







一、内容简介

Orange3 是一个开源的机器学习和数据可视化桌面软件。它允许你通过简单的拖放技术来创建数据分析工作流程。Orange3 提供了一个友好的图形化用户界面,非常适合初学者使用,同时也为熟练的数据科学家提供了数据探索和建模的强大功能。
在 Orange3 中,数据分析过程被设计为工作流程,它顺畅地转换并可视化数据,使用机器学习算法进行建模,并创建了可视化的数据呈现。每个流程都是一系列称为 "widget" 的模块,它们通过渠道连接在一起进行通信。
Orange3 中的一些主要功能如下:
数据可视化:Orange 提供了丰富多样的数据可视化方法,例如散点图、箱线图、直方图、热力图、雷达图,以及其他图例。这些可视化工具使你能够以直观的方式表示和解释数据。
数据预处理:Orange 提供了一些预处理工具,如过滤、排序、创建新变量、离散化等,这些工具几乎覆盖了所有常见的数据预处理任务。
机器学习:Orange 支持广泛的无监督和监督学习算法,比如聚类、分类、回归以及数据探索等。
特征选择和评估:在模型建立之后,还需要进行特征选择和模型评估以优化模型性能,Orange 为此提供了自动和交互式的工具。
数据加载和保存:Orange 支持多种数据格式,如 .csv 文件、SQL 数据库甚至 Google Sheets,都可以方便地导入或导出。
Orange3 可以用于数据挖掘、数据分析、统计分析、机器学习、教学研究等诸多领域,丰富的功能和模块使其在数据科学领域有广泛的用途。
二、课程内容
1.Orange3安装
下载地址:
https://orangedatamining.com/download/
免安装绿色版:
https://download.biolab.si/download/files/Orange3-3.36.2.zip
2.汉化DIY
链接: https://pan.baidu.com/s/1QNElTsv1yaAQdUutzsMPNQ?pwd=p6iq
数据组件分组

转换组件分组

可视化组件分组

模型组件分组

评估分类/回归性能分组

无监督学习
3-Orange3创建快方式
