









作者:来自 Elastic Agi K Thomas 及 Udayasimha Theepireddy (Uday)

由 Amazon MQ 管理的 RabbitMQ 在分布式架构中启用异步通信,但带来了操作风险,例如重试、处理延迟和队列积压。Elastic 的 Amazon MQ 集成对于 RabbitMQ 提供了对代理健康、队列性能、消息流和资源使用的深度可观察性,通过 Amazon CloudWatch 指标和日志进行监控。本文概述了与 RabbitMQ 相关的主要操作风险,并解释了 Elastic 可观察性如何帮助保持系统可靠性并优化大规模消息传递。
使用 Elastic 的 Amazon MQ 可观察性:通过实时洞察解密消息流
管理消息驱动架构中的隐藏复杂性
Amazon MQ 是一项托管的消息代理服务,支持 Apache ActiveMQ Classic 和 RabbitMQ,负责消息代理的设置、操作和维护。像 RabbitMQ 这样的消息系统,由 Amazon MQ 管理,在现代解耦的事件驱动应用程序中发挥着关键作用。作为服务之间的中介,RabbitMQ 通过消息排队、路由和可靠交付促进异步通信,使其成为微服务、实时数据流和事件驱动架构的理想选择。然而,这种灵活性也带来了操作挑战,例如重试、处理延迟、消费者失败和队列积压,这些问题会逐渐影响下游性能和系统可靠性。
通过 Elastic 的 Amazon MQ 集成,用户可以深入了解消息流模式、队列性能和消费者健康状况。该集成使得能够主动检测瓶颈,帮助优化系统行为,并确保大规模的可靠消息传递。
在这篇博客中,我们将深入探讨 RabbitMQ 在现代架构中的操作挑战,同时审视常见的漏洞和应对策略。
为什么在 Amazon MQ 上对 RabbitMQ 进行可观察性至关重要?
RabbitMQ 代理在分布式系统中至关重要,负责订单处理、支付流程和通知发送等任务。任何中断都可能引发严重的下游问题。对 RabbitMQ 的可观察性有助于回答关键的运维问题,例如:
-
CPU 和内存使用率是否在持续上升?
-
消息发布率和确认率的趋势如何?
-
是否有消费者未确认消息?
-
哪些队列出现了异常增长?
-
死信消息数量是否在不断增加?
通过 Amazon MQ 集成实现增强的可观察性
Elastic 为 RabbitMQ 提供了专用的 Amazon MQ 集成,利用 Amazon CloudWatch 的指标和日志来提供全面的可观察性数据。此集成支持采集与连接、节点、队列、交换机及系统日志相关的指标。
部署带有此集成的 Elastic Agent 后,用户可以监控以下内容:
-
队列性能和死信队列(DLQ)指标,包括总消息数(
MessageCount.max)、准备交付的消息数(MessageReadyCount.max)以及未确认的消息数(MessageUnacknowledgedCount.max)。其中MessageCount.max指标跟踪队列中的消息总数,包括已被标记为死信的消息,长期监控此指标可识别消息堆积趋势,提示潜在死信问题。 -
消费者行为,例如消费者数量(
ConsumerCount.max)和确认速率(AckRate.max),有助于识别性能较差的消费者或潜在的积压问题。 -
消息吞吐量,通过实时跟踪发布速率(
PublishRate.max)、确认速率(ConfirmRate.max)和确认消息速率,深入了解应用的消息流模式。 -
代理和节点级别的健康状态,包括内存使用(
RabbitMQMemUsed.max)、CPU 利用率(SystemCpuUtilization.max)、磁盘可用空间(RabbitMQDiskFree.min)和文件描述符使用(RabbitMQFdUsed.max)。这些指标对于诊断资源饱和情况和避免服务中断非常关键。
将 Amazon MQ 指标集成到 Elastic Observability 中
Elastic 的 Amazon MQ 集成支持将 CloudWatch 指标和日志导入 Elastic Observability,提供近乎实时的 RabbitMQ 可见性。预构建的 Amazon MQ 仪表板可视化这些数据,集中展示代理健康状况、消息活动和资源使用,帮助用户快速检测并解决问题。Elastic 的 Observability 告警功能可根据自定义条件触发主动通知,而其 SLO 能力则允许用户定义并跟踪关键性能目标,从而增强系统可靠性和服务承诺。
Elastic 将来自 Amazon MQ 的日志和指标与 AWS、本地部署或多云环境中的其他服务和应用数据整合在一起,实现统一平台上的可观察性。
前提条件
要按步骤操作,请确保你具备以下条件:
-
