









高级搜索变得简单。Elastic App Search 的精心策划的经验将 Elasticsearch 的专注能力带入了一组完善的 API 和直观的仪表板。 利用无缝的可伸缩性,可调的相关性控件,详尽的文档,维护良好的客户端以及强大的分析功能,可以轻松构建领先的搜索体验。
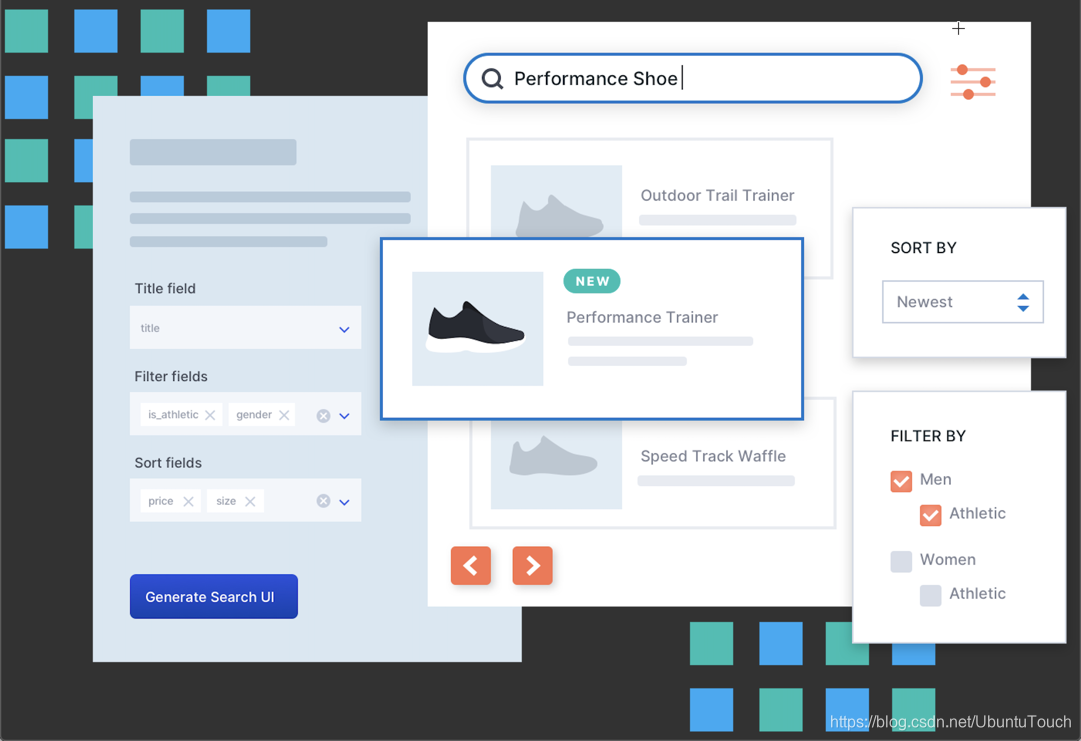
在今天的文章中,我们将详细地一步一步地介绍如何构建一个完整的 Elastic App Search 应用。
Elastic App Search 展示
什么是 Elastic App Search?
简单地说,Elastic App Search 是一组功能强大的 API 和开发人员工具,旨在为开发人员构建丰富的,面向用户的搜索应用程序。开箱即用的一些功能包括:
- 与搜索用例的优化相关性
- 容忍错误的输入
- 相关性微调
- 第一方 API 客户端和强大的 API
- 详细的 API 日志和搜索分析
- 自动扩容和运营支持
- Search UI 库

Elastic App Search 架构
架构图如下:
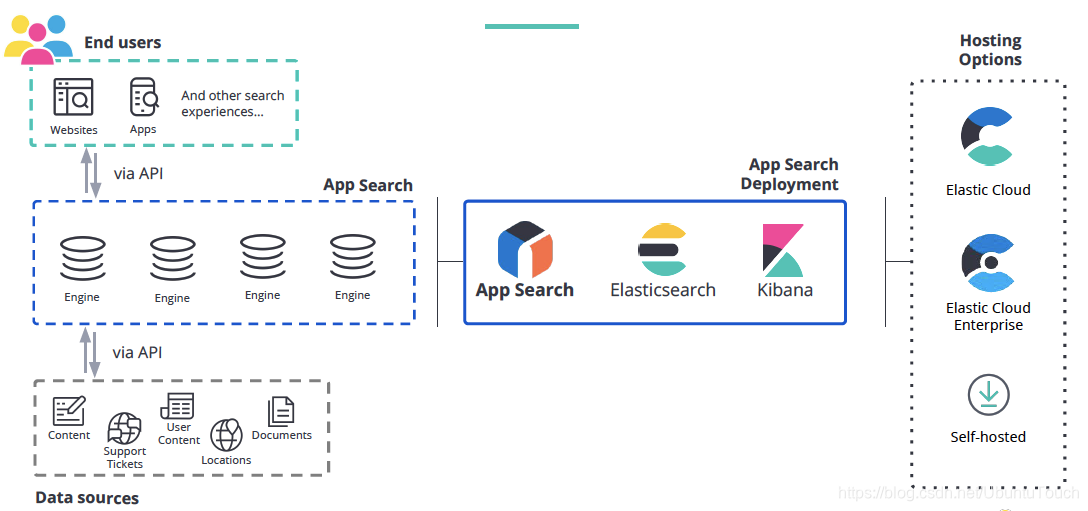
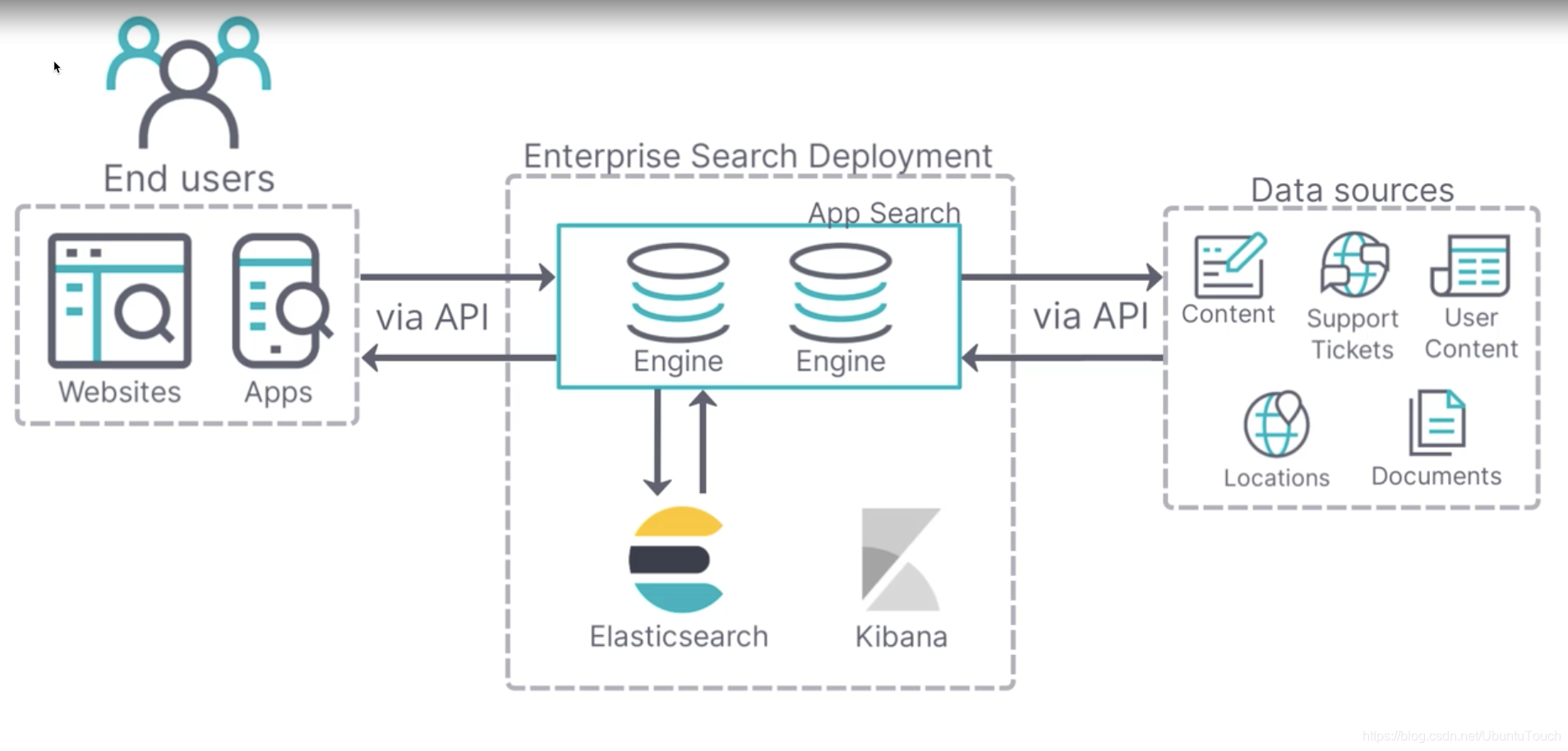
将数据摄取到 App Search 后,你可以轻松地通过 API 将你的应用程序连接到引擎,为你的最终用户创造强大的搜索体验。Enterpise Search 的部署通常由 Elasticsearch,Kibana 及 Enterprise Search 组成。App Search 是一组搜索引擎。 每个都有自己的一组文档,你可以在其中运行查询、调整相关性和探索搜索分析。数据源通过 API 或网络爬虫被摄入到引擎中。 数据源可以是技术支持票证、站点、电子商务库存、分支机构位置或你想从应用程序中搜索的任何数据。
App Search 允许你将搜索添加到你可能正在使用的任何类型的应用程序。 要成功设置你的搜索引擎,需要遵循几个步骤。 让我们来看看它们:
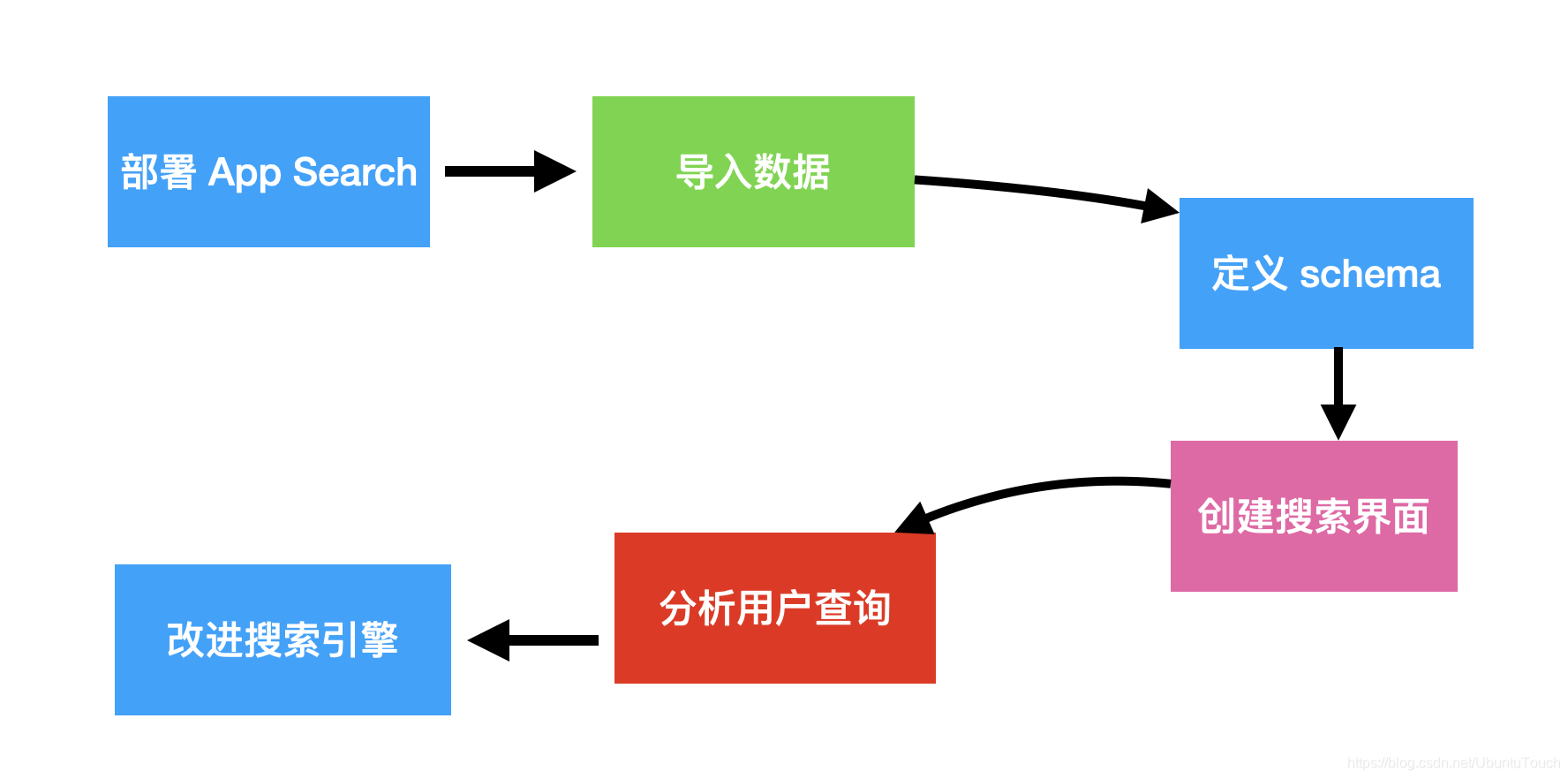
- 部署 App Search:第一步是部署 App Search,它由 Enterprise Search、Kibana 和 Elasticsearch Servers 组成
- 导入数据:创建一个引擎并索引你要搜索的数据
- 定义 schema:索引数据时,会创建默认架构。 为了优化体验,你需要调整这个schema
- 创建搜索界面:你已将文档索引到你的引擎中,现在你需要创建一个搜索界面以允许用户使用此搜索引擎
- 分析用户查询:你用户的查询会登录到 App Search。 分析它们以更好地了解用户的行为并找出引擎的弱点
