







文章目录
堆排序
代码实现(升序)
void Swap(int& a, int& b)
{
int tmp = a;
a = b;;
b = tmp;
}
void AdjustDown(int* a, int n, int root)
{
int parent = root;
int child = parent * 2 + 1;
while (child < n)
{
if ((child + 1 < n) && (a[child] < a[child + 1]))
{
child++;
}
if (a[child] > a[parent])
{
Swap(a[child], a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
int end = n - 1;
while (end >= 0)
{
Swap(a[0], a[end]);
AdjustDown(a, end, 0);
end--;
}
}
int main()
{
int arr[] = { 1,0,2,9,3,8,4,7,5,6 };
HeapSort(arr, sizeof(arr) / sizeof(arr[0]));
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
cout << arr[i] << ' ';
}
return 0;
}
结果
分析
原理
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
分析思路
我们要学习堆排序,首先需要清楚什么是堆。
堆就是一种数据结构,一种逻辑结构为完全二叉树,而物理结构为顺序存储结构(即数组),这样父结点和子结点就可以通过一个关系式连接在一起了,这个关系式我们在后面分析代码时会讲,现在,我们只需要知道虽然堆实际结构为数组,但是我们仍然可以将父结点和子结点关联起来。
根据堆的性质(堆中某个结点的值总是不大于或不小于其父结点的值),将堆分为两类:大顶堆(某个结点的值总是不大于其父结点的值)、小顶堆(某个结点的值总是不小于其父结点的值)。
说到底,堆排序就是选择排序,找到最大的,放在最后,除最大的外,其他元素再组堆,再在其中找到次大的。对于组堆这个操作,我们组什么样的堆呢?
如果是升序,我们就组大顶堆;如果是降序,我就组小顶堆;当我们去分析代码时,你会恍然大悟的。那么如何构造大顶堆呢?我们来举个例子。
举例:有个数组:1 7 6 3 2 5
其逻辑结构:

我们发现,1 的左子树和右子树都已经大顶堆了,这时候我们需要一个向下调整算法,我们来模拟一下这个算法:
1 的孩子是 7 和 6;在其孩子中选出最大的,显而易见,就是 7,然后将 7 与 1 进行交换,变成:

我们接着跟踪这个 1;此时 1 的孩子 3 和 2;3大,然后让其与 1 进行比较,3 大于 1,交换。得到:

形成大顶堆。可是我们不得不说,(开始时,1 的左子树和右子树都是大顶堆,我们经过一次向下调整算法,形成了一个大顶堆)这种行为太巧合了。
所以,为了面对更为普遍的情况,我们进行了自低向下的建堆。比如:
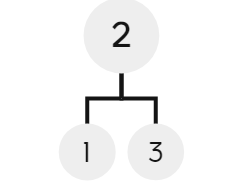
像这样的树,我们进行一次向下调整算法即可形成大顶堆,逐次向上,体现了分治的思想。
分析代码
Ⅰ分析向下调整算法(函数AdjustDown)
传参来父结点,由公式得到左孩子的位置。
进入while循环,条件是:孩子的下标不能超出数组。
第一个if判断(判断两个孩子的大小)
条件(child + 1 < n):防止寻找右孩子的时候超出数组,并且必须放在下一个条件前,先进行判断,因为下一个条件涉及到a[child + 1];
条件(a[child] < a[child + 1):如果成立,说明右孩子更大,则让child加一,则a[child]指的是右孩子,然后让a[child]与父结点进行比较,因为开始a[child]代表左孩子说明,我们默认左孩子更大。
第二个if判断(判断较大的孩子与父节点的大小)
如果孩子更大,那么交换父结点与子结点的大小,然后跟踪原来父结点的数据,直到它不会再交换为止。
Ⅱ堆排序的主体部分
第一个循环(for)(自低向上建堆)
我们可以知道最后一个孩子的下标,根据它的下标我们可以找到它的父结点的位置。开始这个父结点建堆。
第二个循环(while)
进行挑出最大值,放在最后,剩下元素的继续建堆,如此循环。
分析时间复杂度
我们想出满二叉树,最坏的情况莫过于每次都是从1层的节点最终被放到了最高层。

接下来:第二个while循环(重建堆)
重建堆次数:N - 1;
每次重建堆中比较次数:logN;
所以堆排序的时间复杂度为O(N*logN)。
















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











