






中国科学院提出了一种深度离散哈希算法(discrete hashing algorithm),该算法认为学习到的二值编码应该也可以用于分类。实验结果表明该方法在基准数据集上的表现要好过目前最好的哈希方法。
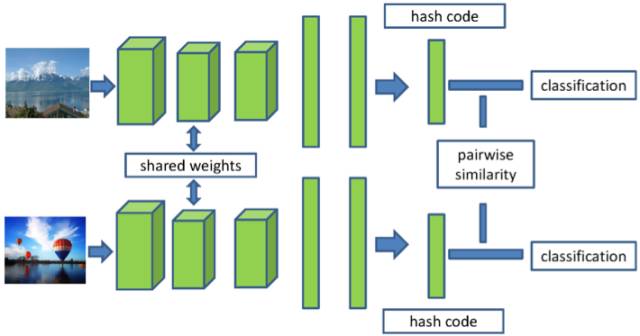
图 1 深度离散哈希编码示意图
由于网络上的图像和视频数据的快速增长,哈希算法(Hashing)在近几年间引起了极大的关注。由于其较低的计算成本和较高的存储效率,是图像搜索和视频搜索中最常使用的技术之一。一般来说,哈希算法可将高维数据编码为一组二进制代码,与此同时还能保持图像或视频的相似性。现有哈希算法可以大致分为两类:数据无关的方法和数据有关的方法。
近期有人提出了基于深度学习的哈希算法,它可以同时学习图像表示和哈希编码(hash coding),取得了比传统哈希算法更好的结果。「CNNH」[19] 是早期将深层神经网络与哈希编码融合的工作之一,该工作包括两个阶段来学习图像特征表示和哈希编码。CNNH 的一个缺点是通过学习得到的图像特征表示不能及时反馈给哈希编码。为了克服 CNNH 的这一缺陷,「Network In Network Hashing/NINH」[8] 提出了基于三元组损失函数来表示图像的相似性。研究表明,图像特征表示和哈希编码可以在一个框架内相互促进。DSRH 算法 [24] 通过保留多标签图像间的相似语义信息来学习哈希函数。近年来还提出了其他基于排序的深度哈希算法 [17,21]。除了基于三元组排序方法外,还有一些基于成对标签的深度哈希算法 [9,25]。
我们所做工作总结如下。「1」我们方法的最后一层输出直接限制为二进制编码。学习到的二进制编码既能保持图像之间的相似关系,同时又能和标签信息保持一致。据我们所知,该方法是第一个在统一框架下同时使用成对标签信息和分类信息学习哈希编码的方法。「2」为了减少量化误差,我们在优化过程中保留了哈希编码的离散化这一特性。此外,我们还提出了一种交替优化方法,即使用坐标下降法优化目标函数。「3」大量的实验结果表明,我们的方法在图像检索问题上,取得了比现最好方法更好的结果,从而验证了我们方法的有效性。
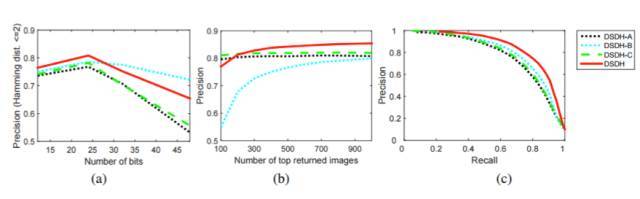
图 1:DSDH-A、DSDH-B、DSDH-C 和 DSDH 在 CIFAR-10 上得到的结果:「a」Hamming 半径为 2 的精度曲线;「b」不同数目最佳返回图像的精度曲线(不确定);「c」具有 48 位哈希编码的精度-召回曲线。
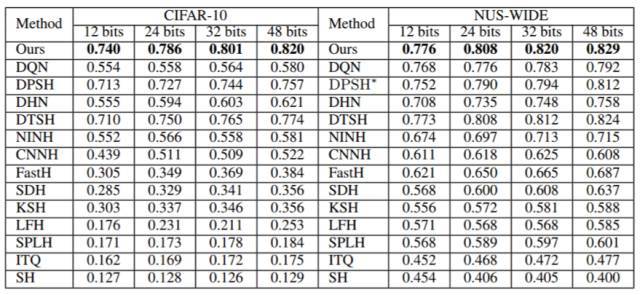
表 1:第一组实验设置下不同方法的 MAP。NUS-WIDE 数据集的 MAP 是根据返回的前 5,000 位邻近值计算的。DPSH * 表示重新运行 DPSH 作者提供的代码。
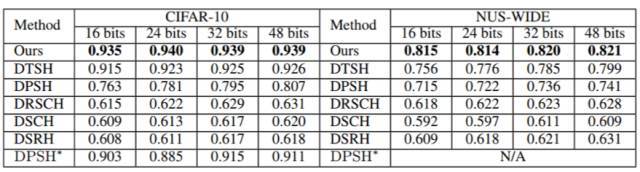
表 2:第二组实验设置下不同方法的 MAP。NUS-WIDE 数据集的 MAP 是根据返回的前 50,000 位邻近值计算的。DPSH * 表示重新运行 DPSH 作者提供的代码。
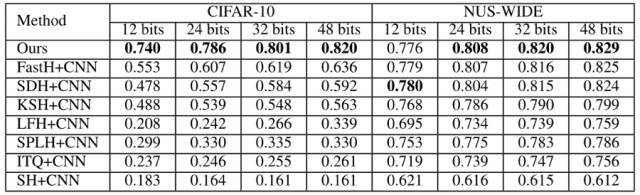
表 3:第一组实验设置下不同方法的 MAP。NUS-WIDE 数据集的 MAP 是根据返回的前 5,000 位邻近值计算的。
论文:Deep supervised discrete hashing

论文地址:https://arxiv.org/abs/1705.10999
摘要:随着网络上图像和视频数据的快速发展,近几年图像及视频检索也被广泛的研究。得益于深度学习的发展,深度哈希方法在图像检索方面也取得了一定的成果。然而,之前的深度哈希方法还是存在一些限制「例如,没有充分利用语义信息」。在本文中,我们提出了一种深度离散哈希算法(discrete hashing algorithm),该算法认为学习到的二值编码应该也可以用于分类。成对标签信息和分类信息在统一框架下用于学习哈希编码。我们将最后一层的输出直接限制为二进制编码,而这种做法在基于深度学习哈希算法中很少被研究。由于哈希编码的离散性质,我们使用交替优化方法来求解目标函数。实验结果表明,我们的方法在基准数据集上的表现要好过目前最好的哈希方法。















 2925
2925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