- 改进搜索引擎:在分析方面,通过调整引擎的相关性、设置同义词和筛选并展示(curations)来改善你的搜索体验
安装
安装 Elasticsearch
我们可参考我之前的文章 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch” 来安装 Elasticsearch
安装 Kibana
我们接下来安装 Kibana。我们可以参考我之前的文章 “如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana” 来进行我们的安装。
Java安装
你需要安装 Java。版本在 Java 8 或者 Java 11。
App search 安装
我们在地址 https://www.elastic.co/downloads/app-search 找到我们需要的版本进行下载。并按照相应的指令来进行按照。如果你想针对你以前的版本进行安装的话,请参阅地址 https://www.elastic.co/downloads/past-releases#app-search。
如果我们不对 Elasticsearch 或 app-search 做任何的配置的话,我们会看到如下的错误信息:
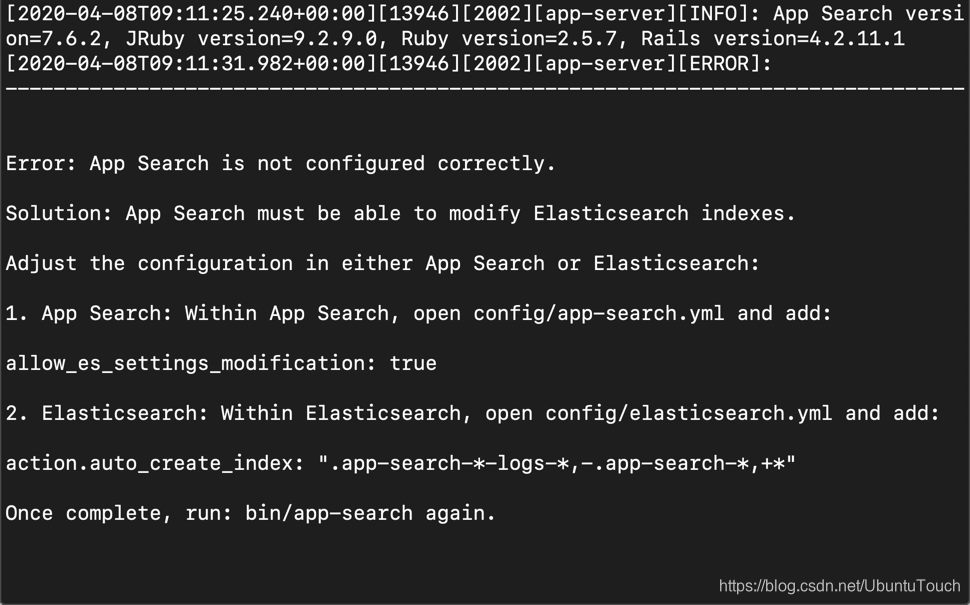
按照要求,我们也需要对我们的 Elasticsearch 的配置进行修改。在 Elasticsearch 的安装根目录中打开文件 config/elasticsearch.yml 文件,并添加如下的配置:
action.auto_create_index: ".app-search-*-logs-*,-.app-search-*,+*"等修改完后,我们重新启动 Elasticsearch:
./bin/elasticsearch我打开 App search 安装目录下的 confing/app-search.yml 文件,并添加如下的配置:
allow_es_settings_modification: true我们保存配置文件,并重新启动 app-search:
./bin/app-search如果我们配置正确的话,这次我们的 App search 的启动将是成功的。
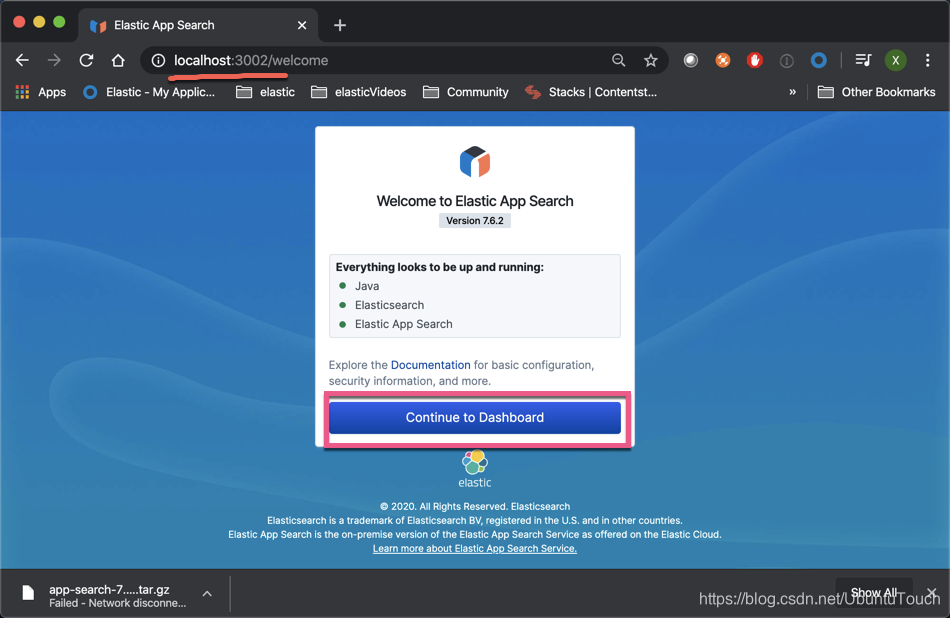
对于第一使用的开发者来说,你可能找不到 App search 的用户界面在哪里。你在自己的浏览器中输入地址 http://localhost:3002。这样你就可以看到如下的界面:
导入数据
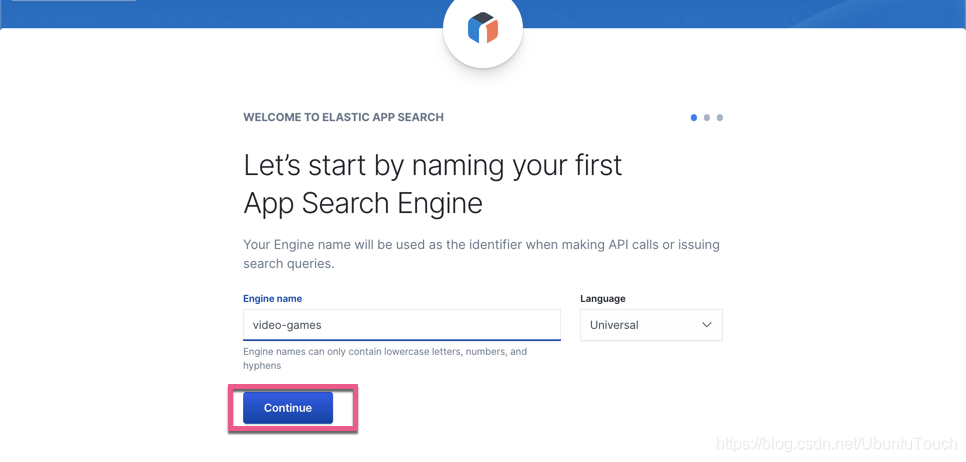
点击上面的 Continue to Dashboard 按钮:
