






上几篇为读者归纳总结了大量基于真实业务场景的图系统评测需求。那么,在本篇内容中,老夫会对评测的结果进行分析,并把其中一些值得探讨的、并非显而易见的测试内容与大家分享,同时给出优化建议。
本篇将按照上一篇中出现的测试内容以倒序的方式来摘选一些图系统执行测试项的结果进行分析。(大家可以在专栏中,找前面的文章。)
·Node2Vec算法
·其他算法
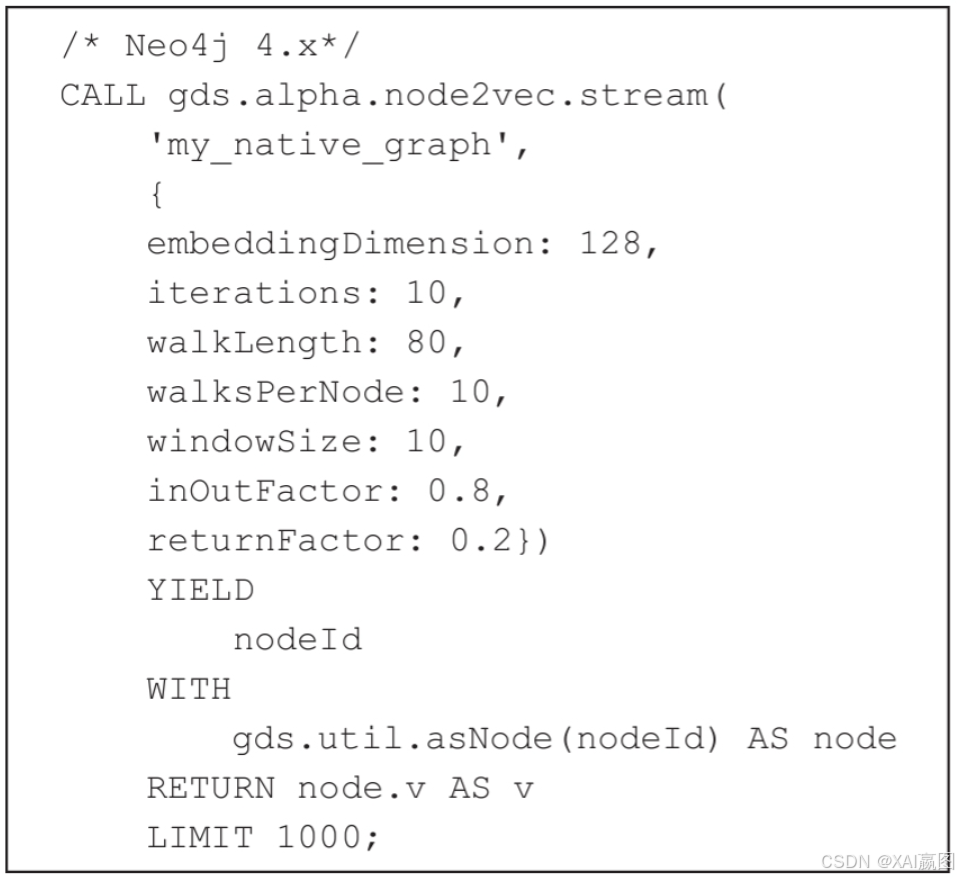
在Node2Vec算法评测中,我们对比了Neo4j的企业级4.x版本与Ultipa 3.x版本的实现效果,两套系统的查询语句分别如图1和图2所示。
单纯从语法上看,并不能看出两个系统处理该算法的底层逻辑,但是我们知道Neo4j默认采样1000条路径(walkBufferSize=1000),并在采样完成后直接返回。而评测的需求则是完成全图采样后,限定返回其中1000条路径。这两者之间的算法复杂度的差别在10亿级别的图上足足有1 000 000倍!因此,Neo4j系统的默认采样1000条路径后随即返回是非常典型的错误,而在10亿数据量级和遍历深度与复杂度条件下,该系统无法完成Node2Vec算法评测。

我们知道,如果采样1000条的深度路径需要1s,全部采样10亿条路径则需要约100万s(12天),那么怎样优化图系统才能在有限的硬件资源条件下及时完成Node2Vec评测呢?
