










 本文深入探讨了Elasticsearch中的Graph功能,解释了其在数据关联分析中的作用,包括图形顶点、连接和聚合框架的工作原理。通过实例展示了如何利用Graph API进行图形浏览和数据可视化,从而发现数据间的有意义联系,适用于欺诈检测、推荐引擎等多种应用场景。
本文深入探讨了Elasticsearch中的Graph功能,解释了其在数据关联分析中的作用,包括图形顶点、连接和聚合框架的工作原理。通过实例展示了如何利用Graph API进行图形浏览和数据可视化,从而发现数据间的有意义联系,适用于欺诈检测、推荐引擎等多种应用场景。
当我刚接触 Elastic 的 Graph 时,我对 Graph 的理解确实是模糊的。从字面上讲,它的意思是 “图形” 的意思。那个它在 Elasticsearch 中到底代表是什么?经过一段时间的探索,我对这个 Graph 有一些初步的认识。简单地说:graph 代表的是数据之间的关联。这个数据可以是同一个索引或者是多个索引的。在今天的文章中,我来介绍一下 graph 到底是什么。
图形分析功能使你可以发现Elasticsearch索引中的项目如何关联。 你可以探索索引词之间的联系,并查看哪些联系最有意义。 从欺诈检测到推荐引擎,这在各种应用中都非常有用。
例如,图形浏览可以帮助你发现黑客所针对的网络漏洞,从而可以加固你的网站。 或者,你可以向电子商务客户提供基于图的个性化推荐。
图形分析功能提供了一个简单但功能强大的图形浏览 API,以及用于 Kibana 的交互式图形可视化工具。 两者都可以与现有的 Elasticsearch 索引一起使用,你需要存储所有其他数据才能使用这些功能。
Graph 是如何工作的?
Graph API 提供了另一种方法来提取和汇总有关 Elasticsearch 索引中的文档和术语的信息。 图实际上只是相关术语(terms)的网络。 在我们的情况下,这意味着索引中的相关术语网络。
要包含在图中的术语称为顶点。 任何两个顶点之间的关系是一个连接。 该连接总结了包含两个顶点的术语的文档。
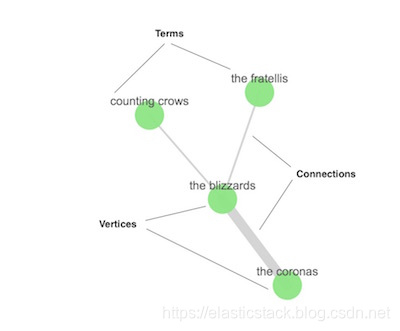
图形顶点只是已经索引的术语 (terms)。这些连接是使用 Elasticsearch 聚合从运行中派生的。为了确定最有意义的连接,图形 API 利用 Elasticsearch 相关性评分。内置于 Elasticsearch 中以支持文本搜索的相同数据结构和相关性排名工具,使图形 API 可以从噪声中获得一些有用的信号,这些噪声是最相关的数据。
该基础使你可以轻松回答以下问题:
- 人们试图入侵我的网站时有哪些共同行为?
- 如果用户购买了这种手套,他们可能还会对哪些其他产品感兴趣?
- Stack Overflow 上的哪些人在 Hadoop 相关技术和 Python 相关技术方面都有专业知识?