下载 最佳视频游戏数据集 到本地的电脑的硬盘里。这个数据的名字叫做 games-array.json。如果由于一些原因,你不能下载这个文件,请到地址 https://github.com/liu-xiao-guo/elastic_app_search 去下载。
在 Engine name 里,我们输入 video-games,并点击上面的 Continue 按钮:
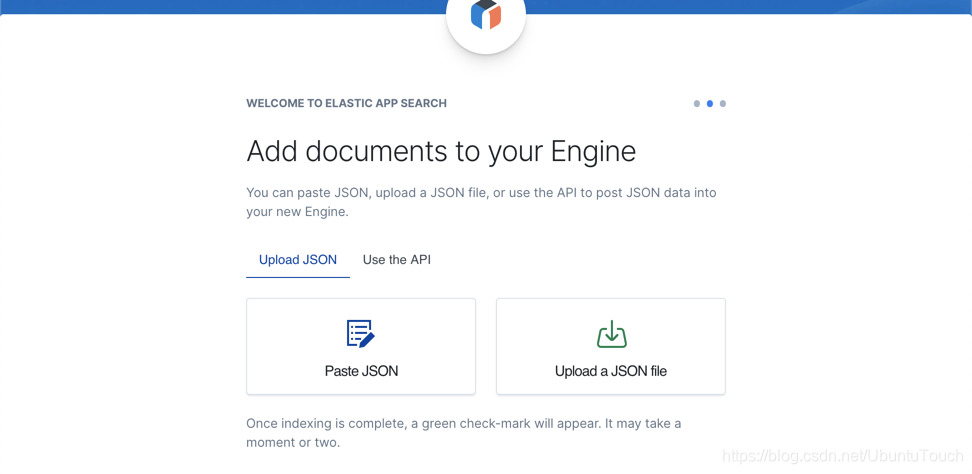
这样我们的 video-games 引擎已经被成功地创建了。我们可以按照上面的 Upload a JSON file 按钮来装载我们的数据。但是在今天的练习中,我们将展示如何使用API接口的方法把我们的数据导入到 Elasticsearch 中。我们点击上面图中的 Use the API 超链接:
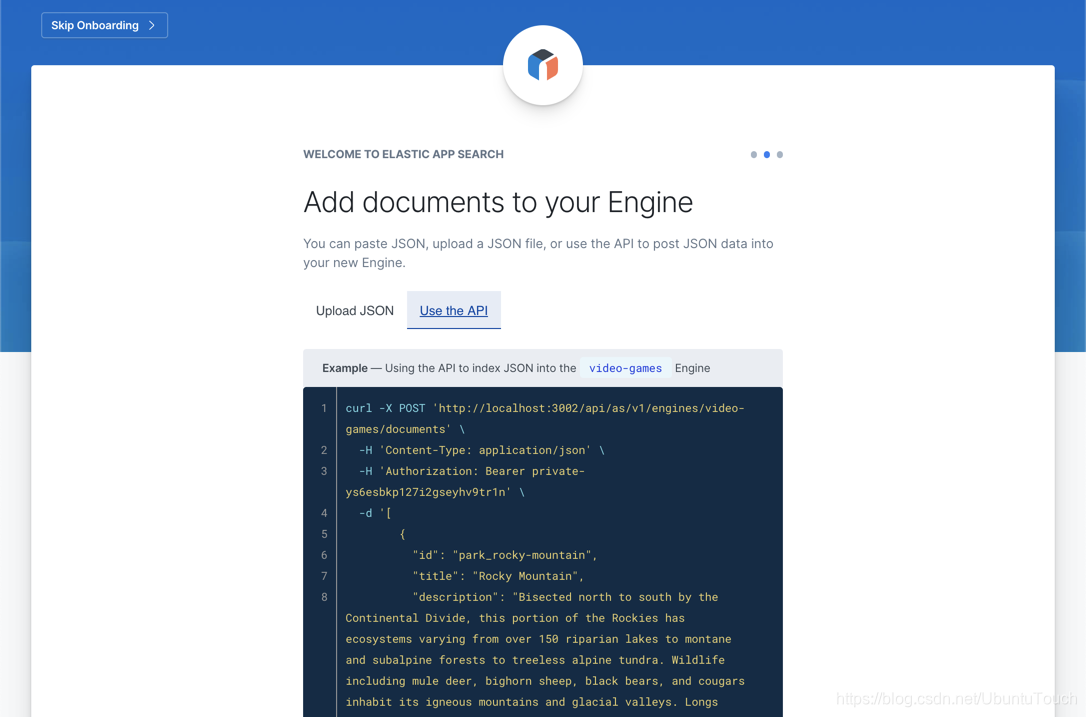
我们会发现在这里有如何通过 API 的方式把我们的数据导入到 Elasticsearch 中。在今天的演示中,我们将使用 ruby 来把数据导入。你也可以根据自己喜欢的语言把数据进行导入。我们创建一个叫做 upload.rb 的文件:
upload.rb
require 'elastic-app-search'
require 'json'
require 'progress_bar'
API_ENDPOINT = ''
API_KEY = ''
ENGINE_NAME = ''
client = Elastic::AppSearch::Client.new(:api_key => API_KEY, :api_endpoint => API_ENDPOINT)
file = File.read('./games-array.json')
data = JSON.parse(file)
bar = ProgressBar.new(data.count / 100)
data.each_slice(100) do |slice|
client.index_document(ENGINE_NAME, slice)
bar.increment!
end在上面,我们需要填入自己 App search 的配置:
- API_ENDPOINT: 这个可以在我们上面的截图中可以看出来:http://localhost:3002/api/as/v1/
- API_KEY: 这个是我们访问 App search 服务器的 key。在上面的 API 接口的 Authorization 部分可以看到:private-ys6esbkp127i2gseyhv9tr1n
- ENGINE_NAME:这个就是我们之前定义的那个引擎的名称 videos-games
