






一、Presto
1、简介
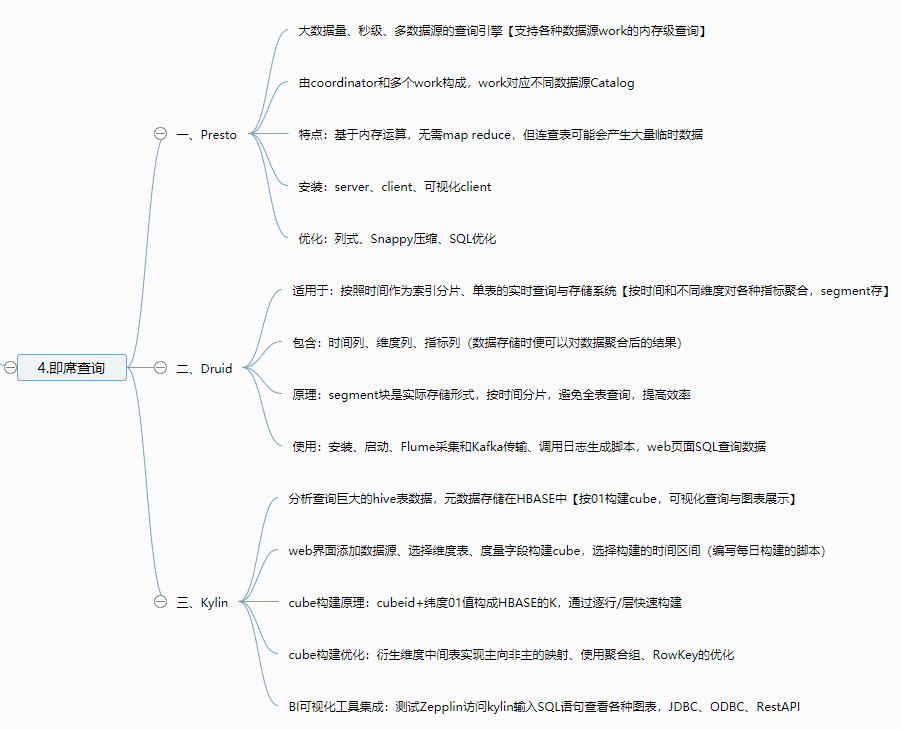
概念:大数据量、秒级、分布式SQL查询engine【解析SQL但不是数据库】
架构
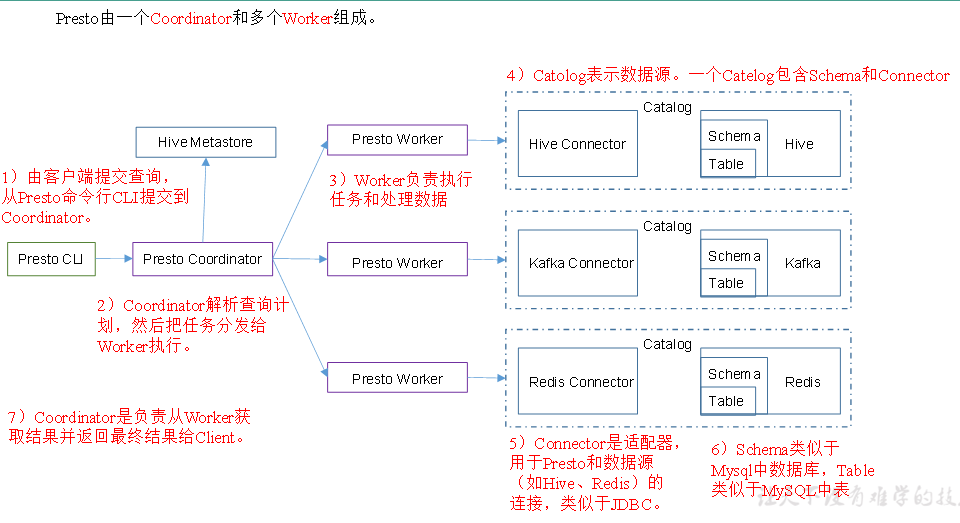
不同worker对应不同的数据源(各数据源有对应的connector连接适配器)
优缺点
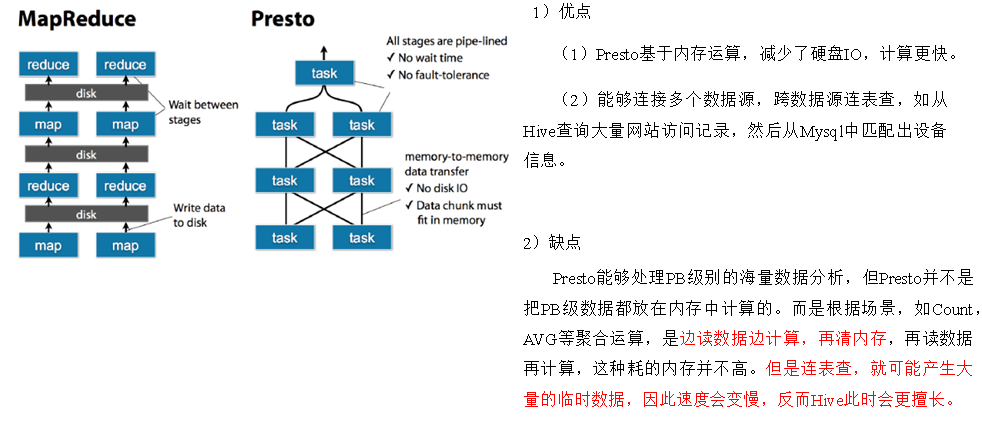
缺点:读数据连查表会产生大量临时数据
与impala比较
Impala性能稍领先于Presto,但是Presto在数据源支持上非常丰富,如redis
2、安装
server安装
配置一个Hive的catalog
在hadoop102上配置成coordinator,在hadoop103、hadoop104上配置为worker
client安装:[atguigu@hadoop102 presto]$ ./prestocli --server hadoop102:8881 --catalog hive --schema default
可视化client安装:
[atguigu@hadoop102 yanagishima-18.0]$
nohup bin/yanagishima-start.sh >y.log 2>&1 &
3、Presto优化之数据存储
