









作者:来自 Elastic Andre Luiz

探索如何使用 Elasticsearch 中的分面(facet)搜索来快速缩小类别内的选项范围。
在本文中,我们将探讨人工智能(AI),特别是使用 GPT-4 等高级语言模型如何帮助创建更多情境方面,从而使它们对用户更加相关和有用。
Facet 搜索是电子商务平台中的一个强大工具。它有助于根据显示项目的特点来组织和优化搜索结果。尽管常常与过滤器混淆,但方面的工作方式不同。过滤器是固定属性,由索引中始终存在的信息定义,例如产品的类别或格式。另一方面,方面是动态的并且根据执行的搜索返回的结果生成。
想象一个服装目录:“类别”(例如,T 恤、裤子)或 “性别”(例如,男性、女性)等字段是帮助缩小结果范围的过滤器。然而,方面反映了结果中出现的产品的特定特征,例如常见颜色,可用尺寸或材料。这可以提供更具适应性和情境化的搜索体验。
下面是我们与某个分面进行交互并可以看到经它们过滤的搜索结果的图像。
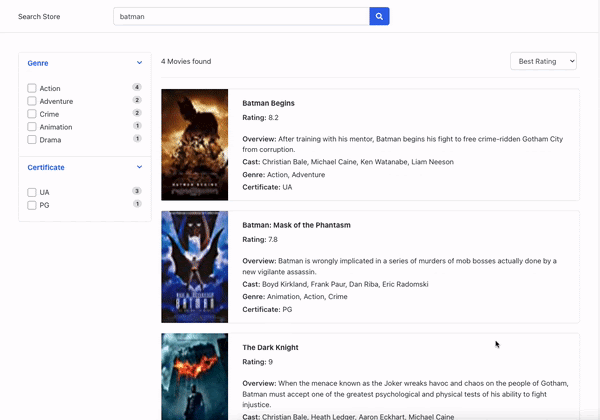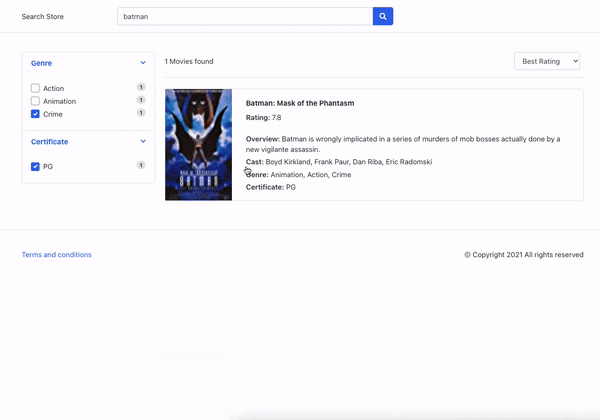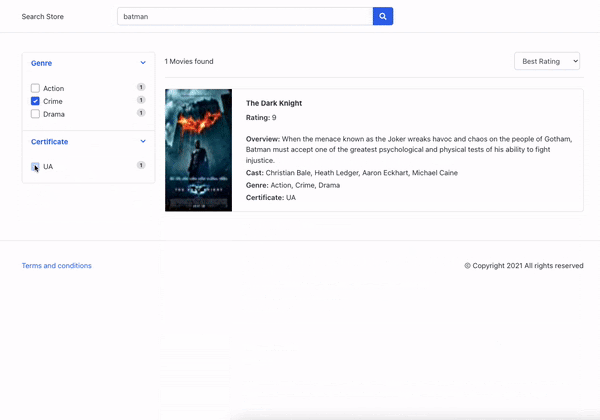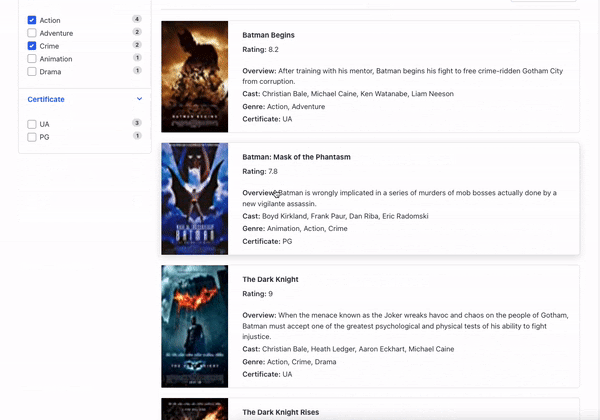
人工智能如何改善分面生成
人工智能通常与语义搜索和嵌入相关,但是分面又如何呢?如何利用人工智能使各个分面对于每次搜索来说更有用且更具针对性?
