








一|大数据的四大阵营是什么?

二|浅谈流数据处理阵营
数据流管理来自于这样一个概念:
数据的价值随着时间的流逝而降低,所以需要在事件发生后尽快进行处理,最好是在事件发生时就进行处理(即实时处理),对事件进行一个接一个处理,而不是缓存起来进行批处理(如Hadoop)。在数据流管理中,需要处理的输入数据并不存储在可随机访问的磁盘或逻辑缓存中,它们以数据流的方式源源不断地到达。
数据流通常具有如下特点:

· 实时性(Real-time):数据流中的数据实时到达,需要实时处理。
· 无边界(Unbounded):数据流是源源不断的,大小不定。
·复杂性(Complex):系统无法控制将要处理的新到达数据元素的顺序,无论这些数据元素是在同一个数据流中还是跨多个数据流。
流数据处理阵营有两类解决方案:
·流数据处理:Spark Streaming、Storm、Apache Flume、Flink等。
·复杂时间处理与事件流处理(CEP/ESP):Esper、SAP ESP、微软StreamInsight等。
在分别介绍这两类解决方案前,我们先温习一下大数据处理的两种通用方法:
MPP与MapReduce,这两种方法的共同点就是采用分而治之的思想,把具体计算迁移到各个子节点,主节点只承担任务协调、资源管理、通信管理等工作。通过这种方式,集群的处理能力往往和节点数量线性相关,面对海量数据,自然也游刃有余。
针对海量数据,这两种方式都强调计算要发生在本地,就是说,在分配任务的时候,尽可能让任务从本地磁盘读取输入。不过,在流处理的应用场景下,这两种处理方式都遇到了不可克服的困难。一方面,当数据源源不断地流入系统,不同时间段数据产生的频率和分布都有可能发生很大的变化,但是系统对于数据的这种变化理解有限,很难有效地进行预测,从而发展出有效的分治算法。其次,常用的方式都是批处理,就是说,系统创建特定任务来处理给定的数据,处理完毕以后,任务就结束了。这种批处理的方式处理流数据,显然不合适。另一方面,流处理系统的适用场景往往对系统反应时间有苛刻的要求,比如,高频交易系统需要在极短时间内完成计算并做出正确的决定,MPP与MapReduce类系统面对这个挑战都难以胜任。
人们也试图在这两种方式的基础上开发出适合流数据的系统。比如Facebook公司在开发Puma的时候,一个最终没有被采用的设计方案就是把源源不断产生的数据都保存到HDFS中去,然后每隔特定的时间(比如每分钟)都创建一个新的MapReduce任务来处理新的数据,从而得到结果。种种权衡之后,这个方案没有被采用,一个可能的原因就是这个方案还是不能保证系统的低延时(不能在指定时间内返回相应的结果)。为此,工业界实现不少分布式流计算平台,在早期(2011—2012年前后)影响力比较大的有Twitter公司的Storm、EsperTech公司的Esper以及Yahoo!公司的S4,不过后来随着Apache Spark的崛起,涌现了一批新的流数据处理架构,如Spark Streaming、Apache Flume、Apache Flink等解决方案。
值得一提的是,CEP类型的大多为商业解决方案(Esper提供开源版本,不过EsperTech主要靠卖商业版Esper Enterprise讨生活),而基于流数据处理架构的解决方案则以开源为主。我们下面分别了解一下Storm和Esper系统架构。
(1)Storm系统
关注大数据的人对Storm应该不会陌生,Storm由一家叫BackType的小公司的创始人Nathan Marz开发。后来BackType公司被Twitter公司收购,于2011年9月17号把Storm开源,并于2013年9月进入Apache软件基金会孵化,2014年9月17号正式成为基金会一级项目。
Storm核心代码是由Clojure这门极具潜力的函数式编程语言开发的(Clojure可以被看作Lisp语言的变种,支持JVM/CLR/JavaScript三大引擎,由于它无缝连接了Lisp与Java,业界认为Clojure兼具美学+实用特性,从而一经面世便游行开来),这也使得Storm格外引人注目。