我们将上面的信息填入到 upload.rb 中。在运行上面的 ruby 应用之前,我们需要安装上面三个需要的库:
sudo gem install progress_bar
sudo gem install elastic-app-search
sudo gem install json我们的工作目录中的文件是:
$ pwd
/Users/liuxg/data/appsearch
liuxg:appsearch liuxg$ ls
games-array.json upload.rb然后在 terminal 中打入如下的命令:
ruby upload.rb显示结果为:
$ ruby upload.rb
[#####################################] [5/5] [100.00%] [00:02] [00:00] [1.99/s]这样我们的数据就导入到 Elasticsearch 中了。这个时候在我们的 App search 界面,我们可以发现:
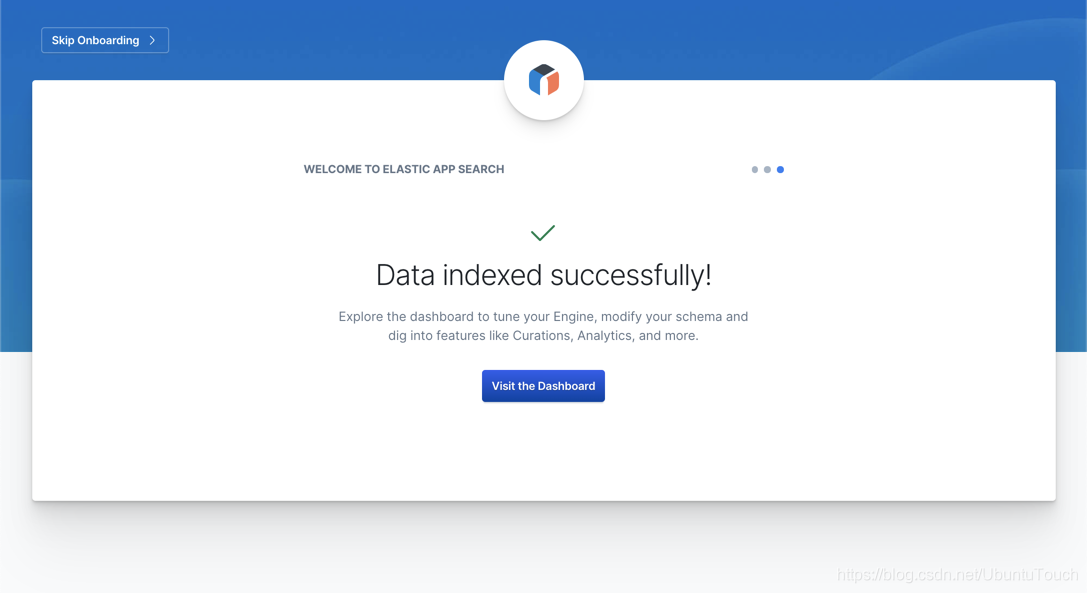
它显示我们的数据已经被成功地导入到 Elasticseach 中了。
搜索引擎: Elastic App Search
我们点击上面的 Visit the Dashboard 按钮:
我们在这个页面可以点击一下 Credentials,你也可以发现我们的 private-key 在这里:
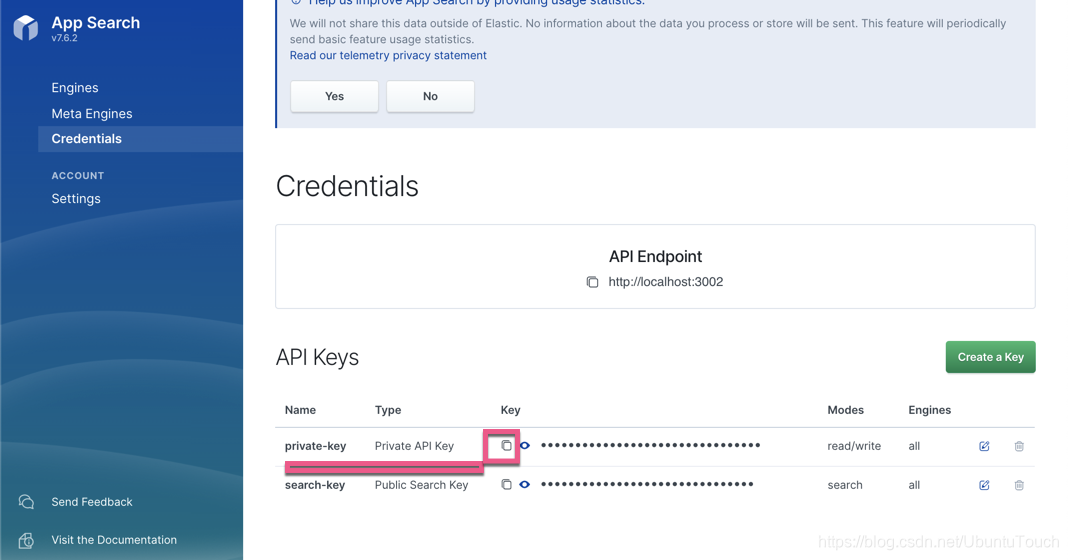
我们可以点击 copy 图标来得到我们所需要的 private-key。按照同样的方法,我们也可以得到 search-key。
我们接下来点击 Engines:
我们点击上面的 video-games:
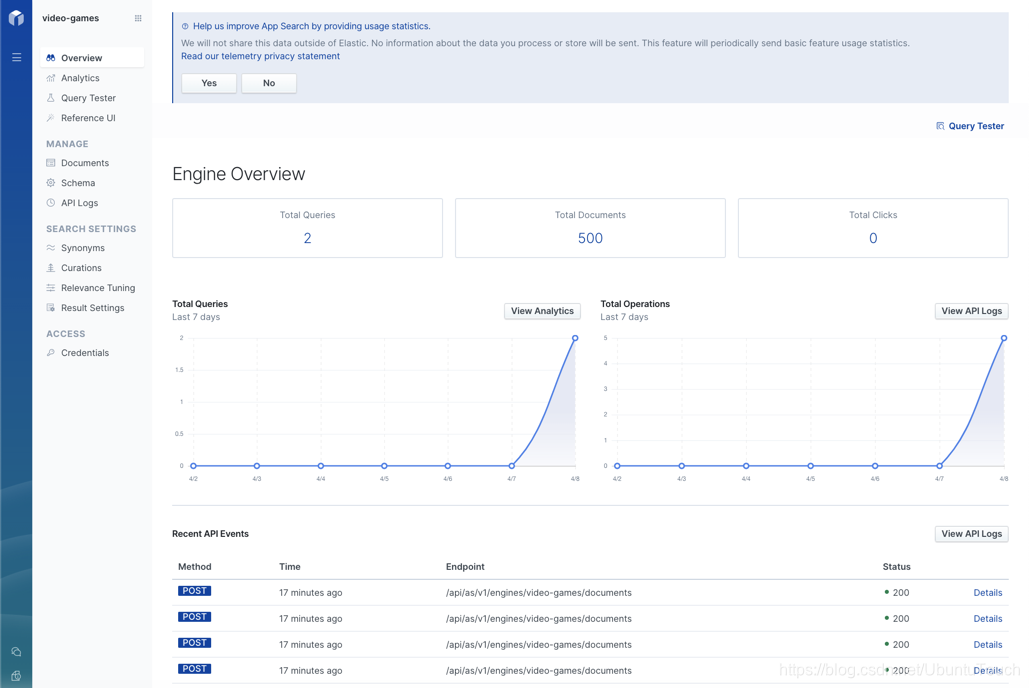
从上面我们可以看到整个 video-engine 的统计情况。它显示我们共用500个文档。同时我们也可以看到所有的 API 的使用情况。如果你发现有任何的问题,你可以点击 View API Logs 来查看 API 的使用情况:
我们接着下来想修改索引的 schema,这是因为在默认的情况下,所有的11个字段都被视为 text 类型。
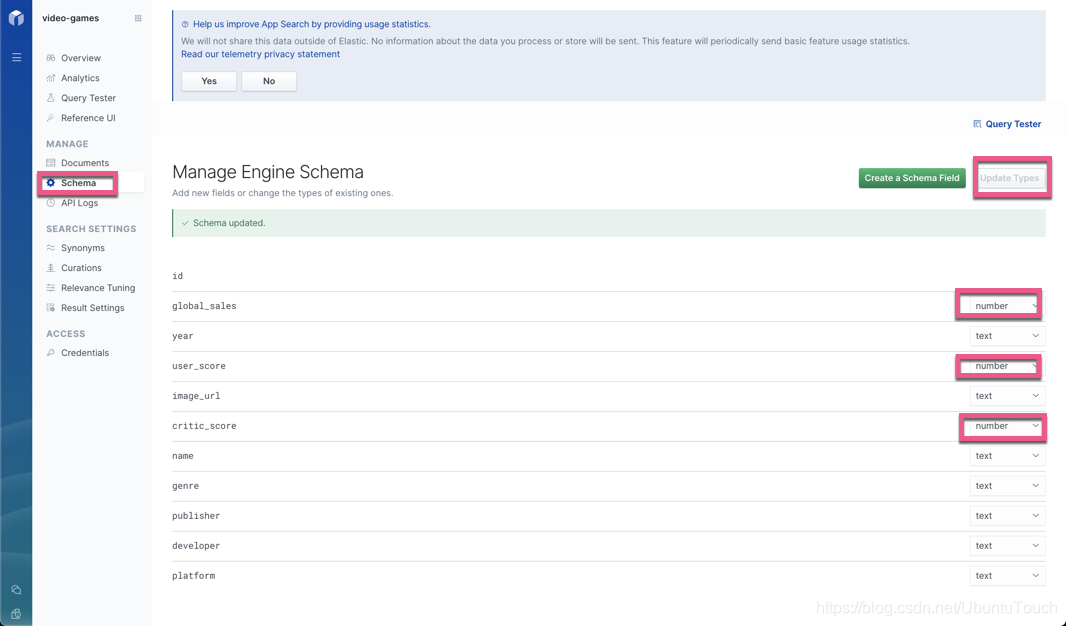
在完成我们的修改过后,点击 Update Types 按钮。这样我们的索引将会被重新更新。我们点击 Documents:
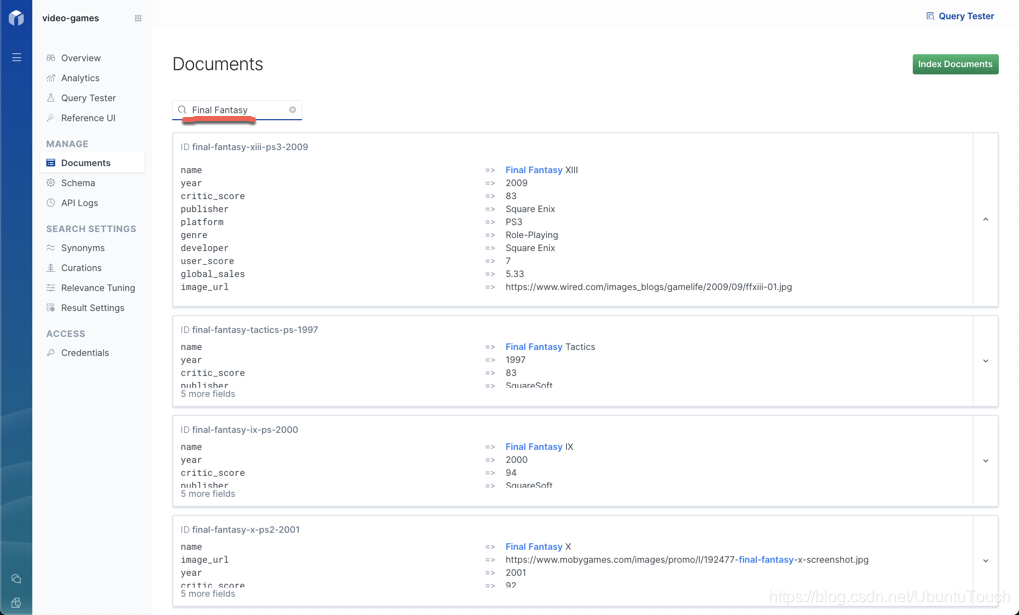
在这里,我们可以看到所有的文档。我可以尝试在 Filter documents 的位置输入一个关键词,比如 Final Fantasy 。我们可以看到所有被搜索到的文档。
调节相关度