快捷方式命令:%COMSPEC% /C start D:\dev\software\portable\Orange3-3.36.2\Orange\pythonw.exe -m Orange.canvas
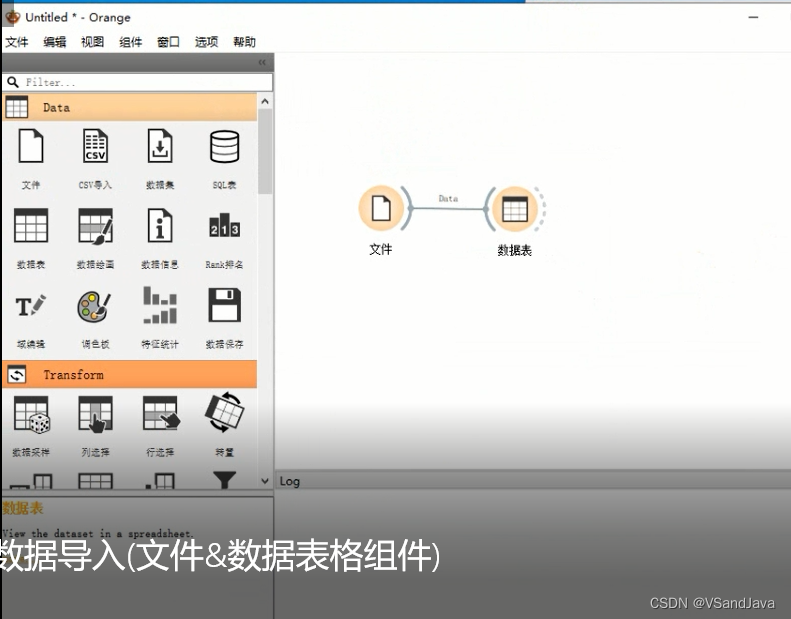
4-数据导入(文件&数据表格组件)
学生成绩表格 Excel文件内容:
| 学生名称 | 学生ID | 课程id | 课程名称 | 成绩 |
| 学生1 | 1 | 5 | 代数 | 51 |
| 学生2 | 2 | 3 | 历史 | 91 |
| 学生3 | 3 | 1 | 数学 | 54 |
| 学生4 | 4 | 4 | 政治 | 76 |
| 学生5 | 5 | 1 | 数学 | 55 |
| 学生6 | 6 | 3 | 历史 | 54 |
| 学生7 | 7 | 4 | 政治 | 59 |
| 学生8 | 8 | 1 | 数学 | 96 |
| 学生9 | 9 | 2 | 语文 | 93 |
| 学生10 | 10 | 1 | 数学 | 48 |
| 学生11 | 11 | 2 | 语文 | 59 |
| 学生12 | 12 | 4 | 政治 | 77 |
| 学生13 | 13 | 2 | 语文 | 84 |
| 学生14 | 14 | 2 | 语文 | 71 |
| 学生15 | 15 | 1 | 数学 | 56 |
| 学生16 | 16 | 4 | 政治 | 44 |
| 学生17 | 17 | 3 | 历史 | 44 |
| 学生18 | 18 | 5 | 代数 | 75 |
| 学生19 | 19 | 1 | 数学 | 62 |
| 学生20 | 20 | 1 | 数学 | 45 |
5-数据导入(Python组件)
import pandas as pd
import numpy as np
import random
from Orange.data.pandas_compat import OrangeDataFrame
# 创建课程表
courses = {
'id': [1, 2, 3, 4, 5],
'课程名称': ['数学', '语文', '历史', '政治', '代数']
}
