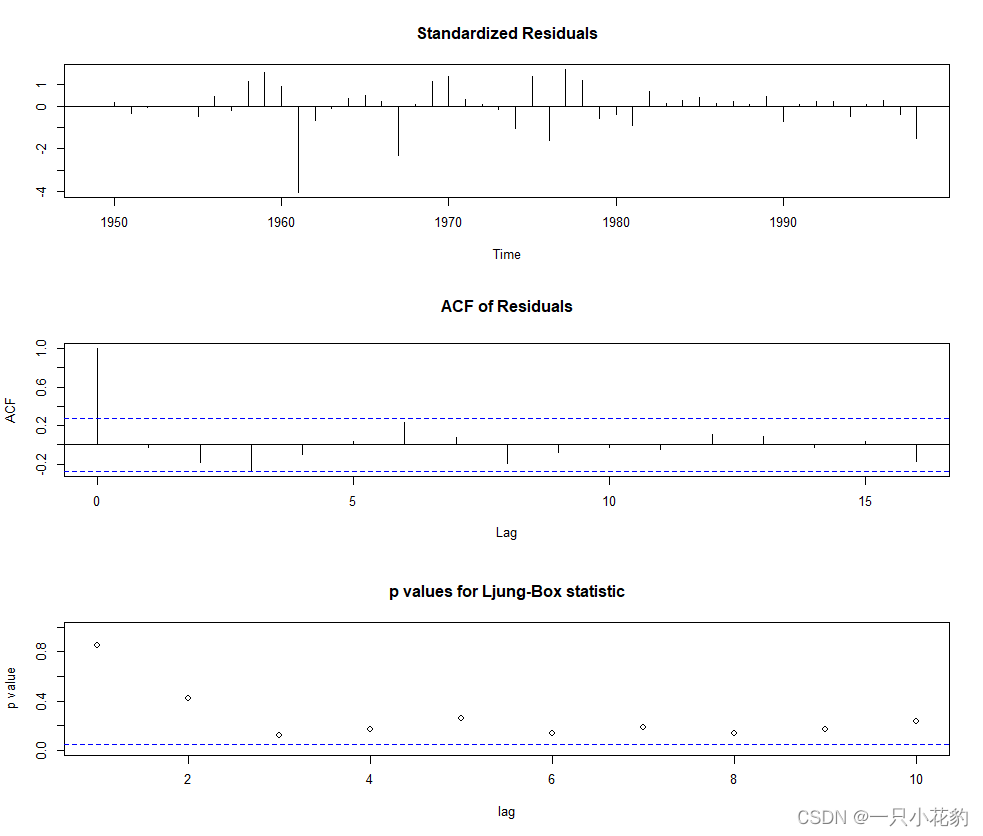
由白噪声检验结果图可看出,优化后的模型各阶延迟下白噪声检验统计量P值都显著大于0.05,所以可以认为优化后的模型显著成立,所以下面我们以fit3进行预测。
模型预测
实现方法为R中的forecast()函数(forecast包):
fore3<-forecast::forecast(fit3,h=10)
结果如下:
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
1999 164328.1 155680.4 172975.9 151102.5 177553.7
2000 167514.6 153264.7 181764.5 145721.3 189307.9
2001 170701.1 152498.5 188903.7 142862.6 198539.5
2002 173887.6 152449.1 195326.1 141100.2 206674.9
2003 177074.1 152827.7 201320.4 139992.5 214155.6
2004 180260.6 153499.4 207021.7 139332.9 221188.2
2005 183447.0 154387.9 212506.2 139004.9 227889.2
2006 186633.5 155445.2 217821.8 138935.1 234331.9
2007 189820.0 156638.9 223001.1 139073.9 240566.1
2008 193006.5 157945.7 228067.3 139385.6 246627.4
在此展示下无漂移项的预测结果
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
1999 164309 154593.8 174024.2 149450.9 179167.1
2000 164309 150569.6 178048.4 143296.5 185321.5
2001 164309 147481.8 181136.2 138574.0 190044.0
2002 164309 144878.6 183739.4 134592.8 194025.2
2003 164309 142585.2 186032.8 131085.3 197532.7