笔者认为最主要的是以下两点:
·高并发架构
·低延时数据结构
以上两点隐含地表达了如下的优化路径:
·最大限度降低磁盘(含硬盘)IO;
·充分利用内存计算;
·采用多级存储及缓存策略;
·采用低延时、高并发友好的编程语言及计算架构。
显然,如果用Python来实现Node2Vec,相信以现有的计算机体系架构能完成以上Node2Vec评测的概率为0,最主要的原因无外乎其执行效率低下、串行,完全不适合作为数据库级别的系统编程语言。
然而,换成Java可以吗?笔者认为在应用层Java构建了庞大而成熟的框架体系,但是作为数据库系统的底层语言,Java和C/C++/Go/Rust相比,劣势较为明显,特别是在对算力要求高、延时低的环境下,无论是JVM还是GC都不利于完成Node2Vec类较复杂算法的评测。
类似地,在有一些算法评测中,例如PageRank,较为复杂的(也更贴近真实应用场景)评测需求会要求全局迭代计算PR值完毕后,再对全量结果进行排序,并返回前50个结果。从算法正确性角度来看,PageRank算法的正确实现要求进行全局迭代完成后才能得出每个顶点的Rank值。在最差的情况下,也要在每个顶点当前所处的连通分量内完成全局迭代。如果在一个远远大于50个顶点的连通分量中,仅计算50个顶点的Rank值即返回是明显的算法逻辑错误。即便我们很难手工去验证一张大图(10亿级)中的每个顶点的PR值,但是如果该算法返回时间极短,且运行时系统资源(CPU、内存等)占用极低,可依此判断算法存在错误(或作弊)。
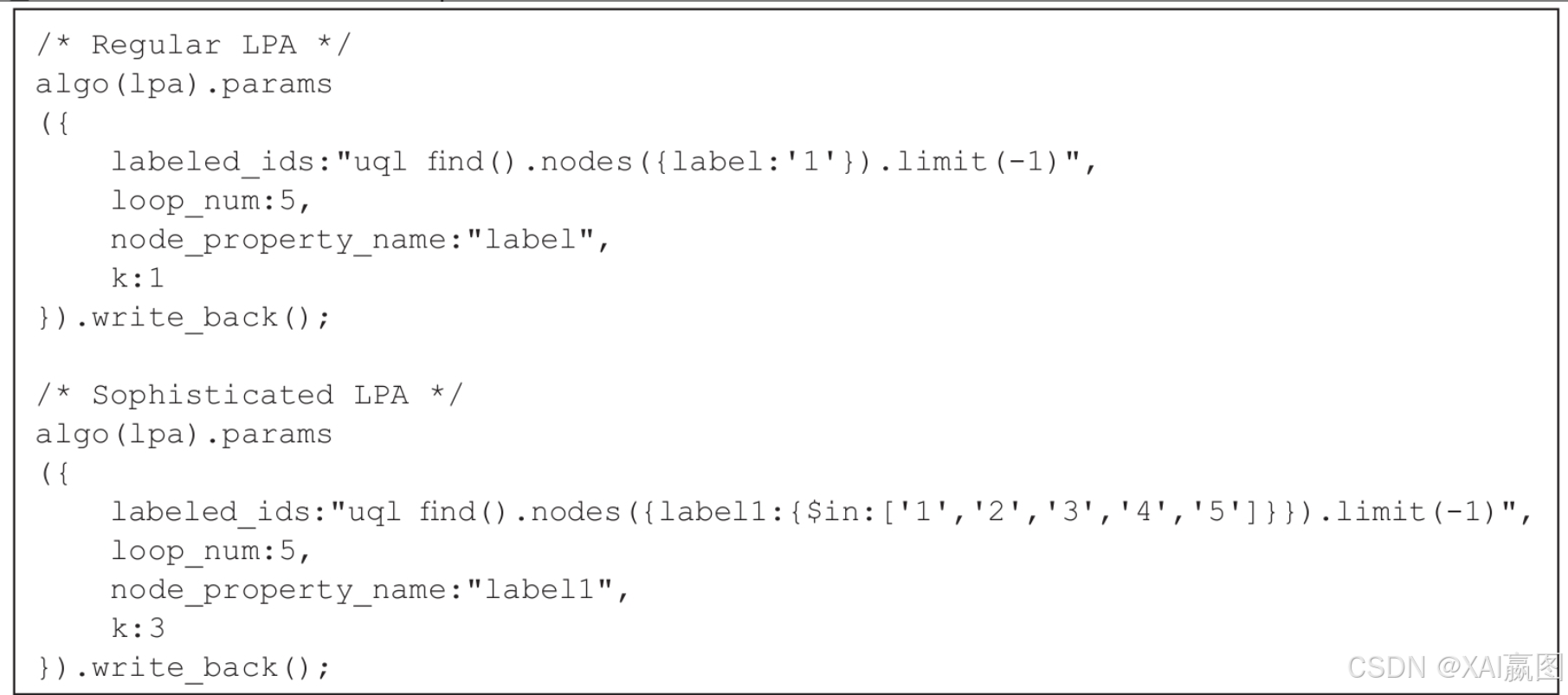
