









作者:来自 Elastic Jeffrey Rengifo

回顾生产环境中的最佳实践,并讲解如何在无服务器环境中运行 Elasticsearch Node.js 客户端。
想获得 Elastic 认证?查看下一期 Elasticsearch Engineer 培训的时间!
Elasticsearch 拥有大量新功能,能帮助你为你的使用场景构建最佳搜索解决方案。深入查看我们的示例笔记本,了解更多信息,开始免费云试用,或立即在本地机器上试用 Elastic。
这是我们 Elasticsearch in JavaScript 系列的第二部分。在第一部分中,我们学习了如何正确设置环境、配置 Node.js 客户端、索引数据以及进行搜索。在第二部分中,我们将学习如何实现生产环境中的最佳实践,并在无服务器环境中运行 Elasticsearch Node.js 客户端。
我们将回顾:
- 生产环境最佳实践
- 错误处理
- 测试
- 无服务器环境
- 在 Elastic Serverless 上运行客户端
- 在函数即服务环境中运行客户端
你可以在这里查看包含示例的源代码。
生产环境最佳实践
错误处理
Elasticsearch 的 Node.js 客户端的一个有用功能是,它会暴露出可能出现的 Elasticsearch 错误对象,这样你就可以用不同的方式进行验证和处理。
要查看所有错误对象,运行以下命令:
const { errors } = require('@elastic/elasticsearch')
console.log(errors)让我们回到搜索示例,处理一些可能出现的错误:
app.get("/search/lexic", async (req, res) => {
....
} catch (error) {
if (error instanceof errors.ResponseError) {
let errorMessage =
"Response error!, query malformed or server down, contact the administrator!";
if (error.body.error.type === "parsing_exception") {
errorMessage = "Query malformed, make sure mappings are set correctly";
}
res.status(error.meta.statusCode).json({
erroStatus: error.meta.statusCode,
success: false,
results: null,
error: errorMessage,
});
}
res.status(500).json({
success: false,
results: null,
error: error.message,
});
}
});特别是 ResponseError,会在响应为 4xx 或 5xx 时出现,意味着请求不正确或服务器不可用。
我们可以通过生成错误的查询来测试这种类型的错误,比如尝试在 text 类型字段上执行 term 查询:
默认错误:
{
"success": false,
"results": null,
"error": "parsing_exception\n\tRoot causes:\n\t\tparsing_exception: [terms] query does not support [visit_details]"
}自定义错误:
{
"erroStatus": 400,
"success": false,
"results": null,
"error": "Response error!, query malformed or server down; contact the administrator!"
}我们也可以以特定方式捕捉和处理每种类型的错误。例如,我们可以在出现 TimeoutError 时添加重试逻辑。
app.get("/search/semantic", async (req, res) => {
try {
...
} catch (error) {
if (error instanceof errors.TimeoutError) {
// Retry logic...
res.status(error.meta.statusCode).json({
erroStatus: error.meta.statusCode,
success: false,
results: null,
error:
"The request took more than 10s after 3 retries. Try again later.",
});
}
}
});测试
测试是保障应用稳定性的关键。为了在与 Elasticsearch 隔离的情况下测试代码,我们可以在创建集群时使用库 elasticsearch-js-mock。
这个库允许我们实例化一个与真实客户端非常相似的客户端,但它会根据我们的配置进行响应,只替换客户端的 HTTP 层为模拟层,其他部分保持与原始客户端一致。
我们将安装 mocks 库和用于自动化测试的 AVA。
npm install @elastic/elasticsearch-mock
npm install --save-dev ava我们将配置 package.json 文件来运行测试。确保它如下所示:
"type": "module",
"scripts": {
"test": "ava"
},
"devDependencies": {
"ava": "^5.0.0"
}现在让我们创建一个 test.js 文件并安装我们的模拟客户端:
const { Client } = require('@elastic/elasticsearch')
const Mock = require('@elastic/elasticsearch-mock')
const mock = new Mock()
const client = new Client({
node: 'http://localhost:9200',
Connection: mock.getConnection()
})现在,添加一个语义搜索的模拟:
function createSemanticSearchMock(query, indexName) {
mock.add(
{
method: "POST",
path: `/${indexName}/_search`,
body: {
query: {
semantic: {
field: "semantic_field",
query: query,
},
},
},
},
() => {
return {
hits: {
total: { value: 2, relation: "eq" },
hits: [
{
_id: "1",
_score: 0.9,
_source: {
owner_name: "Alice Johnson",
pet_name: "Buddy",
species: "Dog",
breed: "Golden Retriever",
vaccination_history: ["Rabies", "Parvovirus", "Distemper"],
visit_details:
"Annual check-up and nail trimming. Healthy and active.",
},
},
{
_id: "2",
_score: 0.7,
_source: {
owner_name: "Daniel Kim",
pet_name: "Mochi",
species: "Rabbit",
breed: "Mixed",
vaccination_history: [],
visit_details:
"Nail trimming and general health check. No issues.",
},
},
],
},
};
}
);
}现在,我们可以为代码创建一个测试,确保 Elasticsearch 部分始终返回相同的结果:
import test from 'ava';
test("performSemanticSearch must return formatted results correctly", async (t) => {
const indexName = "vet-visits";
const query = "Which pets had nail trimming?";
createSemanticSearchMock(query, indexName);
async function performSemanticSearch(esClient, q, indexName = "vet-visits") {
try {
const result = await esClient.search({
index: indexName,
body: {
query: {
semantic: {
field: "semantic_field",
query: q,
},
},
},
});
return {
success: true,
results: result.hits.hits,
};
} catch (error) {
if (error instanceof errors.TimeoutError) {
return {
success: false,
results: null,
error: error.body.error.reason,
};
}
return {
success: false,
results: null,
error: error.message,
};
}
}
const result = await performSemanticSearch(esClient, query, indexName);
t.true(result.success, "The search must be successful");
t.true(Array.isArray(result.results), "The results must be an array");
if (result.results.length > 0) {
t.true(
"_source" in result.results[0],
"Each result must have a _source property"
);
t.true(
"pet_name" in result.results[0]._source,
"Results must include the pet_name field"
);
t.true(
"visit_details" in result.results[0]._source,
"Results must include the visit_details field"
);
}
});让我们运行测试。
npm run test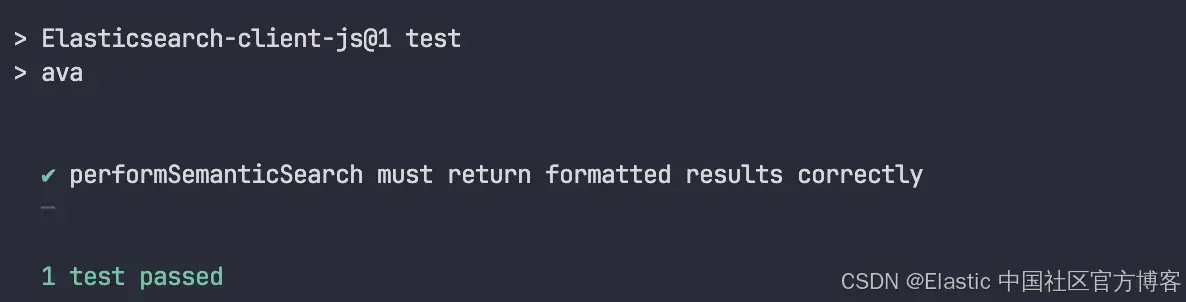
完成!从现在起,我们可以 100% 专注于代码本身进行测试,而不受外部因素影响。
无服务器环境
在 Elastic Serverless 上运行客户端
我们之前讲过在 Cloud 或本地运行 Elasticsearch;不过,Node.js 客户端也支持连接到 Elastic Cloud Serverless。
Elastic Cloud Serverless 允许你创建项目,无需担心基础设施,因为 Elastic 会内部处理,你只需关注要索引的数据及其保留时长。
从使用角度看,Serverless 将计算和存储解耦,为搜索和索引提供自动扩展功能,这样你只需扩展实际需要的资源。
客户端对连接 Serverless 做了以下适配:
- 关闭嗅探(sniffing)功能,忽略所有与嗅探相关的选项
- 忽略配置中除第一个节点外的所有节点,忽略任何节点过滤和选择选项
- 启用压缩和
TLSv1_2_method(与配置 Elastic Cloud 时相同) - 为所有请求添加
elastic-api-versionHTTP 头 - 默认使用
CloudConnectionPool,而非WeightedConnectionPool - 关闭内置的
content-type和accept头,使用标准 MIME 类型
连接无服务器项目时,需要使用参数 serverMode: serverless。
const { Client } = require('@elastic/elasticsearch')
const client = new Client({
node: 'ELASTICSEARCH_ENDPOINT',
auth: { apiKey: 'ELASTICSEARCH_API_KEY' },
serverMode: "serverless",
});在函数即服务(function-as-a-service)环境中运行客户端
在示例中,我们使用了 Node.js 服务器,但你也可以使用函数即服务环境连接,比如 AWS Lambda、GCP Run 等函数。
'use strict'
const { Client } = require('@elastic/elasticsearch')
const client = new Client({
// client initialisation
})
exports.handler = async function (event, context) {
// use the client
}另一个例子是连接到像 Vercel 这样的无服务器服务。你可以查看这个完整示例,了解如何操作,但搜索端点中最相关的部分如下:
const response = await client.search(
{
index: INDEX,
// You could directly send from the browser
// the Elasticsearch's query DSL, but it will
// expose you to the risk that a malicious user
// could overload your cluster by crafting
// expensive queries.
query: {
match: { field: req.body.text },
},
},
{
headers: {
Authorization: `ApiKey ${token}`,
},
}
);该端点位于 /api 文件夹中,从服务器端运行,这样客户端只控制对应搜索词的 “text” 参数。
使用函数即服务的意义在于,与 24/7 运行的服务器不同,函数只在运行时启动机器,完成后机器进入休眠状态,减少资源消耗。
如果应用请求不多,这种配置很方便;否则成本可能较高。你还需考虑函数的生命周期和运行时间(有时仅几秒)。
总结
本文中,我们学习了如何处理错误,这在生产环境中至关重要。还介绍了如何在模拟 Elasticsearch 服务的情况下测试应用,这样测试更可靠,不受集群状态影响,能专注于代码。
最后,我们演示了如何通过配置 Elastic Cloud Serverless 和 Vercel 应用,搭建完全无服务器的架构。
原文:Elasticsearch in JavaScript the proper way, part II - Elasticsearch Labs


















 1441
1441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