一个 Elastic Cloud 帐号并在 AWS 中部署的 stack(参考此处的操作指南),版本需为 8.16.5 或更高。你也可以选择使用 Elastic Cloud Serverless,这是一种完全托管的解决方案,无需管理基础设施,能够根据使用情况自动扩展,让你专注于数据价值的挖掘。
-
一个具备从 AWS 拉取所需数据权限的 AWS 账户,详见文档说明。
架构图
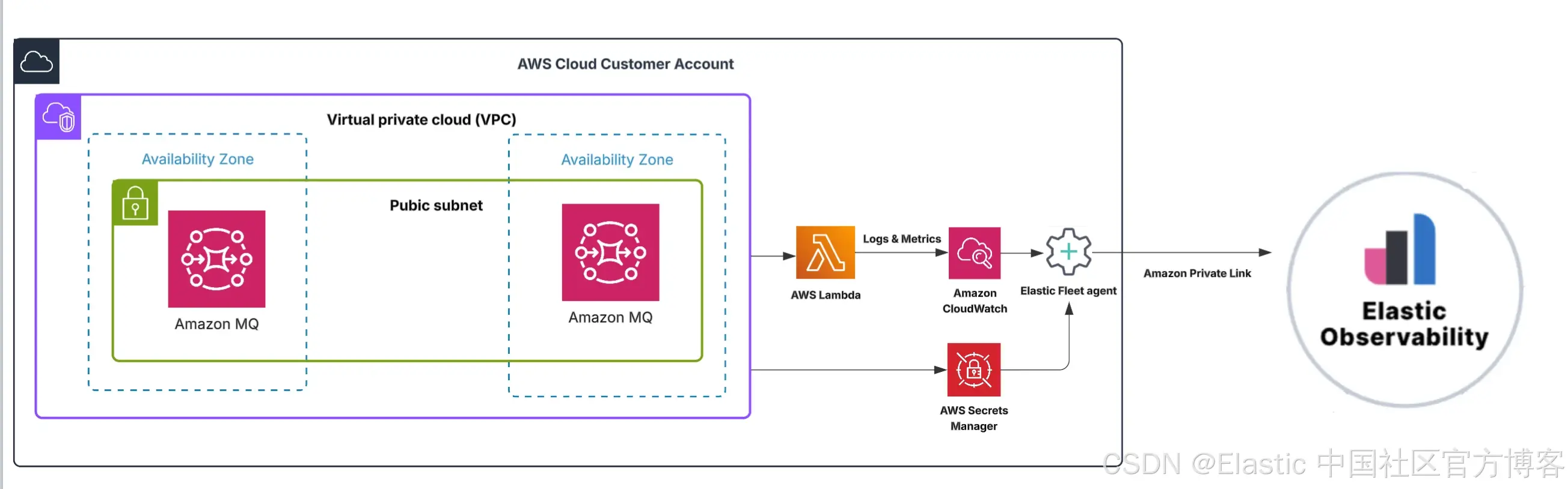
从 RabbitMQ 到 AWS Lambda 的审计流程追踪
以财务审计跟踪为例,每个用户操作(如资金转账)都会发布到 RabbitMQ。一个基于 Python 的 AWS Lambda 函数消费这些消息,使用 id 字段去重,并记录结构化的审计事件供下游分析使用。
通过 RabbitMQ 发送的示例负载:
{
"id": "txn-849302",
"type": "audit",
"payload": {
"user_id": "u-10245",
"event": "funds.transfer",
"amount": 1200.75,
"currency": "USD",
"timestamp": "T14:20:15Z",
"ip": "192.168.0.8",
"location": "New York, USA"
}
}
你现在可以将 RabbitMQ 的消息发布活动与 AWS Lambda 的调用日志进行关联,追踪处理延迟,并为消费者吞吐量下降或 RabbitMQ 队列深度意外激增等情况配置告警。
AWS Lambda 函数:处理来自 RabbitMQ 的消息
这个基于 Python 的 AWS Lambda 函数处理从 RabbitMQ 接收到的审计事件。它基于 id 字段对消息去重,并记录结构化事件数据,供下游分析或合规使用。将以下代码保存为名为 app.py 的文件。
import json
import logging
import base64
# Configure logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# In-memory set to track processed message IDs for deduplication
processed_ids = set()
def lambda_handler(event, context):
logger.info("Lambda triggered by RabbitMQ event")
if 'rmqMessagesByQueue' not in event:
logger.warning("Invalid event: missing 'rmqMessagesByQueue'")
return {'statusCode': 400, 'body': 'Invalid RabbitMQ event'}
for queue_name, messages in event['rmqMessagesByQueue'].items():
logger.info(f"Processing queue: {queue_name}, Messages count: {len(messages)}")
for msg in messages:
try:
raw_data = msg['data']
decoded_json = base64.b64decode(raw_data).decode('utf-8')
message = json.loads(decoded_json)
logger.info(f"Decoded message: {json.dumps(message)}")
message_id = message.get('id')
if not message_id:
logger.warning("Message missing 'id', skipping.")
continue
if message_id in processed_ids:
logger.warning(f"Duplicate message detected: {message_id}")
continue
payload = message.get('payload', {})
logger.info(f"Processing message ID: {message_id}")
logger.info(f"Event Type: {message.get('type')}")
logger.info(f"User ID: {payload.get('user_id')}")
logger.info(f"Event: {payload.get('event')}")
