









在本文中,我们将重点关注 significant terms 和 significant text 聚合。这些聚合旨在搜索数据集中有趣和/或不寻常的术语,这些术语可以告诉您有关数据的隐藏属性的更多信息。此功能对于以下用例特别有用:
- 为用户查询标识包含同义词,首字母缩略词等的相关文档。例如,当用户搜索 H1N1 时,重要术语聚合可能会建议带有“bird flu”的文档。
- 识别数据中的异常和有趣的事件。例如,通过基于位置过滤文档,我们可以确定特定区域中最常见的犯罪类型。
- 使用对整数字段(例如身高,体重,收入等)的 significant term 聚合来确定一组主题的最重要属性。
应当注意,重要术语和重要文本聚合都对直接查询(前景集)和索引中所有其他文档(背景集)检索的文档执行复杂的统计计算。因此,两种聚合都需要大量计算,因此应正确配置以快速工作。但是,一旦在本教程的帮助下掌握了它们,你将获得一个强大的工具,可以在应用程序中构建非常有用的功能并从数据集中获取有用的见解。让我们开始吧!
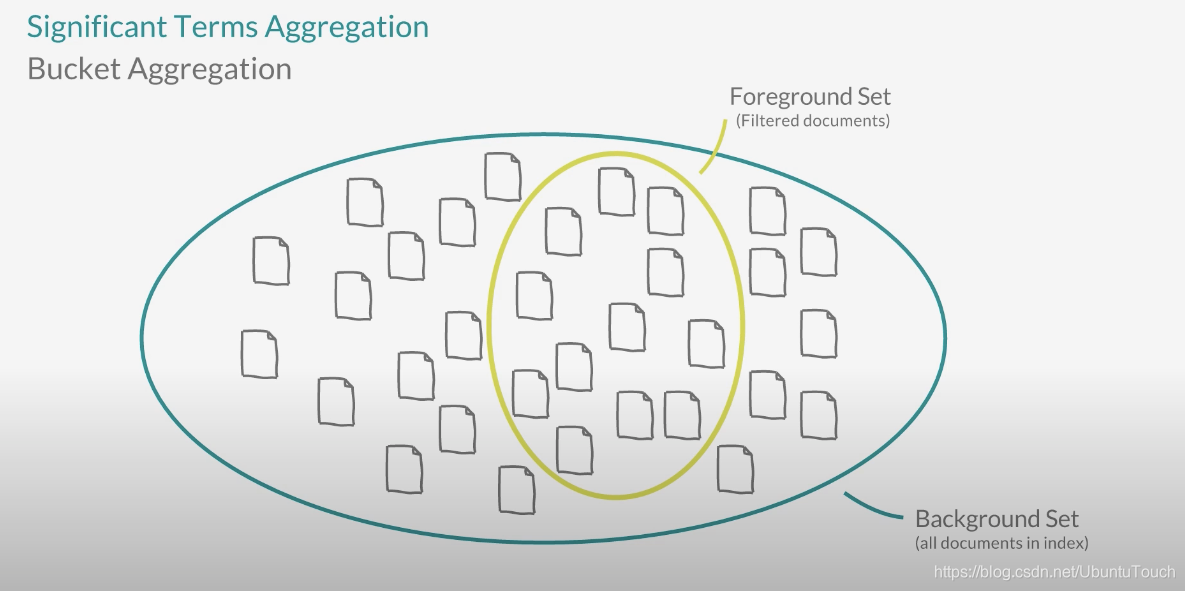
在使用 Significant aggregation 最重要的一点是: Terms aggregation + Noise Filter。 它抛弃一些最常用的术语,然后再做 terms aggregation。举一个例子,比如现在美国最流行的搜索网站是什么?很多人肯定会好不犹豫地说是谷歌。如果我再问你,在美国加州最流行的搜索网站是什么,你可能也好不犹豫地说是谷歌,因为这个网站太出名了。但是如果我们用 siginificant aggregation 的话,那么最终的答案将是除去谷歌这个最为出名的搜索网站以外的搜索网站是什么,是 bing 吗?还是 yahoo?