在LPA算法(即标签传播算法,Label Propagation Algorithm)的评测中,有两种模式,一种是原生LPA,另一种是增强LPA。
两个算法的运算逻辑分别如下,评测结果如表1所示:
·原生LPA:从5万个节点(label=1)出发,传播分类,迭代5轮后,结果回写;
·增强LPA:从5×1万个节点出发(label分别为1、2、3、4、5),传播分类,迭代5轮后,每个顶点保留3个最大概率的标签,回写结果。

图3示意了两种LPA算法调用语句,两种算法的调用方式非常接近。表1和图4记录了两种LPA算法的时效性,因为增强LPA的算法复杂度和回写内容较普通LPA更高(单标签与多标签),特别是回写内容,后者大概是前者的3倍,因此回写时间最终有约2倍的差异。
在图5~图8中罗列了2021年8月在某财富500中排名位于前50名的某知名跨国企业的先进实验室内对Ultipa与Neo4j两款图数据库系统在Alimama电商数据集(1.05亿点+边)上的图算法性能测试的对标结果。
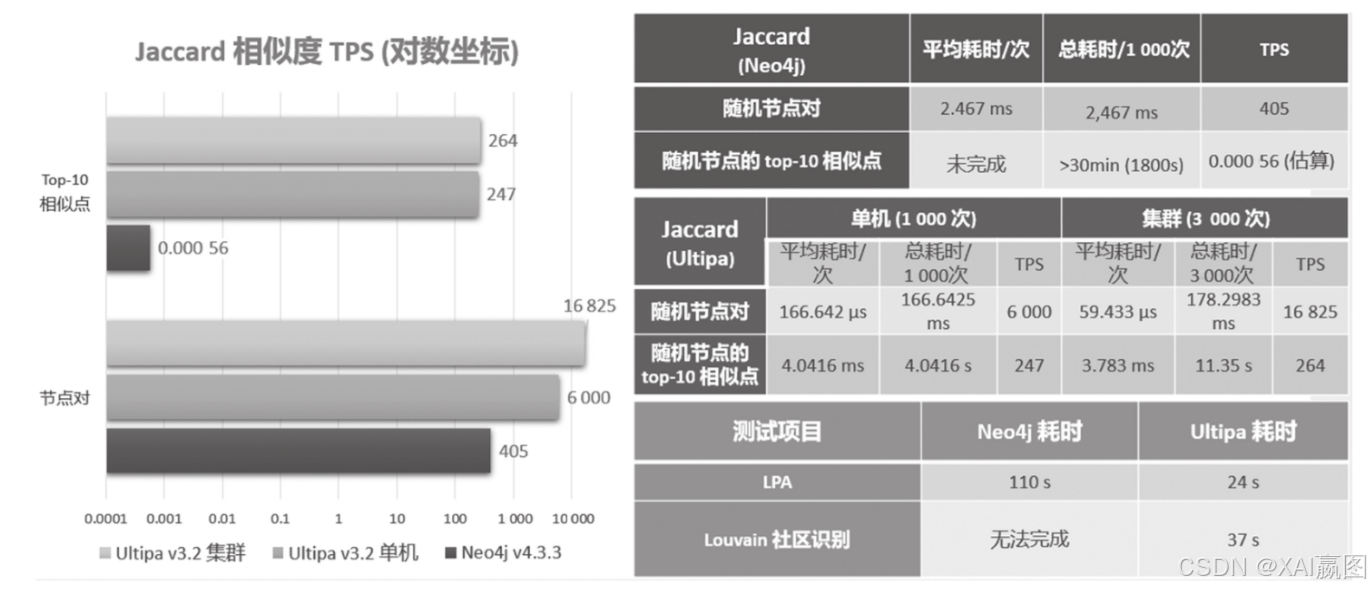
从图5所示的结果中可以看出:
·Neo4j在面对复杂算法(例如鲁汶)+较大数据量级(亿级或以上)时会遇到很大挑战,经常无法完成映射(projection,即从硬盘持久化层数据映射到内存数据结构来进行算法的迭代计算);
·Ultipa的3节点集群模式下的TPS可达单节点的3倍左右,体现出一种系统吞吐率随资源增长而线性增长的能力。该特性在深度查询、元数据查询场景中体现得更加明显。