具有三个关键的相关功能:Synonyms,Curations 和 Relevance Tuning。
Synonyms
世界各地的人们使用不同的词来形容事物。 同义词可帮助你创建被视为一个或一组相同的术语集。
就 video game 搜索引擎而言,我们知道人们会希望找到 Final Fantasy。 但是也许他们会改用FF。
单击进入同义词,然后选择创建同义词集并输入术语:
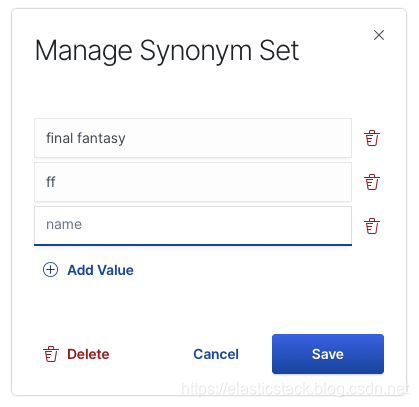
单击 Save。 你可以根据需要添加任意多个同义词集。
现在,搜索 FF 与搜索 Final Fantasy 的权重相同。
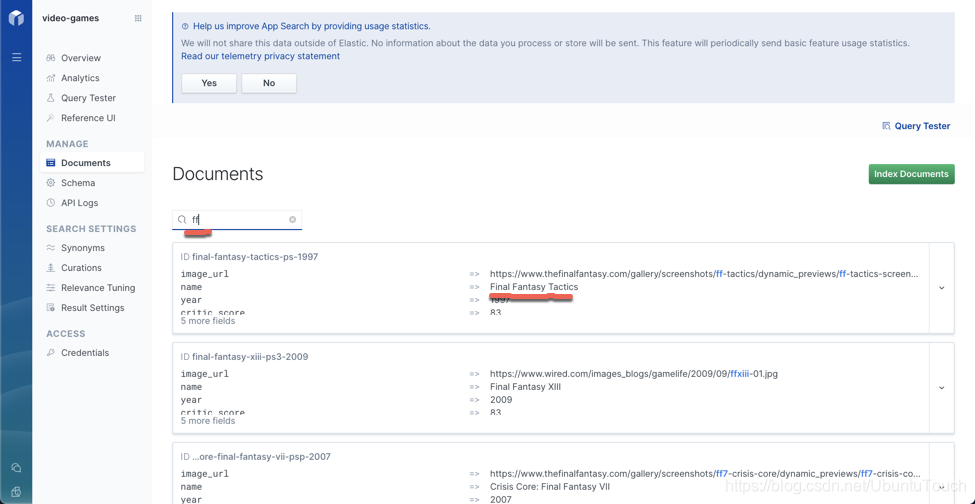
Curations
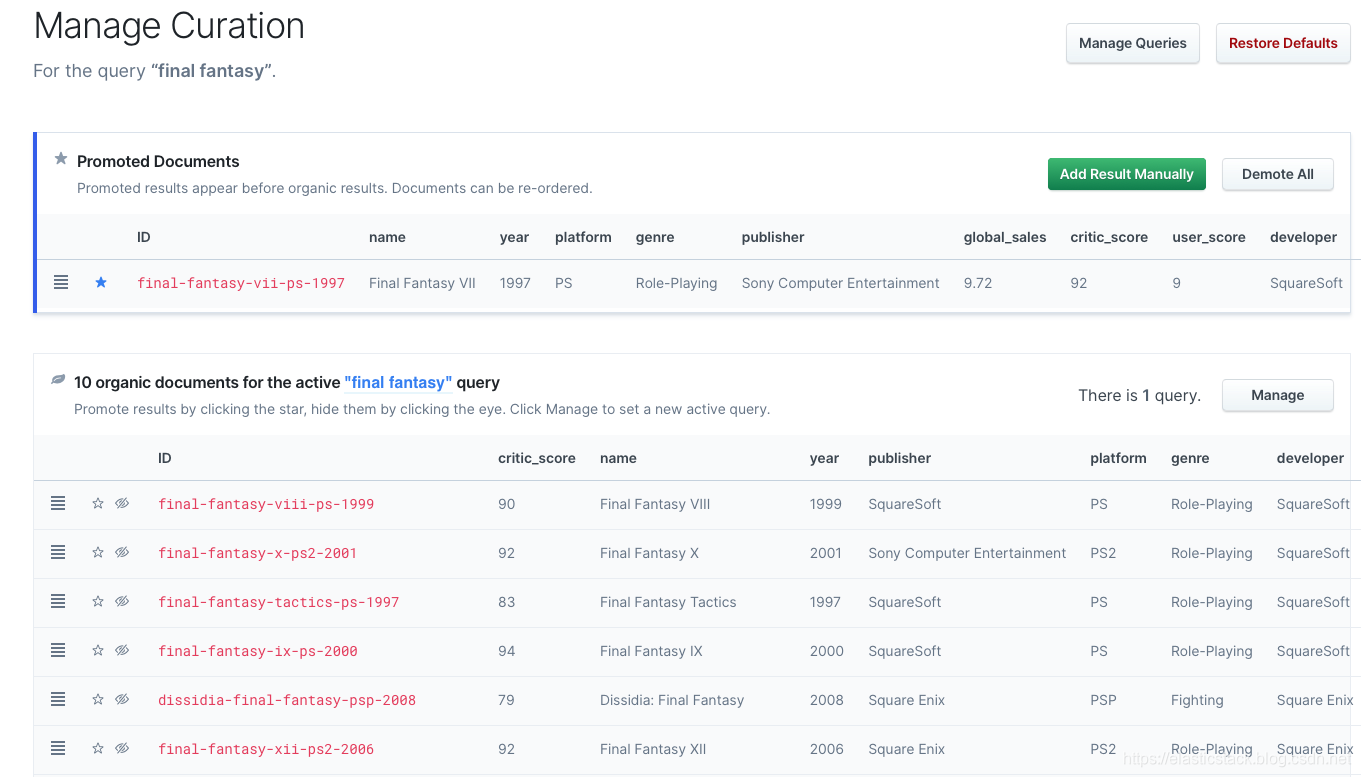
Curations 是另一种可用于优化搜索体验的工具。 Curation 允许你手动提升或隐藏特定查询的文档。 Curation 可用于增加每次点击的搜索比率或执行推广特定内容的活动。
Curations 是最最让人喜欢的。 如果有人搜索 Final Fantasy 或 FF,该怎么办? 系列赛中有很多游戏-他们会得到哪些?
默认情况下,前五个结果如下所示:
- Final Fantasy VIII
- Final Fantasy X
- Final Fantasy Tactics
- Final Fantasy IX
- Final Fantasy XIII
这似乎不正确……Final Fantasy VII 是所有游戏中最好的 Final Fantasy 游戏。 而且 Final Fantasy XIII 不是很好! 😜
我们可以做到这一点,以便搜索 Final Fantas y的人会收到 Final Fantasy VII 作为第一结果吗? 我们可以从搜索结果中删除 Final Fnatasy XIII 吗?
我们可以!
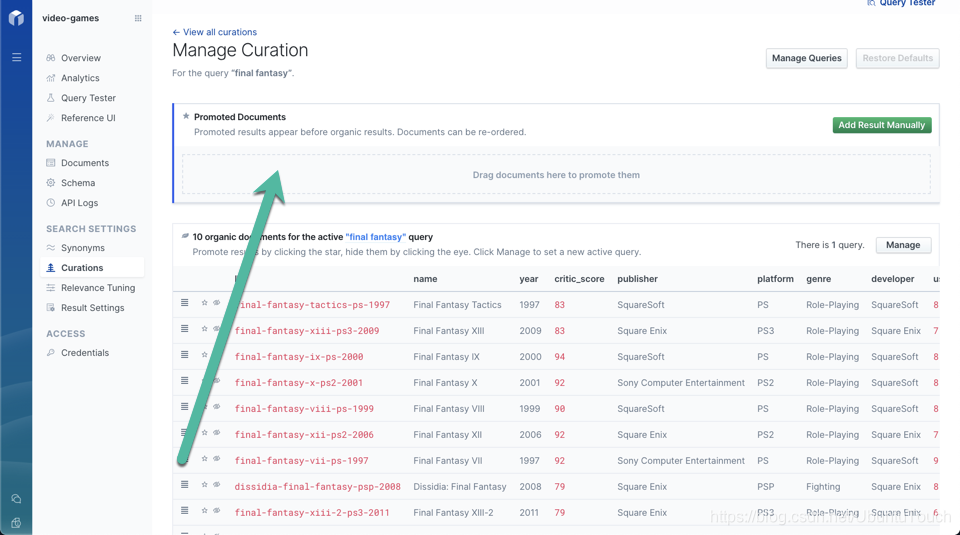
单击 “Curations”,然后输入查询:“Final Fantasy”。
接下来,通过抓住表格最左侧的把手将 “Final FantasyVII” 文档拖到 “Promoted Documents” 部分:
然后单击 “Final Fantasy XIII” 文档上的 “Hide Result” 按钮(那个有一条线穿过眼睛的图标,下图列表中第三个图标):
现在,执行 “Final Fantasy” 或 “FF” 搜索的任何人都将首先看到 “Final Fantasy VII”:
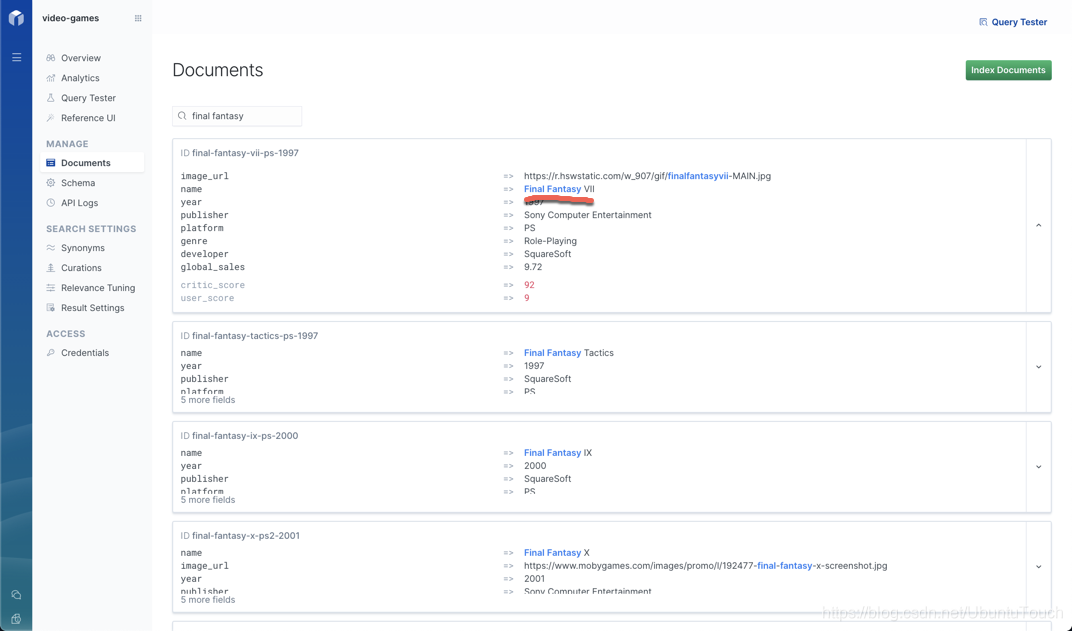
他们根本看不到 Final Fantasy XIII。 哈!
