






 本文介绍Grok语言的基础知识及应用案例,包括如何利用Grok解析不同类型的日志文件,如Syslog、Apache访问日志等,并提供Grok模式示例及调试技巧。
本文介绍Grok语言的基础知识及应用案例,包括如何利用Grok解析不同类型的日志文件,如Syslog、Apache访问日志等,并提供Grok模式示例及调试技巧。
如果没有日志解析,搜索和可视化日志几乎是不可能的。 解析结构化您的传入(非结构化)日志,以便用户可以在调查期间或设置仪表板时搜索清晰的字段和值。
最流行的日志解析语言是 Grok。 你可以使用 Grok 插件在各种日志管理和分析工具中解析日志数据。 在这里查看我的 Grok 教程 “Logstash:Grok filter 入门”。
但是用 Grok 解析日志可能会很棘手。 本博客将研究一些 Grok 模式示例,这些示例可以帮助你了解如何解析日志数据。
Logstash 日志解析的 Grok 模式示例
Logstash 日志解析的 Grok 模式示例_哔哩哔哩_bilibili
什么是 grok?
最初的术语实际上是相当新的——由 Robert A. Heinlein 在他 1961 年的《陌生土地上的陌生人》一书中创造 — 它指的是理解某事到一个人真正沉浸在其中的水平。 它是 grok 语言和 Logstash grok 插件的合适名称,它以一种格式修改信息并将其浸入另一种格式(特别是 JSON)中。 已经有几百种可被日志解析所使用的 Grok 模式。
Grok 是如何工作的?
简而言之,grok 是一种将行与正则表达式匹配、将行的特定部分映射到专用字段并基于此映射执行操作的方法。
内置有 200 多种 Logstash 模式,用于过滤 AWS、Bacula、Bro、Linux-Syslog 等中的单词、数字和日期等项目。 如果找不到你需要的模式,你可以编写自己的自定义模式。 还有多个匹配模式的选项,这简化了表达式的编写以捕获日志数据。
以下是 Logstash grok 过滤器的基本语法格式:
