







背景
今日线上运行时,监控系统不断预警CPU占用100%,遂开始着手排查问题。
排查过程
arthas观察
首先登录服务器,查看当前服务的日志输出情况看看有没有什么错误,结果打开日志一切正常,除了偶尔有几个异常外没有明显的问题,打开arthas进入应用服务的监控界面,发现前几个线程的CPU占用率都接近了30%。由于有现线程名称,所以一下子定位到功能地方了,这个线程一直消费mq的数据,然后进行一些计算和落库写入,每秒的mq消费量很大,几十万条,接下来分析为什么CPU会升高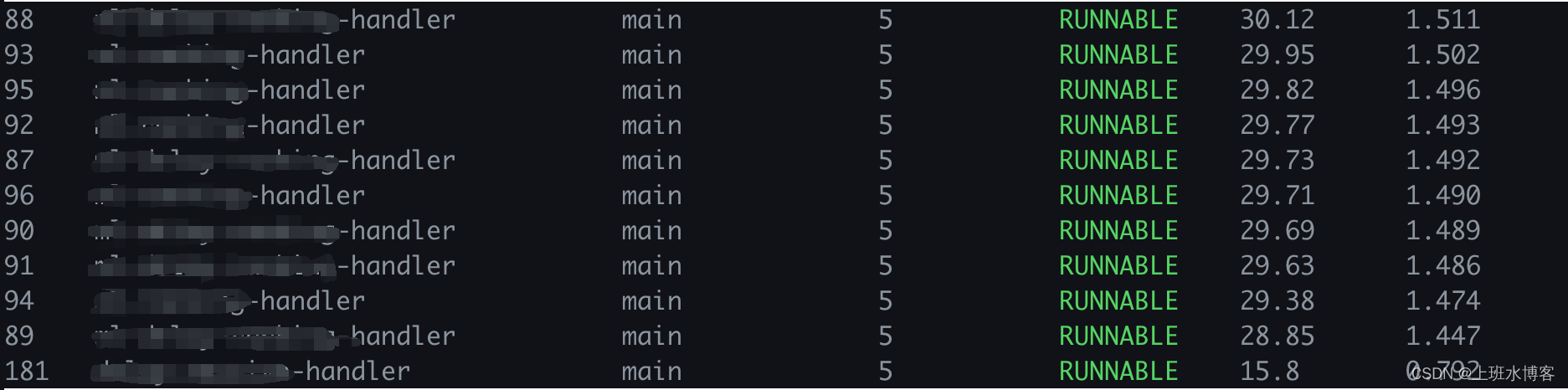
profile记录
我们在本地启动项目,通过IDEA自带的JProfile对项目进行分析,启动项目后,在profile界面选择我们对应的应用程序就行,运行5分钟后,生成jfr运行效果图
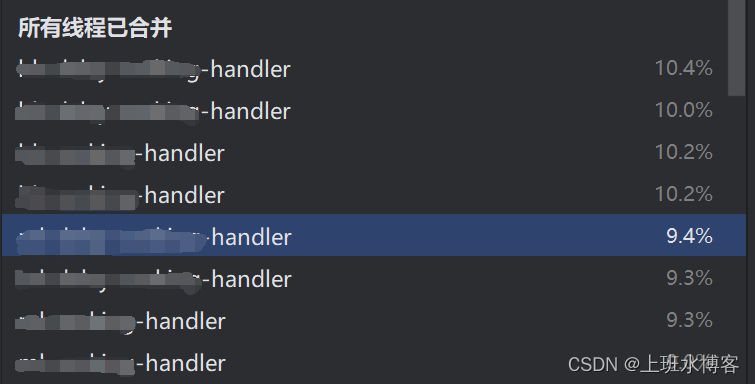
通过图表可以看到每个线程的CPU占用,接下来我们点进具体的线程
找到了第一个问题点,LinkedBlockingQueue的poll方法占用比例最高,高达7.5%,应用的处理逻辑如下,在线程内部启动循环去一直poll,这么做的目的是为了批量攒数据,然后等待时间内去一次处理,减少对数据库的方法。
while (!blockingQueue.isEmpty() && System.currentTimeMillis() - current < 10000) {
T take1 = blockingQueue.poll();
if (take1 != null) {
data.put(take1.getId(), take1);
}
}
既然poll方法的CPU占用这么高,那么这里我们调低批量处理的频率,调整为5秒去批处理一批数据
while (!blockingQueue.isEmpty() && System.currentTimeMillis() - current < 5000) {
T take1 = blockingQueue.poll();
if (take1 != null) {
data.put(take1.getId(), take1);
}
}
解决完第一个问题点,我们继续找第二个问题点,就是处理数据的地方。通过IDEA自带的分析工具,我们可以在侧边栏看到每个代码块的执行时间,可以看到处理数据的代码块消耗比较严重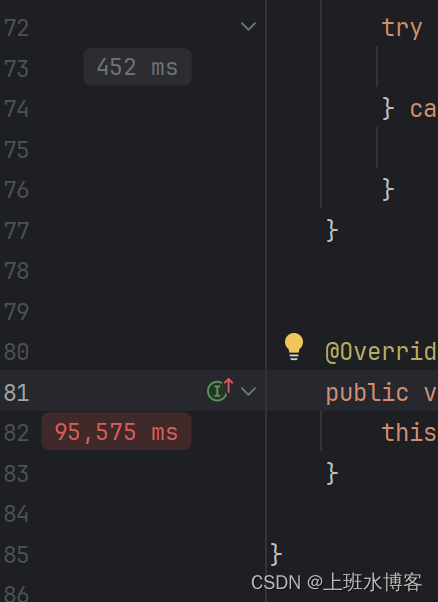
通过排查发现在判断List.contains方法这调用耗时特别长,原因是这个List比较大,大概有几万条数据,但是方法这频繁的进行循环调用和判断,大概如下
foreach(e->{
if(List.contains()){}
})

这里我们将List换成Set,修改后部署后CPU的使用率已经降下来了
总结
List Or Set
List的contains方法查询复杂度为O(n),
Set的查询复杂度最好的情况下为O(1),最坏的时间复杂度可能接近 O(n)
如果我们需要判断一个元素是否在列表中,数据量大且调用频繁的时候尽量还是使用Set结构,查询的效率会比List快
LinkedBlockingQueue
通过LinkedBlockingQueue进行异步操作的使用场景还是很多的,最常见的批处理做法就是在内部while循环获取一批数据,但是这种方式下poll方法执行很快,也会占用很多CPU使用时间,最好一批数据数据我们的等待时间尽量调短,以便减少CPU的消耗
T take = blockingQueue.take();
while ( data.size() < 5000 && System.currentTimeMillis() - current < 5000) {
T take1 = blockingQueue.poll();
}
请求量高的情况下尽量使用本地缓存减少网络IO
在这版优化之前,还碰到另外一个引起CPU高升的原因就是频繁调用redis获取数据,像我们的应用每分钟消费的mq数量在3.40W左右,处理时涉及到部分计算会去从redis取一些不变的数据,在数据量大的情况下,这部分网络IO占用的CPU也会很高,所以更改的方案就是对于不变的数据尽量使用本地缓存存储,设置一个过期时间定期刷新
















 1178
1178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