courses_df = pd.DataFrame(courses)
students_scores_df=pd.read_excel('D:\\学生成绩表.xlsx', index_col=None)
out_data=OrangeDataFrame(courses_df).to_orange_table()
out_object=OrangeDataFrame(students_scores_df).to_orange_table()
print(students_scores_df)
print(courses_df)6-Python库安装(SQL表组件)
pip命令存放在:Orange3-3.36.2\Orange\Scripts
安装Python库:
1.设置Pip源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
#查看配置列表
pip config list
2.安装组件
支持PG数据库:
https://orangedatamining.com/blog/2018/02/16/how-to-enable-sql-widget-in-orange/
pip.exe install psycopg2
Mysql官方驱动程序
pip install mysql-connector
结巴分词,python 一个重要的第三方中文分词函数库
pip install jieba
Orange3中已安装,Requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到
pip install requests
3.测试Mysql安装包
Python代码:import mysql.connector
7-数据导入(Mysql)
from Orange.data import Table, Domain, ContinuousVariable,StringVariable
#https://www.runoob.com/python3/python-mysql-connector.html
import mysql.connector
mysql_db = mysql.connector.connect(
host="localhost", # 数据库主机地址
user="root", # 数据库用户名
passwd="root", # 数据库密码
database="orange3" #数据库名称
)
print(mysql_db)
mycursor = mysql_db.cursor()
mycursor.execute("SHOW DATABASES") #查询数据库名称列表
for x in mycursor:
print(x) #打印出数据库名称列表
mycursor.execute("SELECT id,name,course_id,course_name,score FROM orange3.t_student_score limit 10")
db_results = mycursor.fetchall() # fetchall() 获取所有记录
for x in db_results:
print(x) #打印数据到控制台
#关闭数据库连接
mysql_db.close()
#-------------------------------------------------------------
tableData = [] # 最终返回表格
rowData=[] #行数据
for db_result in db_results:
for idx in range(len(db_result)):
rowData.append(db_result[idx])
tableData.append(rowData) #添加一行数据
rowData=[] #清空行数据
metas = [] #元数据
metas.append(StringVariable('id')) #标识
metas.append(StringVariable('name')) #名字
metas.append(StringVariable('course_id')) #课程标识
metas.append(StringVariable('course_name')) #课程名称
metas.append(StringVariable('score')) #成绩