Storm体系架构中主要有两个抽象化概念需要先行了解。
· 拓扑(topologies):可以比作Hadoop上的MapReduce jobs,主要的区别在于MapReduce jobs早晚会结束,而topologies永无休止(流数据的无边界特征),每个拓扑由一系列的Spout和Bolt构成,见下图左👇。
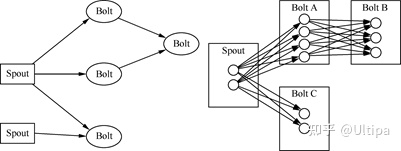
图:Storm topologies, Bolt级联以及stream grouping
·数据流(streams):streams是由连续的元组(tuples)构成的。它是在构成拓扑的Spout与Bolt之间流动。Spout负责产生数据(如事件),Bolt负责处理接收到的数据,Bolt可以级联,见上图右👆。
在定义一个Storm topology过程中需要给Bolt指定接受哪些streams的数据。一个stream grouping定义了如何在Bolt的任务中对stream来分区。Storm提供了八种原生的stream groupings:Shuffles、Fields、Partial Keys、Global、None、Direct、Local以及All grouping,其中Shuffle grouping保证事件在Bolt实例间随机分布,每个实例都收到相同数量的事件。
Storm集群与Hadoop颇为类似(想必是受了Hadoop的启发,毕竟大规模分布式大数据处理系统开源之鼻祖是Hadoop,而且它的HDFS与MapReduce的设计那是相当值得借鉴),由Master节点与Worker节点们构成,Master上跑着Nimbus守护进程(daemon),类似于Hadoop的JobTracker,负责在集群中分发代码,分配任务,监控集群等,见下图👇。

图:Storm集群组件
Worker节点上运行的守护进程叫Supervisor,负责接收被分配的任务,启动或停止Worker进程等。每个Worker进程处理一个topology的子集,一个topology可以包含可能跨多台机器的多个Worker进程。
Nimbus与Supervisor之间的协作通过Zookeeper(Apache Zookeeper是一套分布式的应用协调服务,提供包括配置、维护、域名、同步、分组等服务)集群来实现。Nimbus与Supervisor守护进程都是无状态(Stateless)且故障自保险(Fail-Safe)的,它们的状态都保持在Zookeeper或本地磁盘上,就算是杀掉了Nimbus或Supervisor进程,重启后还会继续正常工作。这样的设计保证了Storm集群的高度稳定性。

图:storm集群在生产环境部署之后,通常会是如下的结构
有一点需要指出的是,基于Storm的应用,在逻辑上,都是有向无环图(DAG = Directed Acylic Grapah),其中的spout和bolt作为顶点,stream作为有向边。这个和区块链的底层架构也是DAG是殊途同归的。笔者不禁想到:如果我们所处的这个高维的世界用图来描述、表达、还原、模拟是最天然的,那么我们需要正视一个问题:为什么我们不用高维的图数据库来完成这些工作呢?
不过,到了21世纪的第三个十年,已经越来越多的人意识到,Storm(还有包括Kafka、Spark、Apex等)这种基于批量文件处理的架构(Batch-file-based-processing),实际上是在模拟真正的流处理,因此它们的性能也会相对而言有明显的瓶颈。对于高效、高性能数据处理的诉求,无论是不是流的方式,永远不会停止。
(2)CEP系统
让我们来看一下CEP系统与解决方案的设计理念。绝大多数CEP方案可以分为两类:
· 面向汇聚(Aggregation-oriented)的CEP;
· 面向侦测(Detection-oriented)的CEP。
前者主要对流经的事务数据执行在线算法(Online-Algorithms),例如对数据流进行均值、中间值等计算;后者主要对数据流中的数据是否会形成某种趋势或模式进行探测。
而我们要关注的Esper则对以上两种方案兼而有之,它是EsperTech公司的CEP产品,整体架构有三大组件,见下图👇:EsperEE设计架构图