但是性能呢? Elasticsearch 聚合框架允许图形 API 作为单个超级连接快速汇总数百万个文档。它不是检索帐户 A 和 B 之间的每个银行交易,而是表示该关系的单个连接。而且,当然,此汇总过程适用于多节点集群并随着你的 Elasticsearch 部署而扩展。通过高级选项,你可以控制如何采样和汇总数据。你还可以设置超时,以防止图形查询对群集产生不利影响。
前提条件
- 目前这个功能需要你需要打开 Elasticsearch 的安全功能才可以使用。如果你还不知道如何打开 Elasticsearch 的安全功能,你可以参考我的文章“Elasticsearch:设置 Elastic 账户安全”。
- 另外你需接受 Elastic 的商业许可才可以使用这个功能。如果你还没有购买我们的商业许可,你看在我们的发行版中试用这个功能。
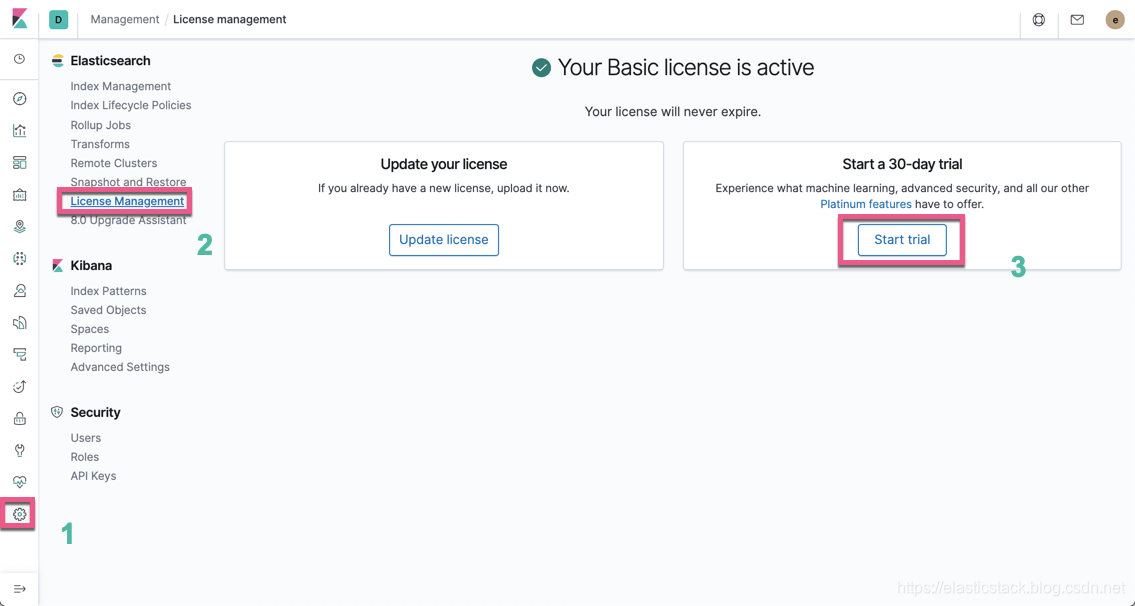
我们可以按照上面的步骤来试用这个功能。
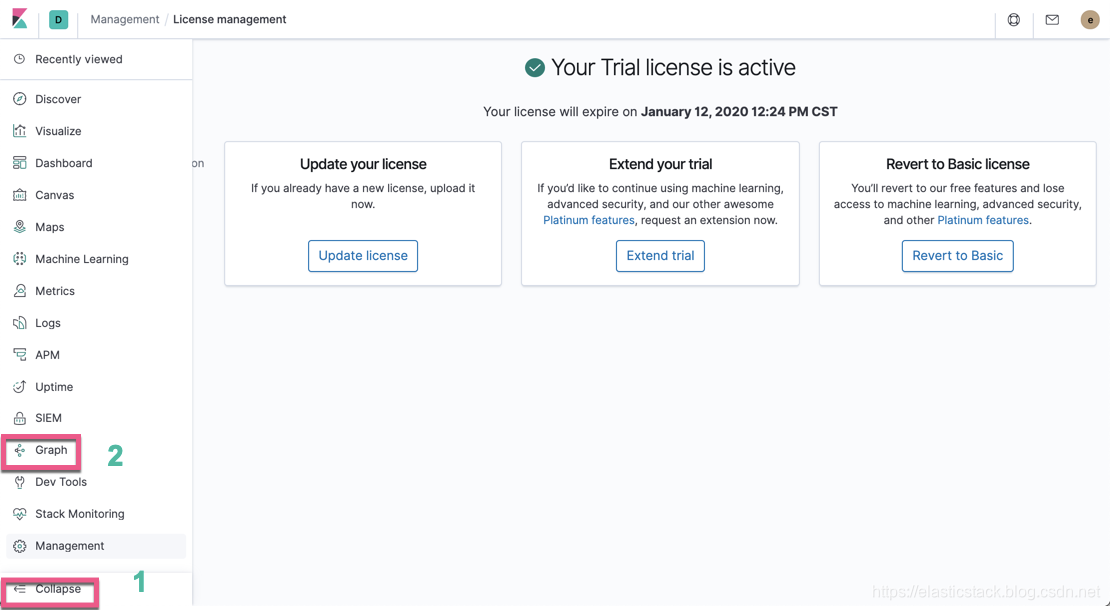
当我们接受完上面的 “30天试用” 后,我们可以在 Kibana 中看到一个多出来的 Graph 应用。
下来我们来使用一个具体的例子来阐述 Graph 有什么样的用途。
例子
准备数据
在今天的例子中,我们来使用一个来自互联网上的数据。我们可以在链接下载芝加哥城市人最新的工作人员的薪水及职位表单。
这些是数据集的元数据:
- 姓名:员工姓名
- 姓:员工的姓
- 部门:他工作的部门
- 职位:工作职位