当我们做 significant terms aggregation 时,我们面对的是两个 datasets:
- Background set
- Foreground set
比如,我们有如下的数据集,在 Elasticsearch 中,有来自不同的浏览器的文档:Chrome, Firefox 及 IE:
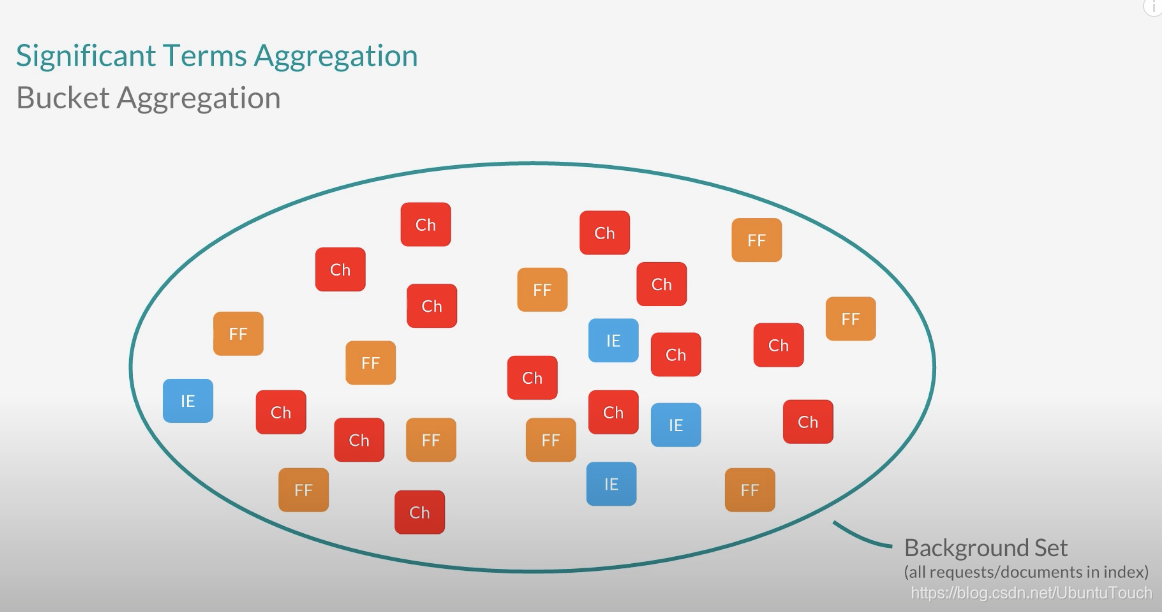
这个数据集是 Background 数据集。接下来,我们来针对我们的 Foreground 的数据集:
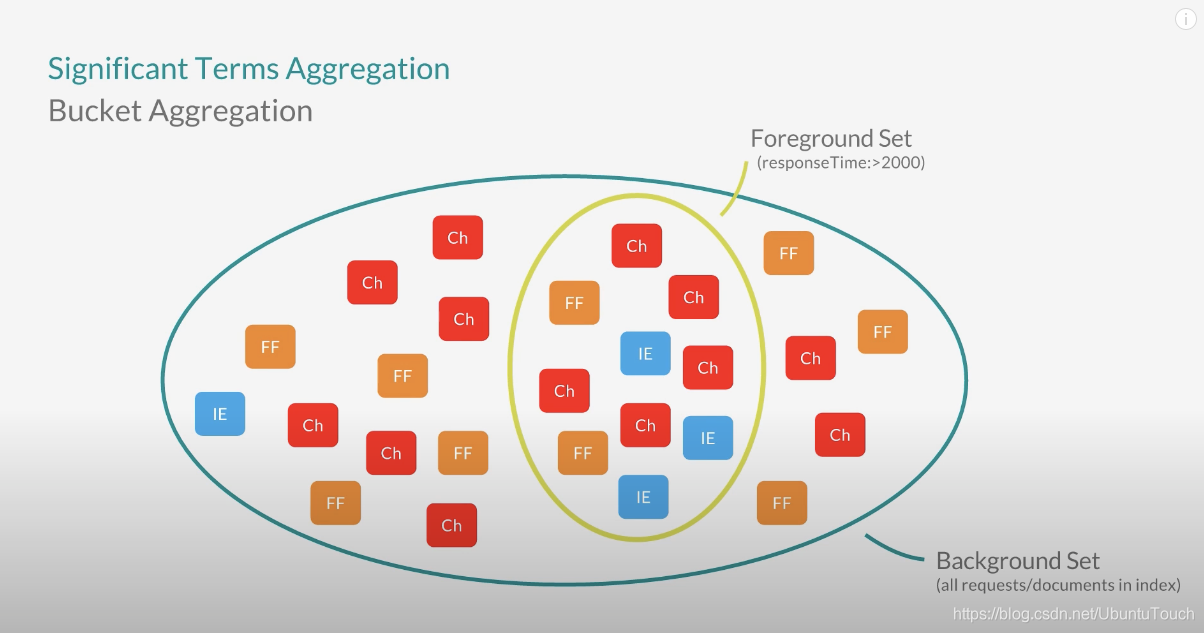
在上面,我们可以看出来:Foreground 数据集实际上是一个被选定的特别的数据集:一个被过滤的小的数据子集。在这个子集里,所有的 responesTime 都打印2000。如果我们只对这个子集里的文档进行统计,那么我们发现这个子集里的浏览器用的最多的还是 chrome。这个和我们的 Background set 里的统计是一样的。显然这个不是 significant 的结果。对于这个子集里的统计数据,significant term 的统计是 IE 浏览器,它的统计数据远大于在 Background set 里的统计数据。
教程
在教程开始,我们假定您已经把 Elasticsearch 及 Kibana 完整地安装好了。如果你还没安装好环境的话,请参阅我的博客文章“Elastic:菜鸟上手指南”来完整地安装好自己的环境。
创建Index mapping
为了说明 significant terms 和 significant text 的工作方式,我们首先需要创建一个测试 “news” 索引来存储新闻文章的集合。 索引映射将包含诸如作者,出版日期,文章标题,视图数和主题之类的字段。 让我们创建映射:
PUT news
{
"mappings": {
"properties": {
"published": {
"type": "date",
"format": "dateOptionalTime"
},
"author": {
"type": "keyword"
},
"title": {
"type": "text"
},
"topic": {
"type": "keyword"
},
"views": {
"type": "integer"
}
}
}
}如您所见,我们在 topic 和 author 字段中使用了 keyword 数据类型,在title字段中使用了 text 数据类型。 提醒您,关键字字段只能按其确切值进行搜索,而文本字段可用于全文搜索。
接下来,让我们使用 Bulk API 将一些任意新闻文档添加到索引中。
POST news/_bulk
{"index":{"_index":"news"}}
{"author":"John Michael","published":"2018-07-08","title":"Tesla is flirting with its lowest close in over 1 1/2 years (TSLA)","topic":"automobile","views":"431"}
{"index":{"_index":"news"}}
{"author":"John Michael","published":"2018-07-22","title":"Tesla to end up like Lehman Brothers (TSLA)","topic":"automobile","views":"1921"}
{"index":{"_index":"news"}}
{"author":"John Michael","published":"2018-07-29","title":"Tesla (TSLA) official says that they are going to release a new self-driving car model in the coming year","topic":"automobile","views":"1849"}
{"index":{"_index":"news"}}
{"author":"John Michael","published":"2018-08-14","title":"Five ways Tesla uses AI and Big Data","topic":"ai","views":"871"}
{"index":{"_index":"news"}}
