









作者:来自 Elastic Jim Ferenczi
第 1 部分:高保真密集向量搜索
简介
在设计向量搜索体验时,可用选项的数量之多可能会让人感到不知所措。最初,管理少量向量很简单,但随着应用程序的扩展,这很快就会成为瓶颈。
在本系列博文中,我们将探讨使用 Elasticsearch 在各种数据集和用例中运行大规模向量搜索的成本和性能。
我们从最大的公开可用向量数据集之一开始本系列:Cohere/msmarco-v2-embed-english-v3。该数据集包括从 MSMARCO-passage-v2 集合中的网页中提取的 1.38 亿个段落,使用 Cohere's latest embed-english-v3 model 嵌入到 1024 个维度中。
对于这个实验,我们定义了一个可重现的轨道(track),你可以在自己的 Elastic 部署上运行它,以帮助你对自己的高保真密集向量搜索体验进行基准测试。
它专为实时搜索用例量身定制,其中单个搜索请求的延迟必须很低(<100ms)。它使用我们的开源工具 Rally 对 Elasticsearch 版本进行基准测试。
在本文中,我们对浮点向量使用默认的自动量化。这将运行向量搜索的 RAM 成本降低了 75%,而不会影响检索质量。我们还提供了在索引数十亿个维度时合并和量化的影响的见解。
我们希望此轨迹可以作为有用的基准,特别是如果你手头没有特定于你的用例的向量。
关于嵌入的注释
选择适合你需求的正确模型超出了本博客文章的范围,但在下一节中,我们将讨论压缩向量原始大小的不同技术。
Matryoshka Representation Learning (MRL)
通过将最重要的信息存储在较早的维度中,Matryoshka 嵌入等新方法可以缩小维度,同时保持良好的搜索准确性。使用这种技术,某些模型的大小可以减半,并且在 MTEB 检索基准上仍保持 90% 的 NDCG@10。但是,并非所有模型都兼容。如果你选择的模型未针对 Matryoshka 缩减进行训练,或者其维数已经处于最小值,则你必须直接在向量数据库中管理维数。
