







在酒店业务中,当用户打开微信中同程旅行小程序/艺龙APP/同程APP等,各式各样的酒店玲玲满目,而让用户将所有酒店浏览完再去选酒店下单已不太可能,因为用户一般也就查看前几页,如果找不到满意的酒店则退出,进而造成流单。因此如何对酒店进行排序使得用户感兴趣的酒店尽量排在前面从而提高交易匹配效率是我们平台重点研究的方向。
用机器学习方法解决排序问题的方法称为LTR(Learning to Ranking),而L2R可以分为三大类,Point Wise、Pair Wise、List Wise,下面将分别对三类排序方法进行介绍。
1、Point Wise、Pair Wise及List Wise的比较
| Point Wise | Pair Wise | List Wise | |
| 思想 | Pointwise排序是将训练集中的每个item看作一个样本获取rank函数,主要解决方法是把分类问题转换为单个item的分类或回归问题。 | Pairwise排序是将同一个查询中两个不同的item作为一个样本,主要思想是把rank问题转换为二值分类问题 | Listwise排序是将整个item序列看作一个样本,通过直接优化信息检索的评价方法和定义损失函数两种方法实现。 |
| 算法 | 1、基于回归的算法;2、基于分类的算法;3、基于有序回归的算法 | 基于二分类的算法 | 直接基于评价指标的算法非直接基于评价指标的算法 |
| 缺点 | ranking 追求的是排序结果,并不要求精确打分,只要有相对打分即可。pointwise 类方法并没有考虑同一个 query 对应的 docs 间的内部依赖性。一方面,导致输入空间内的样本不是 IID 的,违反了 ML 的基本假设,另一方面,没有充分利用这种样本间的结构性。其次,当不同 query 对应不同数量的 docs 时,整体 loss 将会被对应 docs 数量大的 query 组所支配,前面说过应该每组 query 都是等价的。损失函数也没有 model 到预测排序中的位置信息。因此,损失函数可能无意的过多强调那些不重要的 docs,即那些排序在后面对用户体验影响小的 doc。 | 1、如果人工标注包含多有序类别,那么转化成 pairwise preference 时必定会损失掉一些更细粒度的相关度标注信息。2、doc pair 的数量将是 doc 数量的二次,从而 pointwise 类方法就存在的 query 间 doc 数量的不平衡性将在 pairwise 类方法中进一步放大。3、pairwise 类方法相对 pointwise 类方法对噪声标注更敏感,即一个错误标注会引起多个 doc pair 标注错误。4、pairwise 类方法仅考虑了 doc pair 的相对位置,损失函数还是没有 model 到预测排序中的位置信息。5、pairwise 类方法也没有考虑同一个 query 对应的 doc pair 间的内部依赖性,即输入空间内的样本并不是 IID 的,违反了 ML 的基本假设,并且也没有充分利用这种样本间的结构性。 | listwise 类相较 pointwise、pairwise 对 ranking 的 model 更自然,解决了 ranking 应该基于 query 和 position 问题。listwise 类存在的主要缺陷是:一些 ranking 算法需要基于排列来计算 loss,从而使得训练复杂度较高,如 ListNet和 BoltzRank。此外,位置信息并没有在 loss 中得到充分利用,可以考虑在 ListNet 和 ListMLE 的 loss 中引入位置折扣因子。 |