logger.info(f"Amount: {payload.get('amount')} {payload.get('currency')}")
logger.info(f"Timestamp: {payload.get('timestamp')}")
logger.info(f"IP Address: {payload.get('ip')}")
logger.info(f"Location: {payload.get('location')}")
processed_ids.add(message_id)
except Exception as e:
logger.error(f"Error processing message: {str(e)}")
return {'statusCode': 200, 'body': 'Messages processed successfully'}
设置 AWS Secrets Manager
为了安全地存储和管理你的 RabbitMQ 凭证,请使用 AWS Secrets Manager。
创建新密钥:
-
选择 “Store a new secret”。
-
选择 “Other type of secret”。
-
输入以下键值对:
-
username: 你的 RabbitMQ 用户名 -
password: 你的 RabbitMQ 密码
-
配置密钥:
-
提供一个有意义的名称,例如
RabbitMQAccess。 -
可选:添加标签并设置自动轮换(如有需要)。
存储密钥:
-
检查设置并存储密钥。记录你创建的密钥的 ARN。

设置 Amazon MQ 上的 RabbitMQ
要开始在 Amazon MQ 上使用 RabbitMQ,请按照以下步骤设置你的代理:
-
打开 Amazon MQ 控制台。
-
使用 RabbitMQ 引擎创建一个新代理。
-
选择你偏好的部署选项 —— single-instance 或 clustered。
-
使用你之前在 AWS Secrets Manager 中存储的相同用户名和密码。
-
在 “Additional settings” 中启用 CloudWatch Logs,以实现可观测性。
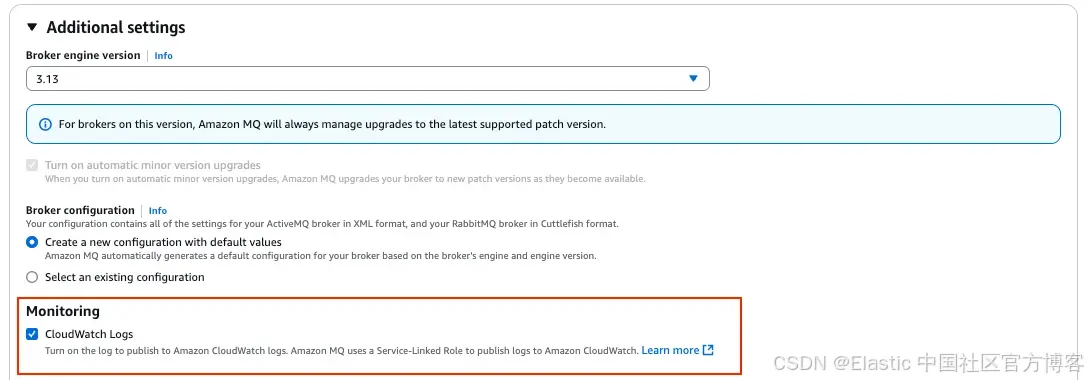
- 配置访问和安全设置,确保该代理可以被你的 AWS Lambda 函数访问。
- 在代理创建完成后,记录以下重要信息:
-
RabbitMQ 代理的 ARN。
-
RabbitMQ Web 控制台的 URL。
-
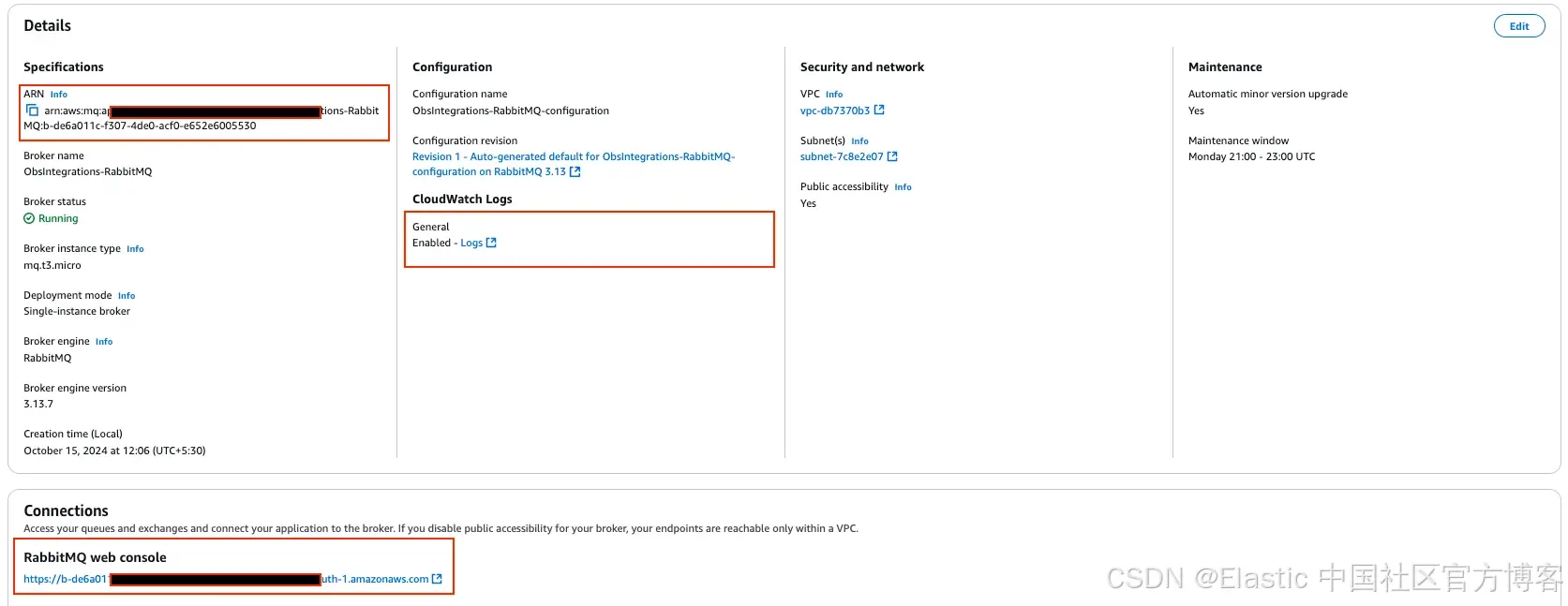
- 你需要 RabbitMQ 日志组的 ARN 来设置 Elastic 的 Amazon MQ 集成。请按照以下步骤找到它:
- 前往代理的 General – Enabled Logs 部分。
- 复制 CloudWatch 日志组的 ARN。

创建 RabbitMQ 队列
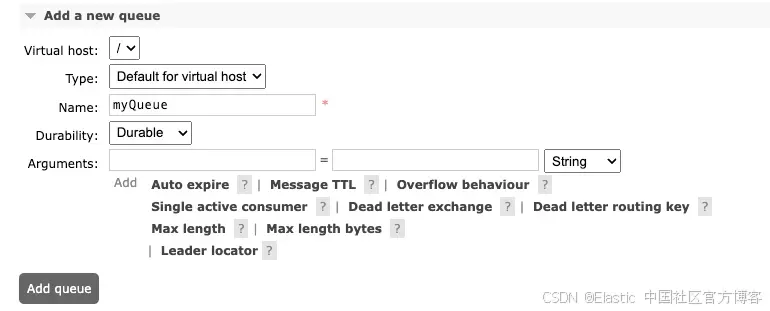
现在 RabbitMQ 代理已配置好,使用管理控制台创建一个消息将被发布到的队列。
- 使用 web 控制台 URL 访问 RabbitMQ 管理控制台。
- 创建一个新队列(例如: myQueue)来接收消息。
构建并部署 AWS Lambda 函数
本节将使用 AWS SAM 设置 Lambda 函数,添加消息处理逻辑,并将其部署到 AWS。此 Lambda 函数将负责从 RabbitMQ 消费消息并记录审计事件。
继续之前,请确保你已完成以下前提条件。
接下来,按照以下步骤继续设置:
- 在命令行中,进入你选择的目录并运行命令
sam init。 - AWS SAM CLI 会引导你完成设置流程。
- 选择 AWS Quick Start Templates。
- 选择 Hello World Example。
- 使用 Python 运行时和 zip 打包类型。
- 使用默认选项继续。
- 将你的应用命名为 sample-rabbitmq-app。
- AWS SAM CLI 会下载起始模板并创建应用项目的目录结构。
- 在命令行中进入新创建的
sample-rabbitmq-app目录。- 将
hello_world/app.py文件的内容替换为用于处理 rabbitmq 消息的 lambda 函数代码。 - 在
template.yaml文件中,使用以下提供的值更新文件内容。
- 将
Resources:
SampleRabbitMQApp:
Type: AWS::Serverless::Function
Properties:
CodeUri: hello_world/
Description: A starter AWS Lambda function.