幸运的是,mixedbread 或 OpenAI 的最新模型内置了对 MRL 的支持。
对于这个实验,我们选择专注于维数固定(1024 个维度)的用例,使用其他模型的维数将是另一个话题。
嵌入量化学习
模型开发人员现在通常提供具有各种权衡的模型来解决高维向量的费用问题。这些模型不是仅仅关注降维,而是通过调整每个维度的精度来实现压缩。
通常,嵌入模型被训练为使用 32 位浮点生成维度。但是,训练它们以降低精度生成维度有助于最大限度地减少错误。开发人员通常会发布针对众所周知的精度优化的模型,这些精度与编程语言中的本机类型直接一致。
例如,int8 表示一个有符号整数,范围从 -127 到 127,而 uint8 表示一个无符号整数,范围从 0 到 255。二进制是最简单的形式,表示一位(0 或 1),对应于每个维度的最小可能单位。
在训练期间实施量化可以微调模型权重,以最大限度地减少压缩对检索性能的影响。但是,深入研究训练此类模型的细节超出了本博客的范围。
在下一节中,我们将介绍一种在所选模型缺少此功能时应用自动量化的方法。
自适应嵌入量化
在模型缺乏量化感知嵌入的情况下,Elasticsearch 采用自适应量化方案,默认将浮点量化为 int8。
这种通用的 int8 量化通常会导致可忽略不计的性能损失。这种量化的好处在于它对数据漂移的适应性。
它采用动态方案,可以不时重新计算量化边界以适应数据中的任何变化。
大规模基准测试
粗略估计
MSMARCO-v2 数据集包含 1.383 亿个文档和 1024 维向量,用于存储原始浮点向量的原始大小超过 520GB。使用强力搜索(brute force)整个数据集在单个节点上需要数小时。
幸运的是,Elasticsearch 提供了一种称为 HNSW(hierachical navigable small world graph - 分层可导航小世界图)的数据结构,旨在加速最近邻搜索(nearest neighbor search)。此结构允许快速近似最近邻搜索,但要求每个向量都位于内存中。
从磁盘加载这些向量的成本非常高,因此我们必须确保系统有足够的内存将它们全部保存在内存中。
每个向量有 1024 个维度,每个维度 4 字节,因此每个向量需要 4 千字节的内存。