| 优点 | 1、输入空间中样本是单个 doc(和对应 query)构成的特征向量;2、输出空间中样本是单个 doc(和对应 query)的相关度;3、假设空间中样本是打分函数;损失函数评估单个 doc 的预测得分和真实得分之间差异。 | 输入空间中样本是(同一 query 对应的)两个 doc(和对应 query)构成的两个特征向量;输出空间中样本是 pairwise preference;假设空间中样本是二变量函数;损失函数评估 doc pair 的预测 preference 和真实 preference 之间差异。 | 输入空间中样本是(同一 query 对应的)所有 doc(与对应的 query)构成的多个特征向量(列表);输出空间中样本是这些 doc(和对应 query)的相关度排序列表或者排列;假设空间中样本是多变量函数,对于 docs 得到其排列,实践中,通常是一个打分函数,根据打分函数对所有 docs 的打分进行排序得到 docs 相关度的排列;损失函数分成两类,一类是直接和评价指标相关的,还有一类不是直接相关的。 |
| 改进 | Pointwise 类算法也可以再改进,比如在 loss 中引入基于 query 的正则化因子的 RankCosine 方法 | Multiple hyperplane ranker,主要针对前述第一个缺陷magnitude-preserving ranking,主要针对前述第一个缺陷IRSVM,主要针对前述第二个缺陷采用 Sigmoid 进行改进的 pairwise 方法,主要针对前述第三个缺陷P-norm push,主要针对前述第四个缺陷Ordered weighted average ranking,主要针对前述第四个缺陷LambdaRank,主要针对前述第四个缺陷Sparse ranker,主要针对前述第四个缺陷 |
2、Point Wise模型总结应用
将排序问题转化为分类问题或者回归问题。考虑单酒店作为训练数据,不考虑酒店间的关系。以分类问题来说,即对于用户 u ,酒店集 ,可以形成 (
) 这样的训练样例 n 个,对于二分类问题学习目标可以分为 y=1 (相关)和 y=0 (不相关),然后训模型以对未知的样本做相关性预测。
点击率预估(CTR)问题是Pointwise的典型应用,此块的算法研究相对比较成熟,主要应用于广告、搜索以及推荐中。CTR问题的数学表达式 ,其中 y 范围为 [0,1] ,即 y 的值越大表示用户点击概率越高。下面将从CTR预估模型入手,详细梳理下Pointwise的演化过程。
(1) LR(logistics regression)
LR最基本的CTR预估模型,亦是工业界排序模型中的首选。LR可以处理大规模的离散化特征、易于并行化、可解释性强。同时LR有很多变种,可以支持在线实时模型训练(FTRL)。
LR的数学表达式如下:
其中,
假设, ,
则
LR假设各特征间是相互独立的,忽略了特征间的交互关系,因此需要做大量的特征工程。同时LR对非线性的拟合能力较差,限制了模型的性能上限。通常LR可以作为Baseline版本。
(2) MLR(阿里巴巴经典CTR预估模型)
混合逻辑回归模型(Mixed Logistic Regression,MLR),本质上是对线性LR模型的推广,利用分片线性方式对数据进行拟合,相比LR模型,能够学习到更高阶的特征组合。
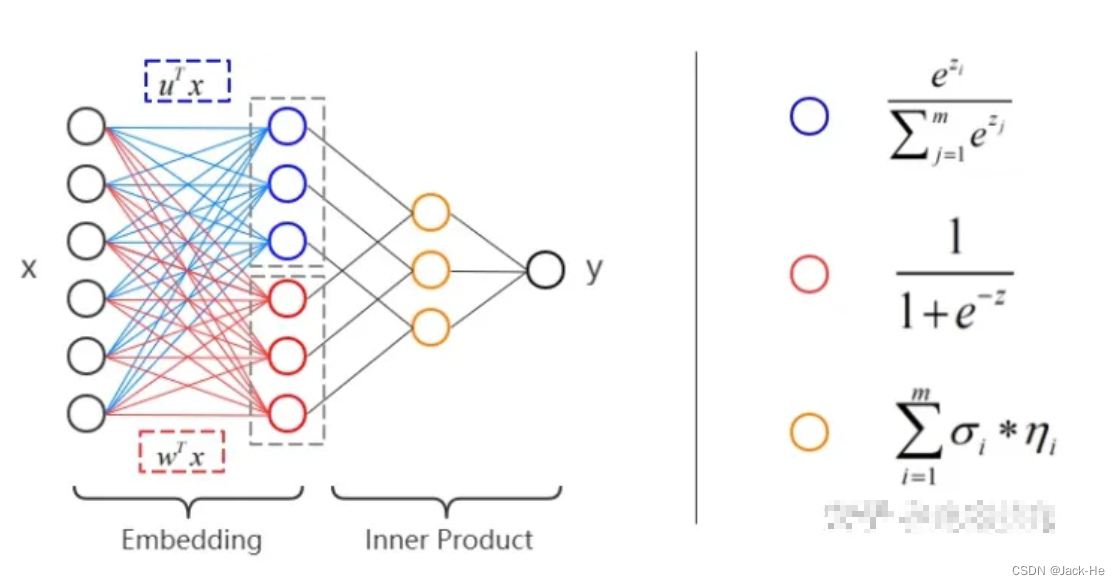
MLR模型结构
简言之,就是多个 LR 的加权组合。 MLR 的数学表达式如下:
其中,
MLR 有更强的非线性拟合能力。
(3) GBDT + LR(Facebook特征组合模型)