domain = Domain([], metas=metas) #生成domain
out_data = Table(domain, tableData) #构建返回表格8-数据导入(数据绘画和公式组件)
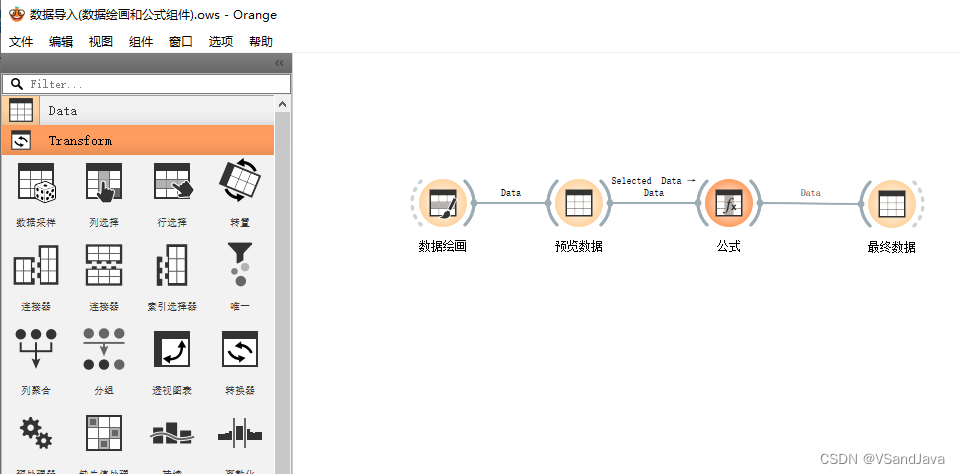
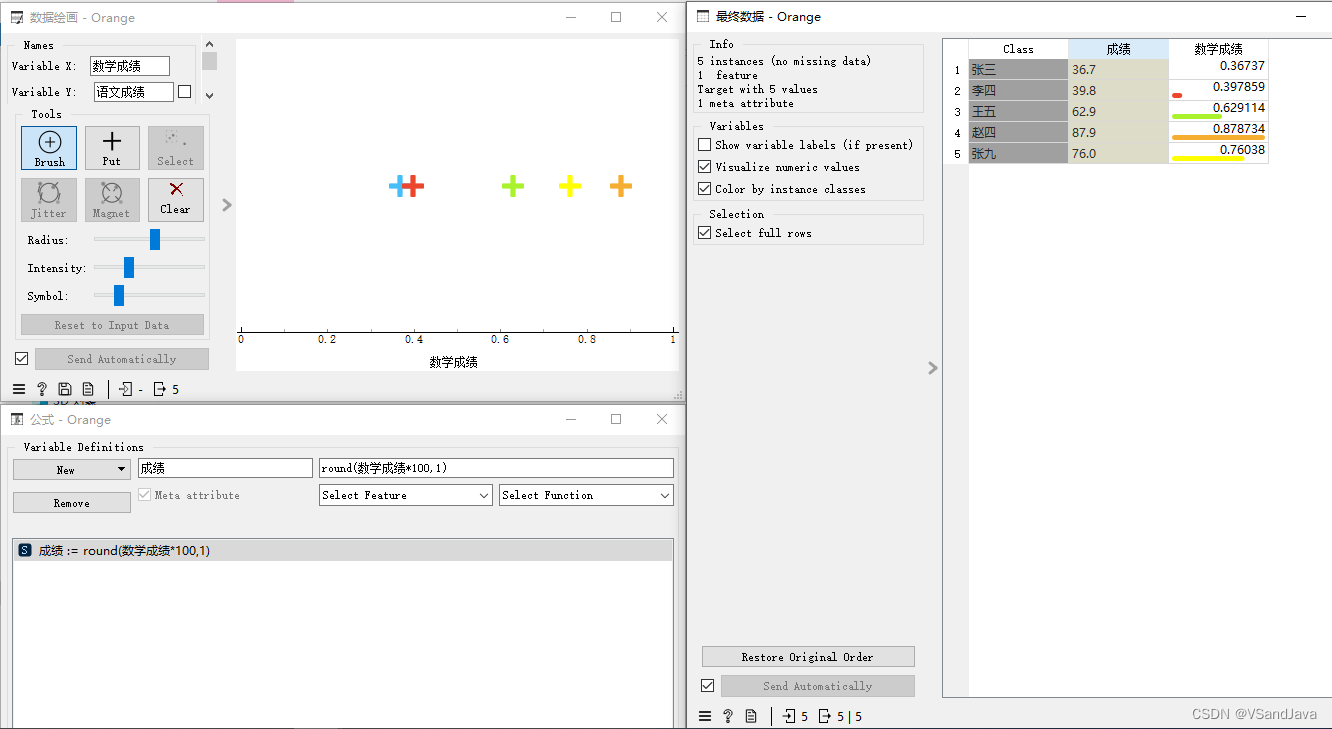
9-数据修改(域编辑和保存组件)
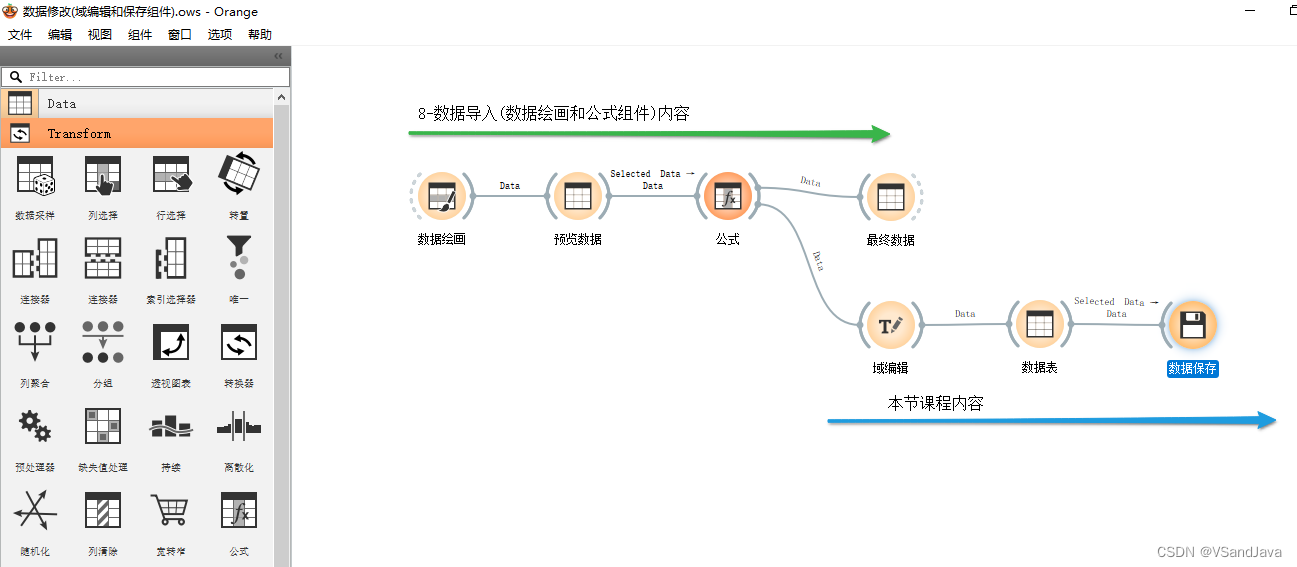
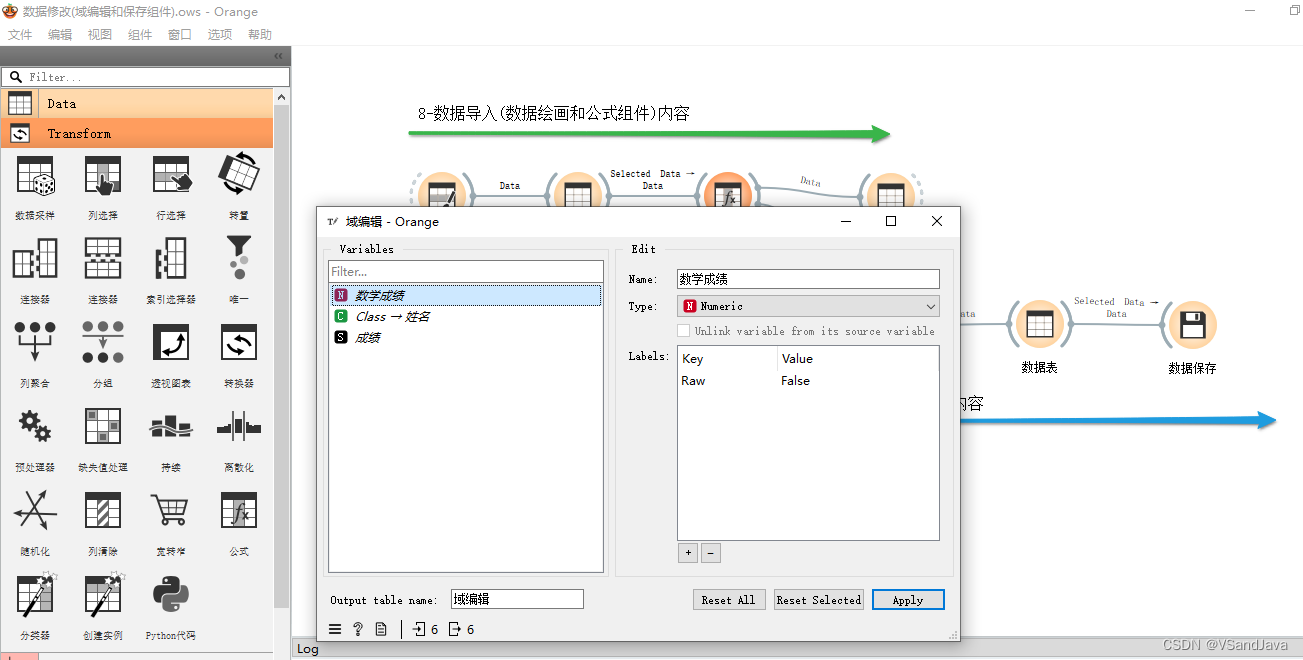
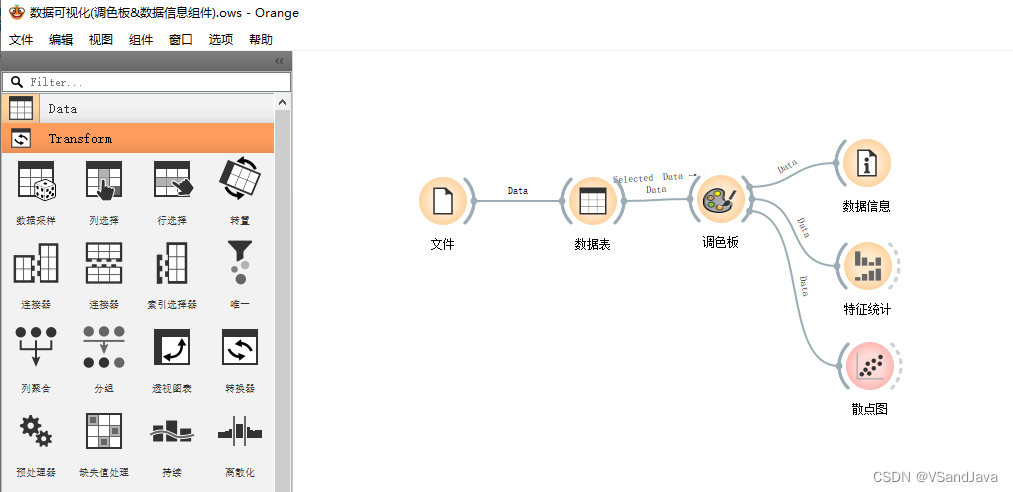
10-数据可视化(调色板&数据信息组件)
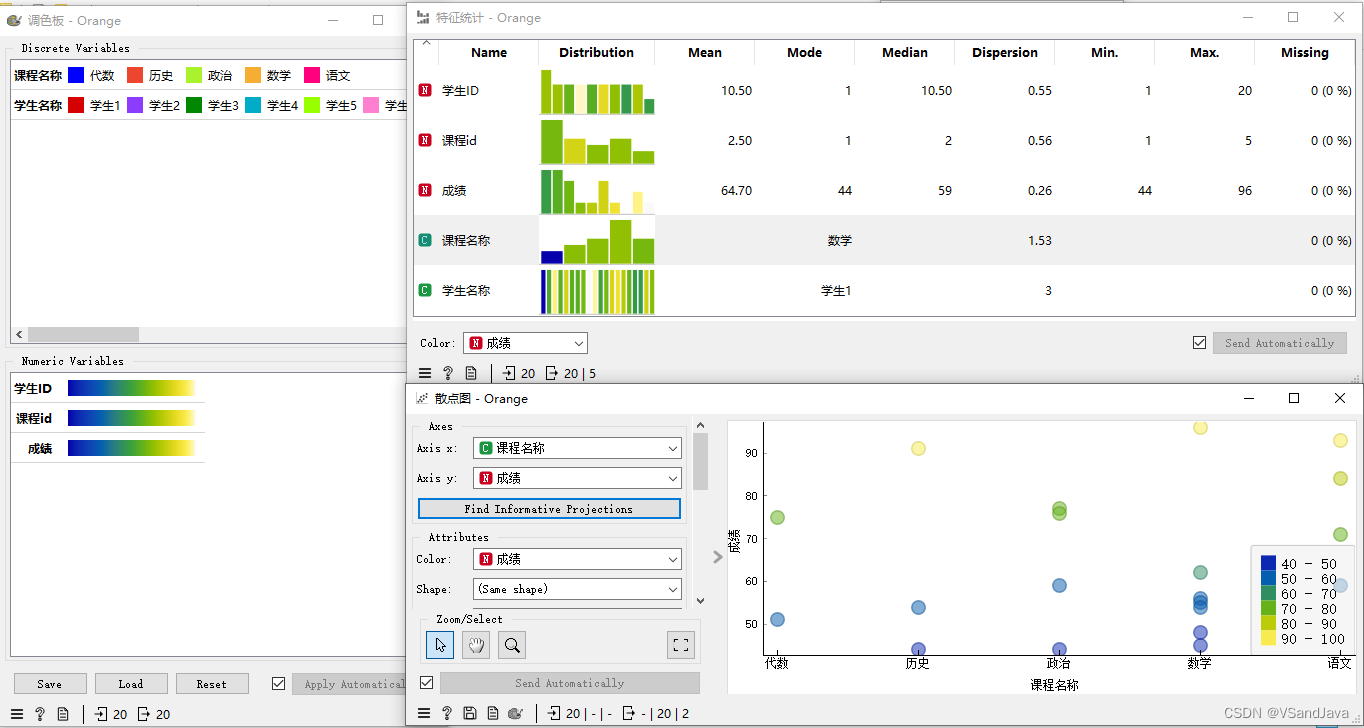
11-数据可视化(特征统计组件)
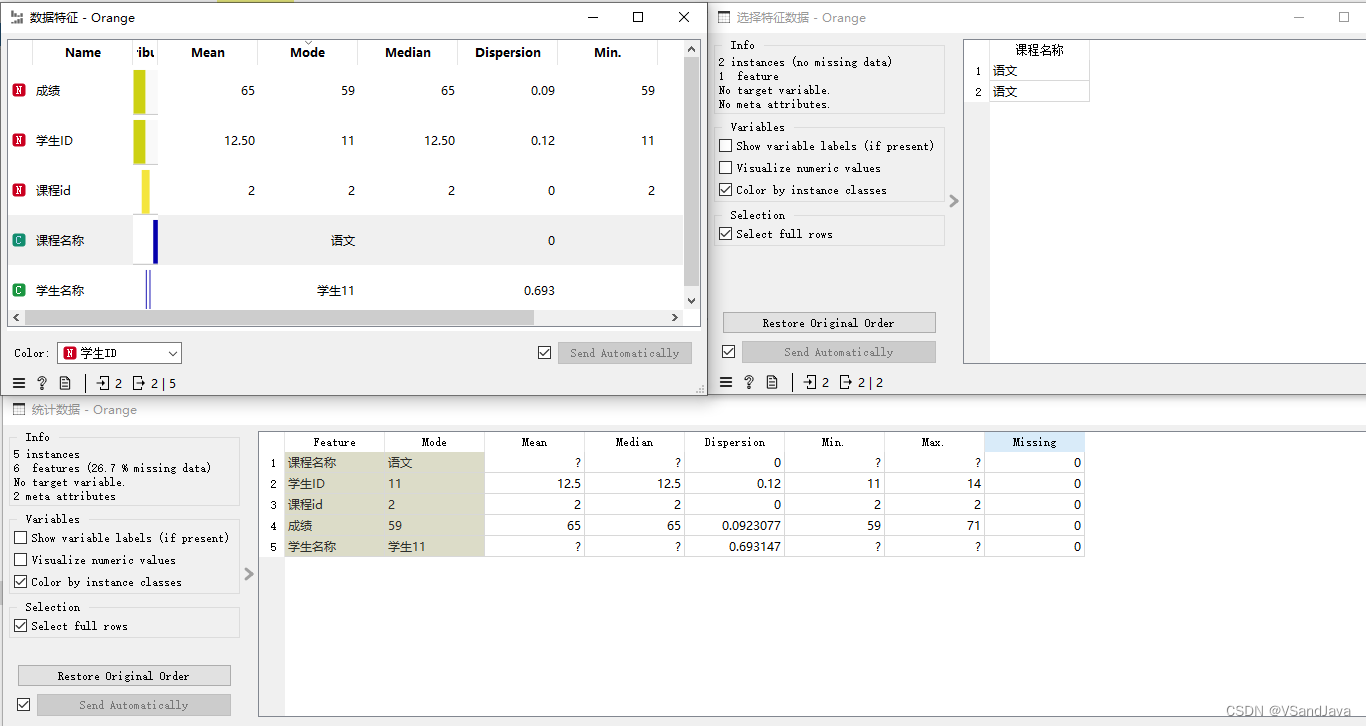
12-数据预处理(行选择组件)
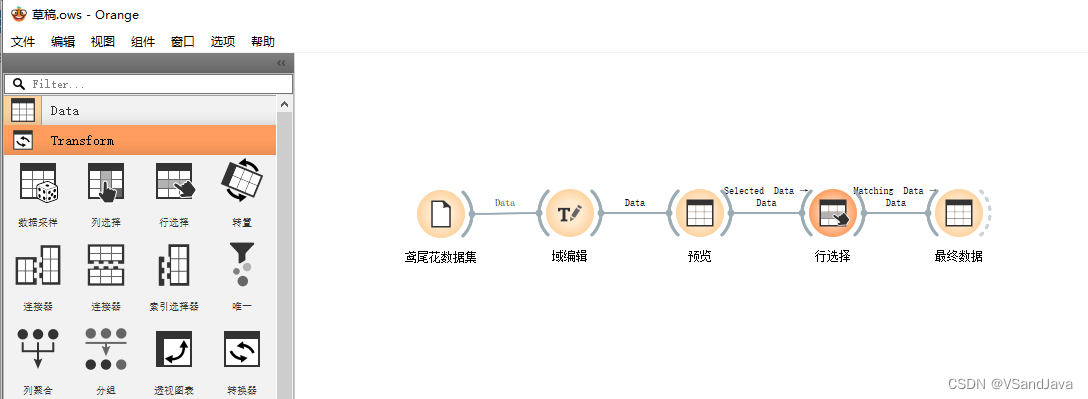
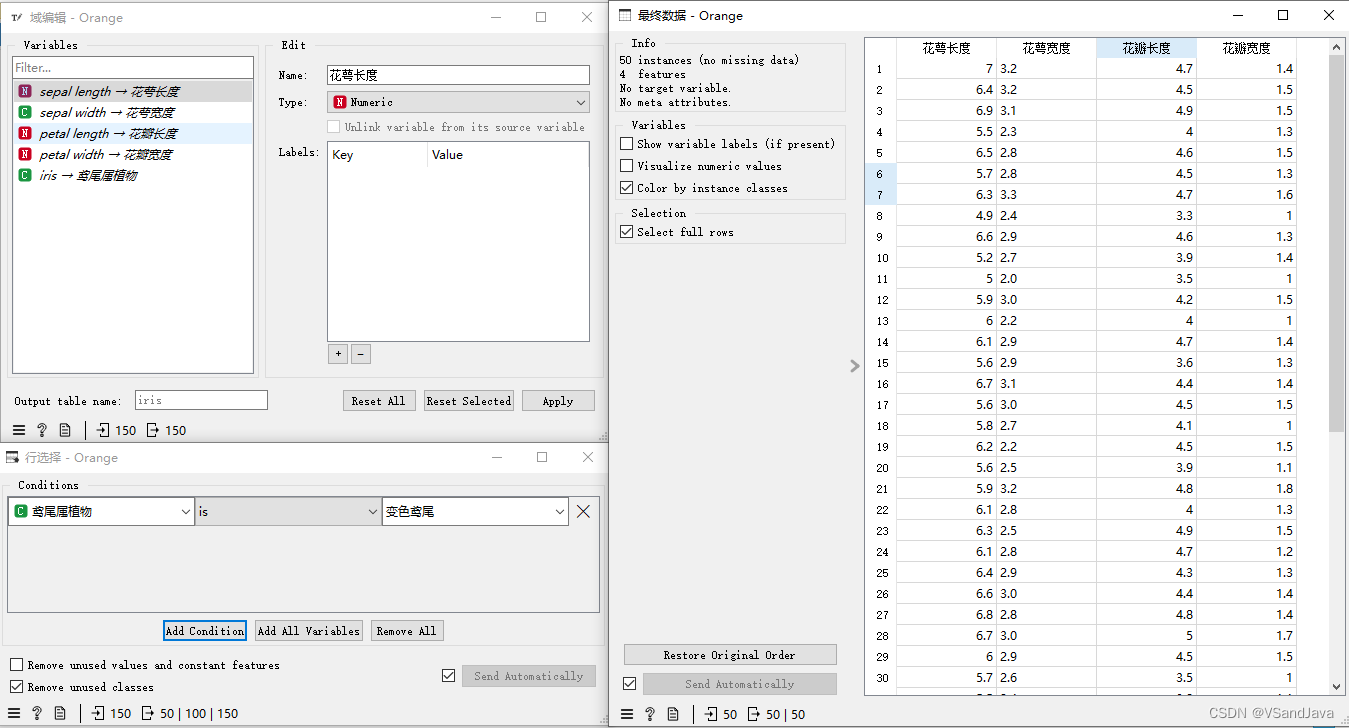
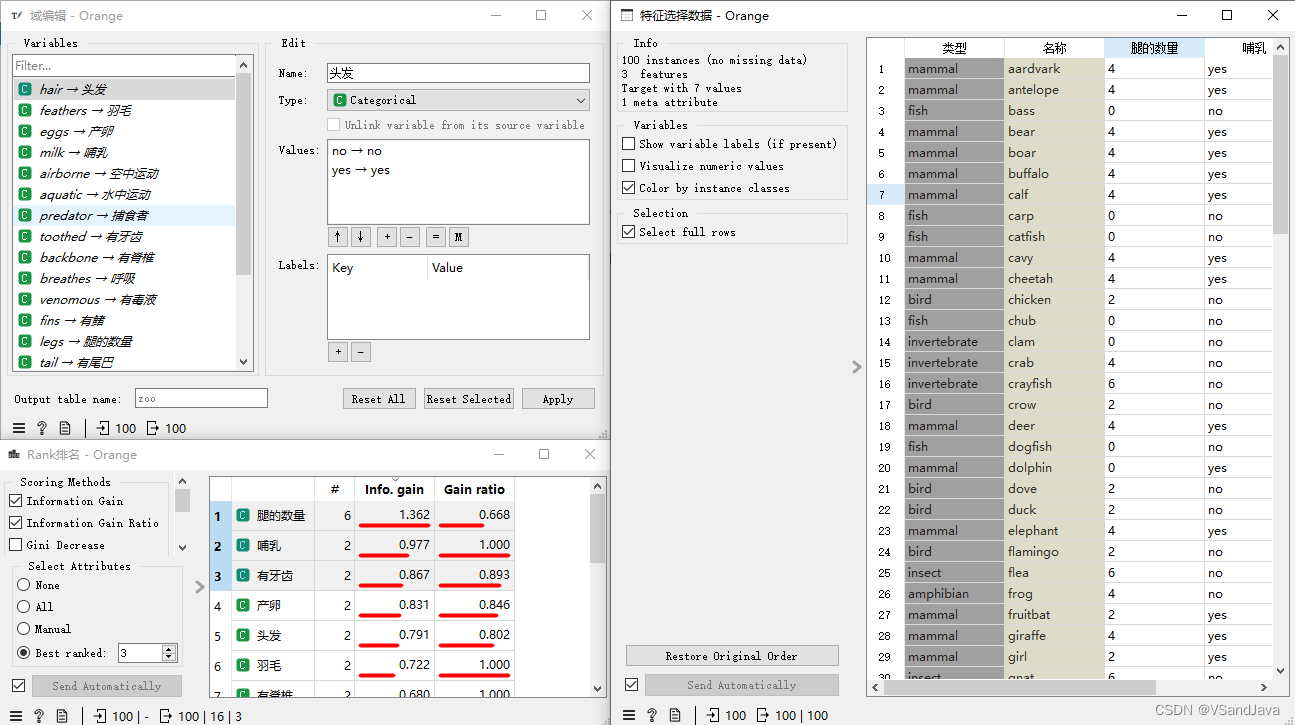
13-特征选择(Rank组件)
Orange3中的Rank组件用于特征选择,它通过评估每个特征与目标变量的相关性来对特征进行排序。以下是Rank组件中常用的评分方法的详解:
- 信息增益 (Information Gain):信息增益衡量了特征携带的信息量,用于分类问题。它计算了特征的熵减少,即特征出现与否对于目标分类的影响程度。信息增益越高,表示该特征对于分类的贡献越大。
- 增益比率 (Gain Ratio):增益比率是信息增益的一个调整版本,用于解决信息增益对多值特征的偏向问题。它考虑了特征的熵,将信息增益与其熵进行比较,以减少多值特征的偏向性。
- 卡方检验 (Chi-square):卡方检验用于衡量特征与目标变量之间的相关性。它通过比较观察到的频率与期望的频率来计算卡方统计量,值越大表示特征与目标变量的关联度越高。