我们可以升级和隐藏许多文档。 我们甚至可以对升级后的文档进行排序,因此我们可以完全控制每个查询顶部显示的内容。
Relevance tuning
单击边栏中的 “Relevance Tuning”。
我们搜索一个文本字段:name 字段。 但是,如果我们有多个文本字段可供人们搜索,例如 name 字段和 description 字段,该怎么办? 我们正在使用的 video game 数据集不包含 description 字 段,因此我们假想一些文档以进行仔细考虑。
说我们的文档看起来像这样:
{
"name":"Magical Quest",
"description": "A dangerous journey through caves and such."
},
{
"name":"Dangerous Quest",
"description": "A magical journey filled with magical magic. Highly magic."
}如果有人想找到游戏 Magical Quest,他们会输入该内容作为查询。 但是第一个结果将是 Dangerous Quest:
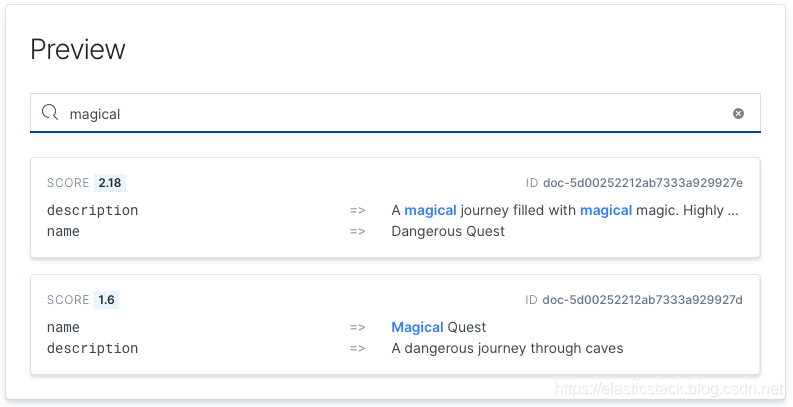
为什么? 因为在 “Dangerous” 的 description 中 “Magical” 一词出现了3次,所以搜索引擎不会知道一个字段比另一个字段更重要。 然后,它将使 “Dangerous Quest” 的排名更高。 这就是为什么存在相关性调整的难题。
我们可以选择一个字段,除其他外,还可以增加其相关性的权重:
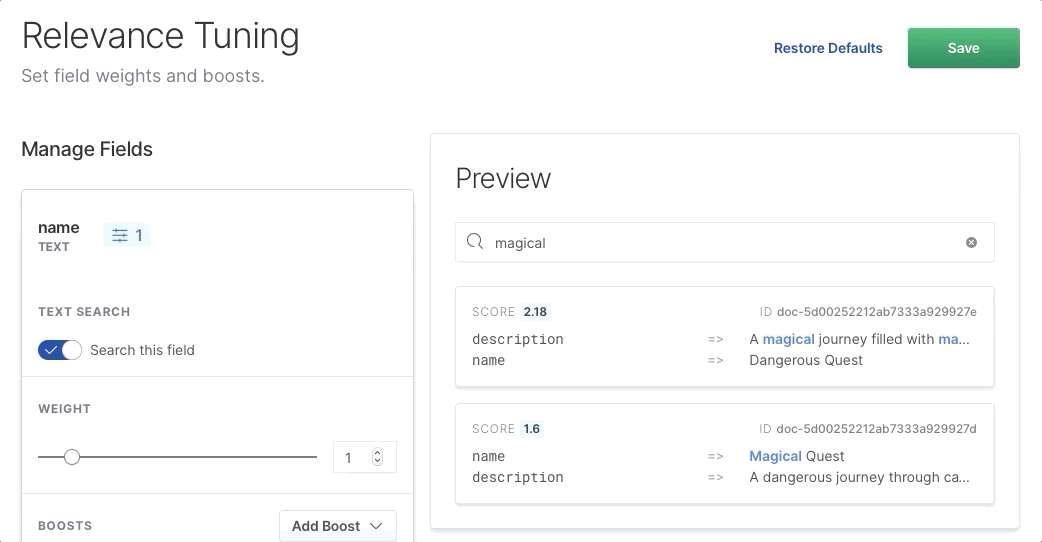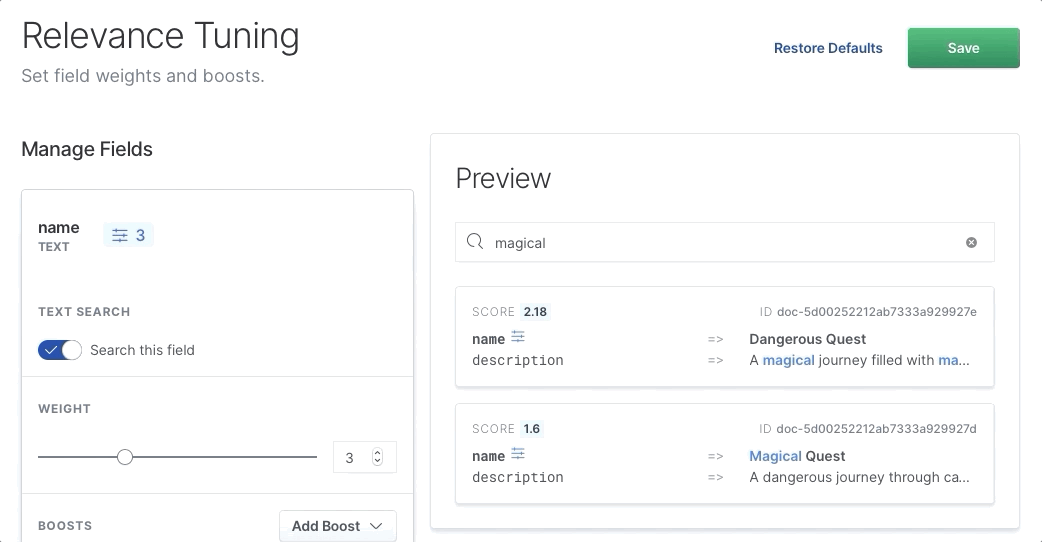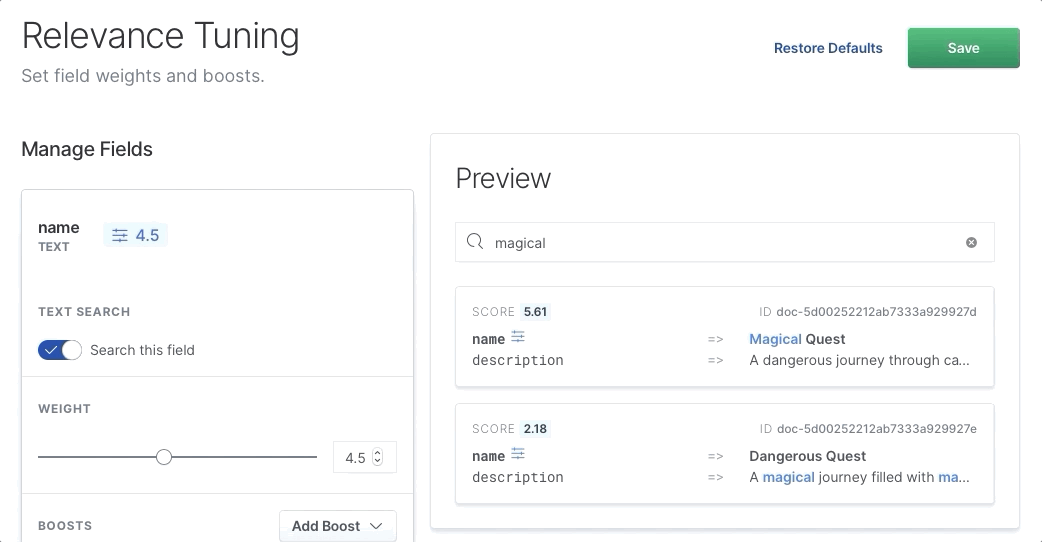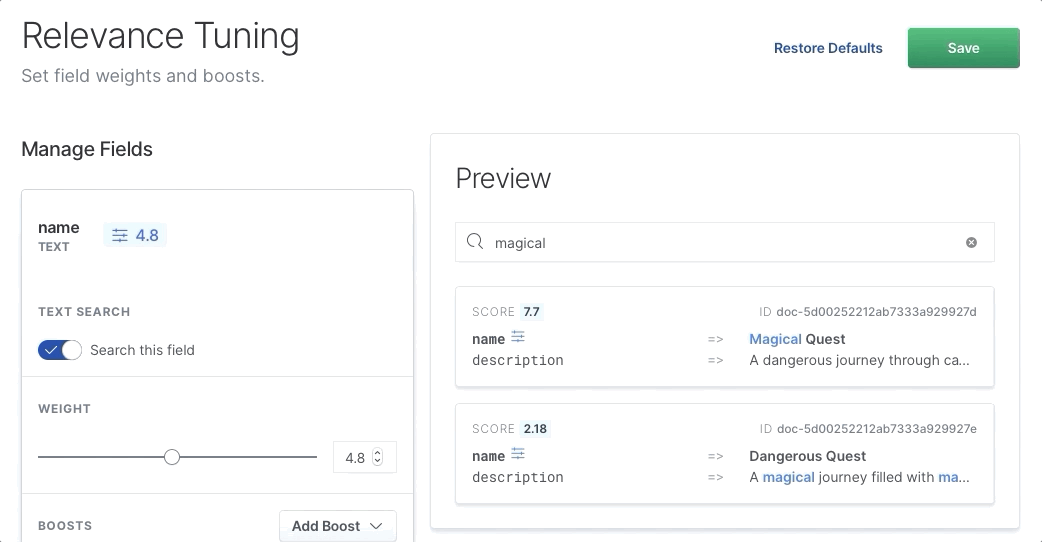
我们看到,当我们增加权重时,正确的项目 “Magical Quest” 上升到顶部,因为 name 字段变得更重要。 我们需要做的就是将滑块拖动到更高的值,然后单击 “Save”。
现在,我们已经使用 App Search 实现了如下的任务:
- 调整 schema,并将 user_score 和 critic_score 更改为数字字段。