MemorySize: 128
Timeout: 3
Handler: app.lambda_handler
Runtime: python3.10
PackageType: Zip
Policies:
- Statement:
- Effect: Allow
Resource: '*'
Action:
- mq:DescribeBroker
- secretsmanager:GetSecretValue
- ec2:CreateNetworkInterface
- ec2:DescribeNetworkInterfaces
- ec2:DescribeVpcs
- ec2:DeleteNetworkInterface
- ec2:DescribeSubnets
- ec2:DescribeSecurityGroups
Events:
MQEvent:
Type: MQ
Properties:
Broker: <ARN of the Broker>
Queues:
- myQueue
SourceAccessConfigurations:
- Type: BASIC_AUTH
URI: <ARN of the secret>
- 运行命令
sam deploy --guided并等待确认消息。这将部署所有资源。
发送审计事件到 RabbitMQ 并触发 Lambda
为了测试端到端设置,通过使用 RabbitMQ 的 Web UI 将审计事件数据发布到 RabbitMQ。一旦消息被发送,它将触发 Lambda 函数。
- 导航到 Amazon MQ 控制台并选择你新创建的代理。
- 找到并打开 Rabbit Web 控制台 URL。

- 在 "Queues and Streams" 标签下,选择目标队列(例如:myQueue)。
- 输入消息负载,然后点击 "Publish message" 将其发送到队列。
以下是通过 RabbitMQ 发布的示例负载:
{