此外,我们还需要考虑将分层可导航小世界 (HNSW) 图加载到内存中所需的内存。在图中每个节点的默认设置为 32 个邻居的情况下,每个向量需要额外的 128 字节(每个邻居 4 字节)内存来存储图,这相当于存储向量维度内存成本的约 3%。
确保有足够的内存来满足这些要求对于实现最佳性能至关重要。
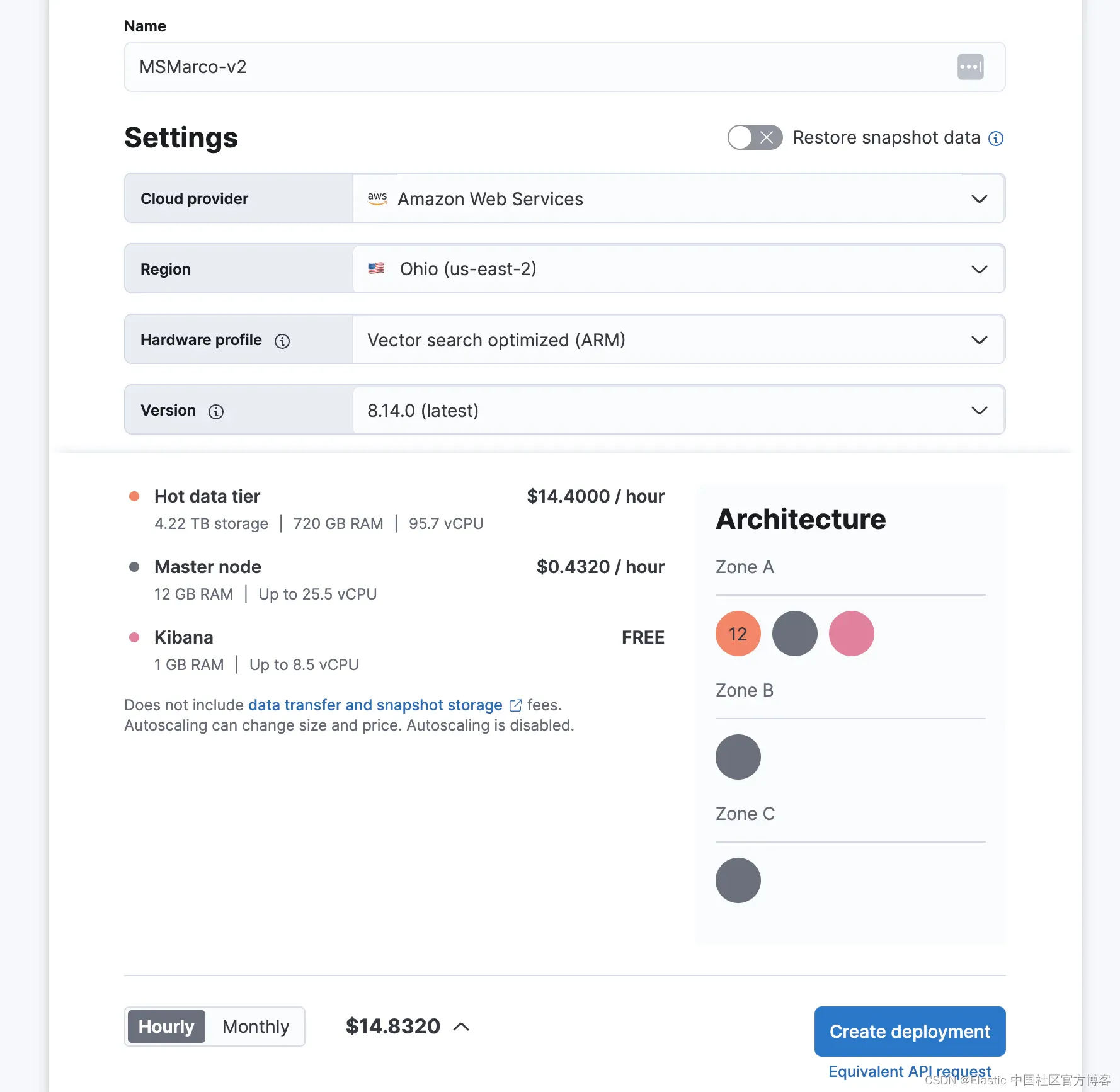
在 Elastic Cloud 上,我们的向量搜索优化配置文件为 JVM(Java 虚拟机)保留了总节点内存的 25%,每个数据节点上 75% 的内存可用于加载向量的系统页面缓存。对于具有 60GB RAM 的节点,这相当于 45GB 的页面缓存可用于向量。向量搜索优化配置文件适用于所有云解决方案提供商 (CSP) AWS、Azure 和 GCP。
为了满足所需的 520GB 内存,我们需要 12 个节点,每个节点具有 60GB RAM,总计 720GB。
在撰写本文时,此设置可部署在我们的 Cloud 环境中,AWS 上的总成本为每小时 14.44 美元:(请注意,Azure 和 GCP 环境的价格会有所不同):
通过利用自动量化到字节,我们可以将内存需求减少到 130gb,这仅仅是原始大小的四分之一。
应用相同的 25/75 内存分配规则,我们可以在 Elastic Cloud 上分配总共 180 gb 的内存。
在撰写本博客时,此优化设置在 Elastic Cloud 上的总成本为每小时 3.60 美元(请注意,Azure 和 GCP 环境的价格会有所不同)
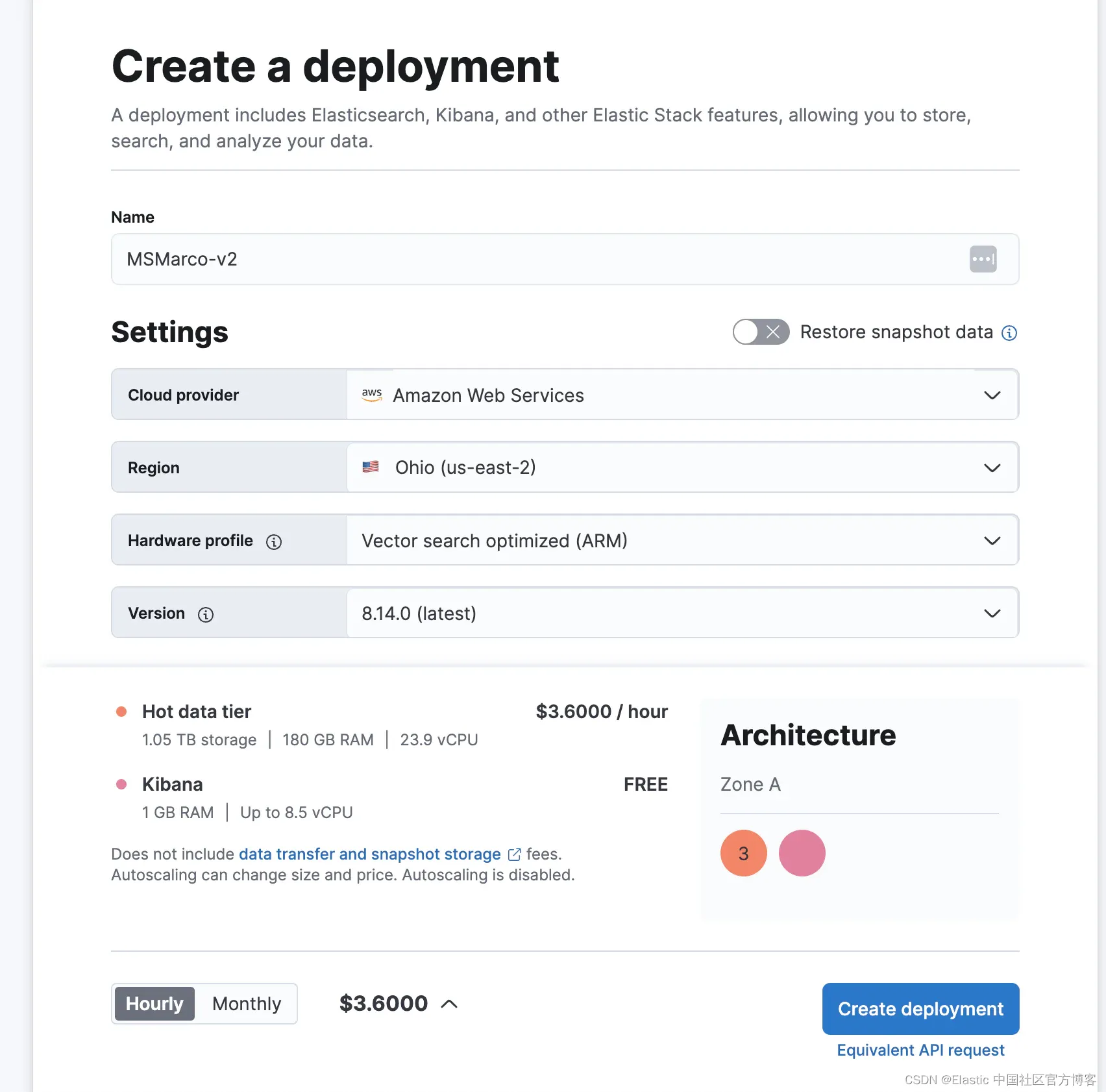
在 Elastic Cloud 上开始免费试用,只需选择新的 Vector Search 优化配置文件即可开始使用。
在这篇文章中,我们将使用我们为试验大规模向量搜索性能而创建的基准来探索这种经济高效的量化。通过这样做,我们旨在展示如何在保持高搜索准确性和效率的同时实现显着的成本节省。
基准测试配置
msmarco-v2-vector rally track 定义了将要使用的默认映射。