在全图度算法评测中,我们做了3个维度的1000次随机计算,包含随机入度计算、随机出度计算、随机度计算。我们可以清晰地看到Ultipa与Neo4j系统的单节点对标性能差异在10倍以上,集群差异则在30倍以上,而这只是最简单、最浅层的元数据级别的操作,在深度查询中,两个系统的性能会有成百上千倍的落差。
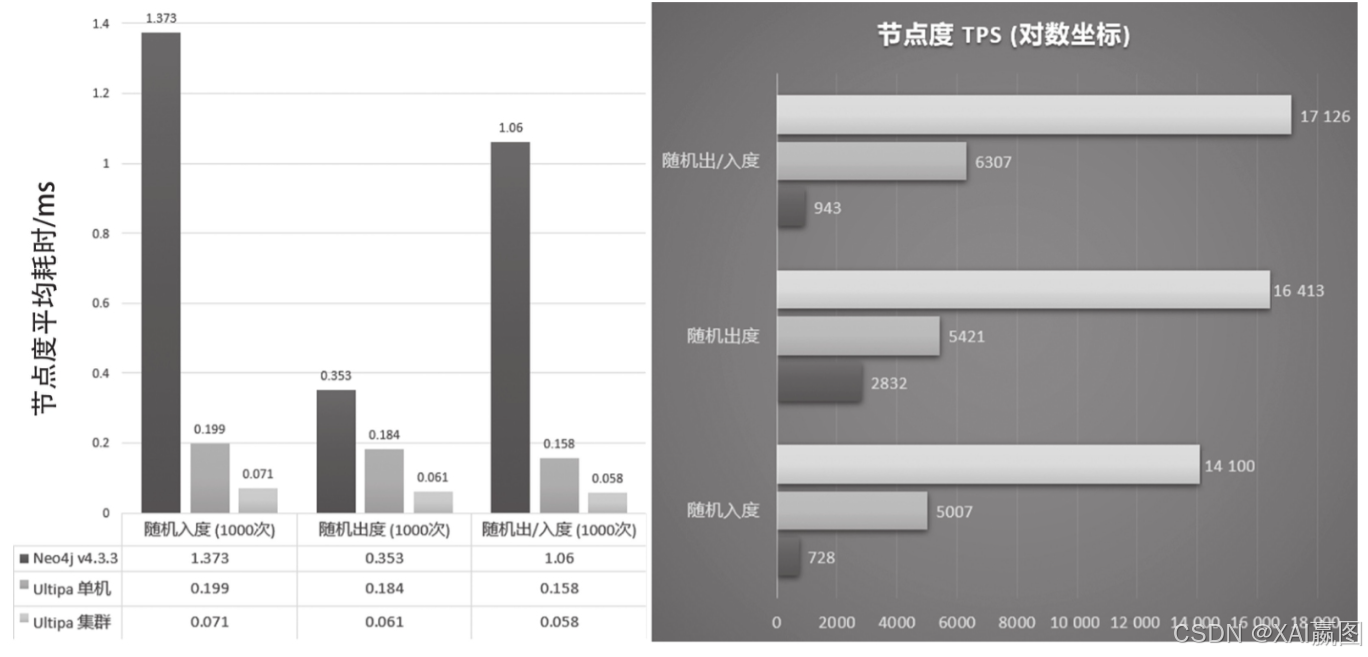
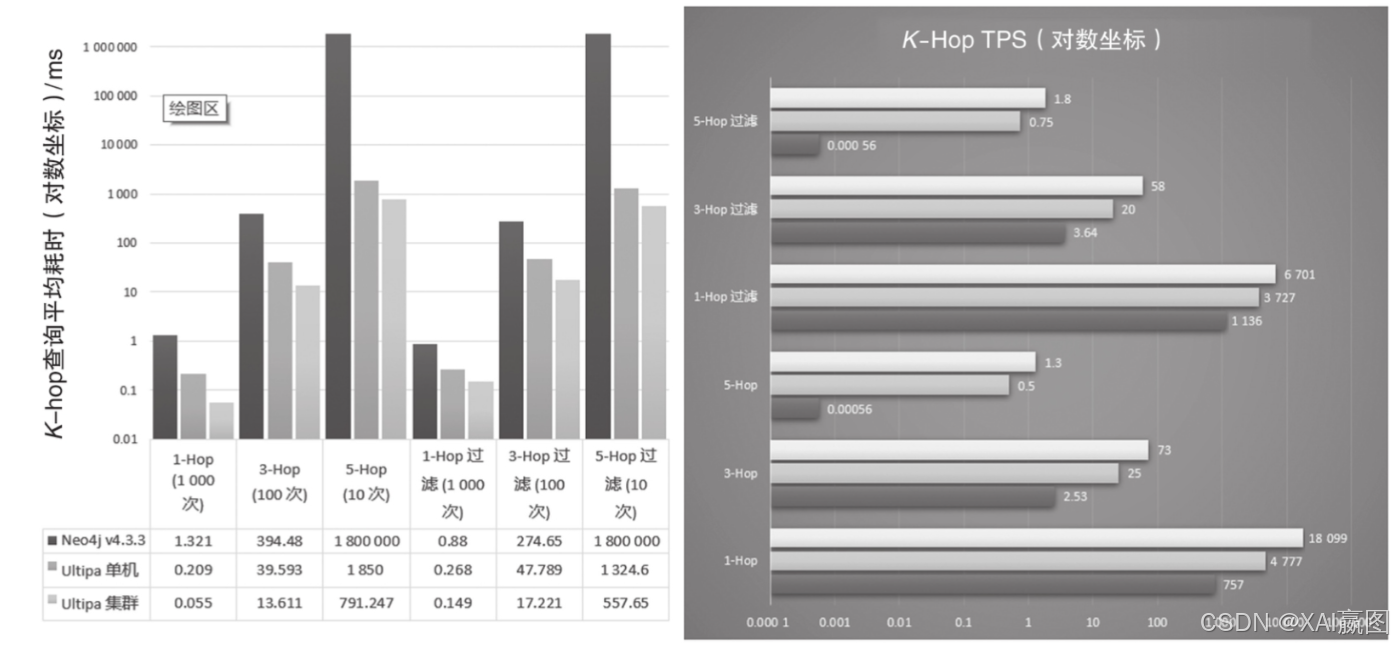
在K邻查询与路径查询中(如图7、图8所示),由浅及深地查询,Neo4j与Ultipa系统的差异从1层的5~10倍,3层时的30倍,再到5层时超出1000倍性能落差或完全无法返回结果。
在K邻查询中,有6个场景分别测试1、3、5层在无过滤和有过滤条件下查询操作的平均时延,因为测试数据集(alimama)属于连通度较高(E/V≥20,即点边数量比)的图集,在进行5度查询时,从每个顶点出发几乎会遍历全图,计算复杂度上升,这个时候Neo4j会骤然从3-Hop的平均400ms(无过滤)、275ms(有过滤)时延到10~30min内无法返回结果,而Ultipa系统则从14~17ms的耗时增长到558~791ms(理论上从3-Hop到5-Hop的计算复杂度变化为O((E/V)2)≈400)。在实际情况中,会因为点边的过滤条件导致动态剪枝,因为实际测试顶点的连通度而导致时耗增长仅为原来的40~50倍。
在路径查询中,我们用了9个子场景来测试1、3、5层深度的无过滤、最短路径以及有过滤条件下的两个系统的时耗比较。仔细观察在深度为1层的路径查询中,无论是Neo4j还是Ultipa,有过滤条件下时耗会略长于无过滤条件查询;而在深度为3层的查询中,两个系统的有过滤的时耗都会显著低于无过滤查询(类似地,在深度为5层的查询中,Ultipa系统也具有同样的特征)。出现以上特征的原因如下:
·在1层路径查询中,过滤条件相当于增加了计算量,故时耗会增长(Ultipa:20%;Neo4j:40%);
·在2层及以上的路径查询中,过滤相当于动态地对需要遍历的图数据集进行剪枝,因此可能实现更高效的返回,故时耗可能会大幅缩短(Ultipa:15倍;Neo4j:5倍);
·在5层及以上的深度查询中,因为动态剪枝以及图的连通度特征(最长最短路径约为5),Ultipa的有过滤条件下的时耗依然维持了亚毫秒级(0.524ms),而无过滤则因为计算复杂度的飙升,耗时12s才返回结果。Neo4j系统则自这个深度开始完全无法返回结果。
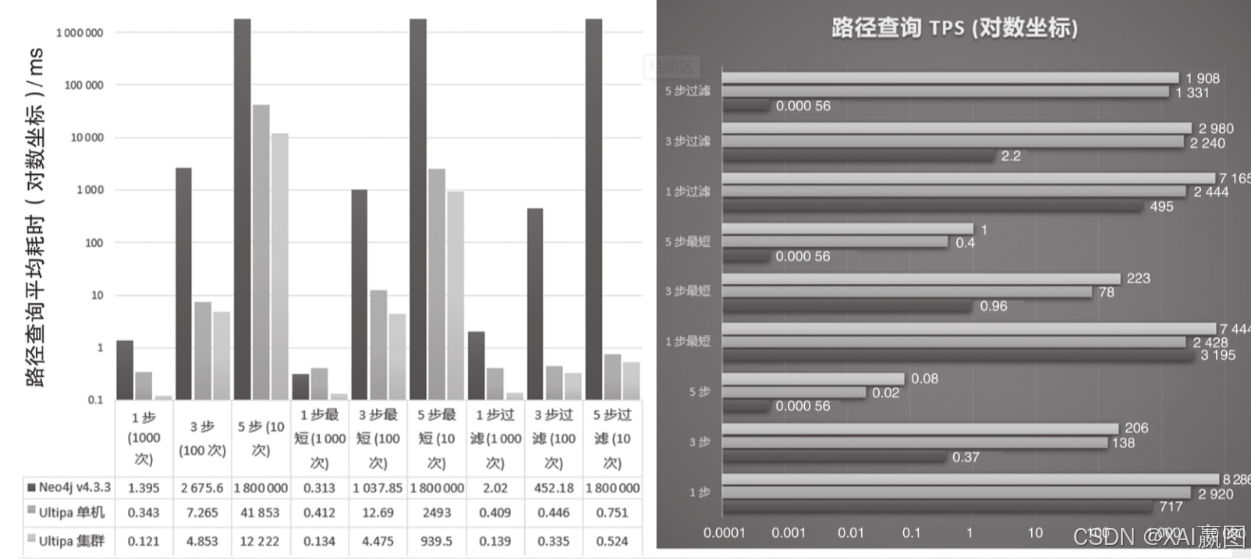
在大数据体量、复杂查询或复杂图算法场景中,Neo4j经常会出现无法成功返回的问题,由此可以推断出Neo4j的核心系统应对高算力需求的场景非常吃力。
但是,如果我们深究Neo4j的底层架构,就会明白它是基于Java/JVM架构的系统,在元数据计算和浅层计算时达到Ultipa系统的10%~15%已经代表了Java系统的极限(一般认为在相同的硬件基础上,Java程序的算力约为C++程序的1/7)。如果我们去关注市面上其他基于Java体系构建的系统,性能大概率还要比Neo4j低很多。
·GAP在3个算法上保持领先——广度优先(BFS)、单源最短路径(SSSP)以及连通分量计算(CC),并存在较明显的性能优势;