"id": "txn-849302",
"type": "audit",
"payload": {
"user_id": "u-10245",
"event": "funds.transfer",
"amount": 1200.75,
"currency": "USD",
"timestamp": "T14:20:15Z",
"ip": "192.168.0.8",
"location": "New York, USA"
}
}
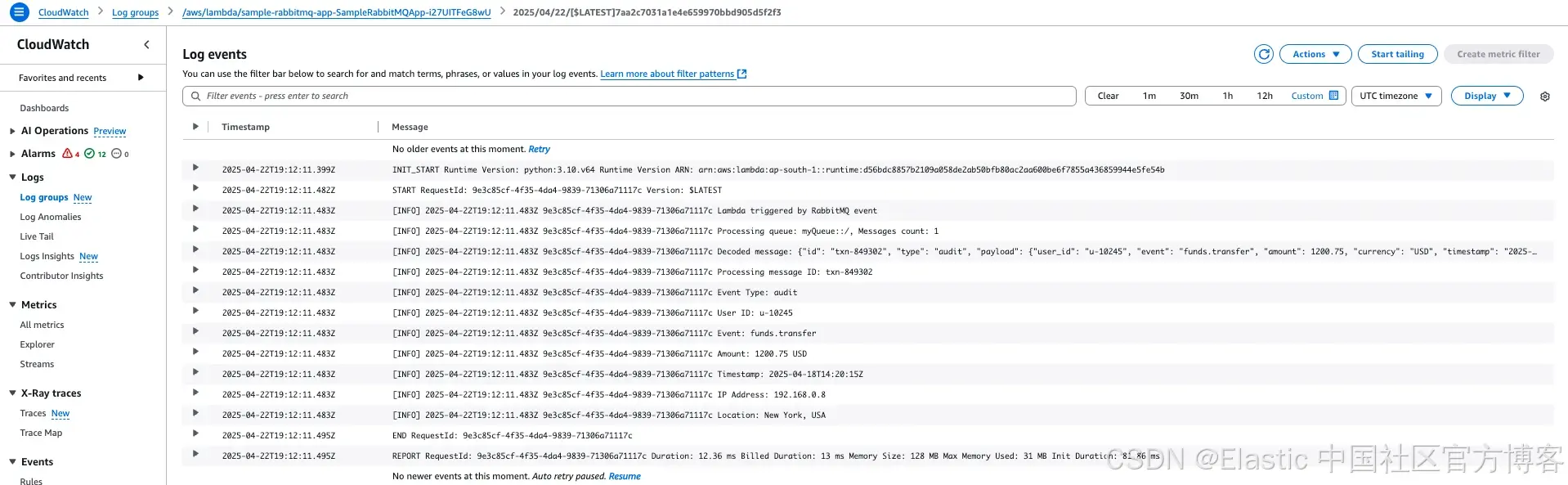
- 导航到之前创建的 AWS Lambda 函数。
- 在 "Monitor" 标签下,点击 "View CloudWatch logs"。
- 检查最新的日志流,确认 Lambda 函数是否被 Amazon MQ 触发,并且消息是否成功处理。
配置 Amazon MQ 集成以收集指标和日志
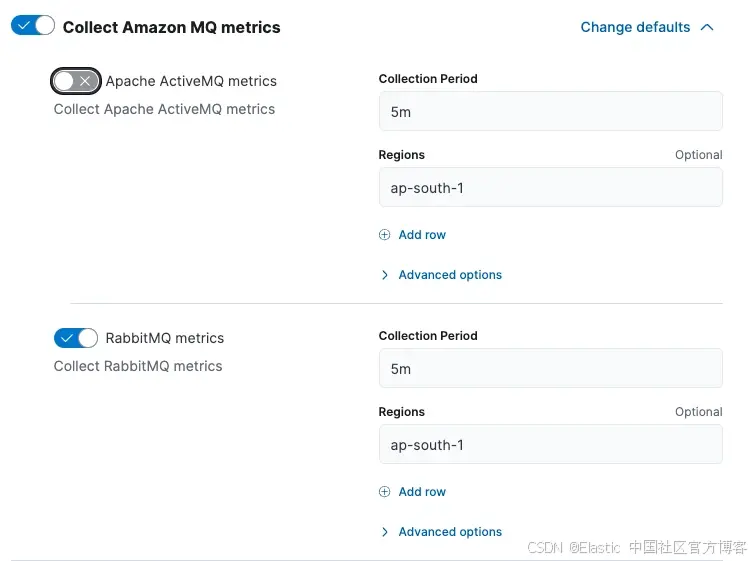
Elastic 的 Amazon MQ 集成简化了从由 Amazon MQ 管理的 RabbitMQ 经纪人收集日志和指标的过程。日志通过 Amazon CloudWatch Logs 获取,而指标则从指定的 AWS 区域按定义的时间间隔提取。
Elastic 提供了默认的指标收集配置。你可以接受这些默认设置,或者根据你的需求调整设置,如收集周期(Collection Period)。
启用日志收集:
-
导航到 Amazon MQ 控制台并选择新创建的经纪人。
-
在 "General – Enabled Logs" 部分,点击 Logs 超链接以打开详细的日志设置页面。
-
从此页面复制 CloudWatch log group ARN。

- 在 Elastic 中,设置 Amazon MQ integration 并粘贴 CloudWatch 日志组 ARN。
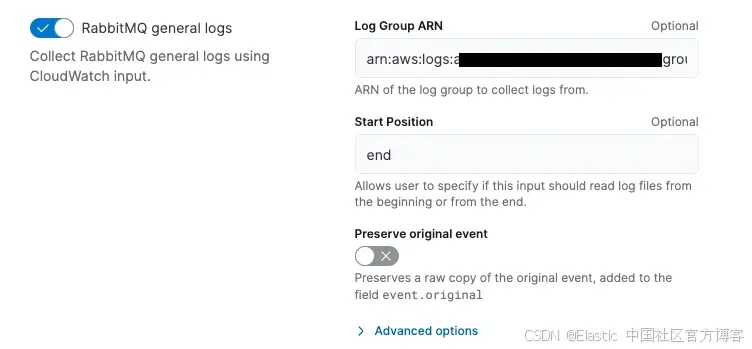