它包括一个具有 1024 个维度的密集向量字段,使用自动 int8 量化进行索引,以及一个关键字类型的 doc_id 字段,用于唯一标识每个段落。
对于此实验,我们测试了两种配置:
- 默认(default):这作为基线,使用 Elasticsearch 上的默认选项的赛道。
- 积极合并(aggressive merge):此配置提供了一个具有不同权衡的比较点。
如前所述,Elasticsearch 中的每个分片都由段组成。段是数据的不可变部分,包含直接查找和搜索数据的必要结构。
文档索引涉及在内存中创建段,这些段会定期刷新到磁盘。
为了管理段的数量,后台进程会合并段以将总数保持在一定预算以下。
这种合并策略对于向量搜索至关重要,因为 HNSW 图在每个段内都是独立的。每个密集向量字段搜索都涉及在每个段中查找最近的邻居,这使得总成本取决于段的数量。
默认情况下,Elasticsearch 合并大小大致相等的段,遵循由每个层允许的段数控制的分层策略。
此设置的默认值为 10,这意味着每个级别不应有超过 10 个大小相似的段。例如,如果第一级包含 50MB 的段,则第二级将包含 500MB 的段,第三级将包含 5GB 的段,依此类推。
积极合并配置将默认设置调整为更积极:
- 它将每个层的段设置为 5,从而实现更积极的合并。
- 它将最大合并段大小从 5GB 增加到 25GB,以最大化单个段中的向量数量。
- 它将最低段大小设置为 1GB,人为地将第一级从 1GB 开始。
通过这种配置,我们期望搜索速度更快,但索引速度较慢。
对于此实验,我们在两种配置中都保留了 HNSW 图的 m、ef_construction 和 confidence_interval 选项的默认设置。对这些索引参数的实验将成为另一篇博客的主题。在第一部分中,我们选择专注于改变合并和搜索参数。
运行基准测试时,将负责发送文档和查询的负载驱动程序与评估系统(Elasticsearch 部署)分开至关重要。加载和查询数亿个密集向量需要额外的资源,如果一起运行,这些资源会干扰评估系统的搜索和索引功能。
