






文章目录
1.java对象内存布局及对象大小
https://blog.csdn.net/loveyour_1314/article/details/123338536
1.java对象结构=对象头+数据区+对齐空间
2.java对象头大小=32位/64位=mark workd + class pointer + arrayLength(仅仅只有数组;集合不算)
3.mark workd:存储了对象的hashcode、分带年龄、锁的信息等3大部分;
4.class pointer(元数据):元数据指针,指向某一个类
5.class pointer默认大小是64bit=8byte,jdk1.8默认压缩为4byte,如果不压缩,通过重启动参数配置(不开启指针压缩 (-XX:-UseCompressedOops))
6.new Object对象,会占用16字节内存=8字节mark word + 4字节classpointer + 4字节对齐填充
7.一个空数组int[] ,会占用16字节内存= 8 字节markword + 4 字节classpointer+4字节数组长度
2.java锁的优缺点
| 锁的种类 | 优点 | 缺点 | 场景 |
|---|---|---|---|
| 偏向锁 | 获得锁执行代码与无锁时执行的效率只存在纳秒级别的误差 | 多线程竞争时,锁的撤销会额外消耗cpu | 适合一个线程的场景 |
| 轻量级锁 | 锁竞争时不会阻塞,提高了程序性能 | 如果始终竞争不到锁,会一直cas自选耗CPU | 追求响应时间;同步代码快执行很快 |
| 重量级锁 | 竞争时无cas操作,无cpu消耗 | 线程阻塞,响应时间慢 | 追求吞吐量,同步代码块执行速度过长 |
3.volatile:可见性和有序性
可见性原理:被volateile修饰的变量 jvm会将class解析成cpu指令,并在指令前加lock;
1.变量值被修改后,会被写会系统内存
2.一个处理器缓存写回系统内存时,会导致其他处理器缓存失效。
有序性原理:
原因:jvm在不改变数据依赖性的情况下,允许编译器和处理器对指令进行重排序,会导致在cpu指令上运行的顺序是不一样的;
通过volatile的内存屏障保证 指令不会被重新排序
4.计数器实现方式?
sync,cas,cas+分段思想
syncronized:
AtomicLong:
LongAdder:
AtomicCucculator:
AtomicLong:底层就是采用unsafe进行cas自选操作对值进行变更
CAS引发ABA问题
cas引发的 ABA问题:加版本号解决或 AtomicStampedReference<>,AtomicMarkableReference ;
AtomicStampedReference原理:
底层定义了私有的静态类pair并volatile修饰保证类的可见性,该类有两个属性,一个是reference即是value值,一个是int类型的stamp对象,用于记录版本号;
AtomicStampedReference使用cas方法时实际是对pair对象进行操作;如果版本不一致pair对象是不一致的,所以++++++
AtomicMarkableReference原理: 与AtomicStampedRefrence 原理类似,只是该类的pair对象是用bool类型的mark变量来标记版本是否变更
LongAdder:只能指定初始值为0
内部结构:底层采用了long类型的base对象和一个cell数组实现
操作原理:
当没有线程竞争的情况下:unsafe对象直接对base进行cas操作
当多线程竞争的情况下:longAdder会初始化一个cell数组,对每个线程的hash值与数组长度做&(与运算)并将value存放在对于的cell中,
之后将所有cell单元格的value与base值求和得到最终值;如果cas失败,则重新获取新的下标值去更新,在多线程情况下大大减少了cas失败的概率,极大减少了cpu的损耗
LongAccumulator:原子累加器原理
1.双目运算器,用于保存累加规则
2.identity指定初始值相当于longadder的base值
原理于longadder类似;LongAdder可以理解为LongAccumulator的一个特例
unsafe类作用:
1.内存管理:包括分配内存,释放内存
2.操作类、对象、变量:通过获取当前对象和偏移量直接修改数据
3.挂起与恢复:将线程阻塞或恢复
4.cas:调用cpu的cas指令进行比较和交换
5.内存屏障:定义内存屏障,避免指令重排序
1.feign用的什么http框架;
httpUrlConnection(默认),httpclient,okHttp(最终使用)等
如果想更换http请求框架直接pom文件中指定即可
okHttp核心初衷:专注简单与高效;优点如下
1.支持http/2;http2通过多路复用在一个tcp连接上支持并发
2.如果http/2不可用,连接池复用技术也可以极大减少延迟
3.支持gzip,可以压缩下载体积
4.响应缓存可以直接避免重复请求
5.连接出现问题会自动恢复
6.如果服务配置了很多ip,其中一个失效时,会自动尝试下一个
7.处理代理问题和ssl握手失败的问题
2.hystix服务隔离策略
信号量隔离和线程池隔离?
4.redis如何实现分布式锁
5.rocket mq事务失败怎么处理
消费者消费失败 -> 进入重试队列(重试次数16次)-> 进入死信队列
死信队列的消息默认保存3天,需要人为处理
如何处理:在控制台查到死信队列的topic,在消息列表对消息进行重投,让消费者
rocket mq使用几阶段提交?