·其他图系统在另外3个算法(PR、BC、TC)上可能存在对GAP系统的性能优势;
·所有系统都大量使用了内存计算,甚至是高度地利用连续内存存储空间来实现最优化算法(缺点是所有数据结构都是静态只读的,一次加载后不能变更);
·需要为每一个算法专门定制优化的数据结构,因此需要每套数据集单独加载入图,完成5套数据集上的6个算法,需要加载30次(5×6)。
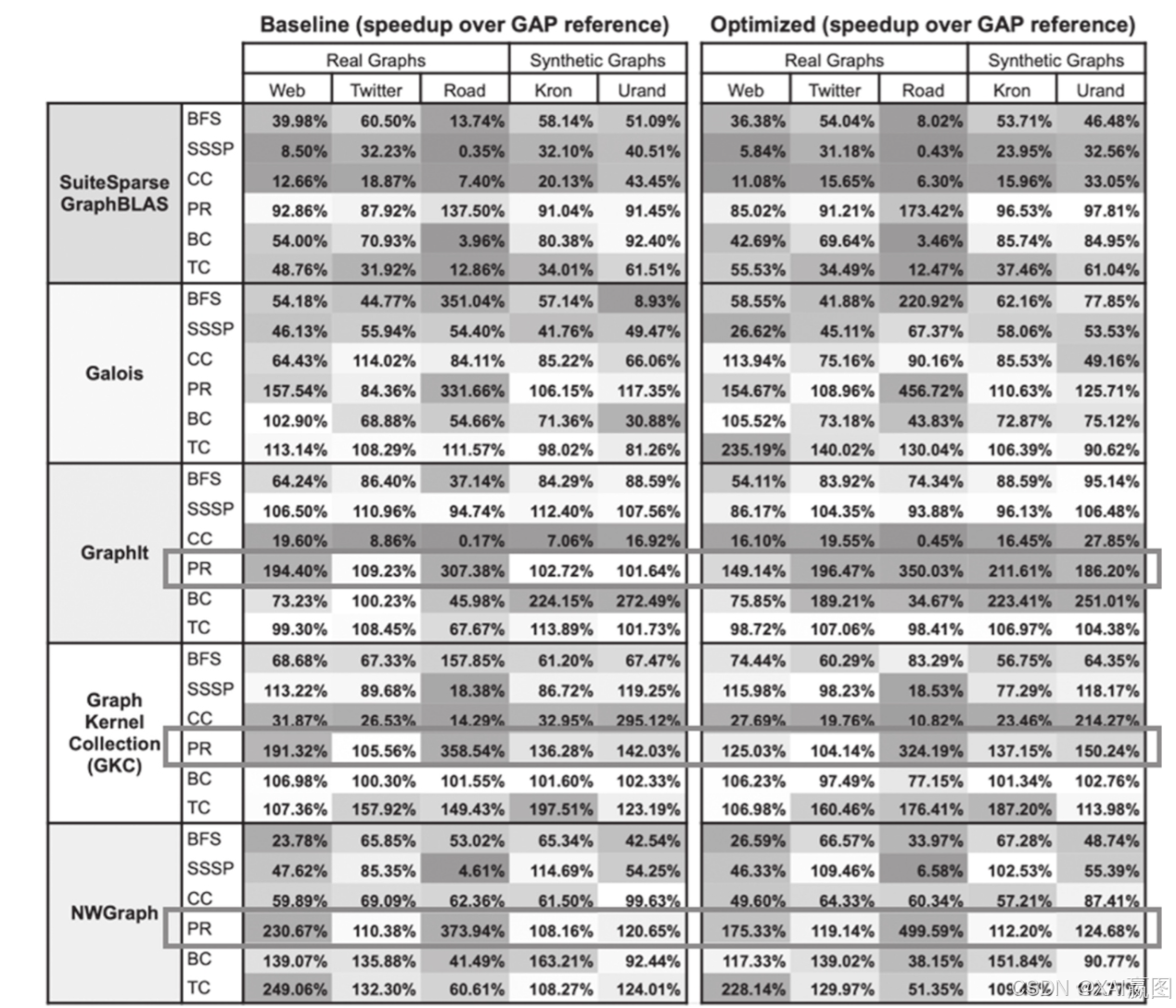
上面最后一点尤为令人难以接受。在实际的业务场景应用中,不可能为每一款算法去重新加载数据集,如若这样效率就太低了。GAP的整个测试也因此弥漫着浓郁的学术气息,不过大多源自学术界的图系统都有类似的问题,GAP并非特例。
我们把Ultipa v3.2系统做了一定的算法优化后与GAP参照系统进行了对标,Ultipa系统对每个数据集仅加载一次,在运行任何算法时无须单独加载。GAP较大的几个数据集全部运行完6个算法,每个数据集仅加载就需要1~2h的时间,而Ultipa则仅需5~27min,加速达7~19倍,节省了77%~95%的数据加载时间,如10所示。
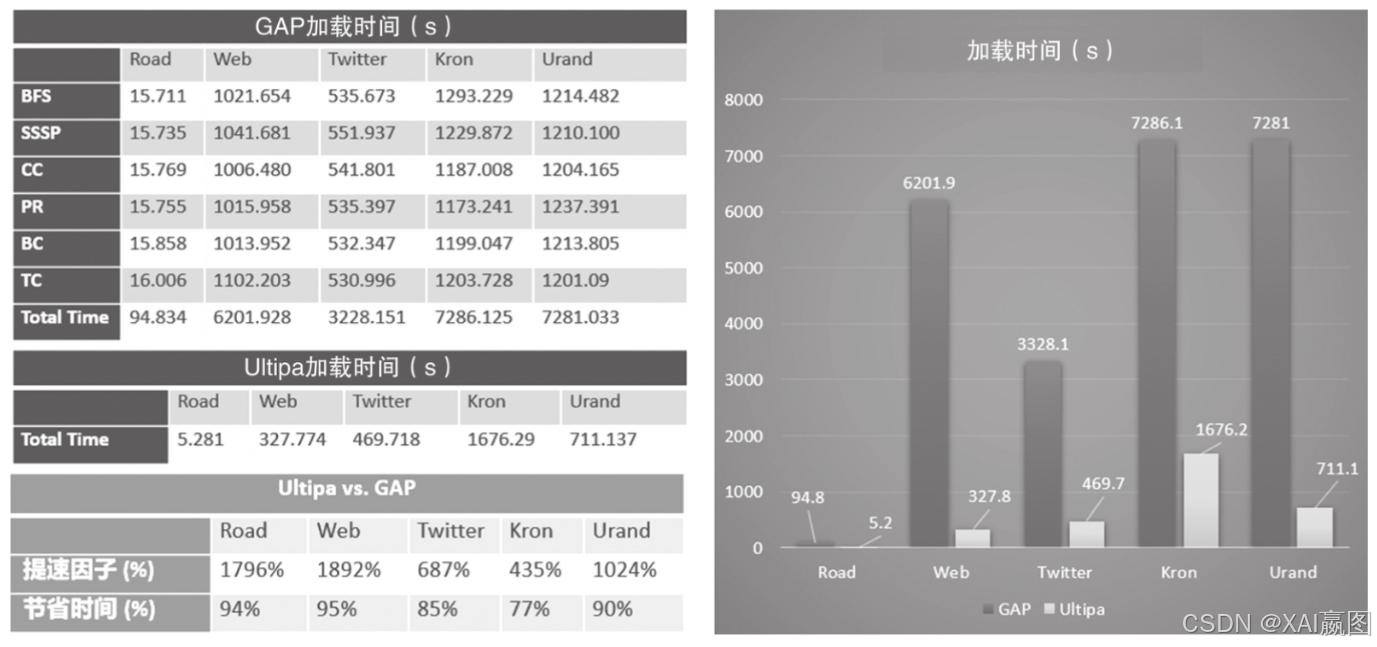
GAP参照系统(以及其他对标系统)为了达到性能的极致做了很多优化,具体如表2所示。
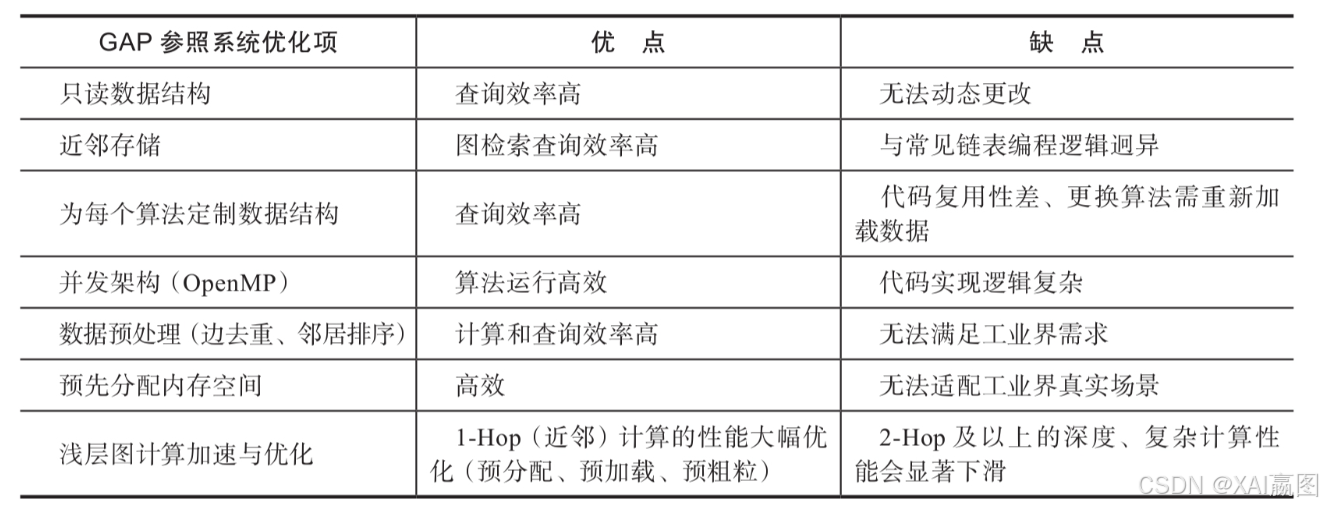