为了最大限度地减少系统和负载驱动程序之间的延迟,建议在与 Elastic 部署相同的云提供商区域中运行负载驱动程序,最好在同一个可用区中。
对于此基准测试,我们在 AWS 上配置了一个 im4gn.4xlarge 节点,该节点与 Elastic 部署位于同一区域,具有 16 个 CPU、64GB 内存和 7.5TB 磁盘。此节点负责将查询和文档发送到 Elasticsearch。通过以这种方式隔离负载驱动程序,我们可以确保准确测量 Elasticsearch 的性能,而不会受到额外资源需求的干扰。
我们使用以下配置运行了整个基准测试:
"track.params": {
"mapping_type": "vectors-only",
"vector_index_type": "int8_hnsw",
"number_of_shards": 4,
"initial_indexing_bulk_indexing_clients": 12,
"standalone_search_clients": 8
}
initial_indexing_bulk_indexing_clients 值为 12 表示我们将使用 12 个客户端从负载驱动程序中提取数据。Elasticsearch 数据节点中总共有 23.9 个 vCPU,使用更多客户端发送数据可提高并行性,使我们能够充分利用部署中的所有可用资源。
对于搜索操作,standalone_search_clients 和 parallel_indexing_search_clients 值为 8 表示我们将使用 8 个客户端从负载驱动程序并行查询 Elasticsearch。最佳客户端数量取决于多种因素;在此实验中,我们选择了客户端数量以最大化所有 Elasticsearch 数据节点的 CPU 使用率。
为了比较结果,我们在同一个部署上运行了第二个基准测试,但这次我们将参数 assault_merge 设置为 true。这有效地将合并策略更改为更激进,使我们能够评估此配置对搜索性能和索引速度的影响。
索引性能
在 Rally 中,挑战配置了要执行和报告的计划操作列表。
每个操作负责针对集群执行操作并报告结果。