- 年薪:年薪(美元)
- 收入等级*:基于年收入的收入
- 性别*:男性或女性
比如,一个员工的数据如下:
Annual Salary: 101,442
Department: POLICE
Full or Part-Time: F
Job Titles: SERGEANT
Name: AARON, JEFFERY M
Salary or Hourly: Salary
当我们下载好数据之后,它是一个 csv 格式的文件。我们可以通过如下的方式把这个数据导入到我们的 Elasticsearch 之中。

我们可以把我们的索引名字叫做 chicago_pay:
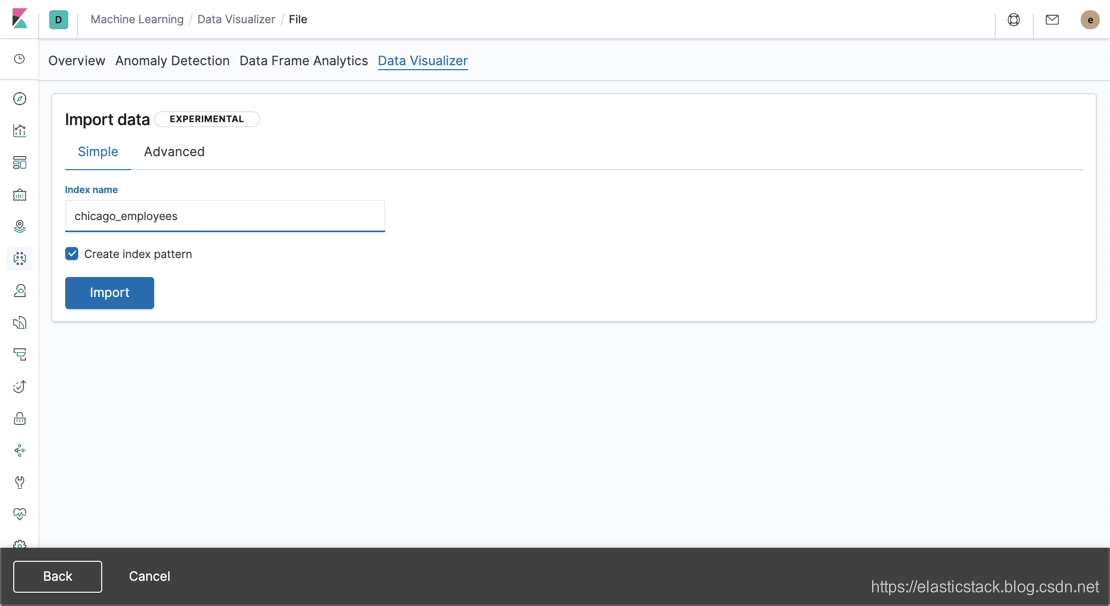
这样我们就创建好了我们的 chicaogo_employees 的索引。
在接下来的章节里,我们来使用 graph 来分析我们的数据。
利用 graph 来分析数据
在这一节里,我们来使用 graph 来找出我们这个样本数据里的所感兴趣的字段里的数据的关联。首先我们选择 graph 应用:
我们选择 Create graph 来创建一个 graph:
我们选择 Select a data source:
我们选择 chicago_employees 索引作为我们的 data source:
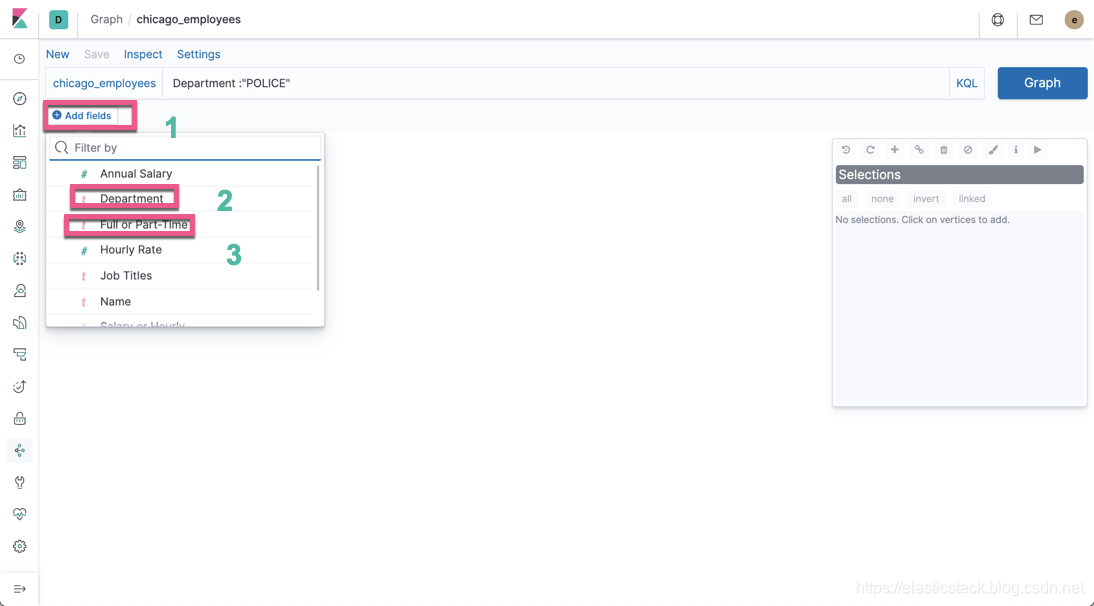