- Accept Defaults or Customize Settings– Elastic 提供了日志收集的 default configuration。你可以接受这些默认设置,也可以调整如 collection intervals 等设置,以更好地满足你的需求。
通过预构建的 Amazon MQ 仪表板可视化 RabbitMQ 工作负载
你可以通过以下方式访问 RabbitMQ 仪表板:
-
导航到仪表板菜单 – 在 Elastic 中选择仪表板菜单选项,搜索 [Amazon MQ] RabbitMQ 概览以打开仪表板。
-
导航到集成菜单 – 打开 Elastic 中的 Integrations 菜单,选择 Amazon MQ,转到 Assets 选项卡,选择 [Amazon MQ] RabbitMQ Overview 以从仪表板资产中查看。
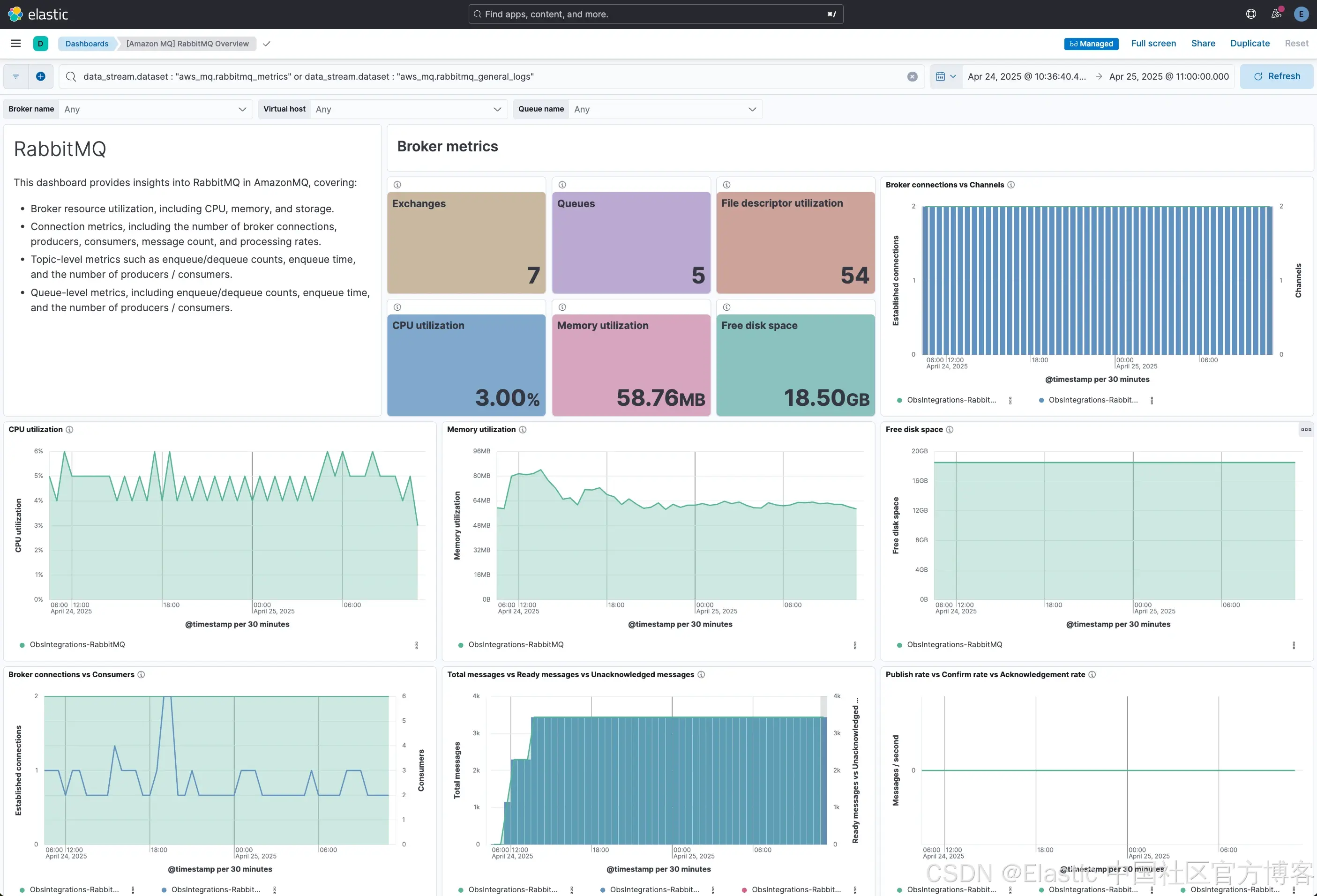
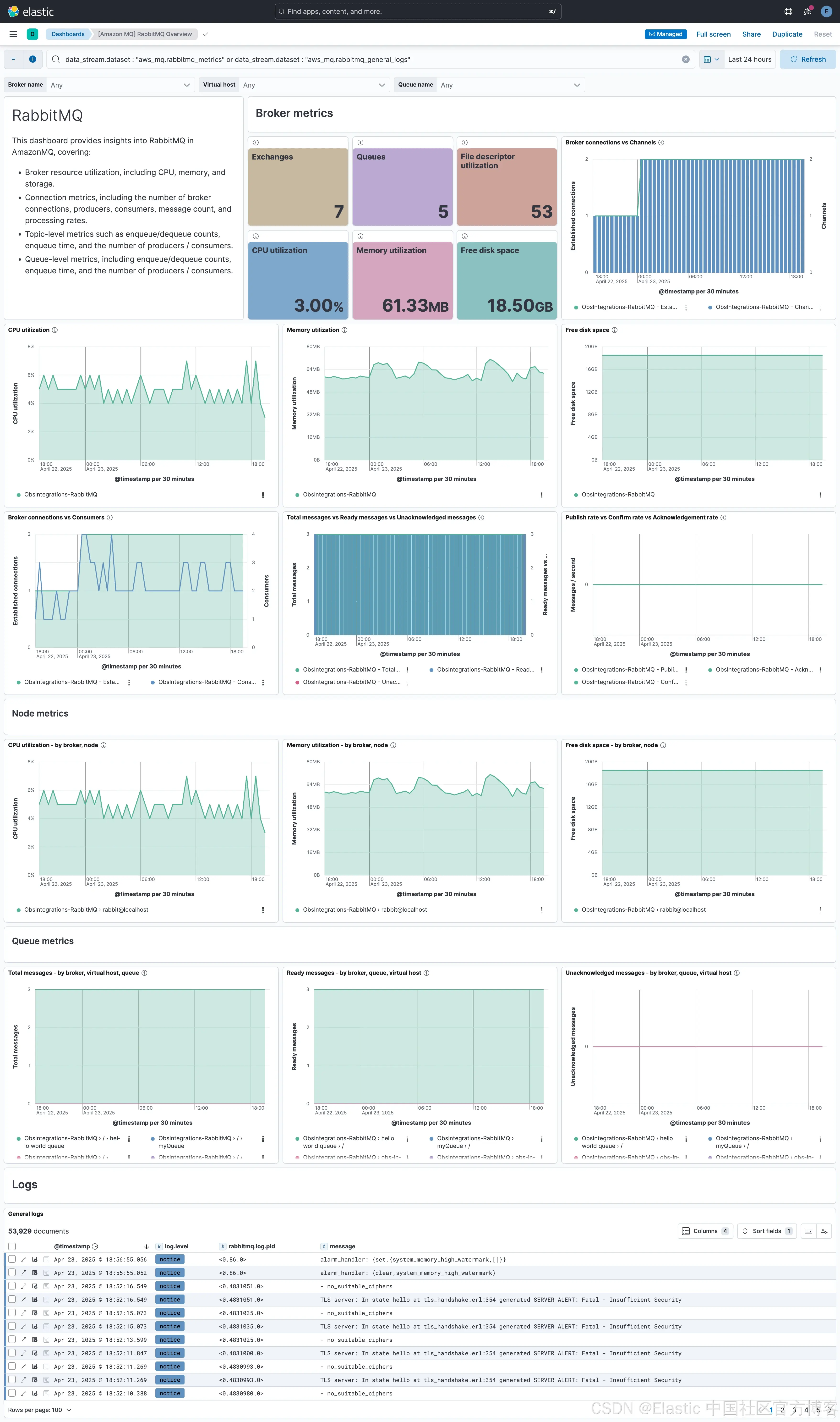
Elastic 集成中的 Amazon MQ RabbitMQ 仪表板提供了对代理健康和消息活动的全面概览。它提供了关于代理资源利用、队列和主题性能、连接趋势和消息吞吐量的实时洞察。该仪表板帮助用户跟踪系统行为,检测性能瓶颈,并确保跨分布式应用程序的可靠消息传递。
代理指标 - Broker Metrics
此部分提供了 RabbitMQ 代理总体健康和性能的集中视图。可视化展示了已配置的交换和队列数量、活动代理连接、生产者、消费者和飞行中的总消息。系统级别的指标,如 CPU 利用率、内存消耗和可用磁盘空间,帮助评估代理是否有足够的资源来处理当前的工作负载。
消息流量指标,如发布速率、确认速率和确认率,显示了消息如何通过代理进行处理。监控这些值的趋势有助于检测消息传递问题、吞吐量下降或在负载下可能导致代理饱和的情况。