{"author":"John Michael","published":"2018-08-14","title":"Toyota partners with Tesla (TSLA) to improve the security of self-driving cars","topic":"automobile","views":"871"}
{"index":{"_index":"news"}}
{"author":"Robert Cann","published":"2018-08-25","title":"Is AI dangerous for humanity","topic":"ai","views":"981"}
{"index":{"_index":"news"}}
{"author":"Robert Cann","published":"2018-09-13","title":"Is AI dangerous for humanity","topic":"ai","views":"871"}
{"index":{"_index":"news"}}
{"author":"Robert Cann","published":"2018-09-27","title":"Introduction to Generative Adversarial Networks (GANs) in self-driving cars","topic":"automobile","views":"1183"}
{"index":{"_index":"news"}}
{"author":"Robert Cann","published":"2018-10-09","title":"Introduction to Natural Language Processing","topic":"ai","views":"786"}
{"index":{"_index":"news"}}
{"author":"Robert Cann","published":"2018-10-15","title":"New Distant Objects Found in the Fight for Planet X ","topic":"astronomy","views":"542"}在这里,我们共同插入了20条数据。
Significant Terms Aggregation
正如我们已经提到的,重要的术语聚合可以识别数据中异常和有趣的术语。 对于以下用例,聚合功能非常强大:
- 识别与用户查询相关的相关术语/文档。 例如,当用户查询 “Spain” 时,聚合可能会建议诸如 “Madrid”,“Corrida” 之类的术语,或有关 Spain 的文档中常见的其他任何术语。
- Significant term 聚合可用于自动新闻分类器,其中基于频繁连接的术语图对文档进行分类。
- 发现数据中的异常。 例如,借助这种汇总,我们可以识别某些地理区域中的异常犯罪类型或疾病。
重要的是要理解,significant terms 聚合选择的术语不仅是文档集中最受欢迎的术语。 例如,即使首字母缩略词 “MSFT” 仅存在于一千万个文档索引中的10个文档中,但如果在与用户查询 “Microsoft” 相匹配的50个文档中有10个找到了这个 MSFT,则它仍然是相关的。 该频率使 acronym(比如 MSFT)与用户的搜索相关。
为了识别重要术语,聚合对与查询匹配的搜索结果以及从中收集结果的索引执行复杂的统计分析。 与查询直接匹配的搜索结果代表前景集,而从中检索它们的索引代表背景集。 重要术语聚合的任务是比较这些集合并找到最常与用户查询关联的术语。
让我们使用真实示例,演示聚合如何工作。 在下面的示例中,我们将尝试在索引中查找每个author的重要 topics。 为此,我们首先在 author 字段上使用术语“桶聚合(bucket aggregation)”。 您还记得,terms aggregation 为找到索引的所有唯一术语(即author)构造了存储桶。 接下来,我们在“topics”字段上使用 significant terms 聚合,以找出每个 author 的最重要 topic。 看一下下面的查询:
GET news/_search
{
"size": 0,
"aggregations": {
"authors": {
"terms": {
"field": "author"
},
"aggregations": {
"significant_topic_types": {
