









作者:来自 Elastic Tomás Murúa

了解 RAG、grounding,以及如何通过将 LLM 连接到你的文档来减少幻觉。
更多阅读:Elasticsearch:在 Elastic 中玩转 DeepSeek R1 来实现 RAG 应用
想获得 Elastic 认证吗?查看下一期 Elasticsearch Engineer 培训的时间!
Elasticsearch 拥有大量新功能,帮助你为你的使用场景构建最佳搜索方案。深入学习我们的示例 notebook,了解更多信息,开始免费的 cloud 试用,或者现在就在你的本地机器上尝试 Elastic 吧。
大型语言模型(LLM)能够生成连贯的回答,但当你需要真实且更新的信息时,它们可能会产生幻觉(编造数据)并给出不可靠的答案。为防止这种情况,我们使用 grounding 来为模型提供专门的、针对特定使用场景的、相关的上下文信息,超越 LLM 的训练内容。
Grounding 是将特定数据源连接到模型的过程,用于将其 “接地” 到真实内容,而不是仅依赖模型训练时学到的模式,从而提供更可靠和更准确的答案。
Grounding 有助于减少模型幻觉,根据你的数据源生成响应,并通过提供引用让你能够审查回答内容。
检索增强生成( Retrieval Augmented Generation - RAG )是一种 grounding 技术,它使用搜索算法从外部来源检索相关信息,然后将这些信息作为上下文提供给 LLM,最后模型结合增强后的上下文和其原始训练数据生成答案。
RAG 的工作流程图如下:
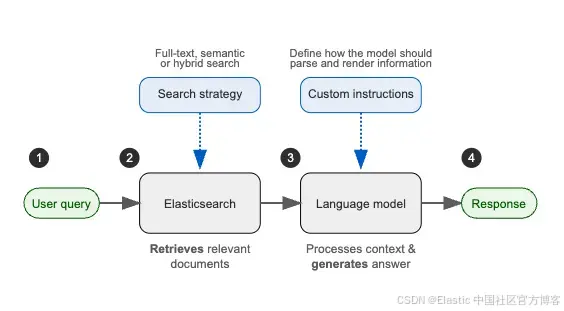
RAG 让你可以通过更新或扩展模型可访问的外部数据源来轻松扩展系统。同时,它也是一种相较于微调 LLMs 更具性价比的替代方案,因为你只需添加数据,无需大量定制。
而且由于 RAG 可以访问并使用最新信息,它非常适合那些对最新信息要求较高的使用场景。
幻觉示例
在这个例子中,我们将使用 DeepSeek 并提问:“Who is the author who won the Chilean National Literature Prize in 1932?” 这是一个有陷阱的问题,因为这个奖项是在 1942 年才设立的。让我们看看模型是如何回答的:

如你所见,由于 AI 没有完整的信息,它产生了幻觉并给出了一个编造的答案。尽管作者和作品是真实存在的,但回答中的其他部分是错误的。
现在,我们来看看当我们使用 RAG 进行 grounding 后,模型的表现如何。为此,我们将上传关于智利国家文学奖的 Wikipedia 页面:

现在,让我们再次提出同样的问题并检查答案:

如你所见,使用 RAG 后我们得到了正确的答案。它指出 1932 年没有颁发该奖项,并请求用户进一步澄清问题。
在 Playground 中使用 RAG
通过使用 Elasticsearch,你可以轻松扩展,唯一的限制是集群容量。你可以使用不同的数据源和连接器(connectors)来获取所需数据。此外,你完全拥有你的数据,因为它保留在你的基础设施中,不会上传到第三方服务;如果你运行本地 LLM,你的数据甚至不会离开你的网络。最后,你可以通过设计查询和基于访问控制( RBAC )的过滤方式来控制搜索过程。
我们将使用 Playground,这是我们的低代码平台,它可以让你快速简单地使用 Elasticsearch 内容创建 RAG 应用。
以下是一个逐步指南,教你如何将 PDF 或其他文档上传到 Playground。你也可以在这里查看更多信息,并在这里试用 Playground。
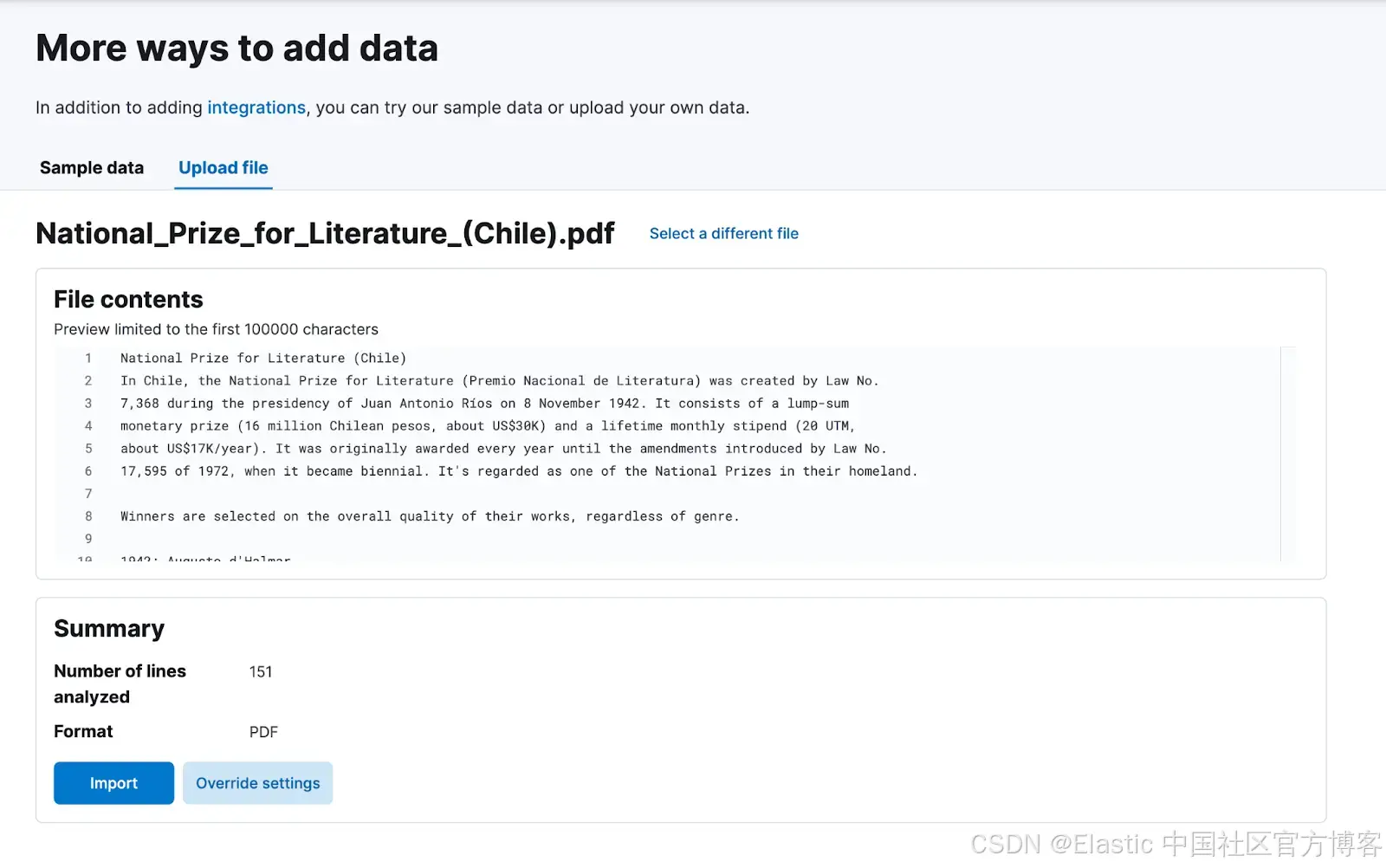
上传 PDF
我们将把与 DeepSeek 提供的相同 PDF 文件索引到 Kibana 中。如果你按照上面文章中的步骤操作并创建了 semantic_text 字段,你将创建一个带有相应嵌入的向量数据库,准备好供使用。
