









今天的文章来自我一个国外同事的分享。通过这个例子,我们可以了解如何选择我们想要的聚合,排序,以及从 source 中提取字段。这个例子来源于一个需求,在 Elastic 有一个叫做 Contributor 的项目。鼓励大家来参加我们的社区分享。每次分享都会得到一个积分。在每个季度或者年度,我们会根据每个 Contributor 的积分进行排名,并得出最终的贡献奖。
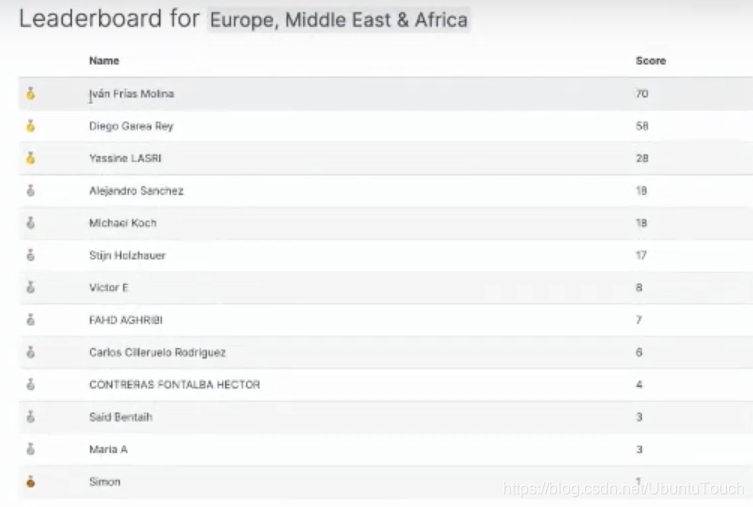
这里有一个问题就是。参加这个活动的每个 Contributor 都会对应于一个独一无二的邮件地址,但是每次分享他的名字可能会有不同。在数据统计时,我们需要依据邮件地址而不是 Contributor 的名字来进行统计。
我们先来看一下如下的一个索引:
PUT scoreboard/_bulk?refresh
{"index":{}}
{ "score" : 1, "@timestamp" : "2021-02-28", "email":"peter@example.org", "name" : "Peter Parker"}
{"index":{}}
{ "score" : 4, "@timestamp" : "2021-02-01", "email":"peter@example.org", "name" : "Peter MiddleName Parker"}
{"index":{}}
{ "score" : 4, "@timestamp" : "2021-02-01", "email":"paul@example.org", "name" : "Paul Paulinson"}
{"index":{}}
{ "score" : 100, "@timestamp" : "2021-01-31", "email":"paul@example.org", "name" : "Paul Paulinson"}
{"index":{}}
{ "score" : 200, "@timestamp" : "2021-03-01", "email":"paul@example.org", "name" : "Paul Paulinson"}
{"index":{}}
{ "score" : 3, "@timestamp" : "2021-02-14", "email":"peter@otherexample.org", "name" : "Peter Parker"}
{"index":{}}
{ "score" : 1, "@timestamp" : "2021-02-28", "email":"other@example.org", "name" : "Someone Other"}
{"index":{}}
{ "score" : 1, "@timestamp" : "2021-02-28", "email":"other@example.org", "name" : "Someone Other"}
{"index":{}}
{ "score" : 1, "@timestamp" : "2021-02-26", "email":"other@example.org", "name" : "Someone Other 123"}
{"index":{}}
{ "score" : 1, "@timestamp" : "2021-02-01", "email":"other@example.org", "name" : "Someone Other 456"}在上面的索引中,我们可以看到 scoreboard 是一个时序的索引。这是一个抽象处理的 Contributor 的索引。每个 Contributor 的邮件地址是唯一的,但是每次参加活动的名字可能有会有出入。这个好比有些活动,有人在一个场合喜欢用中文名字,而在另外一个场合可能喜欢用英文名字。在统计时,我们必须使用邮件地址来进行统计。我们的最终目的是找出其中的一个月的得分最高的 Contributor。我们的聚合要求:
- 限定于某个月
- 以邮件地址来进行统计
- 按照得分高低进行排列
- 最终的名字显示已最近活动一次活动的名字为准,不显示邮件地址(保密)
针对这样的要求,那么我们该如何进行聚合呢?