节点指标 - Node Metrics
节点级的可视化有助于识别集群式 RabbitMQ 设置中各节点之间的资源不平衡情况。此部分包括每个节点的 CPU 使用率、内存消耗和可用磁盘空间,提供对底层基础设施是否能支持代理操作的洞察。
队列指标 - Queue Metrics
特定队列的洞察对于理解消息传递模式和积压情况至关重要。此部分详细说明了按代理、虚拟主机和队列细分的总消息数、准备好的消息数和未确认的消息数。
通过观察这些计数如何随时间变化,用户可以识别慢消费者、消息积压或交付问题,这些问题可能会影响应用程序性能或在压力下导致消息丢失。
日志 - Logs
此部分显示日志级别、进程 ID 和原始消息内容。这些日志提供了对连接失败、资源阈值被触发或队列行为异常等事件的即时可视化。
使用警报规则检测队列积压
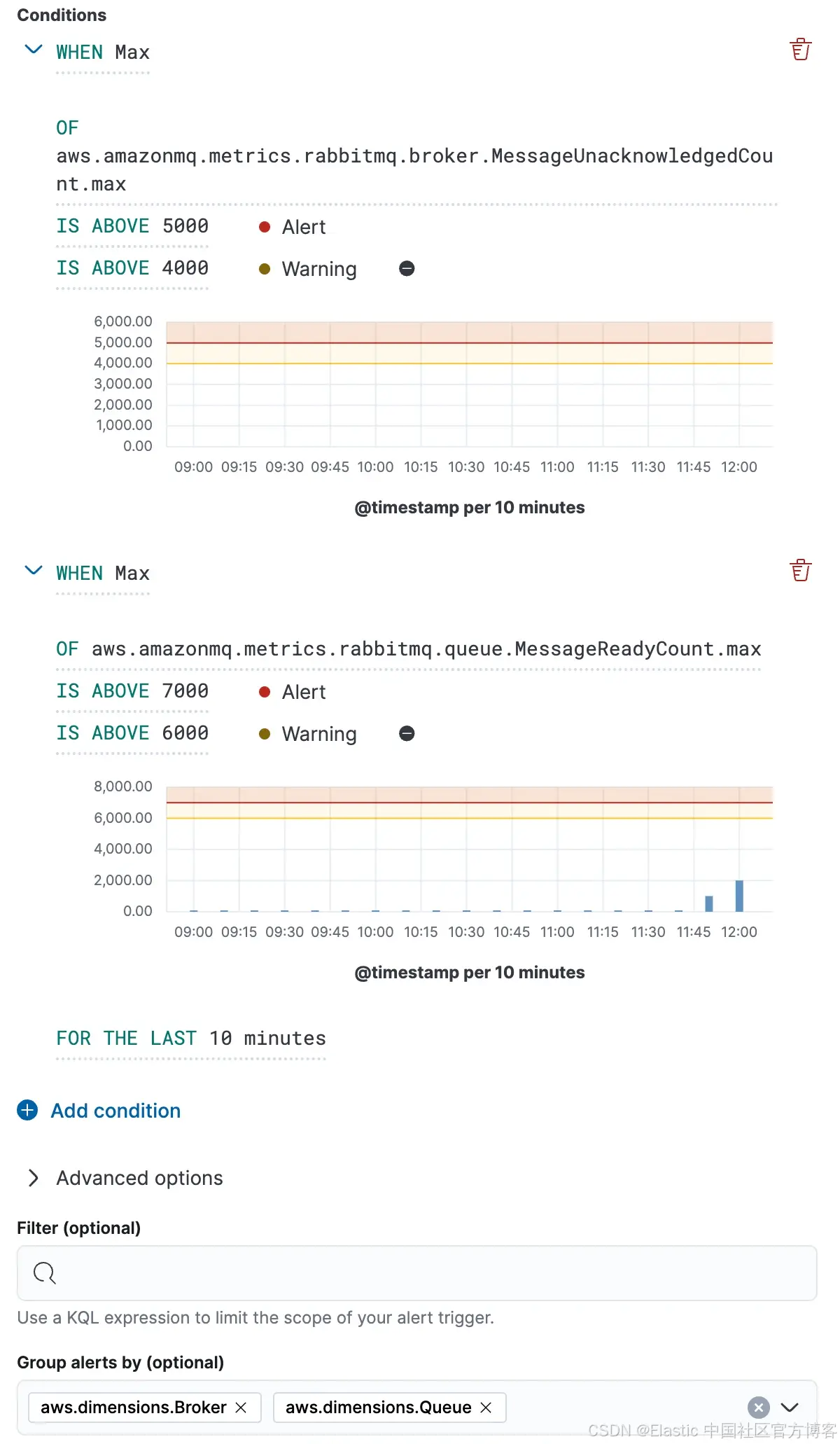
Elastic 的警报框架允许你定义规则,监控关键的 RabbitMQ 指标,并在特定阈值被突破时自动触发操作。
警报:队列积压(消息就绪或未确认的消息)
此警报帮助通过评估两个指标来检测 Amazon MQ 中的队列积压:
-
MessageUnacknowledgedCount.max
-
MessageReadyCount.max
如果以下条件持续超过 10 分钟,则触发警报:
-
MessageUnacknowledgedCount.max 超过 5,000
-
MessageReadyCount.max 超过 7,000
这些阈值应根据典型的消息量和消费者吞吐量进行调整。持续的高值可能表明消费者跟不上,或者消息传递管道出现拥塞,这可能导致延迟或丢失消息。如果不处理,持续的高值可能导致处理延迟或丢失消息。
跟踪资源利用率以维持 RabbitMQ 性能
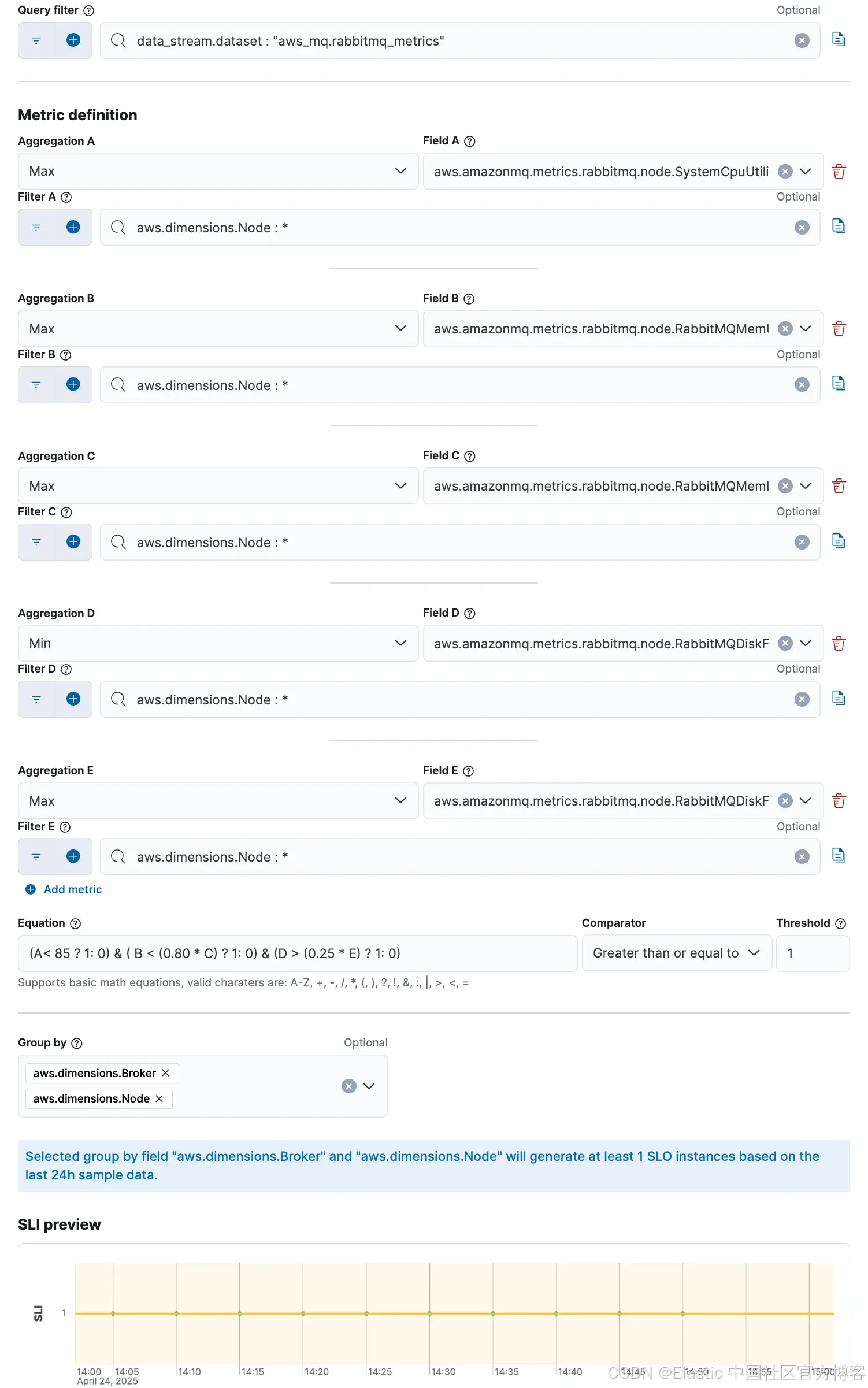