GBDT(梯度提升决策树)是一种表达能力比较强的非线性模型。GBDT的优势在于处理连续值特征,而且树的分裂算法使其具有一定的组合特征的能力。在推荐系统的绝大多数场景中,出现的都是大规模离散化特征,如果我们需要使用GBDT的话,则需要将很多特征统计成连续值特征(或者embedding),这里可能需要耗费比较多的时间。鉴于此Facebook提出了一种GBDT+LR的方案。如下图:
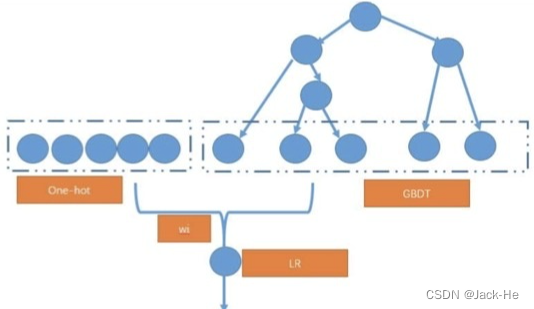
即先使用GBDT对一些稠密的特征进行特征选择,得到的叶子节点,再拼接离散化特征放进去LR进行训练。
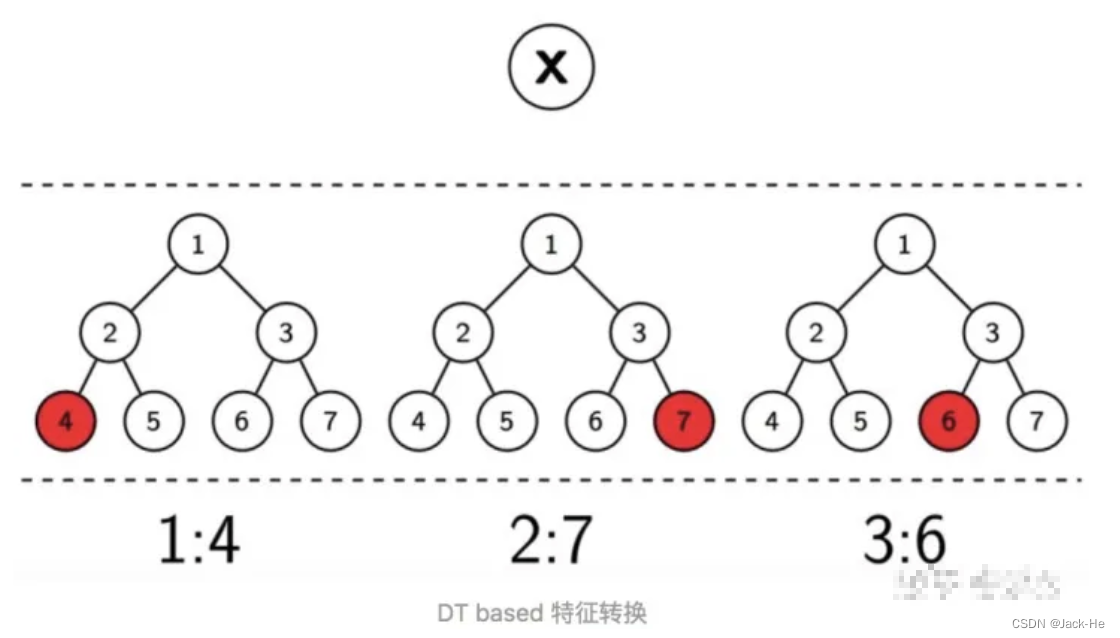
此方案可以看成利用GBDT替代人工实现连续值特征的离散化,而且同时在一定程度组合了特征,可以改善人工离散化中可能出现的边界问题,也减少了人工的工作量。GBDT本质是对历史的记忆,而GBDT+LR则强化了GBDT细粒度的记忆能力!
相关代码如下:
1. CTR预估[十一]: Algorithm-GBDT Encoder - 知乎
2. 推荐系统遇上深度学习(十)--GBDT+LR融合方案实战
(4) FM/FFM(稀疏数据下的特征组合/特征域感知FM模型)
LR模型假设特征之间是相互独立的,忽略了特征间的交互作用,而FM则是在这个基础上进改进。FM的模型公式为:
其中 为二次交叉项,表达了特征两两之间的相互作用。而二次项权重矩阵
可能会存在由于数据稀疏问题带来的不置信问题,同时当特征维度较高时存储空间复杂度较高。一种改进的方法是
,其中
为对应特征
的特征向量。此时:
比如,对于天气特征 , 时间特征
,则两个特征的交互权重为
。同时对于性别特征
,
与
的交互权重为
。
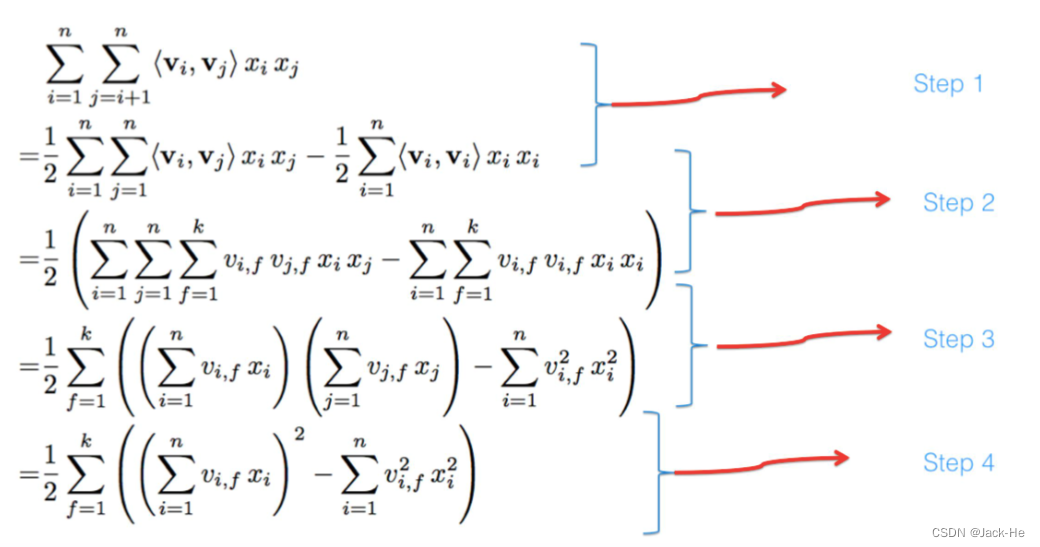
直观上,天气特征对时间特征、性别特征的作用是不一样的,使用同样的向量可能会损失部分信息。因此一种改进的方式是引入 field (域)的概念,即, 也就是天气特征对时间特征、性别特征的向量是不一样的。这称之为 FFM 算法,公式如下:
关于交叉部分的公式推导:
(5) DNN
神经网络是基于感知机的扩展,而DNN可以理解为有很多隐藏层的神经网络。多层神经网络和深度神经网络DNN其实也基本一样,DNN也叫做多层感知机(MLP)。DNN按不同层的位置划分,神经网络层可以分为三类,输入层,隐藏层和输出层,如下图示例,一般来说第一层是输入层,最后一层是输出层,而中间的层数都是隐藏层。
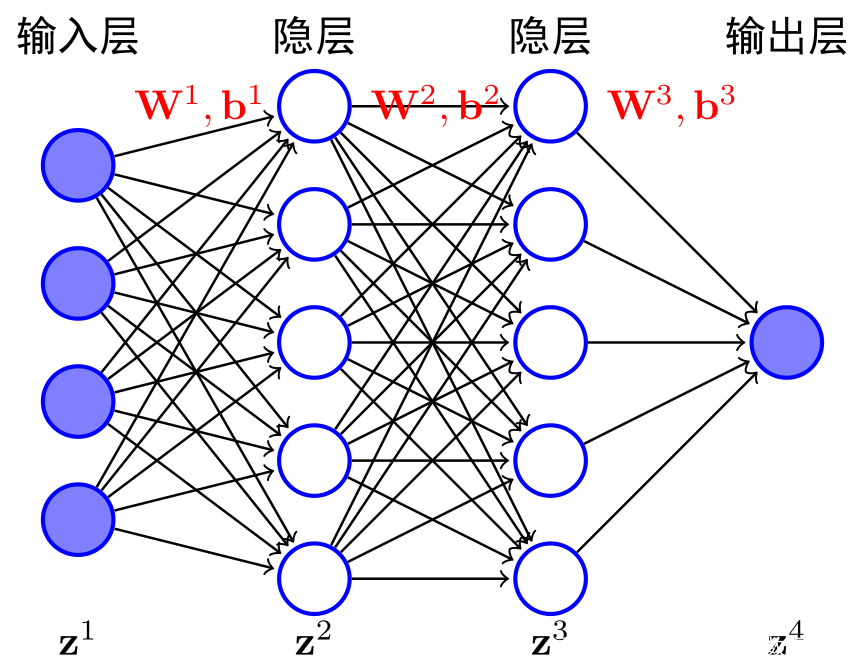
层与层之间是全连接的,也就是说,第 i 层的任意一个神经元一定与第 i+1 层的任意一个神经元相连。虽然DNN看起来很复杂,但是从小的局部模型来说,它还是和感知机一样,即一个线性关系加上一个激活函数。
通常神经网络的输入层 维度不宜过高,否则导致模型参数量剧增。而推荐搜索等排序应用中,商品ID、用户ID类特征的维度通常是亿级别的,为了缓解此问题一般将ID映射为固定维度的Embedding向量。
通过Embedding层,将高维离散特征转换为固定长度的连续特征,然后通过多个全联接层,最后通过一个sigmoid函数转化为0-1值,代表点击的概率。即Sparse Features -> Embedding Vector -> MLPs -> Sigmoid -> Output。这种方法的优点在于:通过神经网络可以拟合高阶的非线性关系,同时减少了人工特征的工作量。
下图是DNN用于CTR预估的网络结构,即用户偏好的商品和店铺作为特征,来预测对未知商品是否会点击。
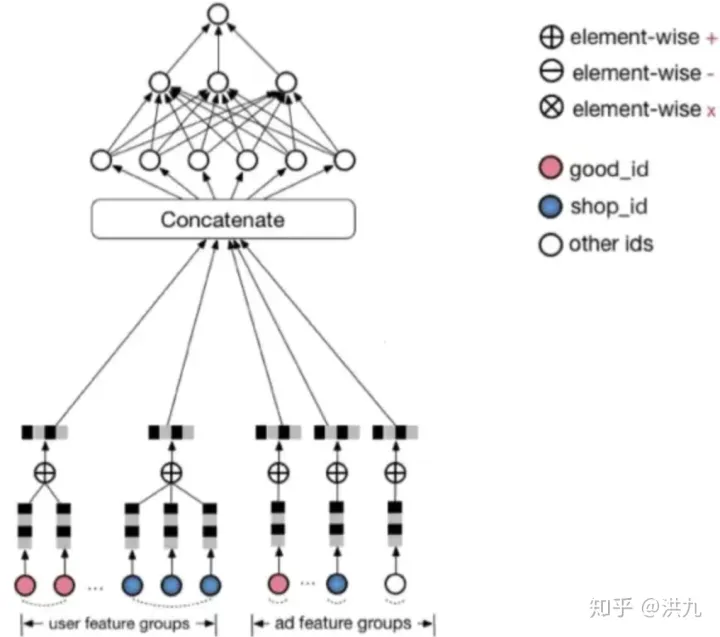
上图所示模型首先把one-hot或multi-hot特征转换为特定长度的embedding,作为模型的输入,然后经过一个DNN的part,得到最终的预估值。特别地,针对multi-hot的特征,做了一次element-wise+的操作。这样,不管特征中有多少个非0值,经过转换之后的长度都是一样的。