一个有趣的可能性是使用人工智能创建超越指标题一数中传统分类的新分类。通过分析内容的具体特征,这些新的类别可以提供更丰富、更精确的情境化,使方面更加相关并符合用户的需求。与原始文档类别相比,这使得结果的细化更加有意义。
人工智能如何改进电影分类以实现更好的搜索
让我们分析一下以下电影,它们目前都被归类为剧情类:
- 梦之安魂曲 - Requiem for a Dream
- 摘要:四个科尼岛人因吸毒而产生的乌托邦随着他们毒瘾的加深而破灭了 - The drug-induced utopias of four Coney Island people are shattered when their addictions run deep。
- 美国丽人 - American Beauty
- 摘要:一位性生活受挫的郊区父亲迷恋上他女儿最好的朋友后陷入了中年危机 - A sexually frustrated suburban father has a mid-life crisis after becoming infatuated with his daughter's best friend。
- 心灵捕手 - Good Will Hunting
- 摘要:麻省理工学院的清洁工威尔·亨廷有着数学天赋,但需要心理学家的帮助来找到人生方向 - Will Hunting, a janitor at M.I.T., has a gift for mathematics, but needs help from a psychologist to find direction in his life。
这种类型分类并没有捕捉到每部电影的细微差别或独特背景。通过利用人工智能分析概要和中心主题,我们可以创建更能反映每部电影真实背景的新类别。例如:
- 梦之安魂曲 —— 新类别:“成瘾与依赖 - Addiction and Dependency”
- 美国丽人 —— 新类别:“中年危机 - Mid-life Crisis”
- 心灵捕手 —— 新类别:“智力斗争 - Intellectual Struggle”
这些新的类别使搜索更加精确,同时为用户提供更有意义的过滤器来优化他们的搜索结果。当原始类别过于通用时,这种方法特别有效,使用户能够更轻松地找到他们正在寻找的内容。
使用 GPT-4 创建新类别:实际示例
在这个例子中,我们将展示如何使用人工智能模型创建更精确、更符合每部作品背景的新电影类别。为了演示此过程,我们将 Elastic 模拟管道(simulation pipeline)与 OpenAI 推理服务(inference service)一起使用。将创建一个具有多个处理器的管道,其中包括脚本处理器,它将负责创建要在推理处理器中执行的提示,能够确定新的类别。其他处理器将用于操作管道执行期间生成的数据和辅助字段。值得一提的是,这个逻辑也可以应用于其他类似的工具或模型。
首先,我们需要创建推理端点,其中我们将服务定义为 OpenAI、访问服务所需的 token 和模型。在这个例子中,我使用的是 gpt-4o-mini。有关 OpenAI 推理服务的更多详细信息,请点击此处。
PUT _inference/completion/generate_topics_ia
{
"service": "openai",
"service_settings": {
"api_key": "your-token",
"model_id": "gpt-4o-mini"
}
}创建端点后,我们现在可以使用它来创建新的类别。下面是处理文档数据操作和提示生成的整个过程的管道。我将详细解释每个处理器的功能。
第一个处理器将负责构建提示(prompt)。清晰详细地说明指令非常重要,这样 AI 才能正确分析和识别主题。在这个提示中,我要求根据电影的标题、描述和类型的分析提出 2 个主题。
{
"script": {
"source": """
ctx.prompt = "You are an expert in semantic analysis and audiovisual content categorization. Your task is to generate only subcategories (max 2 topics) that describe specific aspects of movies based on their genres and descriptions. The output should be like: 'n1, n2, ...n'. Here is a movie info to analyze: Title: " + ctx.title + "Genres: " + ctx.genres + "Description: " + ctx.description;
"""
}下一个管道是推理管道,它将接收提示并将其发送到我们的 generate_topics_ia 端点。模型生成的响应将存储在 result 字段中。
{
"inference": {
"model_id": "generate_topics_ia",
"input_output": {
"input_field": "prompt",
"output_field": "result"
}
}
}接下来,我们有 3 个处理器用于操作响应并将其设置在 topics 字段中,此外还删除了我创建的临时字段。
执行此管道时,我们将得到以下结果:
{
"docs": [
{
"doc": {
"_index": "index",
"_version": "-3",
"_id": "1",
"_source": {
"description": "While Frodo and Sam edge closer to Mordor with the help of the shifty Gollum, the divided fellowship makes a stand against Sauron's new ally, Saruman, and his hordes of Isengard.",
"model_id": "generate_topics_ia",
"title": "The Lord of the Rings: The Fellowship of the Ring",
"genres": [
"Action",
"Adventure",
"Drama"
],
"topics": [
"Fantasy",
"Quest"
]
},
"_ingest": {
"timestamp": "2024-11-22T17:51:51.340010257Z"
}
}
},
{
"doc": {
"_index": "index",
"_version": "-3",
"_id": "2",
"_source": {
"description": "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival.",
"model_id": "generate_topics_ia",
"title": "Interstellar",
"genres": [
"Adventure",
"Drama",
"Sci-Fi"
],
"topics": [