对于我们的新轨道(track),我们将第一个操作定义为初始文档索引,这涉及批量索引整个语料库。接下来是等待合并完成索引,等待批量加载过程结束时后台合并完成。
此操作不使用强制合并;它只是等待自然合并过程完成后再开始搜索评估。
下面,我们报告轨道这些操作的结果,它们对应于 Elasticsearch 中数据集的初始加载。搜索操作将在下一节中报告。
使用 Elasticsearch 8.14.0,138M 向量的初始索引花费了不到 5 个小时,平均每秒 8,000 个文档。
请注意,瓶颈通常是嵌入的生成,这里没有报告。
等待合并最后完成只增加了 2 分钟:

相比之下,在 Elasticsearch 8.13.4 上进行的相同实验需要近 6 个小时进行提取,另外还需要 2 个小时等待合并:

Elasticsearch 8.14.0 标志着首次利用原生代码进行向量搜索的版本。在合并期间使用原生 Elasticsearch 编解码器来加速 int8 向量之间的相似性,从而显著缩短总体索引时间。我们目前正在探索通过使用此自定义编解码器进行搜索的进一步优化,敬请期待更新!
积极的合并运行在不到 6 小时内完成,平均每秒 7,000 个文档。但是,需要等待近一个小时才能完成合并。与使用默认合并策略的运行相比,速度降低了 40%:
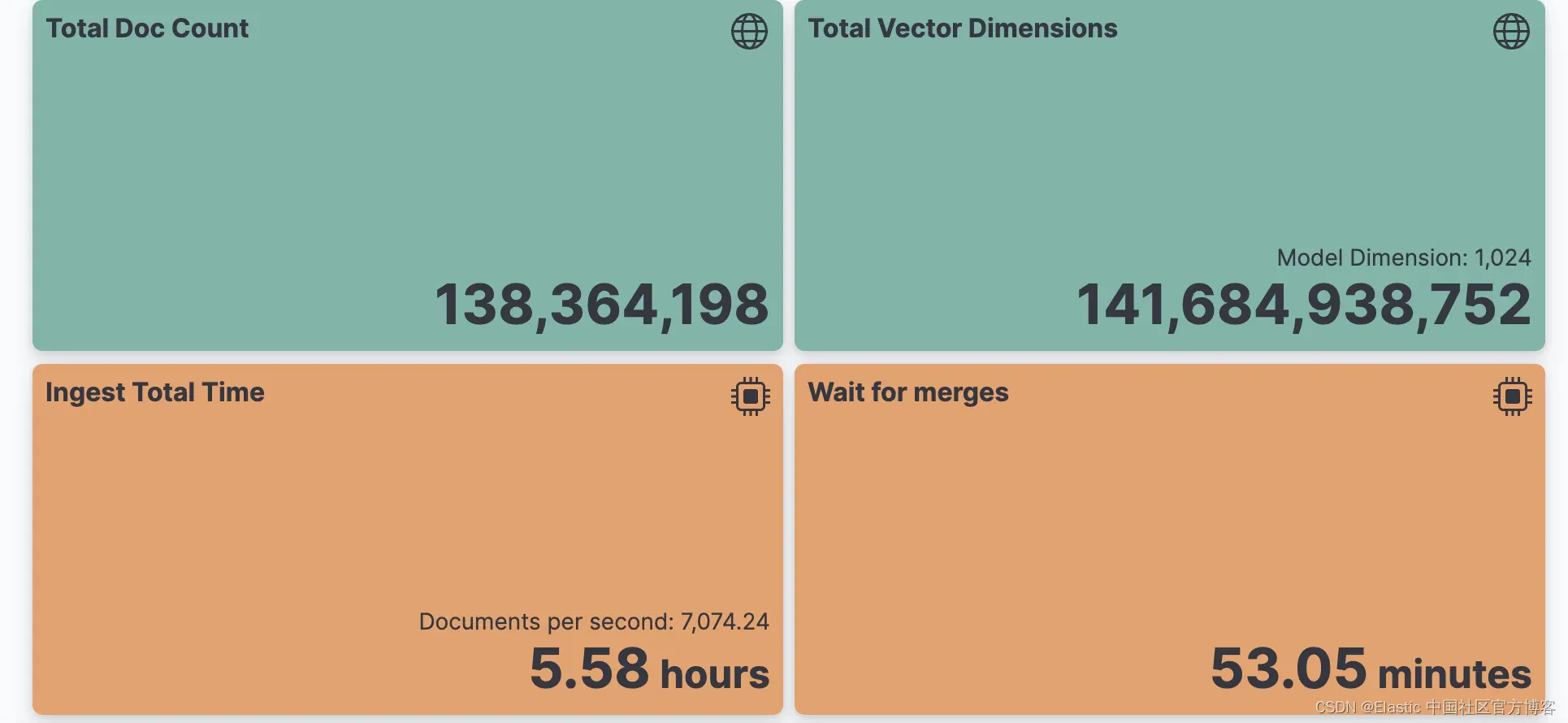
积极合并配置执行的额外工作可总结在下面的两个图表中。
积极合并配置合并了 2.7 倍的文档,以创建更大且更少的段。默认合并配置报告从索引的 1.38 亿个文档中合并了近 3 亿个文档。这意味着每个文档平均合并 2.2 次。
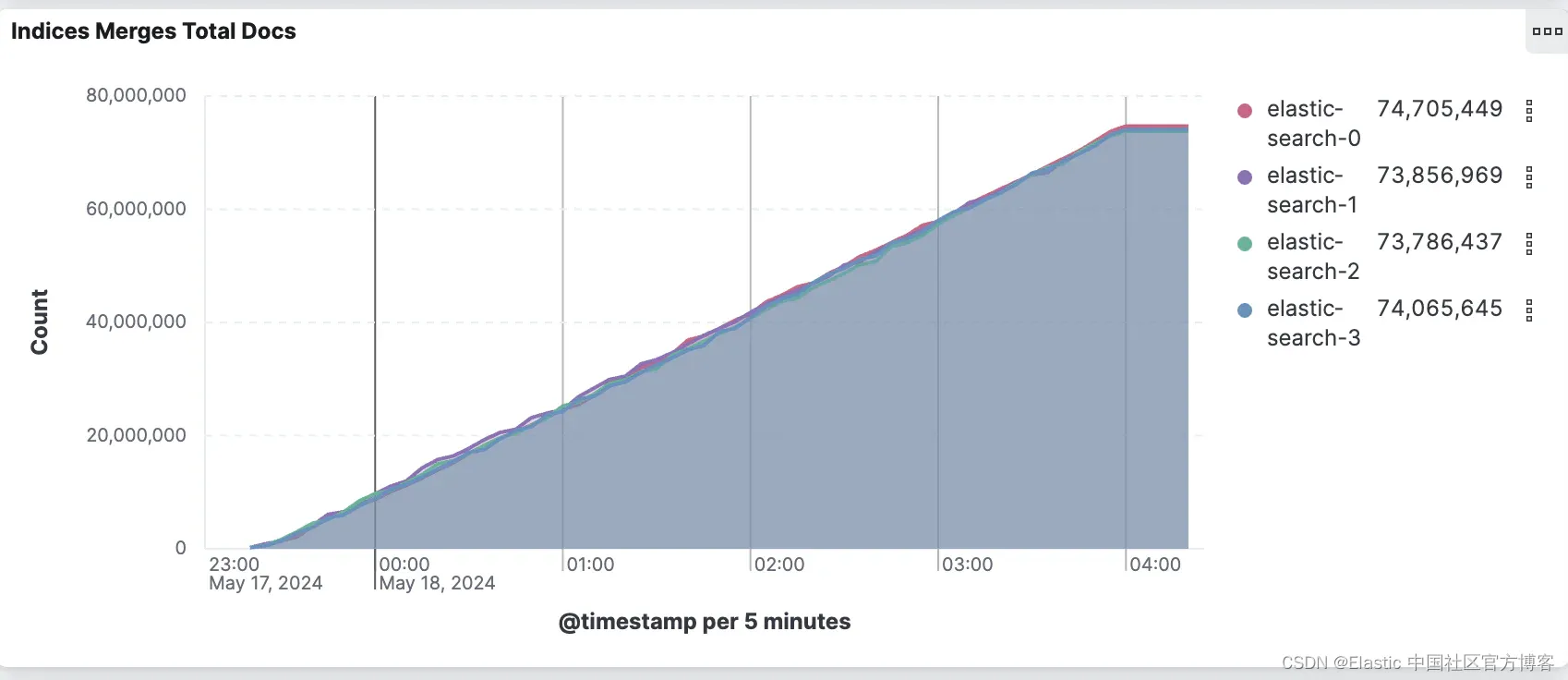
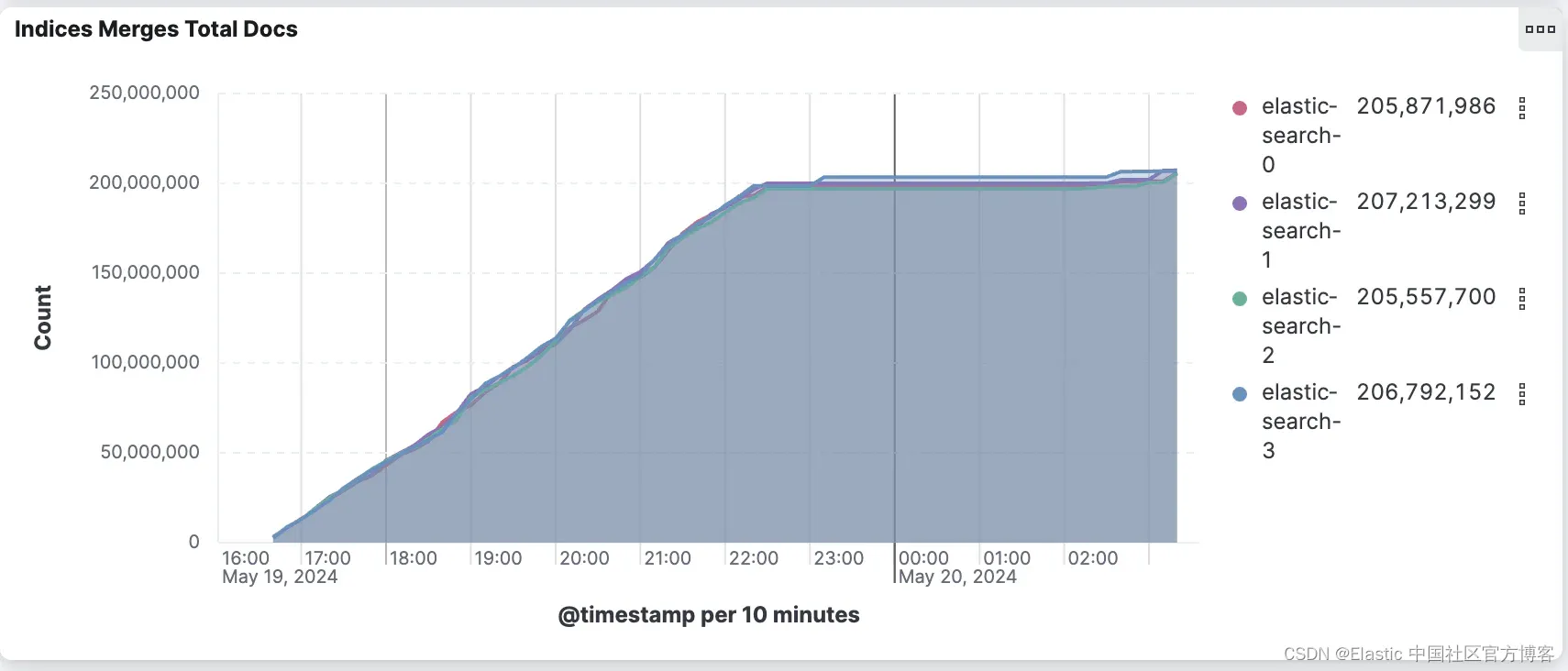
在下一节中,我们将分析这些配置对搜索性能的影响。
搜索评估
对于搜索操作,我们的目标是捕获两个关键指标:最大查询吞吐量和近似最近邻搜索的准确度。