以上性能优化项中,很多是依赖明确的前提条件的,例如静态只读的数据、无须考虑并发读写上锁隔离的问题、可忽略的预处理数据时延问题、内存中使用连续存储数据结构,以及假设全部顶点都在同一连通分量中等。GAP参照系统在其BFS与BC算法实现中,假设全图只有1个连通分量,并在预处理的时候,预先在内存中分配需要自下而上遍历全部顶点的连续存储数据结构以获得极高的遍历效率——从图10的GAP系统与其他图系统的对标结果中也能看到其在BFS与BC算法上的性能优势达十几倍甚至二十几倍。在真实的业务场景中,预分配、预排序、完全连续(顺序)存储的可能性以及全图仅单一连通分量等情况都是可遇而不可求的。
相信不少读者和老夫一样,在对GAP系统进行了一些分析后,也好奇通用的图数据库系统在与GAP参照系统对标时,两者的差异性又是怎样的呢?
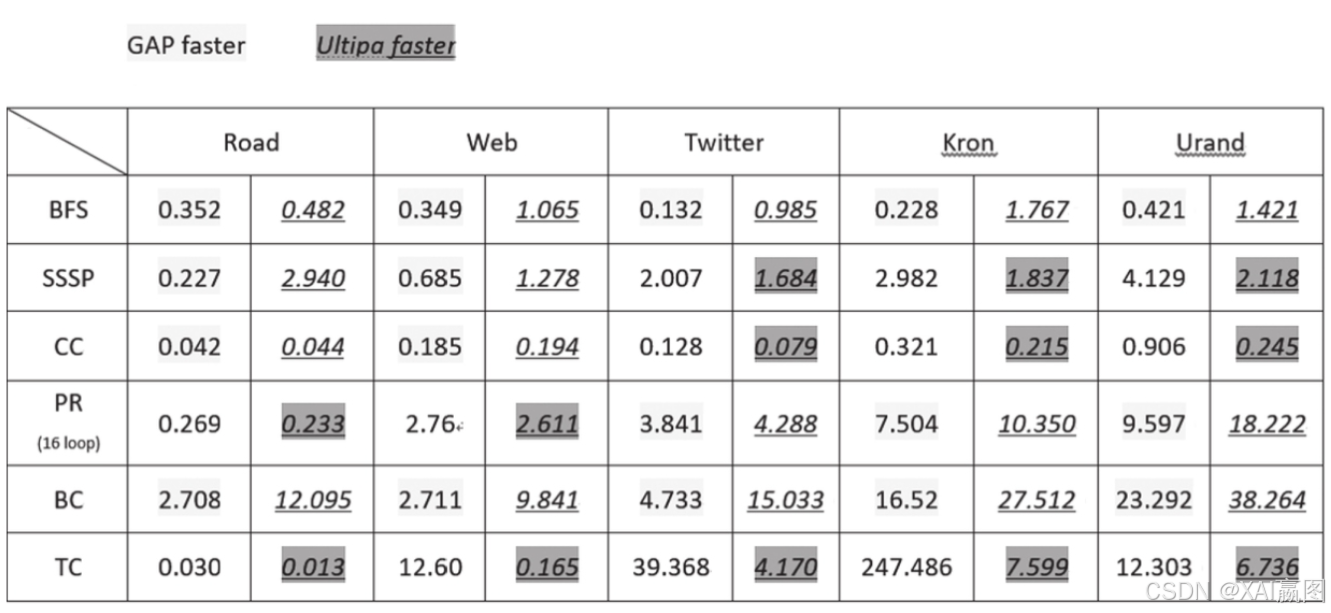
我们对Ultipa系统做了一些简单的改造(主要是新增实现了SSSP算法,关闭了算法文件系统回写功能,并在ULA license中对系统最大可并发规模进行了调整以充分利用底层硬件的多核并发能力)后,对标结果如图11所示,具体有以下几点值得一提:
·不出所料,GAP参照系统的BFS最短路径算法的优势为30%~800%;BC中介中心性算法的优势为40%~400%;
·TC(三角形计算)算法在Ultipa系统中有显著的优势,为200%~7600%;
·对于PR网页排序、SSSP单源最短路径与CC连通分量算法,两套系统则各有千秋。在SSSP与CC算法的大数据集场景下,以及在PR算法的中小数据集场景下,Ultipa系统具有优势;在其他场景下,GAP系统则较有优势。
最后来总结一下图系统的规划、评测与优化中的“要素”,有如下几点。
1)准确性与近似性:除了在一些特殊的图算法中通过近似计算来获得结果外,其他所有图上的查询与计算操作,准确性是第一位的。