%{SYNTAX:SEMANTIC}SYNTAX 将指定每个日志文本中的模式。 SEMANTIC 将是你在已解析日志中实际给出该语法的识别标记。 换一种说法:
%{PATTERN:FieldName}这将匹配预定义的模式并将其映射到特定的识别字段。
例如,像 127.0.0.1 这样的模式将匹配 Grok IP 模式,通常是 IPv4 模式。
Grok 具有独立的 IPv4 和 IPv6 模式,但它们可以与语法 IP 一起过滤。
该标准模式如下:
IPV4 (?<![0-9])(?:(?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2}))(?![0-9])假装没有统一的 IP 语法,你可以简单地用相同的语义字段名称来理解两者:
%{IPv4:Client IP} %{IPv6:Client IP}同样,只需使用 IP 语法,除非出于任何原因要将这些各自的地址分隔到单独的字段中。
由于 grok 本质上是基于正则表达式的组合,因此你还可以使用以下模式创建自己的自定义基于正则表达式的 grok 过滤器:
(?<custom_field>custom pattern)例如:
(?\d\d-\d\d-\d\d)此 grok 模式会将 22-22-22(或任何其他数字)的正则表达式与字段名称匹配。
Logstash Grok 模式例子
为了演示如何开始使用 grok,我将使用以下应用程序日志:
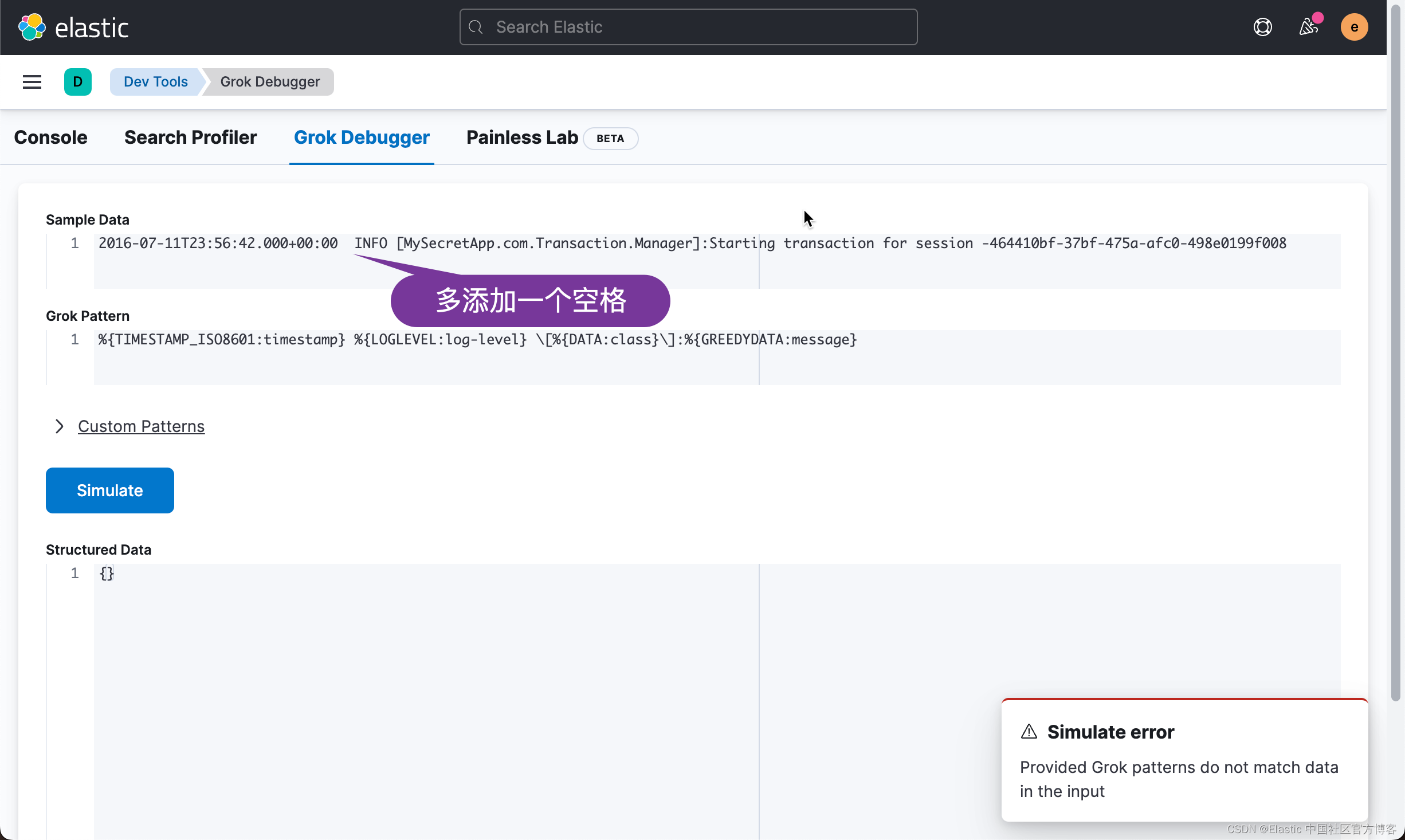
2016-07-11T23:56:42.000+00:00 INFO [MySecretApp.com.Transaction.Manager]:Starting transaction for session -464410bf-37bf-475a-afc0-498e0199f008
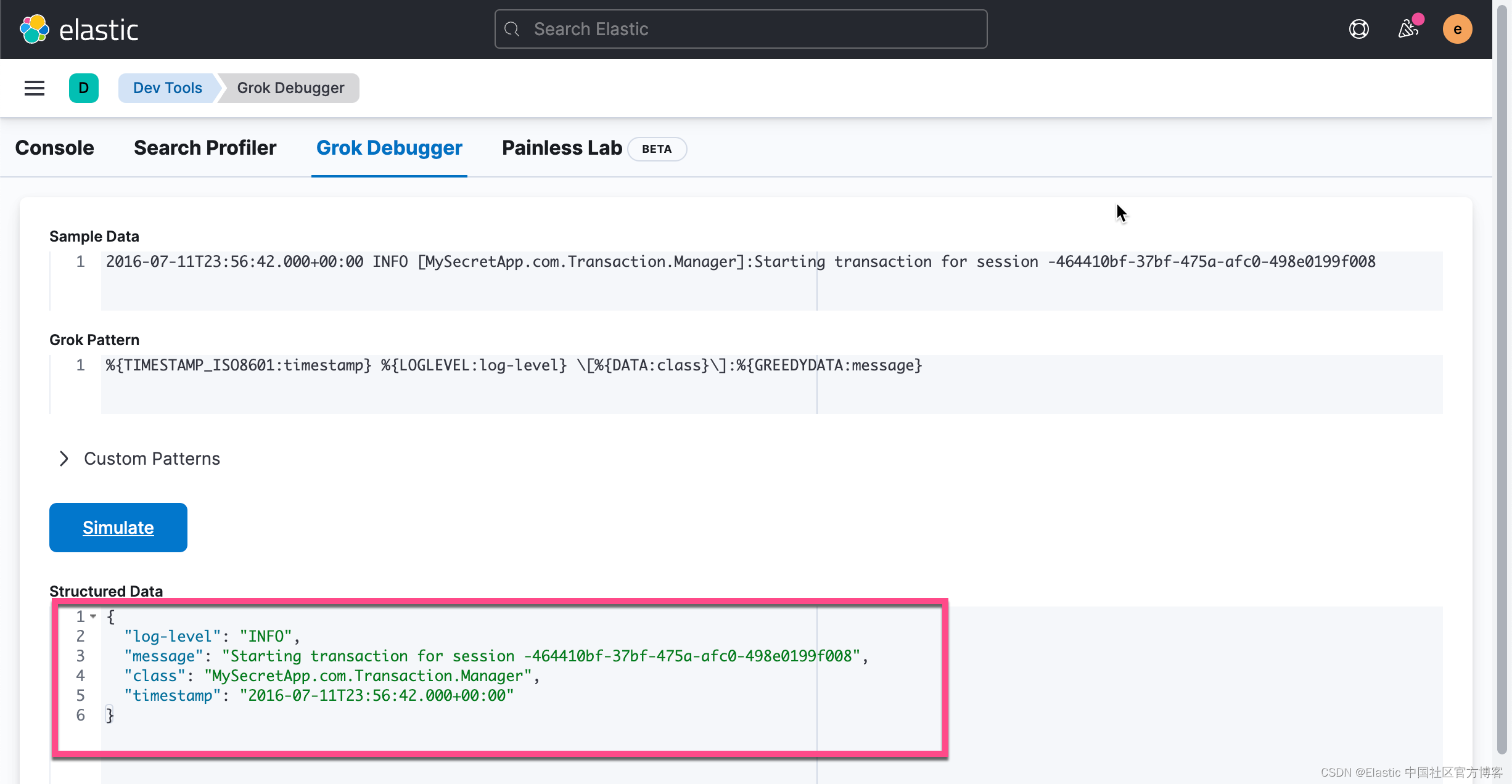
我想用 grok 过滤器实现的目标是将日志线分解为以下字段:timestamp、log level、class,然后是 message 的其余部分。