合理设置分区
使用列式存储:相对于Parquet,Presto对ORC支持更好
使用压缩:采用Snappy压缩
4、Presto优化之查询SQL
选择使用的字段
过滤条件加分区字段:where语句中优先使用分区字段进行过滤
Group By优化:合理安排Group by语句中字段顺序,按照每个字段distinct数据多少进行降序排列
Order By时使用Limit:查询Top N或者Bottom N
使用Join语句时将大表放在左边:join左边的表分割到多个worker,然后将join右边的表数据整个复制一份
5、其他注意事项
字段名反引用:MySQL对字段加反引号`、Presto对字段加双引号分割,以避免和关键字冲突
时间函数:SELECT t FROM a WHERE t > timestamp '2017-01-01 00:00:00';
不支持INSERT OVERWRITE语法:先delete,然后insert into
PARQUET格式:支持Parquet格式,支持查询,但不支持insert
二、Druid
1、简介
概念:快速、列式、分布式、支持实时分析的数据存储系统,性能比OLAP高(PB数据、毫秒查询、实时处理)
与阿里的Druid连接池无关
特点

应用场景(单表、不更新),按照时间分片

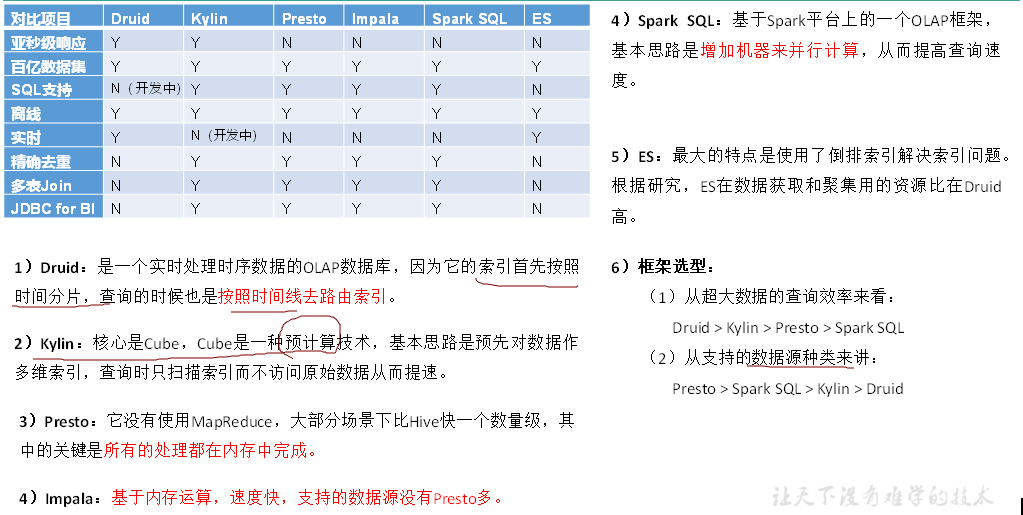
2、框架原理