从业务上讲,以上模型充分利用了用户的历史偏好对未知做出预测。
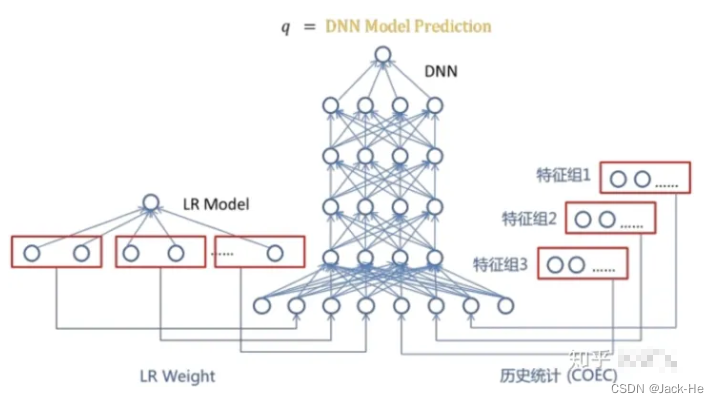
以下是百度DNN模型在CTR预估中的应用:
(6) Wide&Deep(Google经典CTR预估模型)
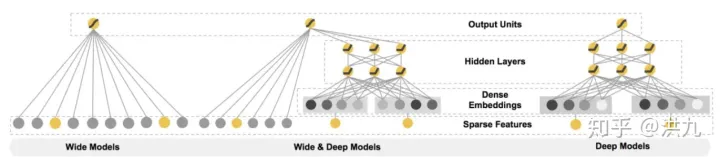
Wide&Deep模型
Google发表在DLRS 2016上的《Wide & Deep Learning for Recommender System》,提出了一种将深度学习应用于推荐系统的方法,在工业生产中得到了广泛的应用。Wide&Deep模型的核心思想是结合线性模型的记忆能力和DNN模型的泛化能力,从而提升整体模型性能。Wide&Deep已成功应用到了Google Play的app推荐业务。
将线性模型组件和深度神经网络组件进行融合,形成了在一个模型中实现记忆(Memory)和泛化(Generalization)的宽深度学习框架。下面分别简单介绍下记忆(Memory)和泛化(Generalization)的含义。
a. Memory(记忆性)
Wide部分长处在于学习样本中的高频部分,优点是模型的记忆性好,对于样本中出现过的高频低阶特征能够用少量参数学习。缺点是模型的泛化能力差,例如对于没有见过的ID类特征,模型学习能力较差。
b. Generalization(泛化性)
Deep部分长处在于学习样本中的长尾部分,优点是泛化能力强,对于少量出现过的样本甚至没有出现过的样本都能做出预测。缺点是模型对于低阶特征的学习需要用较多参才能等同wide部分效果,而且泛化能力强某种程度上也可能导致过拟合出现badcase。
实际用例
a. 美团在外卖搜索排序中W&D模型的网络架构
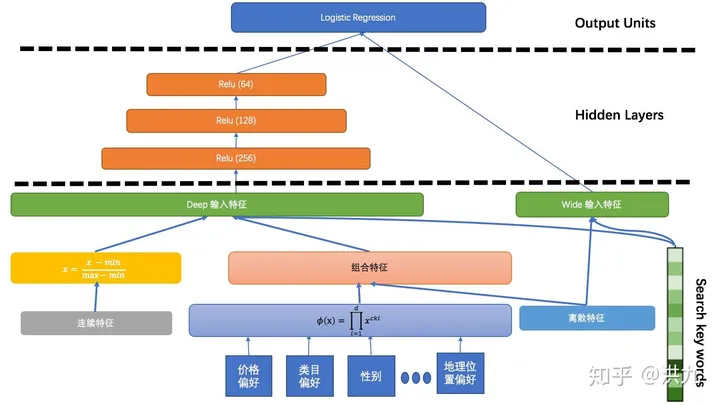
b. Google在google paly商店的推荐应用排序中W&D模型的网络架构
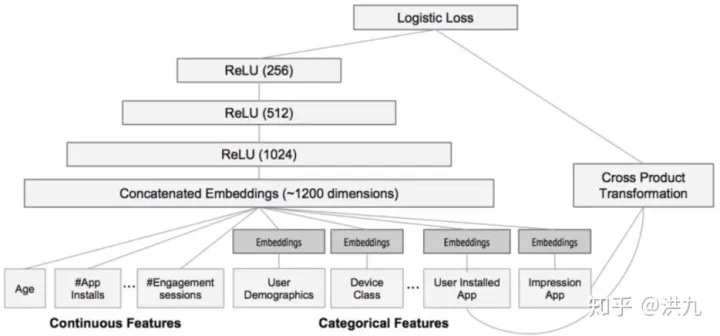
数学表达如下:
(7) DeepFM(FM+深度DNN网络)
DeepFM是哈工大Guo博士在华为诺亚实验室实习期间,提出的一种深度学习方法,它基于Google的经典论文Wide&Deep基础上,通过将原论文的wide部分(LR部分)替换成FM,从而改进了原模型依然需要人工特征工程的缺点,得到一个end-to-end 的深度学习模型。
也就是将2.6所讲的W&D中的线性部分linear(X)替换成2.4中的 FM(X) 就是所谓的DeepFM模型。模型的架构如下:
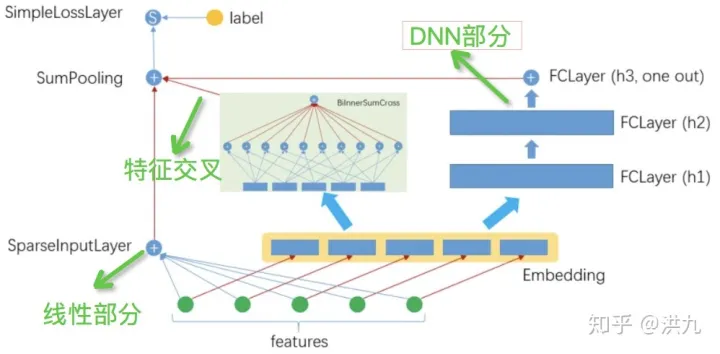
数学公式如下:
将W&D线性部分linear(X)替换成 FM(X) 后增强了低阶特征的表达能力(二阶交叉),克服了W&D的线性部分依然需要对低维特征做特征工程的缺点。
(8) DCN(深度特征交叉网络)
上一小节讲到为了加强低阶特征的表达能力,将W&D中的LR线性部分替换成FM。FM的本质是增加了低纬特征间的二阶交叉能力,为了挖掘更高阶的特征交叉的价值提出了DCN (Deep &Cross Network)模型。
DCN的网络架构如下:
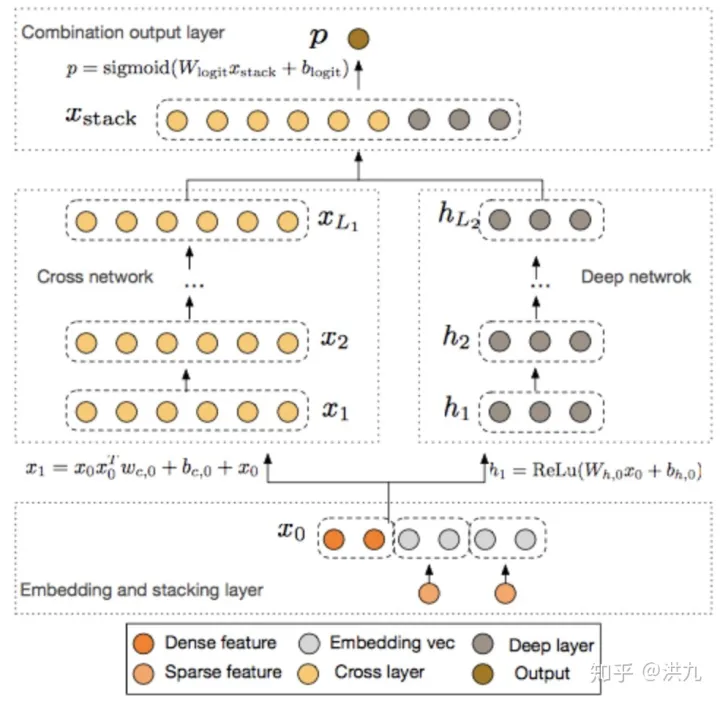
比较DCN与DeepFM的网络架构,可以发现本质区别是将DeepFM的FM结构替换为Cross Network结构。下面看下什么是Cross Network? 以及Cross Network是如何实现高阶特征组合的?