"significant_terms": {
"field": "topic"
}
}
}
}
}
}显示的结果为:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"authors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "John Michael",
"doc_count" : 5,
"significant_topic_types" : {
"doc_count" : 5,
"bg_count" : 10,
"buckets" : [
{
"key" : "automobile",
"doc_count" : 4,
"score" : 0.4800000000000001,
"bg_count" : 5
}
]
}
},
{
"key" : "Robert Cann",
"doc_count" : 5,
"significant_topic_types" : {
"doc_count" : 5,
"bg_count" : 10,
"buckets" : [
{
"key" : "ai",
"doc_count" : 3,
"score" : 0.2999999999999999,
"bg_count" : 4
}
]
}
}
]
}
}
}显然对于作者 John Michael 来说,在他所发表的书里 automobile 是最经常出现的词。共有4次,而 bg_count 是5。同样对于作者Robert Cann 来说,在他发布的作品里,ai是最最经常出现的词,在他的4个作品中,有3次提到ai。可以断定他就是一个ai专家!
针对上面的 significant terms 聚合查询,我们也可以通过如下的方法来查询针对某个作者(author)的聚合。
GET news/_search
{
"size": 0,
"query": {
"term": {
"author": "John Michael"
}
},
"aggregations": {
"significant_topics": {
"significant_terms": {
"field": "topic"
}
}
}
}显示的结果为:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"significant_topics" : {
"doc_count" : 5,
"bg_count" : 10,
"buckets" : [
{
"key" : "automobile",
"doc_count" : 4,
"score" : 0.4800000000000001,
"bg_count" : 5
}
]
}
}
}针对 significant text aggregation,基本它和 significant terms aggregation 非常相似,只是它作用于一个 text 字段而不是一个 keyword 字段。比如:
GET news/_search
{
"size": 0,
"query": {
"match": {
"title": "Tesla ai"
}
},
"aggregations": {
"significant_topics": {
"significant_text": {
"field": "topic"
}
}
}
}注意这里的 title 字段是 text,它同时搜索 Telsa 及 ai,再根据这两个词来进行聚合:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 7,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"significant_topics" : {
"doc_count" : 7,
"bg_count" : 10,
"buckets" : [
{
"key" : "automobile",
"doc_count" : 4,
"score" : 0.08163265306122446,
"bg_count" : 5
},
{
"key" : "ai",
"doc_count" : 3,
"score" : 0.030612244897959134,
"bg_count" : 4
}
]
}
}
}参考:


















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