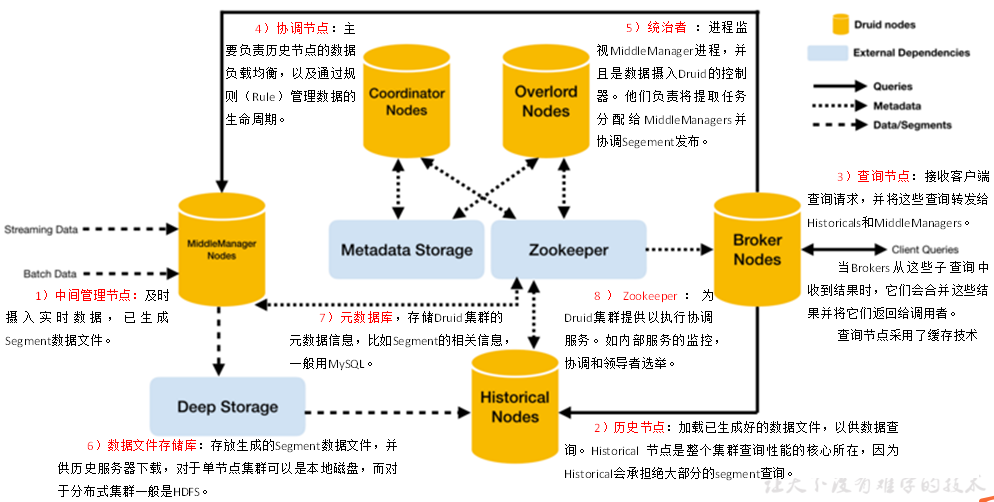
3、数据结构

4、Druid安装(单机版)
改配置(不用内置zk)
启动:[atguigu@hadoop102 imply]$ bin/supervise -c conf/supervise/quickstart.conf
启动采集Flume和Kafka
web页面
启动日志生成程序,登录页面加载数据,创建数据库表配置及时间字段
使用SQL查询
三、Kylin
1、Kylin简介
定义
分布式分析引擎,快速查询巨大的Hive表
架构
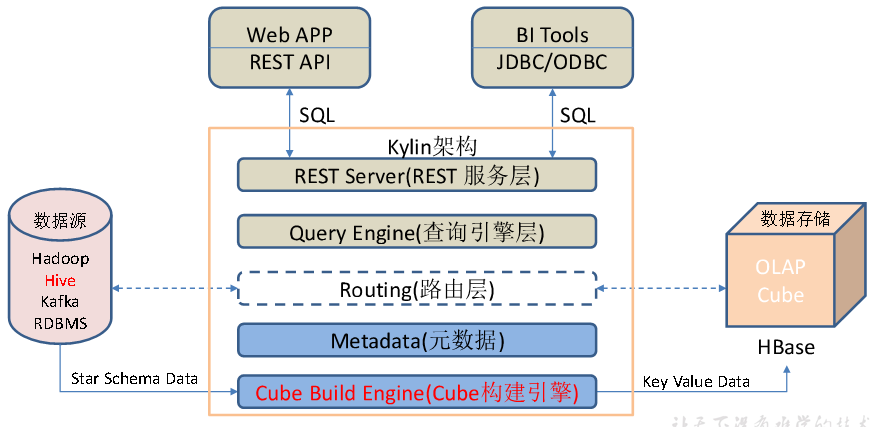
Kylin的元数据存储在hbase中
任务引擎对Kylin当中的全部任务加以管理与协调
特点:支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等
2、安装
依赖环境:先部署好Hadoop、Hive、Zookeeper、HBase
启动:bin/kylin.sh start
http://hadoop102:7070/kylin查看Web页面
3、使用:使用Kylin进行OLAP分析
建工程
添加数据源(导入hive表)
创建model
选择维度表,并指定事实表和维度表的关联条件
构建cube,添加维度或者度量字段
选择要构建的时间区间
实现每日自动构建cube-编写脚本