2)集中式与分布式:分布式更适合浅层、简单查询;集中式适合深层、复杂查询。两者的有机融合是图系统的发展趋势。
3)架构-服务与真实业务场景结合:脱离业务的架构与服务都是空中楼阁,对于系统的构建毫无助益。
4)循序渐进的业务与场景规划:把图系统先用于增量场景、创新场景,而后再规划存量场景的替代问题。
5)真正影响图系统的受众规模和接受度取决于两点:
·系统易用性、工具易用性,是否直观、高效;
·图思维方式,把受众从二维关系表中拉出来进入到高维的图思维世界中是至关重要的。
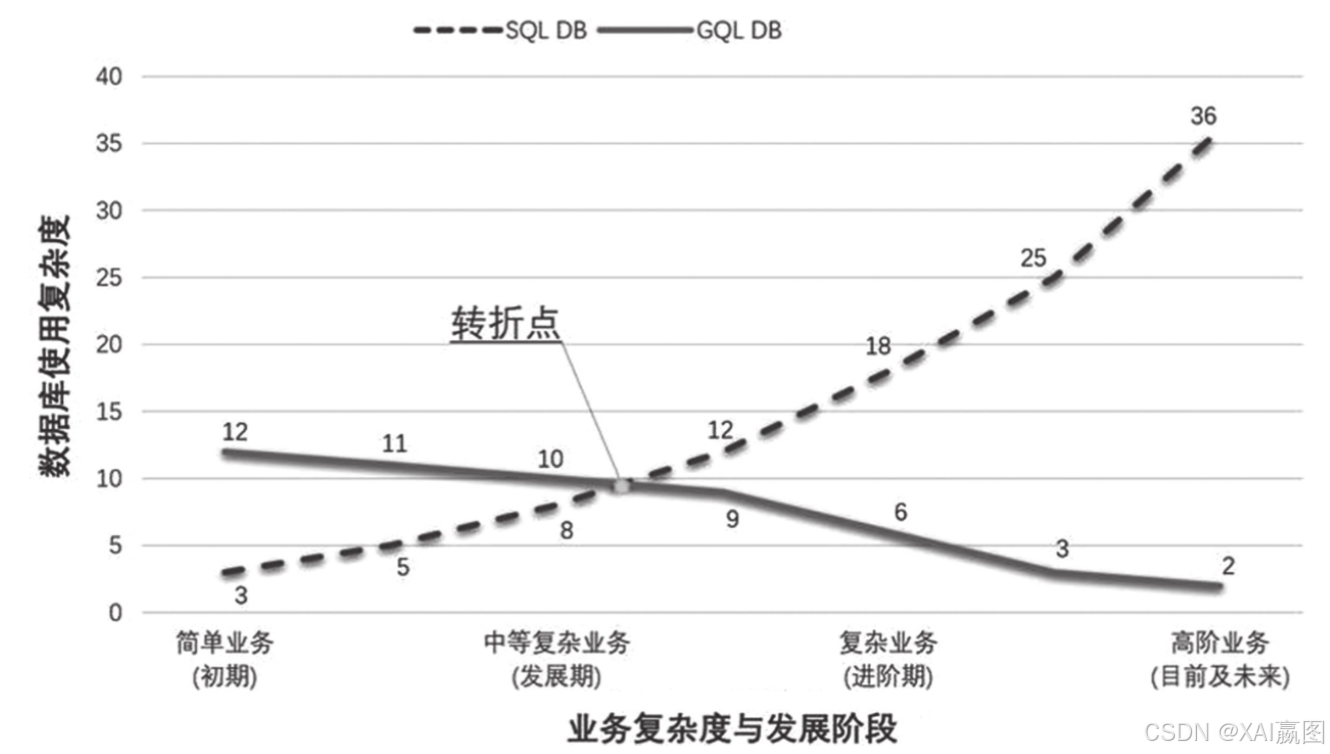
可以预见,在图(数据库)系统(GQL-DB)与SQL类数据库的互动和博弈中,一定是个此消彼涨的过程。SQL类数据库经过40年的发展,对业务的渗透极为广泛,入门门槛已经非常低了,但是绝大多数的使用都停留在浅层,随着应用场景的复杂度增加,SQL代码(和应用)的开发难度指数级上升,运行效率指数级下降,这也是为什么今天我们到处都能看到T+N(N≥1)的批处理场景。图数据库的特点是随着应用场景的复杂度增加,其应用开发与编程的复杂度相对SQL来说是降低的——两者会存在一个交汇点(如图12所示),在这个转折交汇点之后,GQL会快速地攻城略地。未来,GQL-DB一定会成为新一代的主流数据库。让我们拭目以待!
· END ·
(文/Ricky - HPC高性能计算与存储专家、大数据专家、数据库专家及学者)


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