- ANOVA (单因素方差分析):ANOVA用于评估连续特征与分类目标变量之间的关系。它通过比较不同类别的平均值来衡量特征的重要性。ANOVA的值越高,表示该连续特征与分类目标之间的关联度越高。
- 基尼不纯度 (Gini Impurity):基尼不纯度用于评估在决策树中分裂节点的效果。它衡量了数据的不纯度,值越高表示数据的不纯度越高,需要更进一步的分裂。在Rank组件中,基尼不纯度可以用来评估特征对于分类的贡献度。
- 相关性得分 (Correlation Score):相关性得分衡量了特征与目标变量之间的线性关系。它使用皮尔逊相关系数来计算特征与目标之间的相关性,值范围在-1到1之间,越接近1表示特征与目标之间的相关性越高。
这些评分方法可以根据具体的数据集和问题类型进行选择。不同的评分方法适用于不同类型的特征和问题,例如信息增益和增益比率适用于分类问题,卡方检验和ANOVA适用于连续特征与分类目标的关系,基尼不纯度适用于决策树分裂等。根据问题的需求和数据的性质选择适当的评分方法是关键。
请注意,在使用Orange3进行特征选择时,还需要注意数据预处理、异常值和缺失值的处理等步骤,以确保数据的质量和可靠性。此外,建议在使用Rank组件之前先了解各个评分方法的适用场景和局限性,以便更准确地评估特征的重要性并获得更好的特征选择结果。
Gini Decrease
在Orange3 Rank组件中,评分方法Gini Decrease的中文名称是基尼(GINI)削减,它是一个用于计算特征重要性的指标,可以衡量一个特征对于某个分类问题的影响程度。
基尼削减是一种决策树算法使用的特征选择方法,它首先计算分类问题的基尼指数,而后计算每个特征的基尼指数,并使用基尼削减算法确定哪些特征要被保留。这个过程可以帮助我们理解数据中每个特征对于分类问题的重要性,以便优化特征工程和数据预处理过程。
在Orange3中,Rank组件中使用基尼削减算法评估特征重要性,可以用来帮助我们理解不同特征对于某个分类问题的贡献程度,进而做出更好的特征选择和数据预处理决策。
Orange3 Rank组件中评分方法ReliefF中文名称是?作用是?