以下 grok 模式将完成这项工作:
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:log-level} \[%{DATA:class}\]:%{GREEDYDATA:message}" }
}在开发的过程中,很多开发者自己不知道如何测试。在 Kibana 中,它含有一个 grok debugger:
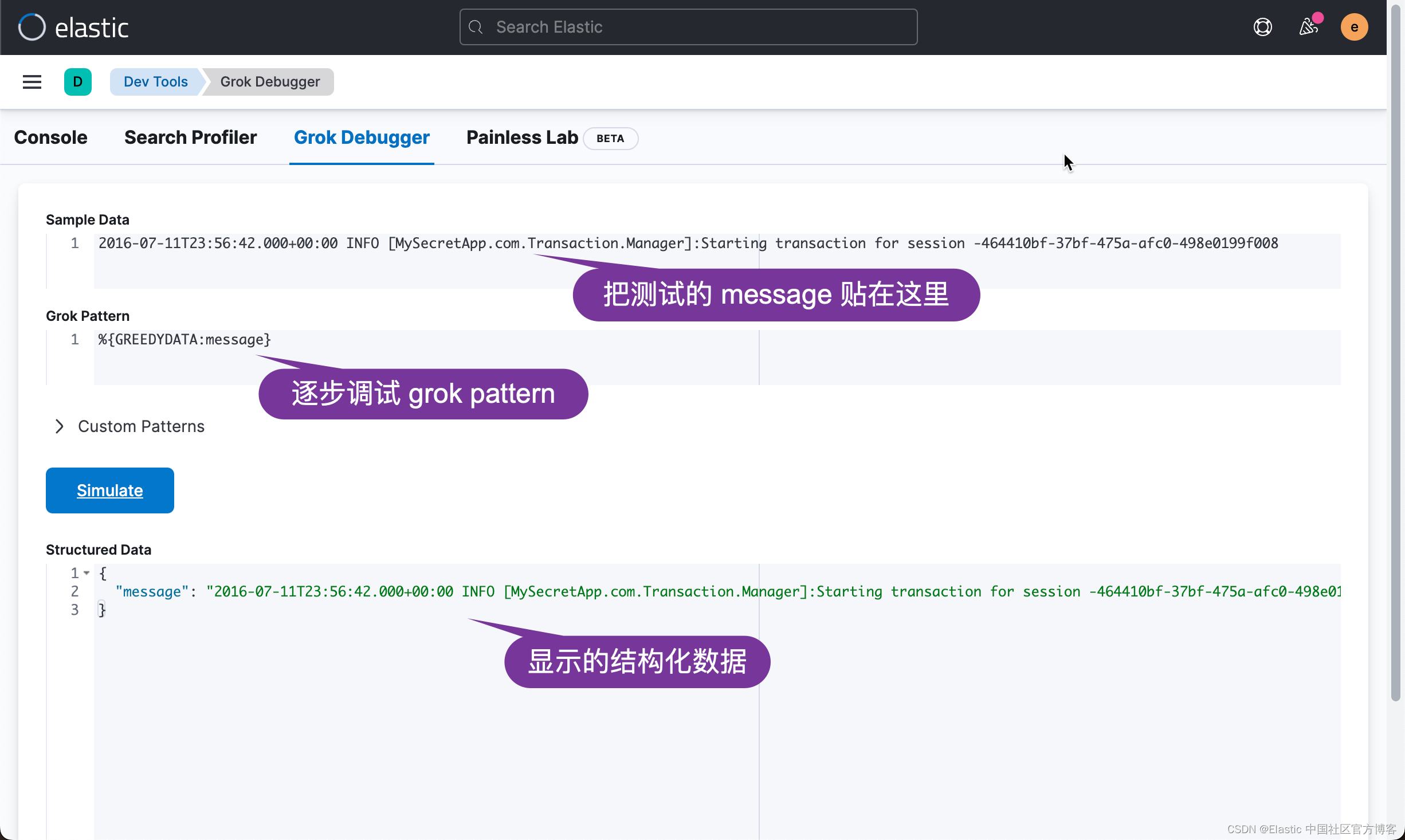
如上所示,我们使用 %{GREEDYDATA:message} 把所有的信息都映射到 message 字段中。如果熟悉英文的开发者,greedy 也就是贪婪的意思。它可以把剩余的所有内容都映射为该字段。
我们可以逐步添加 grok pattern:
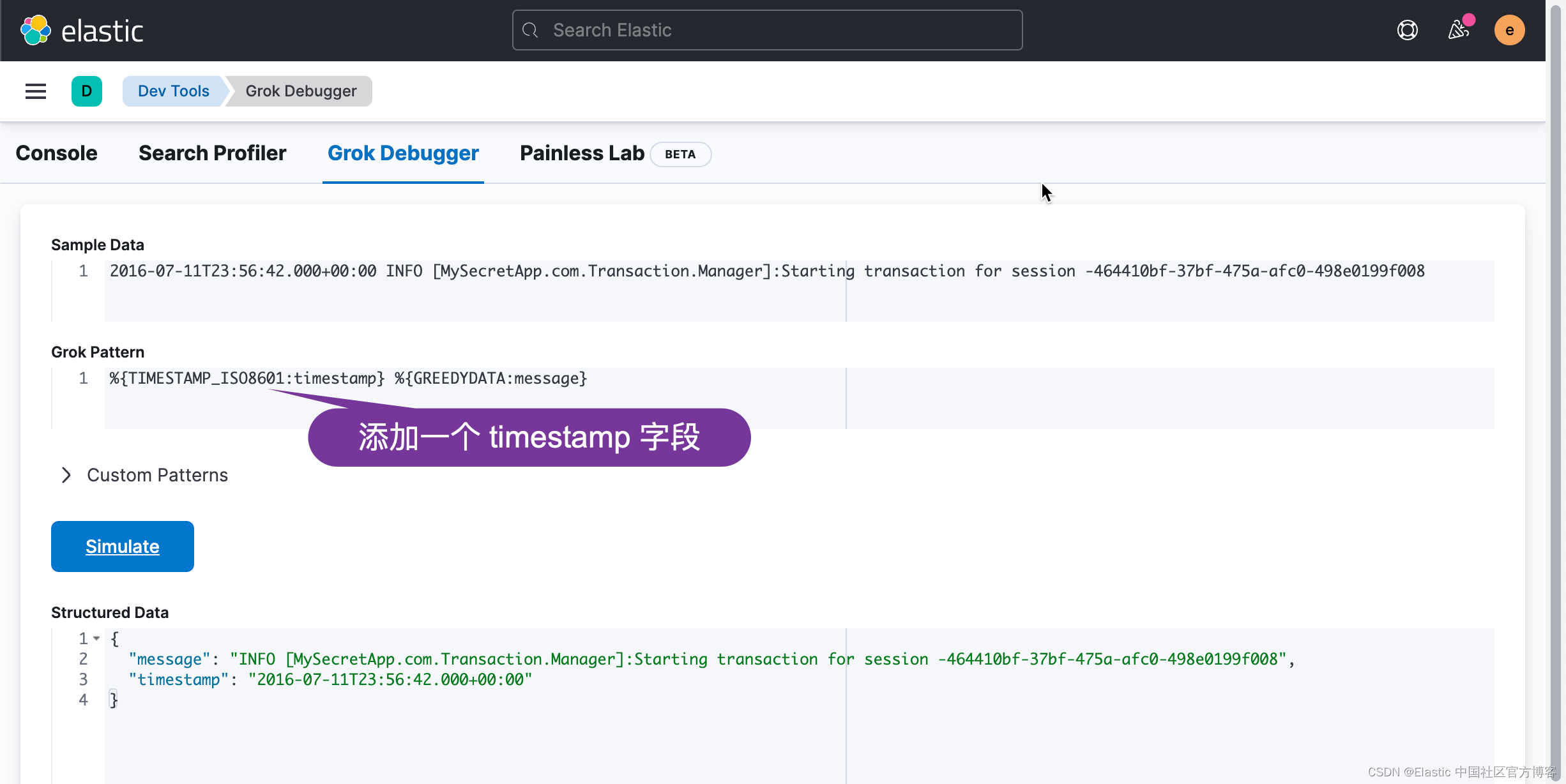
从上面,我们可以看出来,在 structured data 里,它增加了一个新的 timestamp 字段。我们接着修改 grok pattern:
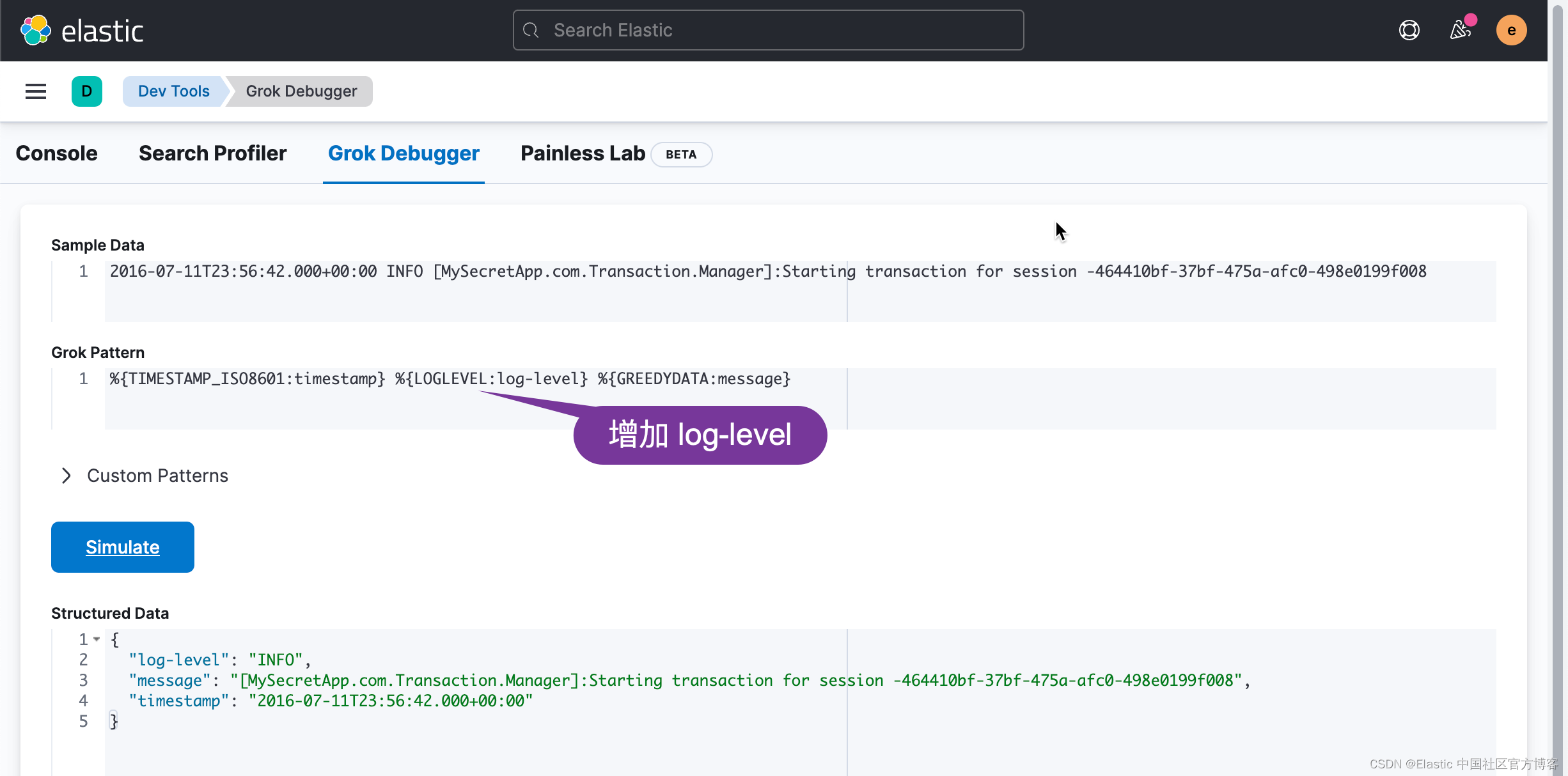
经过上面的修改,我们可以看到一个新增加的 log-level 字段。如法炮制,我们最终得到如下的所有字段:
Grok 数据类型转换
默认情况下,所有 SEMANTIC 条目都是字符串,但你可以使用简单的公式翻转数据类型。 以下 Logstash grok 示例将标识为语义 num 的任何语法 NUMBER 转换为语义浮点数 float:
%{NUMBER:num:float}这是一个非常有用的工具,尽管它目前仅可用于转换为 float 或整数 int。
_grokparsefailure
这将尝试将传入日志与给定的 grok 模式匹配。 如果匹配,日志将根据过滤器中定义的 grok 模式分解为指定的字段。 如果不匹配,Logstash 将添加一个名为 _grokparsefailure 的标签。
操作数据