记录日志表通知开发人员处理
5.实现一个springboot的starter
实质是springboot的装配原理:核心注解@EnableAutoConfiguration
5.1 原理
@EnableAutoConfiguration主要导入了@AutoConfigurationImportSelector实现
@AutoConfigurationImportSelector的selectImports方法最终是通过SpringFactoriesLoader加载器的会去所有依赖包下找到META-INF/spring.factories文件通过全类名进行加载;
该文件里都会声明该依赖所提供的核心功能bean配置信息并进行加载,从而达到加载全部bean信息;
注意:多个暴露的服务用英文逗号隔开
5.2 实现自定义的starter
1.编写暴露服务的service(DemoService)
2.编写配置类的config(DemoConfig)
@Configarution注解到类上,@Bean注解创建DemoService
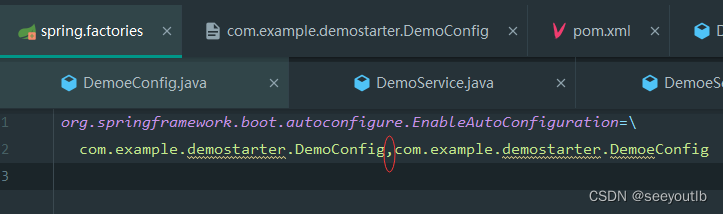
3.创建META-INF/spring.factories文件,并将要暴露服务的配置类配置如上图
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.example.demostarter.DemoConfig,\
com.example.demostarter.DemoeConfig
4.mvn打包编译
mvn clean install -Dmaven.test.skip=true
5.发布到mvn中央仓库
6.A服务在pom中添加starter依赖
5.3 @SpringBootConfiguration
@Configuration是spring的注解
@SpringBootConfiguration:是springboot的注解;是一个特殊的configuration类
5.3 @ComponentScan
作用:扫描当前项目中需要注册到spring容器的bean
包括@Configuration @Component @Service @ Contorller @Repostriy @RestController等
6.rocket mq事务失败怎么处理
1.初次消费失败进入retry队列(重试队列)
2.最多重试18(默认16) 次后,依然失败则进入死信队列
3.在控制台查询出死信消息的topic
4.在消息列表查询具体的死信消息
5.在控制台选择消息重发(修改死信消息权限后)
6.依然失败需要程序员处理(如果是网络问题,网络恢复后重投;如果是代码bug问题,修复代码后重投入)
死信消息的权限是2:禁读;
死信消息权限:2-禁读;4-禁写;6-可读可写
死信队列具有如下的特性;
1.死信队列是一个特殊的topic,命名方式是%DLQ%comsumerGroupId
2.一个死信队列与一个消费组一一对应,而不是消费组的实例
3.一个消费组没有产生死信消息,那么不为为其创建死信队列
4.一个死信队列,包含了所有消费组的所有死信消息,不论该消息时属于那个topic
记录日志表通知开发人员处理
7.线程池为什么要添加一个没有任务的空线程
两种可能:
1.在创建线程池时,将核心线程池数量设置为0;导致阻塞队列中有任务缺不能立刻执行
2.线程池有个属性allowCoreTimeOut,允许核心线程回收断开,默认不允许;
线程池工作原理:
1.有任务时,当未达到核心线程数时,创建核心进程执行
2.当核心线程满了时,将任务放入阻塞队列
3.阻塞队列满了时,创建最大线程数
4.最大线程数满了时,执行拒绝策略
5.当最大线程有空闲时,会存活timealive时间 会被回收
6.核心线程数可以为0,但不会被回收
默认拒绝策略4种:
1.DiscardPolicy - 直接丢弃(可以做自定义的处理方式)
2.AbortPolicy-丢弃抛出异常(默认)
3.CallerRunsPolicy-使用当前线程去执行
4.DiscardOldestPolicy - 丢弃最早的任务,尝试重新执行任务(没获取到不做处理)
8.shareding jdbc 水平分表后如何聚合查询、范围查询
采用内存归并;其他查询场景用流式归并
范围分片算法RangeShardingAlgorithm
tablename_year_month
shareding jdbc工作流程
1.sql解析
2.执行器sql优化
3.sql路由
4.sql改写
5.sql执行
6.结果归并
9.jdk 1.8新特性
1.lambda表达式
2.函数式接口:Function接口,Comsumer等
3.optional对空指针处理
4.新增日期类的:ZoneId,LocalDate,LocalTime,LocalDateTime等
5.接口运行定义默认方法和静态方法
6.方法引用和构造方法引用;使用“::”
7.Stream流式操作
10.nginx配置优化
https://blog.csdn.net/qq_57377057/article/details/126568841
1.linux的ulimit配置
1.1 先设置linux的ulimit最大文件数
1.2 设置nginx work数和work最大连接数
2.cpu的亲和配置
能使nginx的work数绑定到cpu核心数上,减少切换
3.IO事件处理模型优化
多路复用器的设置,linux配置epoll
4.work_connnetction连接数优化
默认是1024,最大是65535
5.会话的保持时间(keepalive timeout)
长连接一般60s差不多了;根据不同的情况去调试
6.GZIP压缩性能优化
7.proxy超时设置
8.proxy_set_header(代理设置头信息等)
9.高效传输模式(sendfile on)
10.expires(到期)缓存调优
11.访问限流配置
12.内核参数优化















 697
697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









