







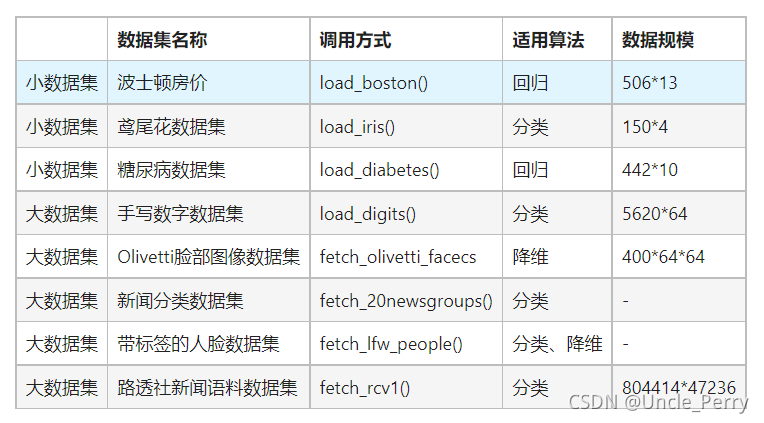
鸢尾花数据集
问题起源
在机器学习到分类问题时,使用sklearn下载数据集的时候,不是很明白具体怎么下载的,以及如何下载其他数据集,于是仔细思考了一番
查看鸢尾花数据集
首先先看代码块
#从sklearn数据集导入我们要的iris数据集,iris数据集调用在下方
from sklearn.datasets import load_iris
iris = load_iris()
#数据集并不能直接用,通过pandas的DataFrame来转化
import pandas as pd
#col是列名
col = list(iris["feature_names"])
#在iris数据集中,标签在"data"数组里,标记在"target"数组里