在匹配的基础上,你可以定义额外的 Logstash grok 配置来操作数据。 例如,你可以让 Logstash 1) 添加字段,2) 覆盖字段,或 3) 删除字段。
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:log-level} \[%{DATA:class}\]:%{GREEDYDATA:message}" }
overwrite => ["message"]
add_tag => [ "My_Secret_Tag" ]
}在我们的例子中,我们使用 “overwrite” 操作来覆盖 “message” 字段。 这样,我们的 “message” 字段将不会与我们定义的其他字段(timestamp、log-level 和 class)一起出现。 此外,我们正在使用 “add_tag” 操作将自定义标签字段添加到日志中。
此处提供了可用于操作日志的可用操作的完整列表,以及它们的输入类型和默认值。
常见的 Logstash grok 示例
以下是一些示例,可帮助你熟悉如何构建 grok 过滤器:
Syslog
使用 Grok 解析 syslog 消息是新用户更常见的需求之一。 syslog 也有几种不同的日志格式,因此请牢记编写自己的自定义 grok 模式。 下面是一个常见的 syslog 解析示例:
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp}
%{SYSLOGHOST:syslog_hostname}
%{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?:
%{GREEDYDATA:syslog_message}" }
}如果你使用的是 rsyslog,则可以将后者配置为将日志发送到 Logstash。
Apache access logs
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}Elasticsearch
grok {