- 微调关联(relevance)模型。
通常我们进行文字搜索的时候,相关性可以体现在不同 text 字段的匹配度上。在上面,我们通过调整 name 字段的 weight 来达到 relevance 的调整。通过这样的设置,可以使得 name 字段比其它字段更为重要。但是在实际的应用中,我们也可以使用数字来提高文档的相关度。比如,我们可以使用 user_score 来评估一个视频的受欢迎程度。一个视频的用户打分越高,那么就越值得推荐。在我们的搜索中,我们也希望能把这个视频的排名排在前面。在这种情况下,我们可以使用 boost 来调整这些数值字段从而提高相关文章的搜索相关度。比如,在上面的搜索场景中,我们可以使用 user_score 来 boost 搜索的结果。user_score 越高,则代表文档的相关性越高。
weights 和 boosts 有一下的一些区别,尽管两个都会影响最终的文档的分数。首先,通过组合每个搜索的字段的分数来计算文档的分数。 请注意,只能在文本(text)字段上启用搜索,并且你可以在相关性调整中手动禁用字段。
- Weight 通过将该字段的分数乘以你设置的权重来影响单个字段的分数。
- Boost 会影响整个文档的分数。 提升通过使用加法或乘法来增加文档分数。 你可以选择三种不同类型的函数来计算此提升。
这样就总结出了精美的“仪表板”功能-每个功能都有一个匹配的 API 端点,如果你不是 GUI 的用户,则可以使用它们使程序以编程方式工作。
我们可以点击 Analyics 来发现我们的搜索的统计情况:
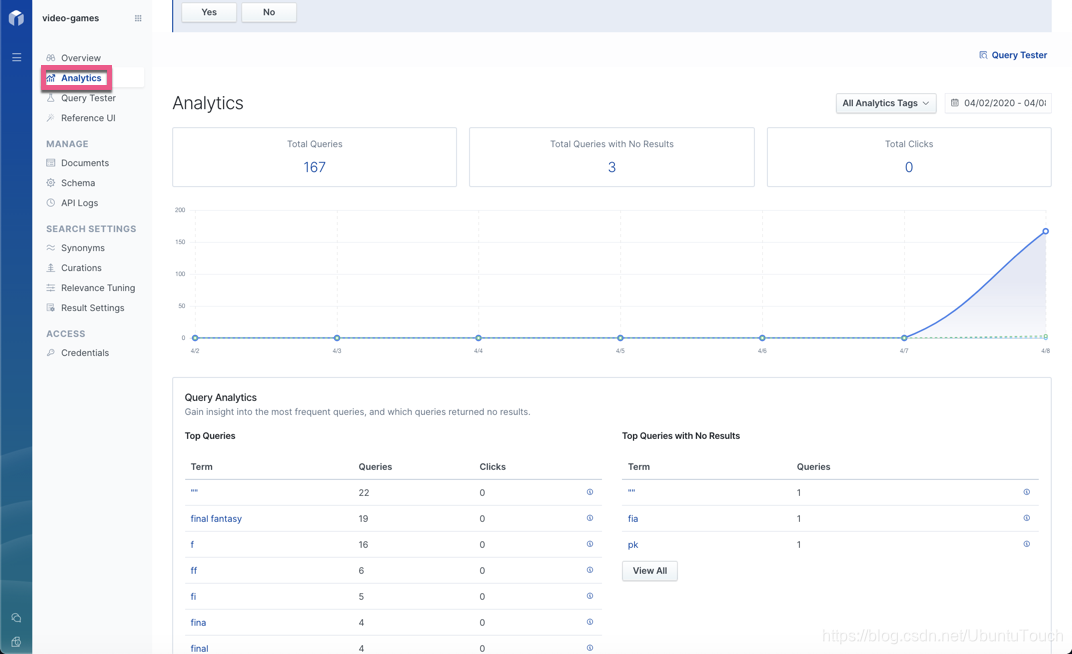
你可以看到 Top queries 及 Top Queries with No Results。
App Search 跟踪所有执行的查询和点击的结果。 分析页面使你能够分析这些数据。可以通过多种不同方式使用分析来帮助你改善用户体验。 几个例子是:
- 没有点击或没有结果的 queries -> 应该返回带有更多文档的结果 -> 修复它创建同义词或新内容
- 每次搜索点击率低的查询 -> 应该返回具有更多相关文档的结果 -> 修复它创建 curations 或重新考虑相关性调整策略
Reference UI
我们点击 Reference UI:
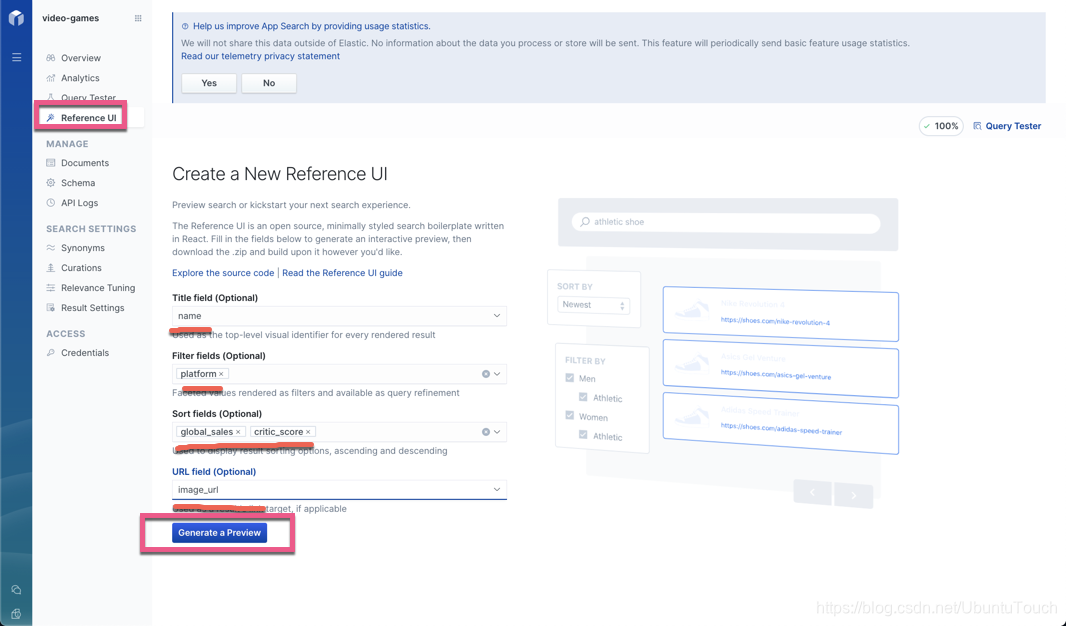