· Esper引擎:有Java和.Net(C#)两大版本,.Net版本前面有个N,叫作NEsper,这两个引擎都是开源的。
· EsperEE:熟悉Java的一眼就可以看出,这是闭源企业版(Enterprise Edition)。
· EsperHA:提供high-availability(高度可用性),也意味着fast-recovery(快速故障或宕机恢复),EsperHA还支持高性能的写操作。
Esper扩展了SQL-92标准,实现了一种私有化语言EPL(Event-Processing Language),非常适合对时间序列数据进行分析处理以及侦测事件发生,它提供了聚集(Aggregation)、模式匹配(Pattern Matching)、事件窗口(Event Windowing)以及联表(Joining)等功能。对于熟悉SQL语言的人,EPL非常容易上手,例如在Esper系统中当发现3分钟内有超过(含)5个事件发生的条件得到满足时立刻报告,只需要如下简单的操作:
select count(*) from OrderEvent.win:time(3 min) having count
(*) >= 5
最后,作为本节的总结,我们从可靠性、运维、成本、实时性、数据规模等维度考察NoSQL、Hadoop、RDBMS与流处理架构,它们的优劣比较如下图所示👇。

很显然,目前为止,没有任何一款单一的大数据架构是完美的。数据规模大的,就很难保证系统响应实时性,可以实现复杂的强一致性的系统,成本必然不会很低,运维起来恐怕也十分复杂。在实践中我们通常会根据业务具体需求与预期,把两种或多种大数据解决方案组合在一起,例如Hadoop的HDFS可以被解耦出来作为一个通用的数据存储层(Data-Persistence Layer),NoSQL用来提供可交互查询后台,关系型数据库依然可以被用来做关系型数据的实时查询……下图示意了这样一种多方案融合而成的大数据平台架构方案。

不过(再一次),这种大数据平台的架构,虽然很流行,但是,流行并不代表它是最好的、最合理的、最有性价比、最有可扩展性、最高性能的,更不代表它是最高效的。大多数IT从业人员都习惯于采用已成既定现实的所谓的主流架构,但是并没有认真去分析业务的诉求,当下与未来的诉求和发展趋势。
今天,已经没有人会反对Hadoop已死的提法,虽然HDFS与MapReduce的这种分而治之的理念本身会经久不衰,但是这种15年前兴起的用堆廉价机器的方式构造大规模集群来分布式处理的思路,已经遇到越来越多的障碍 -- 它的效率太低,无法有效解决商业诉求,其次,它的硬件成本、运维成本也不低。最核心的问题是:基于Hadoop类的解决方案的硬件利用率极低,特别是对于处理器高并发啊算力的利用率(释放程度)极低。这也直接导致近年来Hadoop的市场江河日下,类似的,Storm已经越来越少人提起了,我们甚至可以预言几年内Spark阵营也会走下坡路。
当然,传统关系型数据库、数仓也遇到了不一样的挑战 -- 所谓分布式关系型数据库和NewSQL类数据库、数仓的挑战。IT行业的残酷性在于,有太多无中生有、微创新类的产品和解决方案,让用户很多时候无所适从,因为我们时常忘了商业的本质是什么 -- 是解决问题、多快好省的解决问题。大数据的4大阵营分别解决了不同类型的挑战,在很多时候,因为挑战是多重的,因此多个阵营的方案可能会融合,例如HTAP融合了OLTP+OLAP,这个也是近两年兴起的一大数据库发展潮流;另一方面,从数据生命周期和流转的角度,流处理+HTAP+MPP架构,就已经把四大阵营4合1了。以笔者在Ultipa图数据库的经验,Ultipa的架构采用的就是Shared-Nothing MPP架构,集群内支持HTAP(TP节点与AP节点共存),在金融等场景内数据就是先通过流处理流入图数据库的(当然也可以反向流出进入其它数据生命周期环节),这就是一种典型的大数据四阵营合一的打法。
·End·
















 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