m1 = pd.DataFrame(iris.data,index=range(150),columns=col)
m2 = pd.DataFrame(iris.target,index=range(150),columns=["outocme"])
#将上述两张DataFrame表连接起来,how是DataFrame参数,可以不写,这里用外连接。不清楚外连接的可以看下SQL语句
m3 = m1.join(m2,how='outer')
#to_excel语句转化成excel格式,后缀名为.xls
m3.to_excel("./test.xls")

查看关于sklearn数据集的下载方式后,这两句代码就是照着来的
from sklearn.datasets import load_iris
iris = load_iris()
明白之后,我们可以先直接输出iris数据集看看
from sklearn.datasets import load_iris
iris = load_iris()
print(iris)
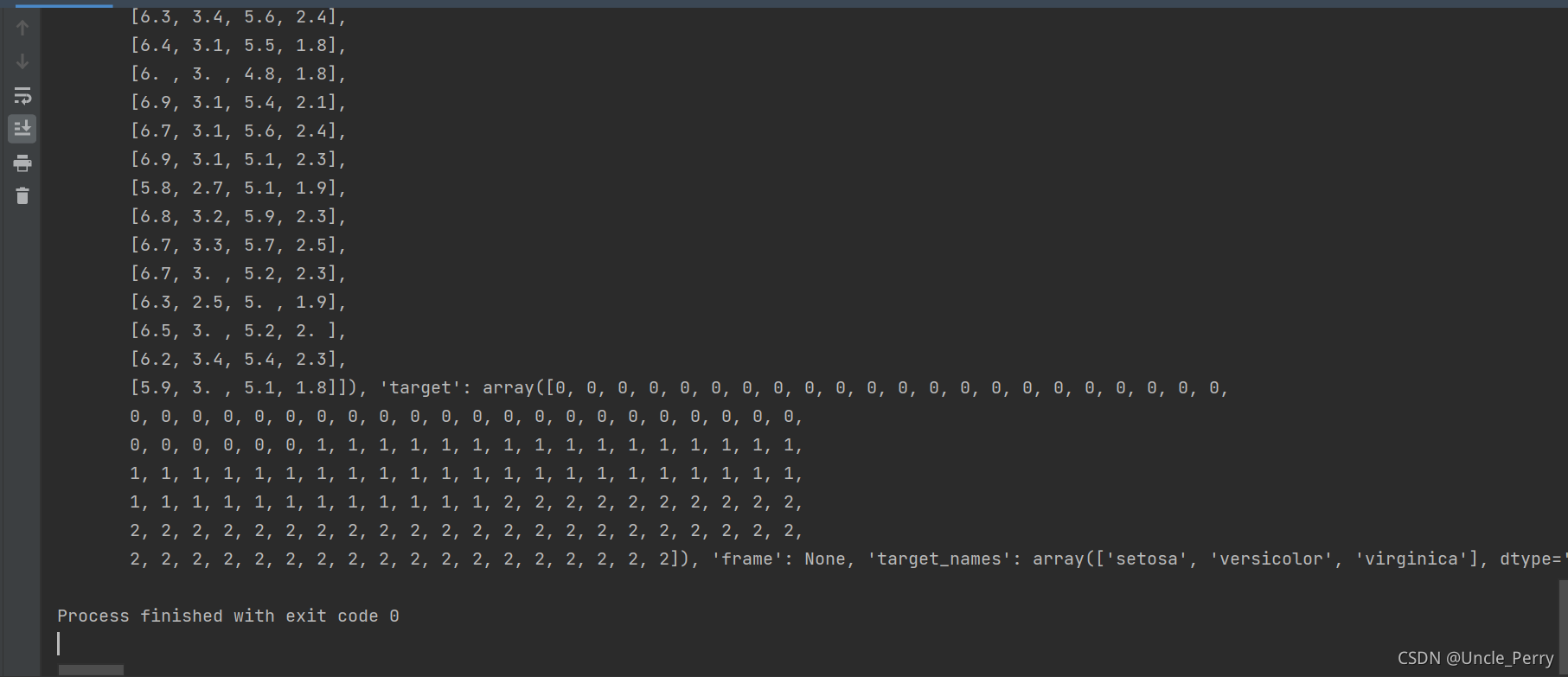
拖到最下端,发现没显示全,点击Soft-Wrap按钮
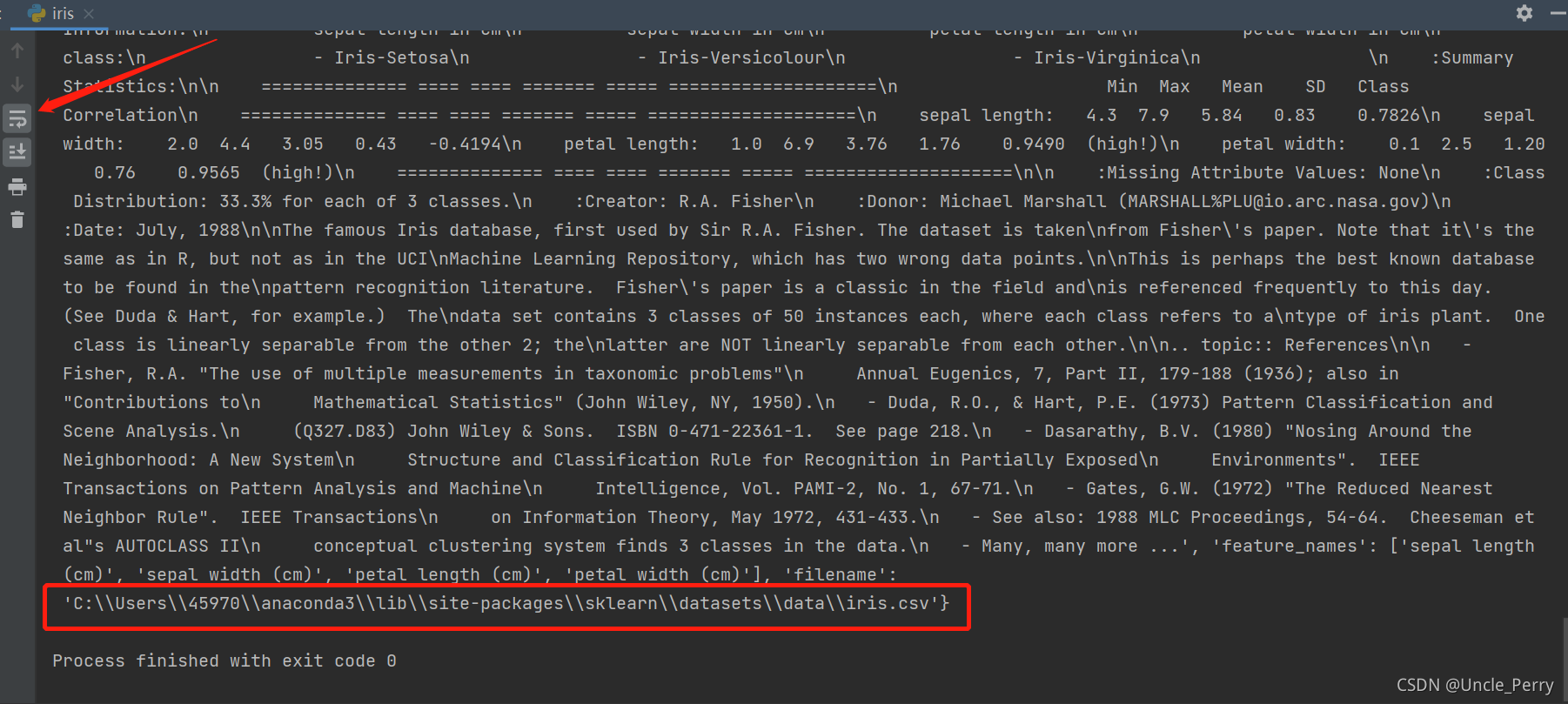
可以看到所在本地文件夹的位置
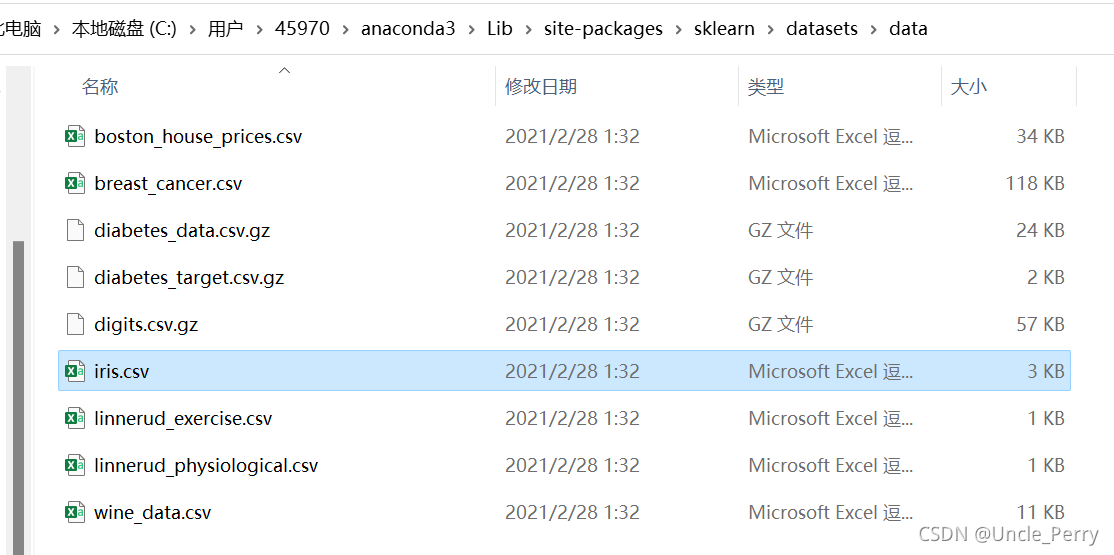
pandas的DataFrame教程很多内容也很长,这里我记住他的主要用法:
pd.DataFrame(内容,index,columns),即一张表主要就是内容、行和列,注意这里的index是行,columns是列
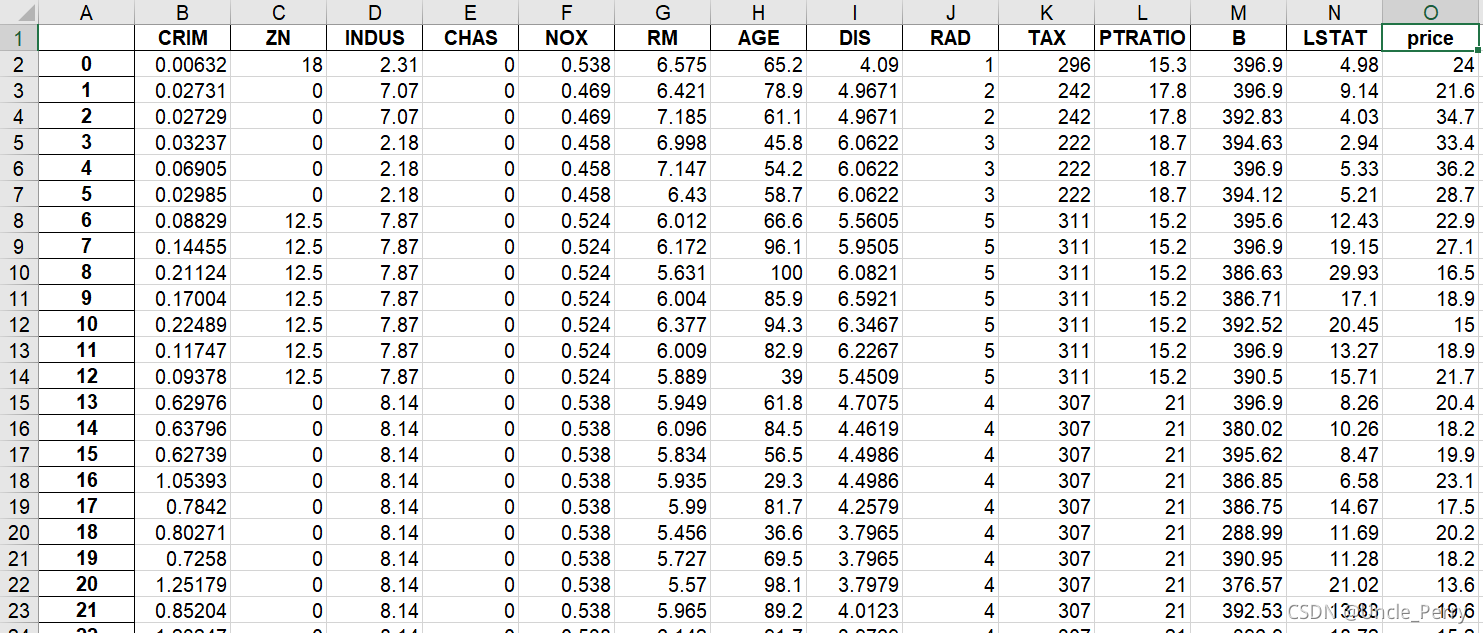
同理,我们再试着来下载保存波士顿房价:
from sklearn.datasets import load_boston
load_boston = load_boston()
import pandas as pd
# print(load_boston)
col = load_boston["feature_names"]
m1 = pd.DataFrame(load_boston.data,index=range(506),columns=col)
m2 = pd.DataFrame(load_boston.target,index=range(506),columns=["price"])
m3 = m1.join(m2,how="outer")
m3.to_excel("./load_boston.xls")
成功下载保存


















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