按照上面的顺序,我们点击 Add fields 来添加 Full or Part-time 和 Department 两个字段(我们可以分别定制两个字段的颜色及 icon。记住我们必须选择 keyword 字段才可以。在供选择的字段里标识为 “t”):
并点击 Save 保持我们的 graph:
等我们保存完我们的 graph 后,接下来,我们在我们的搜索框中进行搜索:
我们在上面的输入框中输入 Department:“POLICE" 字样来加入我们的 POLICE 和 Full or Part-Time 的关系。按照同样的方法,我们可以加入更多部门的关系:
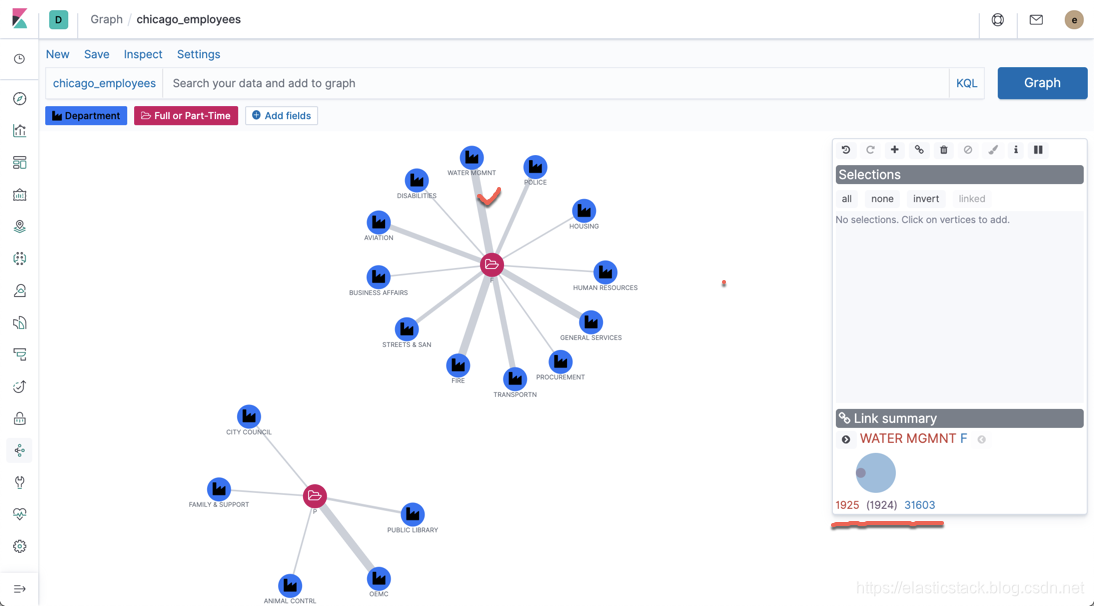
这里的线的粗细代表文档的关联的数量大小。从上面我们可以看出哪个部门的 Full time 的人最多 (FIRE部门),哪个部门 Full time 的最少 (DISABILITIES)。同时,我们可以可以看出来,针对 Part-time 的部门,那些是最多的,比如 OEMC 部门的 Part-time 的人是最多的。
我们可以引入更多的字段来反应它们之间的关系,比如我们加入 Salary or Hourly 字段,这样我们可以看出来那些人是按照年薪来发薪水的,哪些是按照小时计酬的:

从上面的图,我们可以看出来警察是按照年薪Salary来计酬的,而对于大多数的Part-time的工作人员来说,它们是按照小时来领取薪水的。
参考:


















 1639
1639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