2004 164309 140511.7 188106.3 127914.2 200703.8
2005 164309 138605.0 190013.0 124998.1 203619.9
2006 164309 136830.3 191787.7 122283.9 206334.1
2007 164309 135163.4 193454.6 119734.7 208883.3
2008 164309 133586.9 195031.1 117323.5 211294.5
可以看出预测结果为常数可能预测精度较高不过无法反映波动特征与现实不相符。
下面展示fit3预测结果与实际的差异
fore3<-forecast::forecast(fit3,h=10)#有漂移项的预测p158
fore3
error3<-ceshi-fore3$mean
error3
file3<-data.frame(fore3$mean,ceshi,error3)
names(file3) <- c('预测结果','真实数据','数据差异')
file3
plot(fore3)
lines(fore3$fitted,col=2,lty=2)
结果如下:
预测结果 真实数据 数据差异
1 164328.1 167554 3225.873
2 167514.6 178581 11066.388
3 170701.1 193189 22487.903
4 173887.6 204956 31068.418
5 177074.1 224248 47173.933
6 180260.6 249017 68756.448
7 183447.0 269296 85848.963
8 186633.5 288224 101590.478
9 189820.0 314237 124416.994
10 193006.5 330354 137347.509
最后绘制模型拟合与预测效果图
plot(fore3)
lines(fore3$fitted,col=2,lty=2)
结果如下:
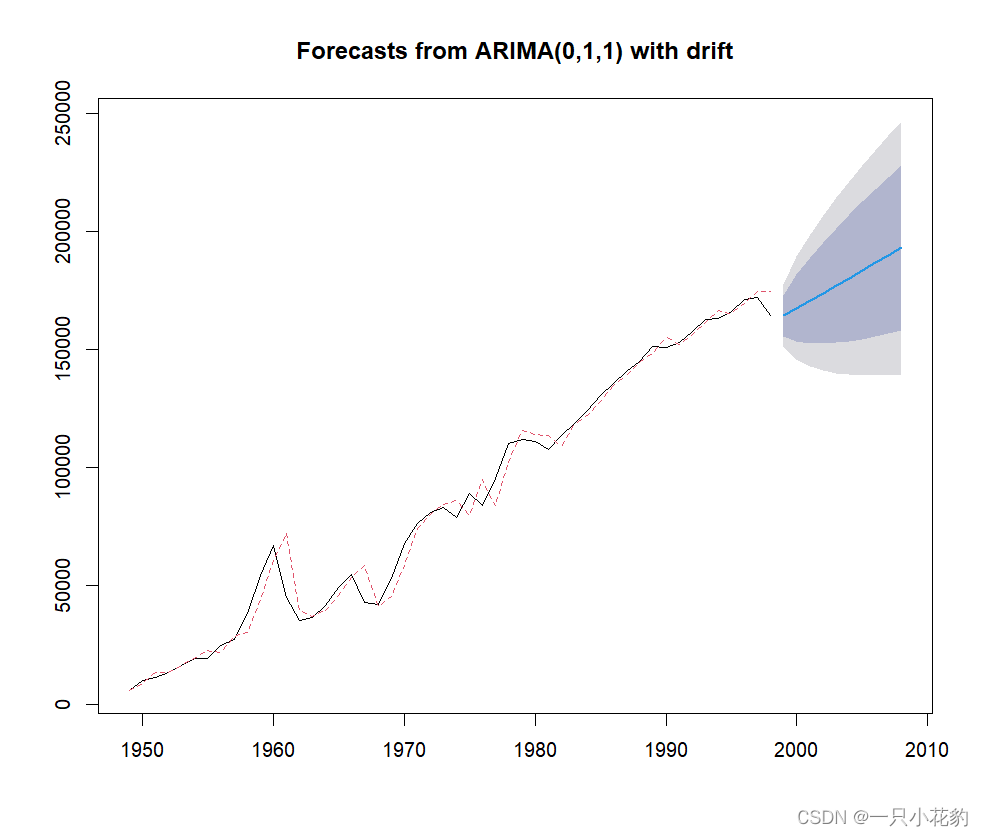
图中红线为观察值实线为拟合值,深色阴影部分为置信区间为80%的预测置信区间,浅色阴影部分为置信水平为95%的预测置信区间。
至此一个完整的时间序列分析就完成了!














 4846
4846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