match => ["message", "\[%{TIMESTAMP_ISO8601:timestamp}\]\[%{DATA:loglevel}%{SPACE}\]\[%{DATA:source}%{SPACE}\]%{SPACE}\[%{DATA:node}\]%{SPACE}\[%{DATA:index}\] %{NOTSPACE} \[%{DATA:updated-type}\]",
"message", "\[%{TIMESTAMP_ISO8601:timestamp}\]\[%{DATA:loglevel}%{SPACE}\]\[%{DATA:source}%{SPACE}\]%{SPACE}\[%{DATA:node}\] (\[%{NOTSPACE:Index}\]\[%{NUMBER:shards}\])?%{GREEDYDATA}"
]
}Redis
grok {
match => ["redistimestamp", "\[%{MONTHDAY} %{MONTH} %{TIME}]",
["redislog", "\[%{POSINT:pid}\] %{REDISTIMESTAMP:timestamp}"],
["redismonlog", "\[%{NUMBER:timestamp} \[%{INT:database} %{IP:client}:%{NUMBER:port}\] "%{WORD:command}"\s?%{GREEDYDATA:params}"]
]
}MogoDB
MONGO_LOG %{SYSLOGTIMESTAMP:timestamp} \[%{WORD:component}\] %{GREEDYDATA:message}MONGO_QUERY \{ (?<={ ).*(?= } ntoreturn:) \}MONGO_SLOWQUERY %{WORD} %{MONGO_WORDDASH:database}\.