并做相应的配置。点击 Generate a Preview 按钮:
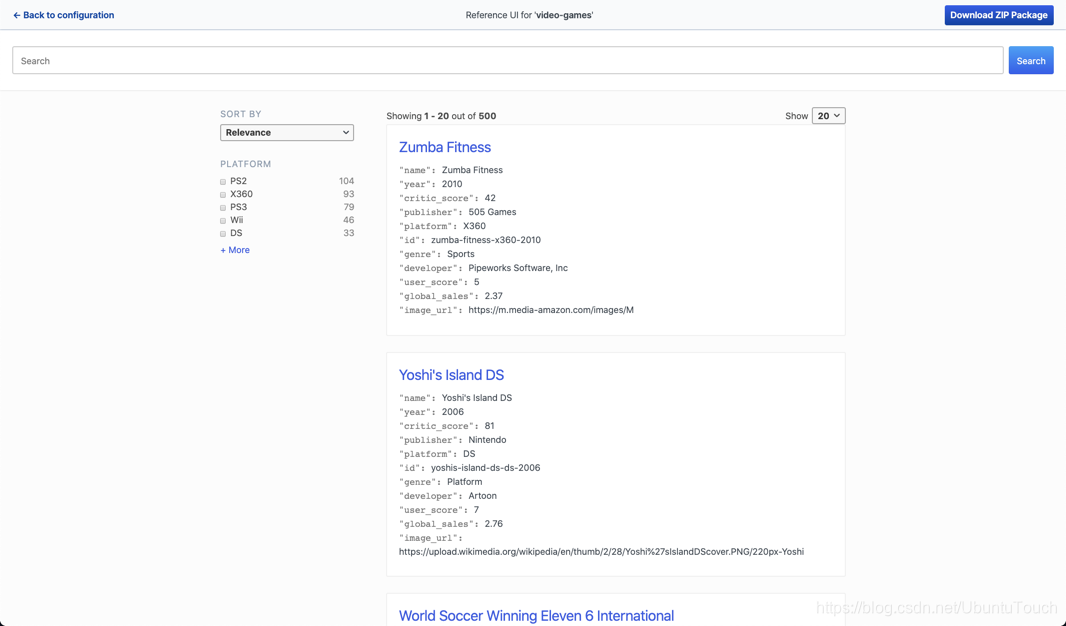
这样我们就可以看到如上所示的用户界面。我们可以尝试输入一个关键字比如 final fantasy 来进行搜索:
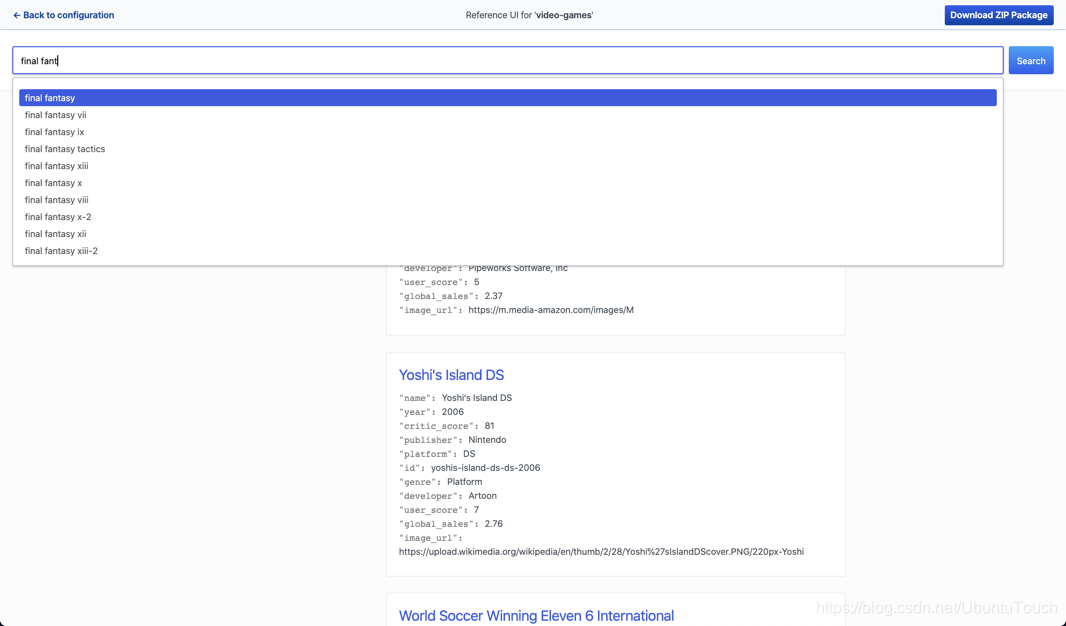
在上面我们可以看到在输入框中,它含有 auto-complete 的功能。我们选择 final fantasy:
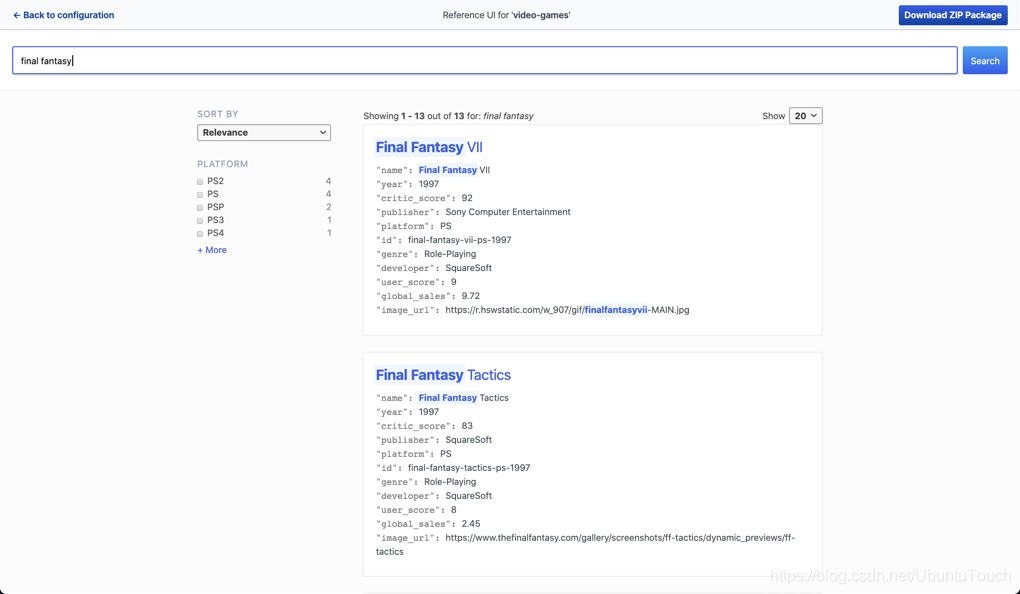
我们马上看到我们想要的结果了。我们有我可以点击上面显示的 filter 及 sort by:
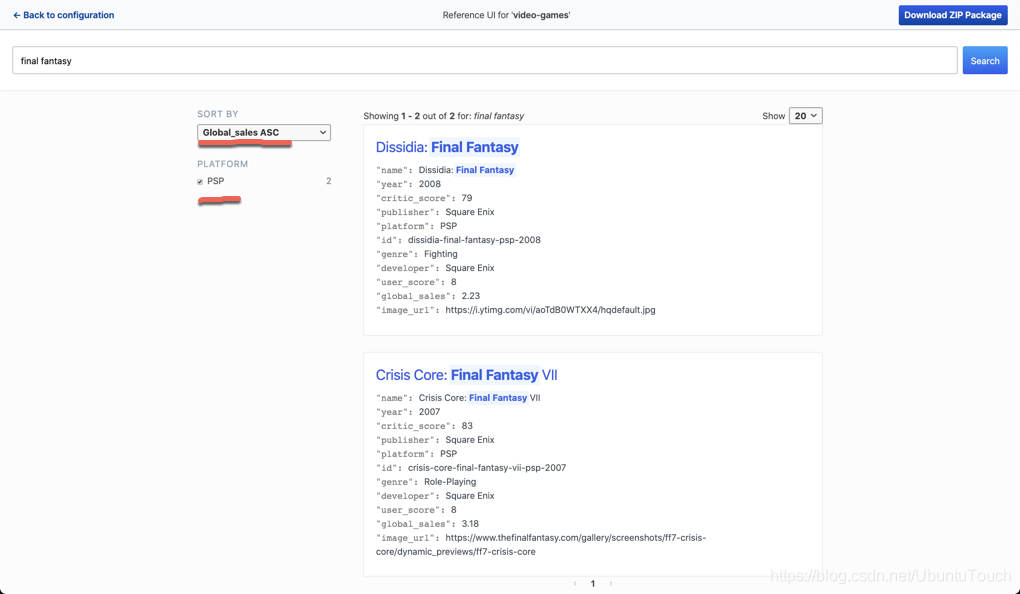
到目前为止是不是很酷啊。我们没有做任何的开发就有一个非常酷的界面给我们进行搜索了。
我们点击上面屏幕右上角的 Download Zip Package,并保存于一个文件目录中。我们解压这个压缩包:
$ pwd
/Users/liuxg/data/appsearch/app
liuxg:app liuxg$ ls
LICENSE.txt bin package.json
NOTICE.txt logo-app-search.png public
README.md package-lock.json src在上面,我们可以看到这是一个 nodejs 的应用程序。我们使用如下的命令来进行安装:
npm install一旦安装完后,我们可以使用如下的命令来进行运行:
npm start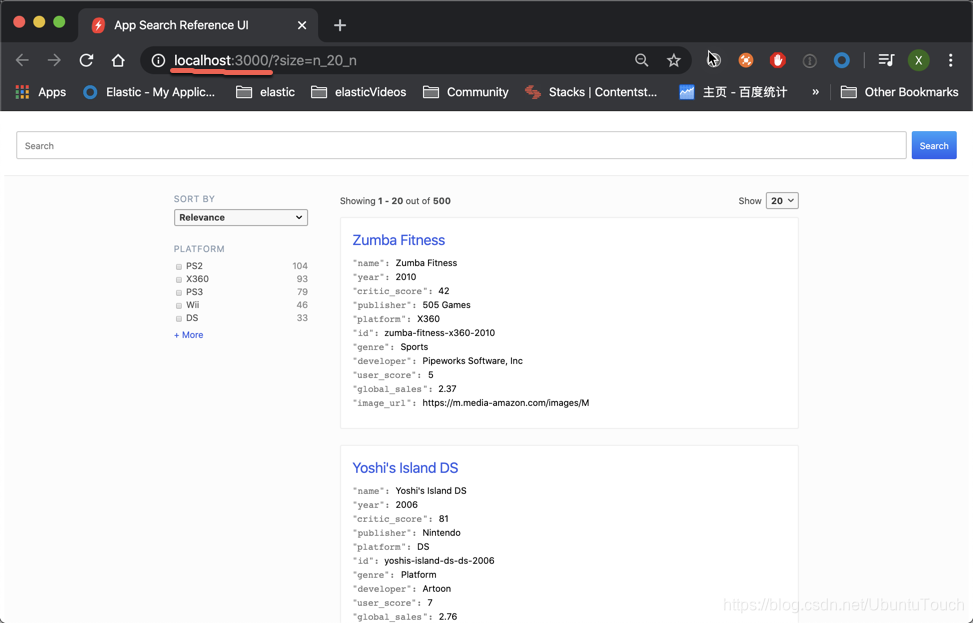
在上面我们可以看到和之前一样的界面。
好了到此为止,我们已经创建了一个真正意义上的从0开始的 App search 应用。希望大家喜欢。如果你希望对 Elastic 的 Search UI 感兴趣的话,或者你想更加细致地设计自己的UI和搜索体验的话,你可以参阅:
参考:
【1】https://swiftype.com/documentation/app-search/self-managed/installation#app-search


















 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