Cross Network结构:
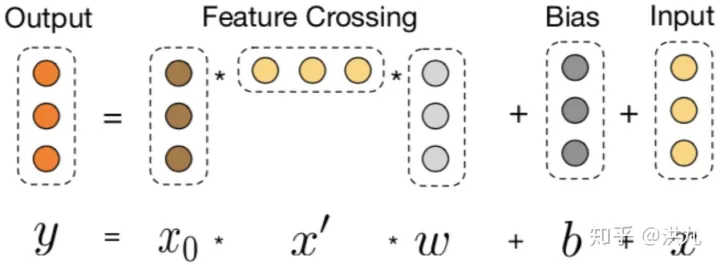
Cross Network整体看是一个递推结构:
首先, 为输入的特征(第一层输入),
为第 L 层的输入,
为第 l 层的参数矩阵。结合图可以看出Cross Network通过矩阵乘法实现特征的组合。每一层的特征都由其上一层的特征进行交叉组合,并把上一层的原始特征重新加回来。这样既能做特征组合,自动生成交叉组合特征,又能保留低阶原始特征,随着cross层的增加,是可以生成任意高阶的交叉组合特征(而DeepFM模型只有2阶的交叉组合特征)的,且在此过程中没有引入更多的参数,有效控制了模型复杂度。
同时为了缓解网络性能"退化"的问题,还引入了残差的思想:
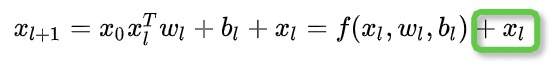
总结一下,DCN提出了一种新的交叉网络,在每个层上明确地应用特征交叉,能够有效地捕获有限度的有效特征的相互作用,学会高度非线性的相互作用,不需要人工特征工程或遍历搜索,并具有较低的计算成本。此外Cross Network可以看成是对FM的泛化,而FM则是Cross Network在阶数为2时的特例。
(9) DIN(基于Attention的用户兴趣动态表达)
在(5)小节中讲到DNN模型利用了用户的历史偏好信息对未知做出预测,然而阿里的研究者们通过收集用户真实数据发现用户行为有两个重要的特性:
a. Diversity:用户在浏览电商网站的过程中显示出的兴趣是十分多样性的。Diversity体现在年轻的母亲的历史记录中体现的兴趣十分广泛,涵盖羊毛衫、手提袋、耳环、童装、运动装等等。而爱好游泳的人同样兴趣广泛,历史记录涉及浴装、旅游手册、踏水板、马铃薯、冰激凌、坚果等等。
b. Local activation:当我们给爱好游泳的人推荐goggle(护目镜)时,跟他之前是否购买过薯片、书籍、冰激凌的关系就不大了,而跟他游泳相关的历史记录如游泳帽的关系就比较密切。
显然,(5)小节中对所有物品简单做element-wise+的操作无法表达上述两种特性,因为这里将所有物品或店铺向量视作同等重要。
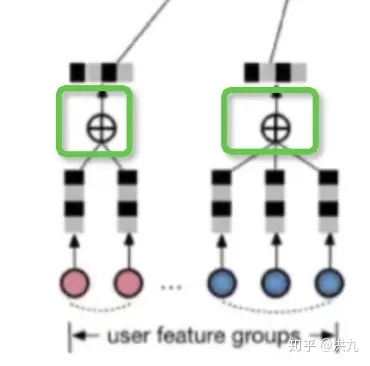
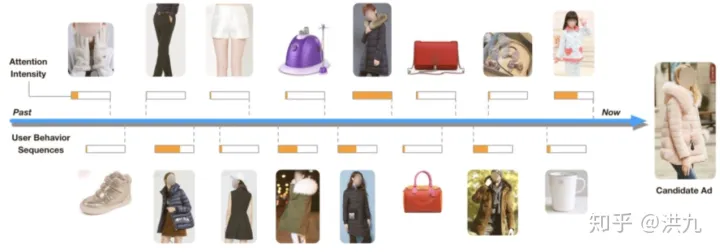
为了解决该问题阿里提出的DIN模型中使用了weighted-sum机制,其实就是加权的sum-pooling,权重经过一个activation unit计算得到,即Attention(注意力)机制。
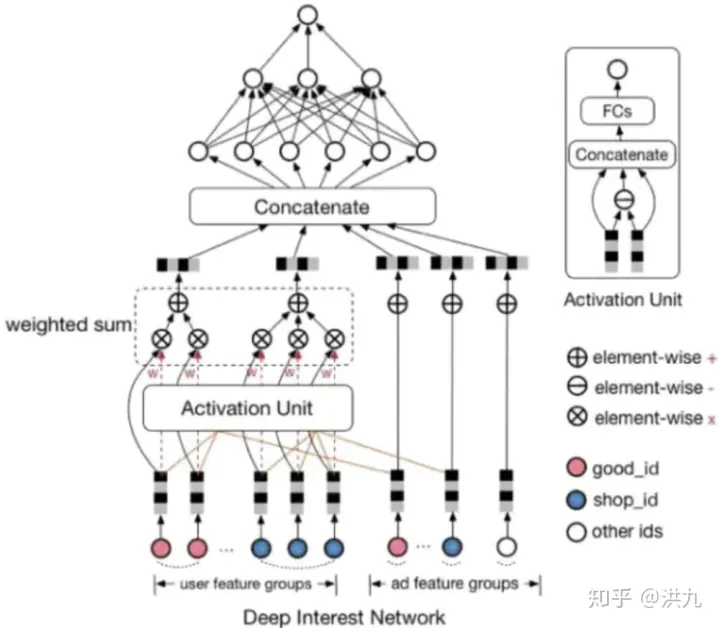
Attention机制也是一个小的神经网络模型,针对不同的候选项,用户历史行为与该候选项的权重是不同的。假设用户有ABC三个历史行为,对于候选项D,那么ABC的权重可能是0.8、0.1、0.1;对于候选项E,那么ABC的权重可能是0.3、0.6、0.1。这里的权重,就是Attention机制即上图中的Activation Unit所需要学习的。
下图是注意力机制的简单示例:
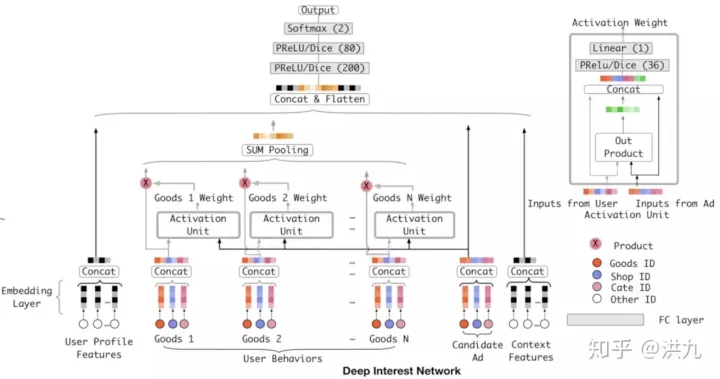
下面是一张更详细的DIN网络结构图:
(10) DIEN(序列模型建模用户兴趣)
前面介绍的深度兴趣网络DIN(Deep Interest Net)提出在电商场景下,用户同时会存在多种多样的兴趣,同时用户在面对一个具体商品的时候只有部分和此商品相关的兴趣会影响用户的行为。DIN提出了一个兴趣激活的模块(注意力机制),用于根据被预测的候选项C激活其相关的历史行为从而表达用户和此商品C相关的部分兴趣。相比以往的模型需要用一个固定的向量表达用户所有的兴趣,DIN用一个根据不同被预测商品变化的向量来表达用户相关的兴趣,这样的设计降低了模型表达用户兴趣的难度。
然而DIN也有其不足:
a. 用户的兴趣其实是一个更为抽象的概念,而DIN的设计中直接将一个具体的用户行为(如点击一个具体的商品)当做了用户的兴趣。
比如用户购买了某款连衣裙,其背后可能是因为触发了用户对颜色、品牌、风格、当季相关的隐藏兴趣,而用户的兴趣并不仅仅局限于这一款具体的商品。
某个用户一段历史行为序列是:
其中, A,B \in I 代表兴趣空间内的两种不同兴趣。
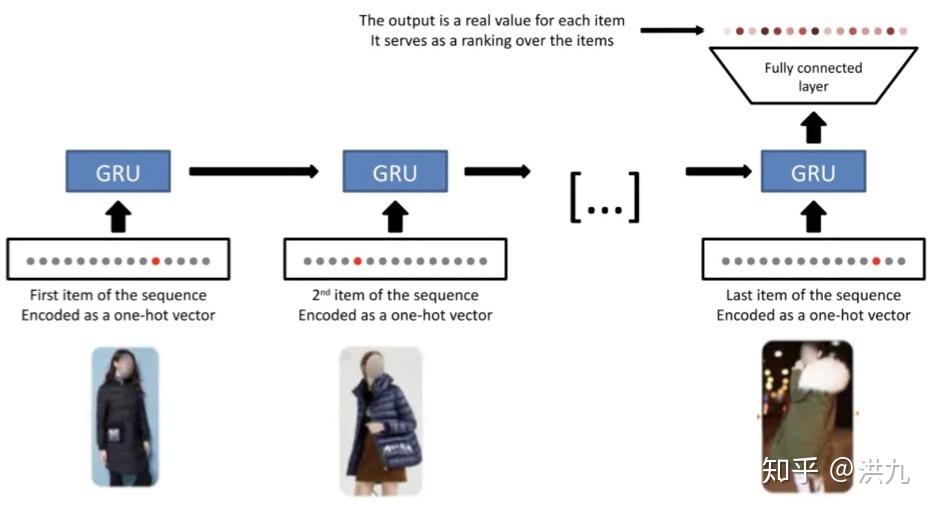
兴趣隐藏在行为背后,用户的历史行为可以看做是多个兴趣的很多采样点混合在一起的综合序列。这样的序列与自然语言处理遇到的有序序列是完全不同的,在这样的场景下,序列被打断是一个常规行为。因此单纯的序列建模,比如RNN、LSTM、GRU模型等,在这种场景下效果是不理想的。
如下图,表示用RNN根据用户历史的行为预测未来的兴趣:
b. DIN忽略了对用户兴趣演化的构建

用户的浏览历史看上去杂乱无章,但其中也隐含着规律性,比如一个女孩看了上衣、裤子后,接下来可能要看下鞋子相关的商品,上衣->裤子->鞋子,这几个兴趣间隐含着某种关联性。
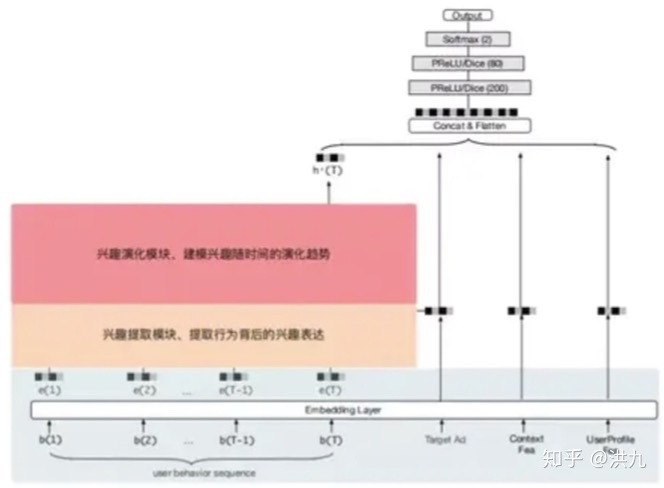
为了解决上面的问题,阿里提出的DIEN(深度兴趣进化网络)中引入了两个新的模块,分别是:兴趣提取模块和兴趣演化模块。
DIEN的网络模型如下:
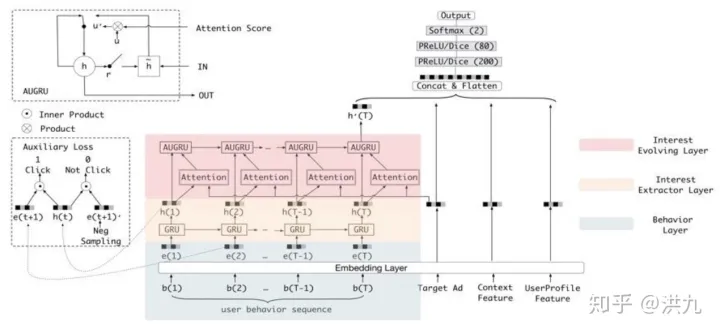
用户历史行为->兴趣抽取模块->兴趣演化模块,简约一点的表示如下:
兴趣抽取模块:行为是具体的,兴趣是抽象的,直接用行为Embedding当兴趣缺乏抽象、概括能力。兴趣提取模块的目的就是挖掘出行为背后用户抽象兴趣的表达。