%{MONGO_WORDDASH:collection} %{WORD}: %{MONGO_QUERY:query} %{WORD}:%{NONNEGINT:ntoreturn} %{WORD}:%{NONNEGINT:ntoskip} %{WORD}:%{NONNEGINT:nscanned}.*nreturned:%{NONNEGINT:nreturned}..+ (?<duration>[0-9]+)msMONGO_WORDDASH \b[\w-]+\bMONGO3_SEVERITY \wMONGO3_COMPONENT %{WORD}|-MONGO3_LOG %{TIMESTAMP_ISO8601:timestamp} %{MONGO3_SEVERITY:severity} %{MONGO3_COMPONENT:component}%{SPACE}(?:\[%{DATA:context}\])? %{GREEDYDATA:message}AWS
ELB_ACCESS_LOG %{TIMESTAMP_ISO8601:timestamp} %{NOTSPACE:elb} %{IP:clientip}:%{INT:clientport:int} (?:(%{IP:backendip}:?:%{INT:backendport:int})|-) %{NUMBER:request_processing_time:float} %{NUMBER:backend_processing_time:float} %{NUMBER:response_processing_time:float} %{INT:response:int} %{INT:backend_response:int} %{INT:received_bytes:int} %{INT:bytes:int} "%{ELB_REQUEST_LINE}"CLOUDFRONT_ACCESS_LOG (?