在Orange3 Rank组件中,评分方法ReliefF的中文名称是浮动特征选择方法,是一种采用随机方式进行搜索的特征选择算法,它是一种适用于分类和回归问题的特征选择算法。
浮动特征选择方法是一种基于概率的特征选择算法,它通过对数据中的样本进行随机采样,并计算每个特征对于分类或回归的重要程度来进行特征排序。在所有特征都已被计算和排序后,就可以选择最重要的特征进行特征选择。
在Orange3中,Rank组件中使用浮动特征选择方法ReliefF评估特征重要性,可以帮助我们理解不同特征对于某个分类或回归问题的贡献程度,进而做出更好的特征选择和数据预处理决策。相对于其他特征选择方法,浮动特征选择方法具有更好的稳健性和鲁棒性,这对于处理现实世界的数据集具有更大的优势。
Orange3 Rank组件中评分方法FCBF中文名称是?作用是?
在Orange3 Rank组件中,评分方法FCBF的中文名称是快速相关性依存过滤(Fast Correlation-Based Filter, FCBF),是一种用于特征选择的算法。
快速相关性依赖过滤算法(FCBF)可以在保持很高的准确率的同时,大大减少特征数量,即从强相关性系数较高的特征中选择最佳的特征作为分类器的输入。FCBF算法的主要思想是,对每个类别和特征计算相关性系数,然后根据相关性系数来过滤掉冗余的特征,而且该算法优先选择与类别相关性最高的特征。
在Orange3中,Rank组件中使用了FCBF方法评估特征重要性,该方法可帮助我们了解哪些特征是对分类问题最重要的,从而筛选出最具有预测能力的特征,提高模型准确度并减少过拟合的风险。
Orange3 Rank组件中评分方法ANOVA中文名称是?作用是?
在Orange3 Rank组件中,评分方法ANOVA的中文名称是方差分析(Analysis of Variance,ANOVA),是一种用于在分类变量之间进行比较时评估差异的统计学方法,具体应用在特征选择中用于评价各特征与目标变量之间的关联。
ANOVA可以分析和解释目标变量不同水平之间存在的任何变异性。它会将特征划分为两种类型: 类别型和连续型。它具有计算简单、解释性强、适用性广等优点,除此之外,由于该方法是一种统计方法,因此在使用之前需要对样本是否满足统计假设进行检验。
在Orange3中,Rank组件中使用ANOVA方法评估特征重要性,可以测量每个特征与目标变量之间的关联程度,帮助选择最相关的特征以提高模型的准确性。此外,ANOVA方法还可以作为特征选择的一种手段,有助于排除对模型预测能力不大或者冗余的特征。
14-数据转换(数据采样组件)
组件介绍:
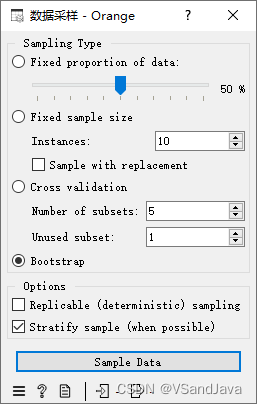
固定数据比例(Fixed proportion of data) 返回整个数据的选定百分比
固定样本量(Fixed sample size) 返回选定数量的数据实例,并可以设置 Sample with replacement(替换样本),该替换样本始终从整个数据集中进行采样(不减去子集中已有的实例)。 通过替换,您可以生成比输入数据集中更多的实例。