"space exploration",
"human survival"
]
},
"_ingest": {
"timestamp": "2024-11-22T17:51:51.340413173Z"
}
}
},
{
"doc": {
"_index": "index",
"_version": "-3",
"_id": "3",
"_source": {
"description": "An astronaut becomes stranded on Mars after his team assume him dead, and must rely on his ingenuity to find a way to signal to Earth that he is alive.",
"model_id": "generate_topics_ia",
"title": "The Martian",
"genres": [
"Adventure",
"Drama",
"Sci-Fi"
],
"topics": [
"survival",
"ingenuity"
]
},
"_ingest": {
"timestamp": "2024-11-22T17:51:51.340427965Z"
}
}
}
]
}请注意,我们有与电影背景更相关的新类别(new categories),即使有些类别最初属于同一类型(genre)。
我们现在可以使用这些新类别并将它们与文档一起编入索引。这样,在生成分面时,除了主要类别之外,我们还有更多与电影背景相一致的具体子类别(subcategories)。
此外,还可以将这些新类别向量化并用于向量搜索。这意味着新的类别不仅可以作为过滤器,还可以用于计算与搜索词的语义相似性,从而进一步提高所呈现结果的相关性。
完整管道:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"script": {
"source": """
ctx.prompt = "You are an expert in semantic analysis and audiovisual content categorization. Your task is to generate only subcategories (max 2 topics) that describe specific aspects of movies based on their genres and descriptions. The output should be like string: 'n1, n2m ...n'. Here is a movies info to analyze: Title: " + ctx.title + "Genres: " + ctx.genres + "Description: " + ctx.description;
"""
}
},
{
"inference": {
"model_id": "generate_topics_ia",
"input_output": {
"input_field": "prompt",
"output_field": "result"
}
}
},
{
"split": {
"field": "result",
"target_field": "topics",
"separator": ", "
}
},
{
"remove": {
"field": "result"
}
},
{
"remove": {
"field": "prompt"
}
}
]
},
"docs": [
{
"_index": "index",
"_id": "1",
"_source": {
"title": "The Lord of the Rings: The Fellowship of the Ring",
"description": "While Frodo and Sam edge closer to Mordor with the help of the shifty Gollum, the divided fellowship makes a stand against Sauron's new ally, Saruman, and his hordes of Isengard.",
"genres": [
"Action",
"Adventure",
"Drama"
]
}
},
{
"_index": "index",
"_id": "2",
"_source": {
"title": "Interstellar",
"description": "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival.",
"genres": [
"Adventure", "Drama", "Sci-Fi"
]
}
},
{
"_index": "index",
"_id": "3",
"_source": {
"title": "The Martian",
"description": "An astronaut becomes stranded on Mars after his team assume him dead, and must rely on his ingenuity to find a way to signal to Earth that he is alive.",
"genres": [
"Adventure", "Drama", "Sci-Fi"
]
}
}
]
}结论
使用人工智能来改进方面可以使结果更加具体和更具情境性,从而改变搜索体验。与通常很广泛的固定类别不同,人工智能生成的类别可以更好地反映上下文。例如,在对电影进行重新分类时,我们可以捕捉主要类别遗漏的背景,从而提供更相关的分组。
这些新的类别可以添加到索引中,不仅可以改善分面,还可以实现向量搜索。结果是搜索体验更加高效,过滤器更加符合上下文。
参考
https://www.elastic.co/guide/en/elasticsearch/reference/current/infer-service-openai.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/simulate-pipeline-api.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/script-processor.html
想要获得 Elastic 认证吗?了解下一期 Elasticsearch 工程师培训何时举行!
Elasticsearch 包含许多新功能,可帮助你为你的用例构建最佳的搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在本地机器上试用 Elastic。
原文:https://www.elastic.co/search-labs/blog/faceted-search-examples-ai


















 1653
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