<timestamp>%{YEAR}-%{MONTHNUM}-%{MONTHDAY}\t%{TIME})\t%{WORD:x_edge_location}\t(?:%{NUMBER:sc_bytes:int}|-)\t%{IPORHOST:clientip}\t%{WORD:cs_method}\t%{HOSTNAME:cs_host}\t%{NOTSPACE:cs_uri_stem}\t%{NUMBER:sc_status:int}\t%{GREEDYDATA:referrer}\t%{GREEDYDATA:agent}\t%{GREEDYDATA:cs_uri_query}\t%{GREEDYDATA:cookies}\t%{WORD:x_edge_result_type}\t%{NOTSPACE:x_edge_request_id}\t%{HOSTNAME:x_host_header}\t%{URIPROTO:cs_protocol}\t%{INT:cs_bytes:int}\t%{GREEDYDATA:time_taken:float}\t%{GREEDYDATA:x_forwarded_for}\t%{GREEDYDATA:ssl_protocol}\t%{GREEDYDATA:ssl_cipher}\t%{GREEDYDATA:x_edge_response_result_type}总结
Logstash grok 只是一种过滤器,可以在将日志转发到 Elasticsearch 之前将其应用于你的日志。 因为它在日志管道中扮演着如此重要的角色,所以 grok 也是最常用的过滤器之一。
以下是一些有用的资源列表,可以帮助你深入了解:
- http://grokdebug.herokuapp.com – 这是在日志上构建和测试 grok 过滤器的有用工具
- http://grokconstructor.appspot.com/ – 另一个 grok builder/tester
- https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns – Logstash 支持的模式列表


















 1832
1832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