限定时间范围
我们可以通过 range query 来限定时间的范围:
GET scoreboard/_search
{
"query": {
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
}
}通过上面的搜索,我们把时间的范围限定于 2021 年 2 月份。我们可以得到8个文档。
以邮件地址来进行聚合并统计分数
我们可以通过 terms aggregation 来针对邮件地址来进行统计,并使用 sum aggregation 来统计分数:
GET scoreboard/_search
{
"size": 0,
"query": {
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
},
"aggs": {
"by_user": {
"terms": {
"field": "email.keyword",
"size": 10
},
"aggs": {
"total": {
"sum": {
"field": "score"
}
}
}
}
}
}上面统计的结果是:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"by_user" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "other@example.org",
"doc_count" : 4,
"total" : {
"value" : 4.0
}
},
{
"key" : "peter@example.org",
"doc_count" : 2,
"total" : {
"value" : 5.0
}
},
{
"key" : "paul@example.org",
"doc_count" : 1,
"total" : {
"value" : 4.0
}
},
{
"key" : "peter@otherexample.org",
"doc_count" : 1,
"total" : {
"value" : 3.0
}
}
]
}
}
}从上面的结果中,我们可以看出来每个邮件地址的统计结果,但是它并没有帮我们进行排序。我们可以依据 total 的结果来进行排序。我们需要更进一步做如下的修改:
GET scoreboard/_search
{
"size": 0,
"query": {
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
},
"aggs": {
"by_user": {
"terms": {
"field": "email.keyword",
"size": 10,
"order": {
"total.value": "desc"
}
},
"aggs": {
"total": {
"sum": {
"field": "score"
}
}
}
}
}
}在上面,我添加了 order 的部分。运行上面的查询:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"by_user" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "peter@example.org",
"doc_count" : 2,
"total" : {
"value" : 5.0
}
},
{
"key" : "other@example.org",
"doc_count" : 4,
"total" : {
"value" : 4.0
}
},
{
"key" : "paul@example.org",
"doc_count" : 1,
"total" : {
"value" : 4.0
}
},
{
"key" : "peter@otherexample.org",
"doc_count" : 1,
"total" : {
"value" : 3.0
}
}
]
}
}
}这一次,我们可以看到分数是从上到下的排列。
获取 Contributor 的名字
在上面的结果中,它显示了每个人的邮件地址。这个可不好!我们希望显示的是每个 Contributor 的名字。我们需要使用到 top_hits 聚合。并且我们希望得到的是他最近一次使用的名字为准。
GET scoreboard/_search
{
"size": 0,
"query": {
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
},
"aggs": {
"by_user": {
"terms": {
"field": "email.keyword",
"size": 10,
"order": {
"total.value": "desc"
}
},
"aggs": {
"total": {
"sum": {
"field": "score"
}
},
"top_hits_name": {
"top_hits": {
"size": 1,
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
]
}
}
}
}
}
}在上面,我们添加了 top_hits 聚合,并按照时间的顺序进行排序。显示的结果为:
"aggregations" : {
"by_user" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "peter@example.org",
"doc_count" : 2,
"total" : {
"value" : 5.0
},
"top_hits_name" : {
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "scoreboard",
"_type" : "_doc",
"_id" : "1nSCw3gBI6xucLpoqrCy",
"_score" : null,
"_source" : {
"score" : 1,
"@timestamp" : "2021-02-28",
"email" : "peter@example.org",
"name" : "Peter Parker"
},
"sort" : [
1614470400000
]
}
]
}
}
},
...在上面,它显示了 Contributor 的名字,但是在 _source 里含有我们不想要的字段,比如 @timestamp 以及 email。我们可以通过如下的方式来限制这些字段:
GET scoreboard/_search
{
"size": 0,
"query": {
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
},
"aggs": {
"by_user": {
"terms": {
"field": "email.keyword",
"size": 10,
"order": {
"total.value": "desc"
}
},
"aggs": {
"total": {
"sum": {
"field": "score"
}
},
"top_hits_name": {
"top_hits": {
"size": 1,
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
],
"_source": {
"includes": "name"
}
}
}
}
}
}
}在上面,我们使用了 includes 来选择 name,而其它的字段我们并不感兴趣:
"aggregations" : {
"by_user" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "peter@example.org",
"doc_count" : 2,
"total" : {
"value" : 5.0
},
"top_hits_name" : {
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "scoreboard",
"_type" : "_doc",
"_id" : "1nSCw3gBI6xucLpoqrCy",
"_score" : null,
"_source" : {
"name" : "Peter Parker"
},
"sort" : [
1614470400000
]
}
]
}
}
}
...到目前为止,我们已经完成了我们想要的功能。我们通过 top_hits 获得每个 Contributor 的名字。但是这种方法是不是最优的呢?毕竟 top_hits 需要去读取每个 source。
进一步思考
为了找出来 Contributor 的名字,我们可以使用 terms aggregator,并以 @timestamp 来进行排序:
GET scoreboard/_search
{
"size": 0,
"query": {
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
},
"aggs": {
"by_user": {
"terms": {
"field": "email.keyword",
"size": 10,
"order": {
"total.value": "desc"
}
},
"aggs": {
"total": {
"sum": {
"field": "score"
}
},
"name": {
"terms": {
"field": "name.keyword",
"size": 1,
"order": {
"latest.value": "desc"
}
},
"aggs": {
"latest": {
"max": {
"field": "@timestamp"
}
}
}
}
}
}
}
}在上面,我们使用了 max aggregation 来获取每个 terms 桶里最大的一个时间,并按照这个时间进行排序。
上面显示的结果为:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"by_user" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "peter@example.org",
"doc_count" : 2,
"total" : {
"value" : 5.0
},
"name" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 1,
"buckets" : [
{
"key" : "Peter Parker",
"doc_count" : 1,
"latest" : {
"value" : 1.6144704E12,
"value_as_string" : "2021-02-28T00:00:00.000Z"
}
}
]
}
},
{
"key" : "other@example.org",
"doc_count" : 4,
"total" : {
"value" : 4.0
},
"name" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 2,
"buckets" : [
{
"key" : "Someone Other",
"doc_count" : 2,
"latest" : {
"value" : 1.6144704E12,
"value_as_string" : "2021-02-28T00:00:00.000Z"
}
}
]
}
},
{
"key" : "paul@example.org",
"doc_count" : 1,
"total" : {
"value" : 4.0
},
"name" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Paul Paulinson",
"doc_count" : 1,
"latest" : {
"value" : 1.6121376E12,
"value_as_string" : "2021-02-01T00:00:00.000Z"
}
}
]
}
},
{
"key" : "peter@otherexample.org",
"doc_count" : 1,
"total" : {
"value" : 3.0
},
"name" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Peter Parker",
"doc_count" : 1,
"latest" : {
"value" : 1.6132608E12,
"value_as_string" : "2021-02-14T00:00:00.000Z"
}
}
]
}
}
]
}
}
}

















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