交叉验证(Cross validation) 将数据实例划分为指定数量的互补子集。交叉验证是一种评估机器学习模型性能的常用方法,其作用是通过将数据集分为几个互斥的子集(称作“fold”),然后对模型进行多次训练和测试,以评估其泛化能力。
自助采样(Bootstrap) 是一种常用的数据采样类型,它的作用在于用于建立稳健性较强的机器学习模型。
Bootstrap是一种有放回的重新采样方法,它会从原始数据集中随机采集一定量的样本,重复地采样多次,从而得到一组新的采样数据集。
这些新的采样数据集与原始数据集具有相同的大小,但由于采集方式不同,它们的样本和特征分布可能会有所不同,有助于减小因数据分布不均而导致的误差。
具体而言,使用Bootstrap方法可以补偿数据集样本数量不足,增加样本量;对于样本分布不平衡的情况,
可以采用Bootstrap来提高少数类别样本数量,从而避免由于类别不均造成的分类偏差;Bootstrap还可以用来模拟样本数量少的情况,从而评估机器学习模型的泛化能力。
在Orange3中,Bootstrap采样作为数据采样类型可用于构建机器学习模型时,
例如Classification Tree、Random Forest、Bootstrap Aggregating等组件中,可以选择Bootstrap作为采样方法,以提高模型的准确性和鲁棒性。
分层采样 Stratify Sample(when possible)选项使用的情况是,如果数据集中存在分类变量,该选项可以确保在分割数据集成训练和测试子集时,
每个子集中的分类变量分布与原始数据集中的分类变量分布相同,从而使训练和测试集更具代表性,并且最终模型的性能更加准确。
具体而言,Stratify Sample(when possible)选项会确保训练和测试集中的分类变量的比例与原始数据集中的分类变量的比例相同。
例如,假设原始数据集中鸢尾花的种类占总样本数的一半,如果使用Stratify Sample(when possible)选项,
则训练和测试子集中鸢尾花的种类分布也将各占一半。
可复制(确定性)抽样(Replicable(deterministic)sampling) 选项 使用的情况是,当我们需要多次使用相同的随机样本时,这个选项可以确保每次重复执行实验和分析时,所使用的随机样本都是相同的。这对于需要进行重复性调试和再现性研究的情况非常有用。一个常见的应用场景是,在开发和测试机器学习模型时,我们可能需要在同样的训练集和测试集上运行多次实验来评估模型的性能,并进行超参数优化。
测试流程: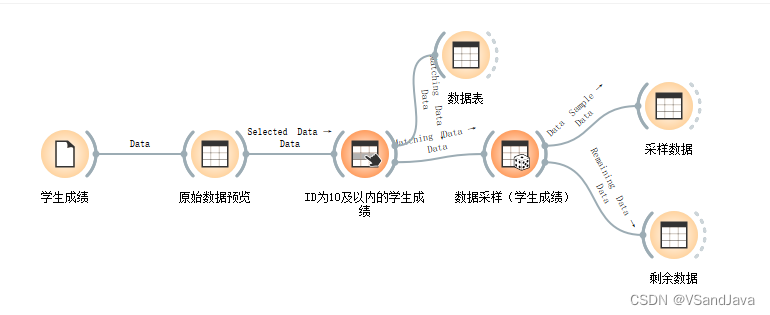 示例数据:
示例数据: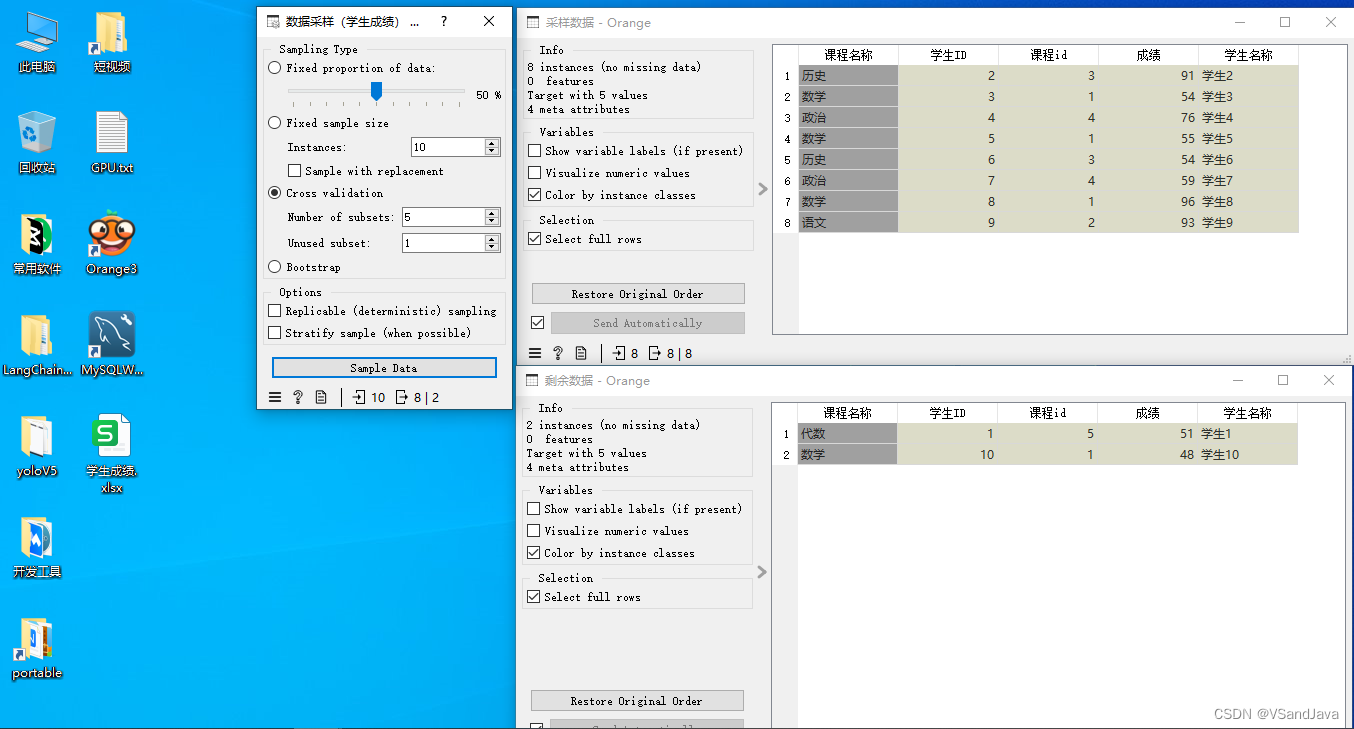
视频教程:关注我不迷路, 抖音:Orange3dev

















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