Elastic 的服务级目标(Service-level objectives - SLOs)功能允许你使用关键指标(如延迟、可用性和错误率)定义和监控性能目标。一旦配置,Elastic 会实时评估这些 SLO,提供直观的仪表板、超出阈值的警报以及错误预算消耗的洞察。这使得团队能够提前识别问题,确保服务可靠性和一致的性能。
SLO: 节点资源健康(CPU、内存、磁盘)
此 SLO 关注确保 RabbitMQ 代理和节点具有足够的资源来处理消息,而不会导致性能下降。它跟踪 RabbitMQ 代理和节点的 CPU、内存和磁盘使用情况,以防资源耗尽导致服务中断。
目标阈值:
-
SystemCpuUtilization.max 始终保持在 85% 以下,持续时间为 99%。
-
RabbitMQMemUsed.max 始终保持在 RabbitMQMemLimit.max 的 80% 以下,持续时间为 99%。
-
RabbitMQDiskFree.min 始终保持在 RabbitMQDiskFreeLimit.max 的 25% 以上,持续时间为 99%。
CPU 或内存使用率的持续高值可能表明资源竞争,这可能导致消息处理变慢或停机。磁盘可用性低可能导致代理停止接受消息,存在丢失消息的风险。这些阈值旨在捕捉资源饱和的早期迹象,并确保 RabbitMQ 部署中平稳、无中断的消息流动。
结论
随着基于 RabbitMQ 的消息架构的扩展和复杂化,深入了解系统性能和潜在问题的需求也在增加。Elastic 的 Amazon MQ 集成将这种可见性呈现到前端 —- 帮助你超越基本的健康检查,实时了解消息吞吐量、队列积压趋势以及代理和消费者之间的资源饱和情况。
通过利用预构建的仪表板、配置警报和 SLO,你可以主动检测异常,优化消费者性能,并确保在事件驱动的应用程序中可靠地交付消息。


















 1521
1521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