假设用户浏览了一条裤子,那么裤子id是一个特征,该特征对于推荐系统来说是一个较为随机的特征,然而这个id类特征背后代表的可能是用户喜欢这个裤子的颜色、样式、功能等某更抽象的兴趣。
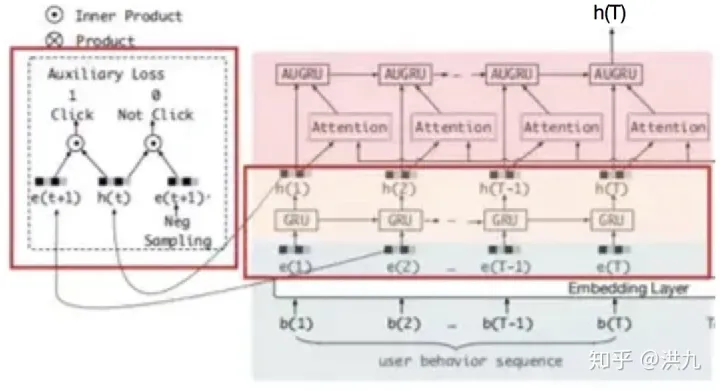
由于用户某一时刻的兴趣,不仅与当前的行为相关,也与历史各个时刻的行为相关。因此可以用时序模型对上述问题建模,比如LSTM、GRU等。
DIEN模型采用GRU模型,因为GRU在效果相差无几的前提下,比 LSTM要节省更多的参数。在神经网络模型整体结构非常复杂的大前提下,会尽量将每一个模块简单化、轻量化。
用GRU提取出的隐层状态表达用户兴趣的抽象。同时还引入了辅助loss的功能,用来辅助提取兴趣表达,有如下好处:
a. 辅助loss利用的label反馈是点击序列pattern而不仅仅是ctr信号。
b. 能有效解决长序列梯度传播问题,因为在现实场景中,用户兴趣序列有可能非常长,若直接用GRU,没有辅助loss,则会面临长序列梯度消失问题。
c. 通过点击pattern的学习,出来hidden state能学的更好,Embedding通过反向传播也能学到更多语义表达,使得学习更加有效。
兴趣演化模块:兴趣提取模块相当于是对用户历史行为提纯,去除噪声,得到用户兴趣表示。而兴趣演化模块则是在提取模块的基础上得到对未来兴趣的抽象表示,这里同样使用了GRU。
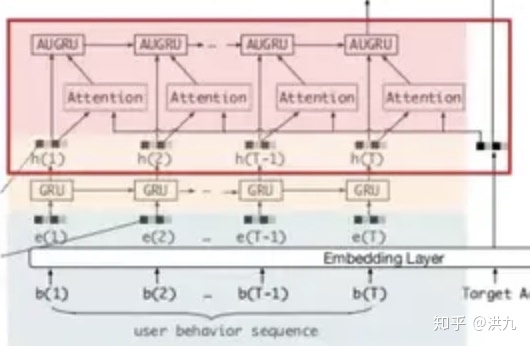
与通常GRU不同的是,这里引入了Attention机制。因为人的兴趣是多峰分布的,比如可能同时对衣服、书籍、电子产品感兴趣,通过Attention机制将筛选出与候选项相关的兴趣,忽略无关的兴趣。
AUGRU = GRU + Attention,使用attention score来控制update门的权重,这样既保留了原始的更新方向,又能根据与候选广告的相关程度来控制隐层状态的更新力度。
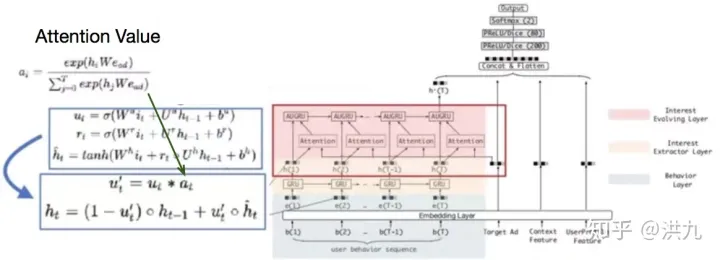
举2个极端的例子:
a.假如该时刻的行为与候选项相关度为1,我们希望这个行为能更新用户兴趣的隐状态即 ,而当行为与候选项不相关的时候我们要保留当前状态,即:
。
b.假如某行为与候选广告不相关,那么隐状态的更新是 , 0 向量并不会不更新,而是会将
更新到一个新的地方去,这并不是我们期望的。
如下公式是常规GRU的公式,可以对比下与AUGRU的不同。
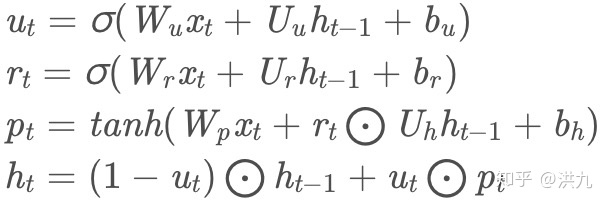
GRU
最后总结下,DIN和DIEN的最底层都是Embedding Layer,User profile, target AD和context feature的处理方式是一致的。不同的是,DIEN将user behavior组织成了序列数据的形式,并把简单的使用外积完成的activation unit变成了一个attention-based GRU网络。
(11) 语义相似模型
Pointwise除了广泛应用于推荐搜索中CTR预估问题外,在问答系统、同义词扩展中也有很多应用。
a.CNN(Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks)
Paper:http://eecs.csuohio.edu/~sschung/CIS660/RankShortTextCNNACM2015.pdf
Code:https://github.com/YETI-WU/Semantic_Analysis_NLP/blob/master/rank_TextPairs.py
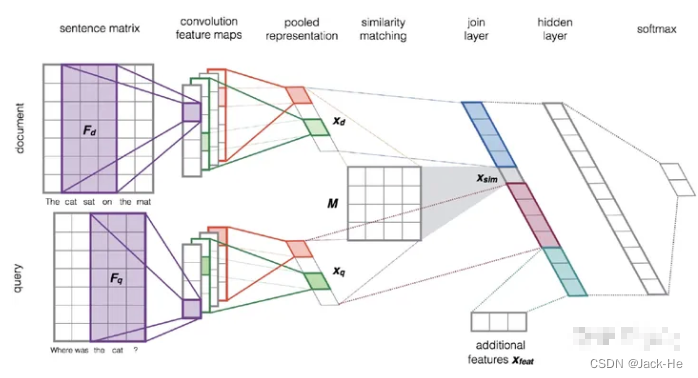
Semantic analysis. GloVe word embedding + Conv1D + MaxPool, concatenated with similarity matching, forward to Softmax layer and following the logistic regression output, binary cross entropy loss function to identify the matching similarity of documentary and query in sklearn datasets fetch_20newsgroup training.
b.DRMM(Deep Relevance Ranking Using Enhanced Document-Query Interactions)
Paper:http://nlp.cs.aueb.gr/pubs/emnlp2018.pdf
c.DSSM
// TODO
Point Wise实战代码参考
6.推荐系统遇上深度学习(十七)--探秘阿里之MLR算法浅析及实现
8.CTR预估[十一]: Algorithm-GBDT Encoder
11. 深度学习在CTR预估中的应用
13.计算广告CTR预估系列(四)--Wide&Deep理论与实践
17.DeepFM理论与其应用
18.推荐系统遇上深度学习(三)--DeepFM模型理论和实践
21.DCN(Deep & Cross Network)模型在手淘分类地图CTR预估上的应用
22.SIGIR阿里论文 | 可视化理解深度神经网络CTR预估模型
23.阿里妈妈DIN模型(Deep Interest Network)
24.DIN(Deep Interest Network of CTR) [Paper笔记]