4、cube构建原理
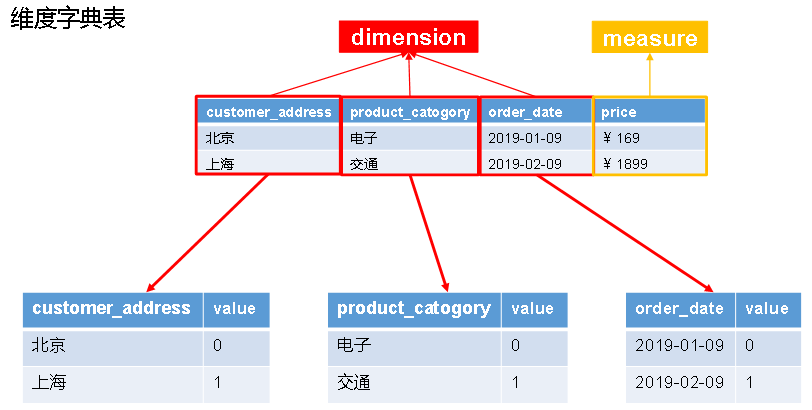
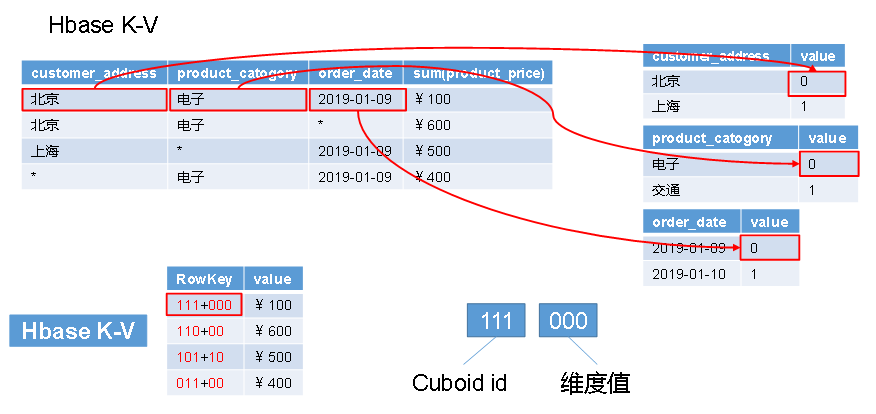
构建算法:逐层构建、快速构建
5、cube构建优化
使用衍生维度-中间表实现主到非主的映射
使用聚合组:强制维度、层级维度、联合维度
Row Key优化:用作where过滤的维度放在前边、基数大的维度放在基数小的维度前边
并发粒度优化
6、Kylin Bi工具集成
与Kylin结合使用的可视化工具很多,例如:
ODBC:与Tableau、Excel、PowerBI等工具集成
JDBC:与Saiku、BIRT等Java工具集成
RestAPI:与JavaScript、Web网页集成
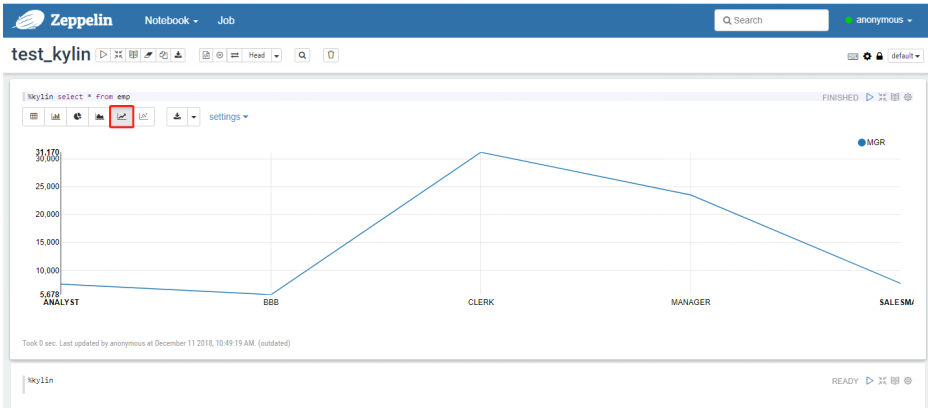
Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务。
JDBC
Zepplin:[atguigu@hadoop102 zeppelin]$ bin/zeppelin-daemon.sh start
修改配置
添加Note并编写SQL语句查询















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