为了实现这一点,standalone-search-knn-* 操作使用各种近似搜索参数组合来评估最大搜索吞吐量。此操作涉及使用 parallel_indexing_search_clients 尽可能快速地并行执行来自训练集的 10,000 个查询。这些操作旨在利用节点上所有可用的 CPU,并在所有索引和合并任务完成后执行。
为了评估每个组合的准确性,knn-recall-* 操作计算相关的召回率和标准化折扣累积收益 (Normalized Discounted Cumulative Gain - nDCG)。nDCG 是根据 msmarco-passage-v2/trec-dl-2022/judged 中发布的 76 个查询计算得出的,使用了 386,000 个 qrels 注释。所有 nDCG 值的范围从 0.0 到 1.0,其中 1.0 表示完美排名。
由于数据集的大小,生成真实结果来计算召回率的成本极高。因此,我们将召回率报告限制为测试集中的 76 个查询,我们使用强力方法离线计算了这些查询的真实结果。
搜索配置包含三个参数:
- k:要返回的段落数(passages)。
- num_candidates:用于限制在最近邻图上搜索的队列大小。
- num_rescore:使用全保真向量重新评分的段落数。
使用自动量化,使用原始浮点向量重新评分略多于 k 个向量可以显著提高召回率。
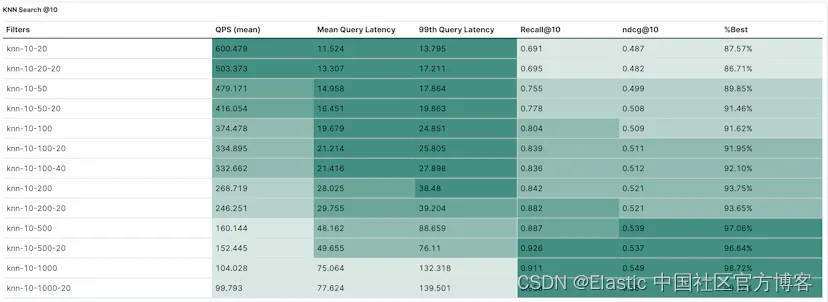
操作根据这三个参数命名。例如,knn-10-100-20 表示 k=10、num_candidates=100 和 num_rescore=20。如果省略最后一个数字,如 knn-10-100,则 num_rescore 默认为 0。
有关我们如何创建搜索请求的更多信息,请参阅 track.py 文件。
下图说明了不同召回率水平下的预期每秒查询数 (Queries Per Second - QPS)。例如,默认配置(橙色系列)可以实现 50 QPS,预期召回率为 0.922。
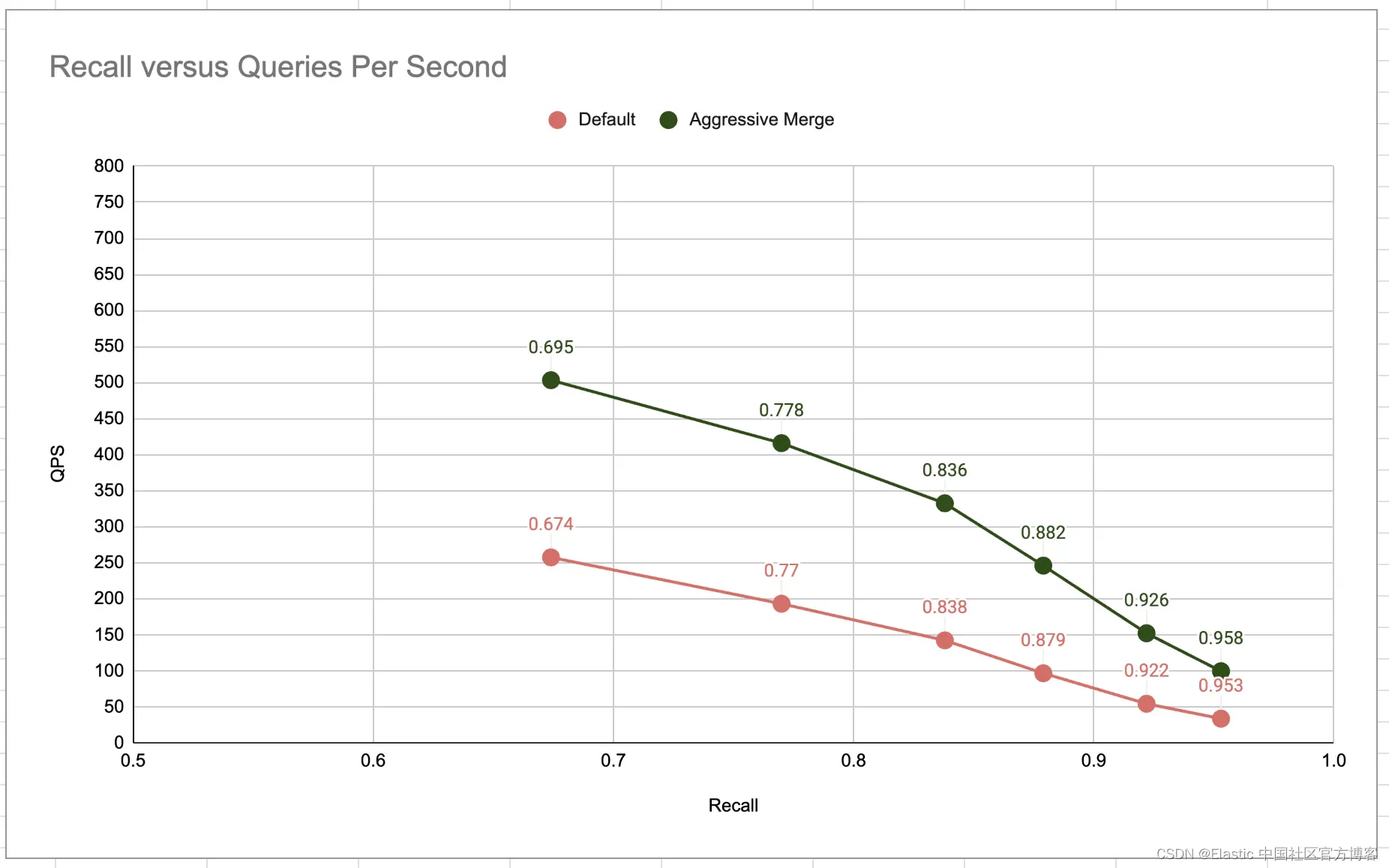
对于相同级别的召回率,激进合并配置的效率是后者的 2 到 3 倍。这种效率是意料之中的,因为搜索是在更大、更少的片段上进行的,如上一节所示。