提问
提问以下问题:
“Who is the author who won the Chilean National Literature Prize in 1932?”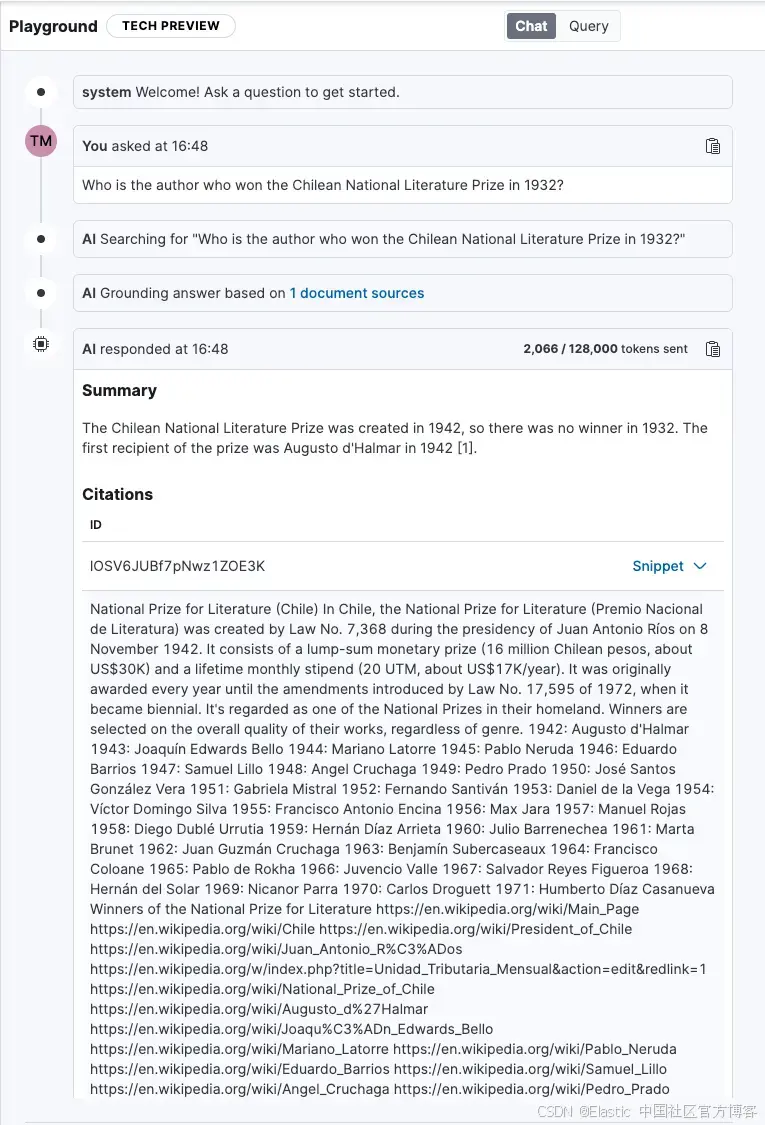
Playground 将此查询发送到 Elasticsearch,Elasticsearch 运行语义搜索并定位与问题相关的信息片段。然后,这些片段作为上下文被包含在发送给 LLM 的提示中,以便将答案与我们提供的信息源进行 grounding。
最后,Playground 生成的答案说明 1932 年没有颁发奖项,并提供相关片段的引用作为证据。
Playground 还提供了两个非常有用的功能,以帮助理解 RAG 系统的底层组件:
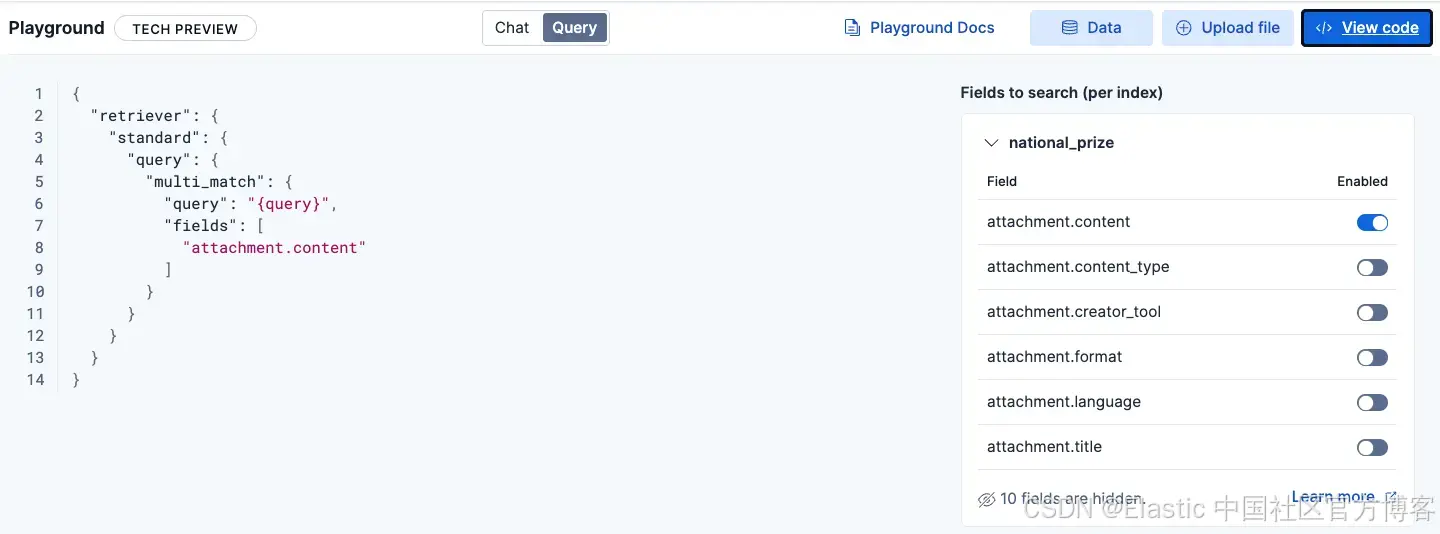
查询
你可以查看 Elasticsearch 正在运行的查询,以检索相关文档,并根据需要启用/禁用字段。
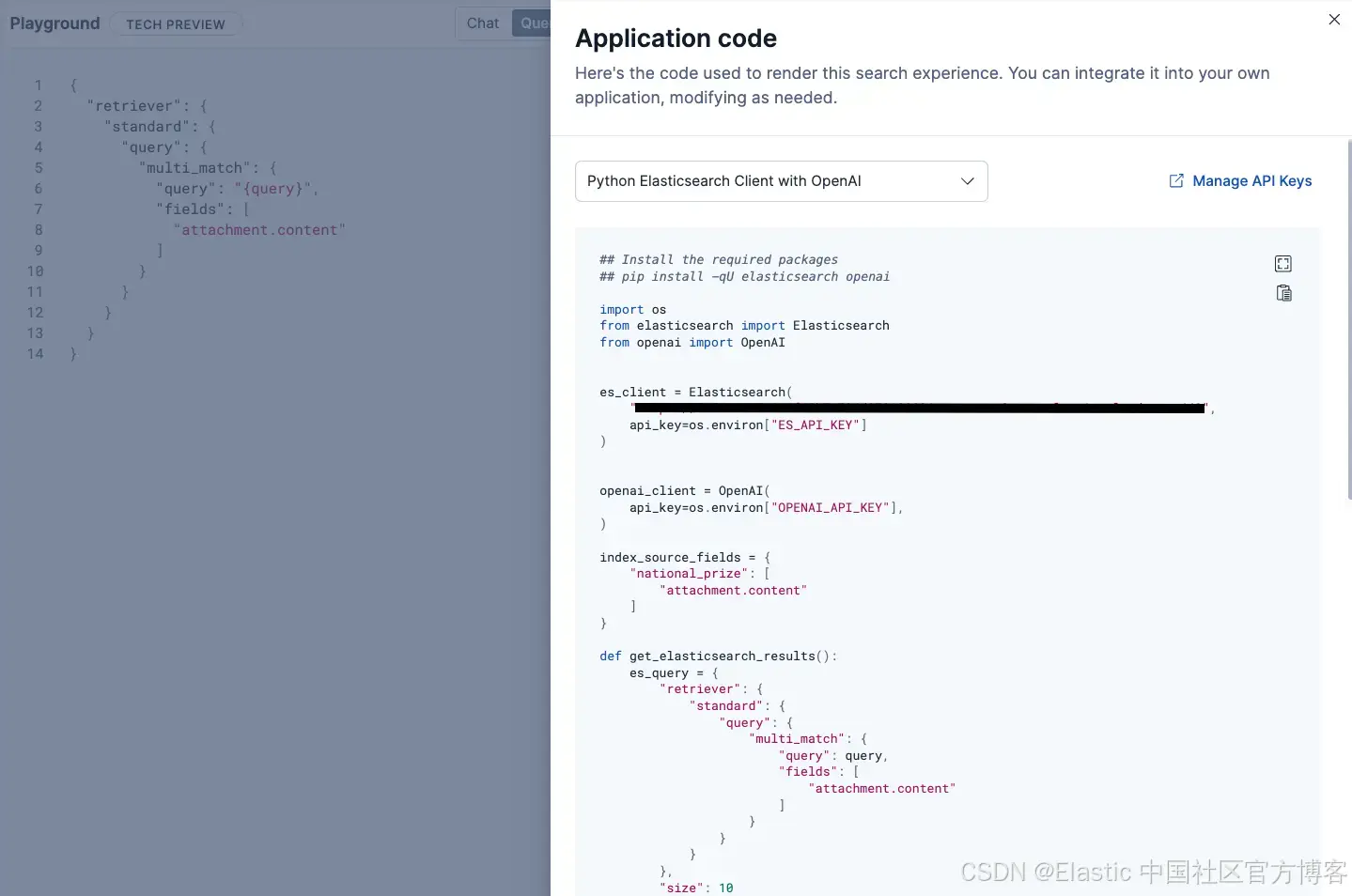
查看代码
如果你可以部署你的 RAG 应用,Playground 为你提供支持。在 "View Code" 标签下,你可以查看用于创建整个 RAG 工作流的底层代码。你可以选择两种 Python 方案:使用 Elasticsearch 客户端与 OpenAI,或基于 Langchain 的实现。
如果你想定制体验并将代码部署到其他地方,你可以使用这个代码片段作为起点。
结论
Grounding 是一个将 LLM 连接到外部数据源的过程,使它们能够超越训练内容,提供更准确和可信的答案。检索增强生成(RAG)是一种 grounding 方法,它具有可扩展性、性价比高,并确保可以访问最新的信息。
像 Playground 这样的工具通过启用大规模索引、定制搜索和带有引用的响应,简化了 RAG 的实施,这使你能够轻松验证答案并确保获得准确和可信的结果。
如果你想阅读更多关于 RAG 特性的深入文章,可以从这篇开始,获得 RAG 的更技术性定义。你还可以查看《Rag vs. fine-tuning: When RAG is the best decision》,《How to leverage document security using RAG》以及《RAG systems in production》。


















 1318
1318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