26.【干货】近年火爆的Attention模型,它的套路这里都有!
28.推荐系统中使用ctr排序的f(x)的设计-dnn篇之AFM模型
推荐系统中使用ctr排序的f(x)的设计-dnn篇之AFM模型 - 知乎
29.DIN(Deep Interest Network of CTR) [Paper笔记]
30.Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
32.推荐系统遇上深度学习(二十四)--深度兴趣进化网络DIEN原理及实战!
34. 双十一疯狂剁手,你知道阿里是如何跟踪用户兴趣演化的吗?
35. 阿里妈妈:定向广告新一代点击率预估主模型——深度兴趣演化网络
36. 搜狐视频个性化推荐架构设计和实践
37.机器学习实践
38.【RNN 推荐】Long and Short-Term Recommendations with Recurrent Neural Networks
39. Deep Relevance Ranking Using Enhanced Document-Query Interactions阅读笔记
45.PaperWeekly 第37期 | 论文盘点:检索式问答系统的语义匹配模型(神经网络篇)
2、Pairwise模型总结应用
Pairwise是目前比较流行的方法,相对pointwise他将重点转向文档顺序关系。它主要将排序问题归结为二元分类问题,这时候机器学习的方法就比较多了,比如Boost、SVM、神经网络等。
对于同一query的相关文档集中,对任何两个不同label的文档,都可以得到一个训练实例 (di,dj) ,如果 di>dj ,则赋值+1,反之为-1。于是我们就得到了二元分类器训练所需的训练样本。预测时可以得到所有文档的一个偏序关系,从而实现排序。

(1) RankNet排序模型
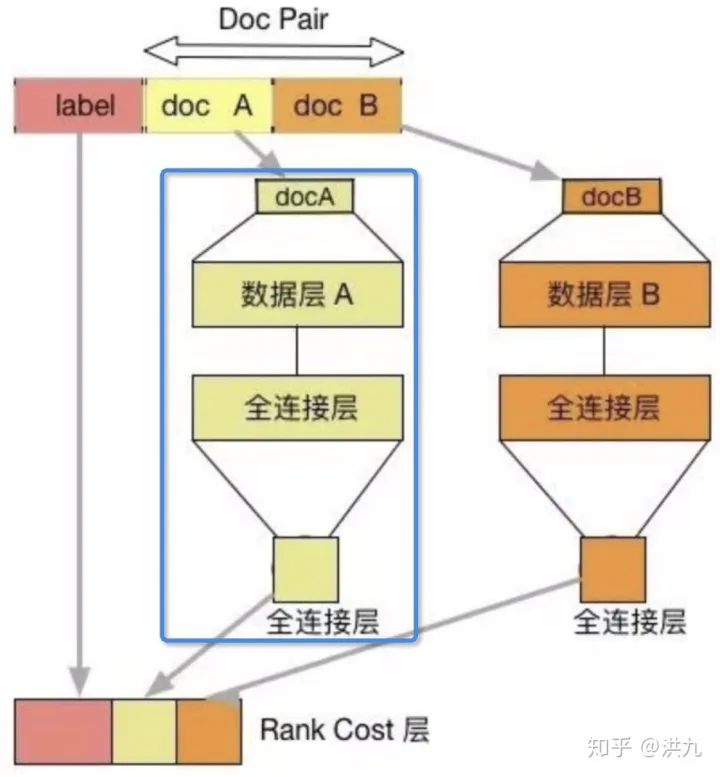
RankNet是一种经典的Pairwise的排序学习方法,是典型的前向神经网络排序模型。在文档集合 S 中的第 i 个文档记做 Ui ,它的文档特征向量记做xi ,对于给定的一根据以上推论构造RankNet网络结构,由若干层隐藏层和全连接层构成。
如下图所示,将文档特征使用隐藏层,全连接层逐层变换,完成了底层特征空间到高层特征空间的变换。其中docA 和docB 结构对称,分别输入到最终的 RankCost 层中。文档对 Ui , Uj,RankNet将输入的单个文档特征向量 x 映射到 f(x) ,得到si=f(xi), sj=f(xj)。将Ui相关性比Uj好的概率记做Pi,j,则
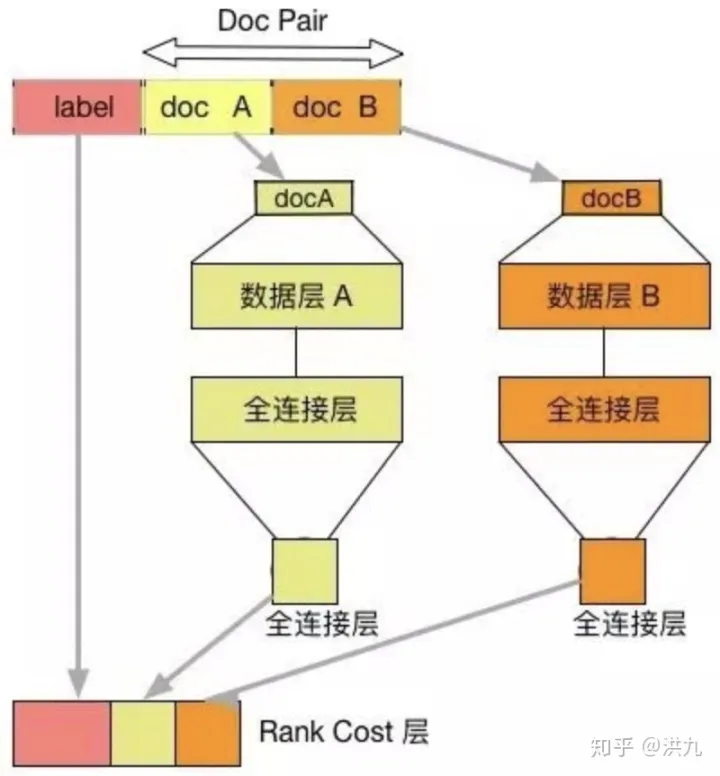
RankNet
由于Pairwise中的网络结构是左右对称,可定义一半网络结构,另一半共享网络参数。模型预测的输入为单个文档的特征向量,模型会给出相关性得分。将预测得分排序即可得到最终的文档相关性排序结果。
注意这里并没有预测偏序关系,输出的是类似Pointwise的单点结果,与Pointwise类模型不同的是Pairwise的模型结构中学到了更利于区分正负样本的特征。
RankCost的损失函数为:
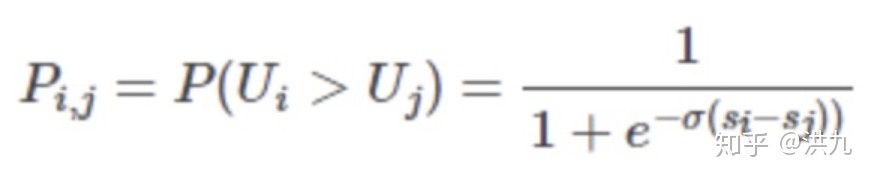
基于Keras的RankNet实现:
# 网络参数
def create_base_network(input_dim):
seq = Sequential()
seq.add(Dense(input_dim, input_shape=(input_dim,), activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(64, activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(32, activation='relu'))
seq.add(Dense(1))
return seq
# Rank Cost层
def create_meta_network(input_dim, base_network):
input_a = Input(shape=(input_dim,))
input_b = Input(shape=(input_dim,))
rel_score = base_network(input_a)
irr_score = base_network(input_b)
# subtract scores
diff = Subtract()([rel_score, irr_score])
# Pass difference through sigmoid function.
prob = Activation("sigmoid")(diff)
# Build model.
model = Model(inputs = [input_a, input_b], outputs = prob)
model.compile(optimizer = "adam", loss = "binary_crossentropy")
return model
事实上Pairwise只是一种框架,可以将图中的网络部分替换成Pointwise部分讲解的任何模型。
(2) xgboost+pairwise
import pandas as pd
import numpy as np
from xgboost import DMatrix,train
# 训练参数
xgb_rank_params = {
'bst:max_depth':2,
'bst:eta':1, 'silent':1,