默认配置的完整结果如下表所示:
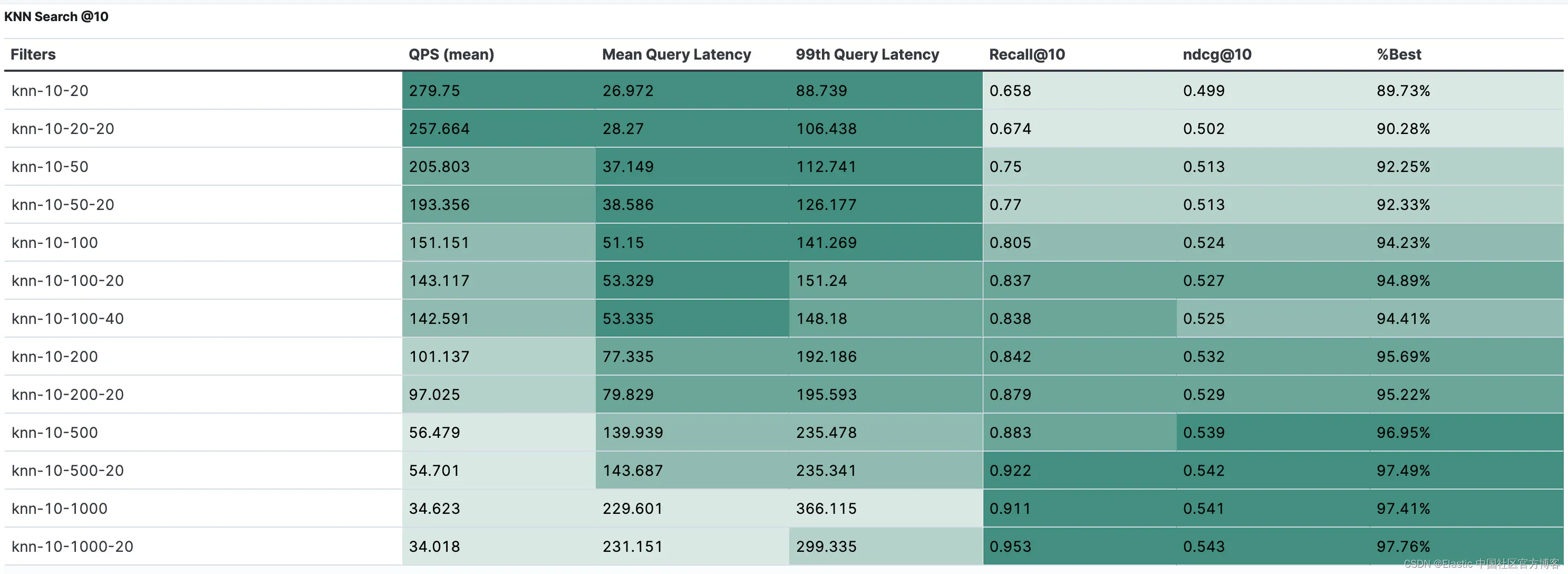
%best 列表示此配置的实际 NDCG@10 与最佳可能 NDCG@10 之间的差异,后者使用离线强力计算的地面实况最近邻确定。
例如,我们观察到,尽管 knn-10-20-20 配置的召回率为 67.4%,但它实现了此数据集最佳可能 NDCG 的 90%。请注意,这只是一个点结果,结果可能因其他模型和/或数据集而异。
下表显示了积极合并配置的完整结果:
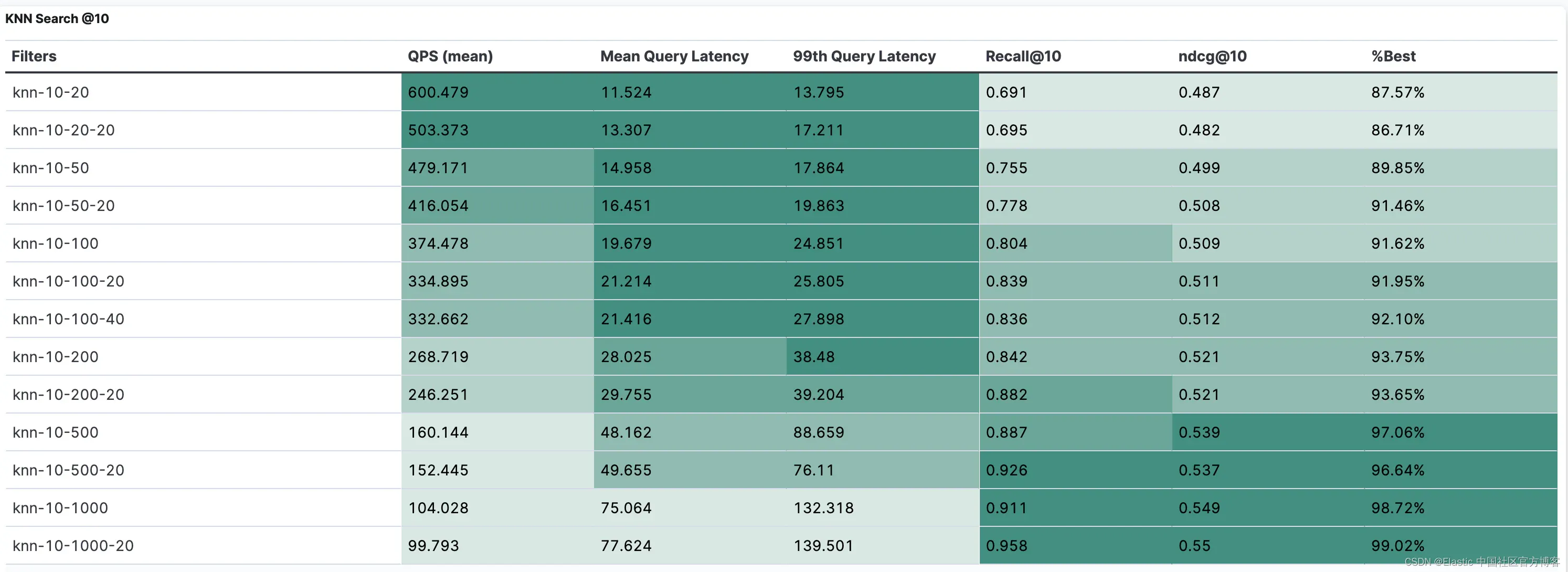
使用 knn-10-500-20 搜索配置,积极合并设置可以在 150 QPS 下实现 > 90% 的召回率。
结论
在这篇文章中,我们描述了一种新的 rally track,旨在对 Elasticsearch 上的大规模向量搜索进行基准测试。我们探讨了运行近似最近邻搜索所涉及的各种权衡,并展示了在 Elasticsearch 8.14 中,我们如何将成本降低 75%,同时将索引速度提高 50%,以实现真实的大规模向量搜索工作负载。
我们正在努力优化和寻找机会来增强我们的向量搜索功能。请继续关注本系列的下一篇文章,我们将在其中深入探讨向量搜索用例的成本和效率,特别是研究 int4 和二进制压缩技术的潜力。
通过不断改进我们的方法并发布用于大规模测试性能的工具,我们的目标是突破 Elasticsearch 的极限,确保它仍然是大规模向量搜索的强大且经济高效的解决方案。
准备好自己尝试一下了吗?开始免费试用。
Elasticsearch 集成了 LangChain、Cohere 等工具。加入我们的高级语义搜索网络研讨会,构建你的下一个 GenAI 应用程序!
原文:Elasticsearch vector search: Designing for large scale — Elastic Search Labs
















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