'objective':'rank:pairwise',
'nthread':4,
'eval_metric':'ndcg'
}
# 产生随机样本
#一共2组*每组3条,6条样本,特征维数是2
n_group=2
n_choice=3
dtrain=np.random.uniform(0,100,[n_group*n_choice,2])
dtarget=np.array([np.random.choice([0,1,2],3,False) for i in range(n_group)]).flatten()
#n_group用于表示从前到后每组各自有多少样本,前提是样本中各组是连续的,[3,3]表示一共6条样本中前3条是第一组,后3条是第二组
dgroup= np.array([n_choice for i in range(n_group)]).flatten()
# 构造Xgboost训练数据
xgbTrain = DMatrix(dtrain, label = dtarget)
xgbTrain.set_group(dgroup)
# 构造评测数据
dtrain_eval=np.random.uniform(0,100,[n_group*n_choice,2])
xgbTrain_eval = DMatrix(dtrain_eval, label = dtarget)
xgbTrain_eval .set_group(dgroup)
evallist = [(xgbTrain,'train'),(xgbTrain_eval, 'eval')]
# 训练模型
rankModel = train(xgb_rank_params,xgbTrain,num_boost_round=20,evals=evallist)
# 测试模型
dtest=np.random.uniform(0,100,[n_group*n_choice,2])
dtestgroup=np.array([n_choice for i in range(n_group)]).flatten()
xgbTest = DMatrix(dtest)
xgbTest.set_group(dgroup)
print(rankModel.predict( xgbTest))输出结果:
[0] train-ndcg:1 eval-ndcg:0.98197
[1] train-ndcg:0.898354 eval-ndcg:1
[2] train-ndcg:0.898354 eval-ndcg:1
[3] train-ndcg:0.898 354 eval-ndcg:1
[4] train-ndcg:0.898354 eval-ndcg:1
[5] train-ndcg:1 eval-ndcg:1
[6] train-ndcg:0.898354 eval-ndcg:1
[7] train-ndcg:1 eval-ndcg:1
[8] train-ndcg:1 eval-ndcg:1
[9] train-ndcg:1 eval-ndcg:1
[10] train-ndcg:1 eval-ndcg:1
[11] train-ndcg:1 eval-ndcg:1
[12] train-ndcg:1 eval-ndcg:1
[13] train-ndcg:1 eval-ndcg:1
[14] train-ndcg:1 eval-ndcg:0.829501
[15] train-ndcg:1 eval-ndcg:0.829501
[16] train-ndcg:1 eval-ndcg:0.829501
[17] train-ndcg:1 eval-ndcg:0.829501
[18] train-ndcg:1 eval-ndcg:0.829501
[19] train-ndcg:1 eval-ndcg:0.829501
[ 1.3936174 1.3936174 -0.65021324 1.3936174 1.3936174 1.3936174 ]Pair Wise代码参考
1. LambdaFM:一种在深度学习模型架构融合pairwise的策略
2.基于Pairwise和Listwise的排序学习
https://cloud.tencent.com/developer/news/135904
3.Learning to rank的讲解,单文档方法(Pointwise),文档对方法(Pairwise),文档列表方法(Listwise)...
https://blog.csdn.net/weixin_30474613/article/details/98159675
4.RankNet
https://github.com/eggie5/RankNet
3、Listwise模型总结应用
Listwise 算法相对于 Pointwise 和 Pairwise 方法来说,它不再将排序问题转化为一个分类问题或者回归问题,而是直接针对评价指标对文档的排序结果进行优化,如常用的 MAP、NDCG 等。
Listwise 的模型有 ListNet、ListMLE、SVM MAP、AdaRank、SoftRank、LambdaRank、LambdaMART。其中 LambdaMART(对 RankNet 和 LambdaRank 的改进)在 Yahoo Learning to Rank Challenge 表现出最好的性能。

















 1469
1469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









