




python实现爬取名人名言
技术路线:requests-bs4-re
- 第一步
首先打开名人名言的网站https://mingyan.supfree.net/search.asp

- 第二步
然后查看源代码,可以看到,名人名言都存储在table标签内,可以利用bs4库对其进行查找标签

即soup1 = soup.find('table') 找到table标签,然后再table标签里再寻找a标签,stockInfo = soup1.find_all('a'),此是的stockinfo变量是class 'bs4.element.Tag类型的,所以需要变换成str类型才可以用正则表达式re库进行精确查找,str1 = str(stockInfo)(这里涉及到将bs4.element.Tag转换成string,可以参考https://www.jianshu.com/p/d67a3858728c)
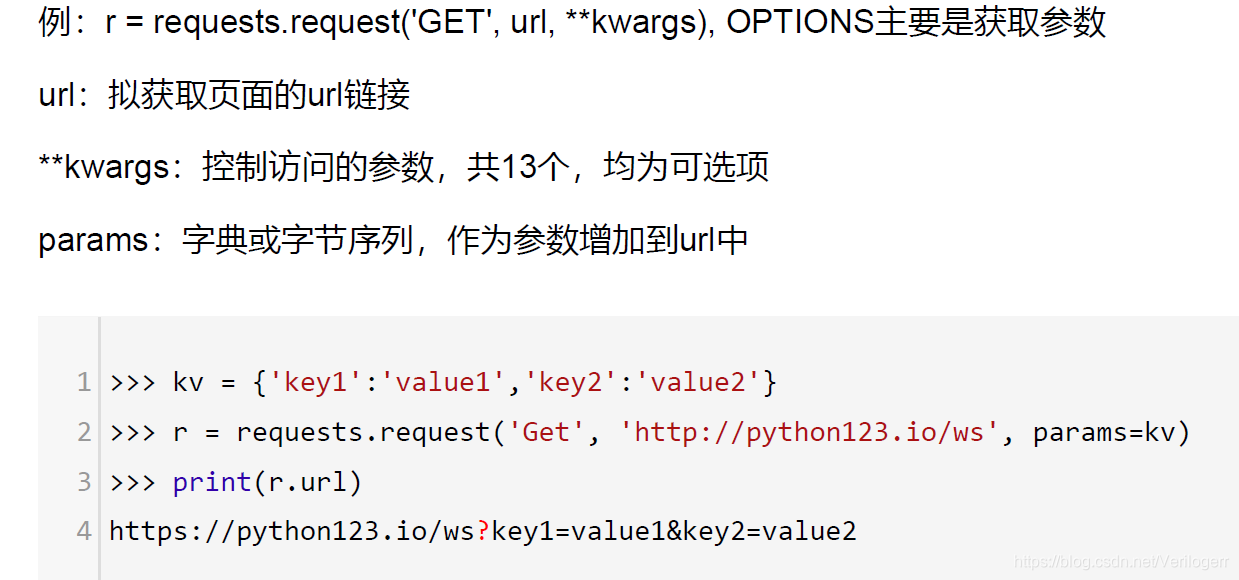
这里可以观察到下一页的url是,可以用requests库参数设置,对url进行修改就可以用for循环实现翻页功能,具体参数设置参考下图,这里我只爬取第一个页面,即用:
for i in range(1, 2):
kv = {
'page': i}
r = requests.get('https://mingyan.supfree.net/search.asp', params=kv)
3. 第三步
最后用正则表达式re库对其进行精确查找
contents = re.findall(r'<a href="honda\.asp\?id=\d+" target="_blank">(.*?)</a>', str1)
authors = re.findall(r'<a href="toyota\.asp\?id=[\u4e00-\u9fa5]+" target="_blank">(.*?)</a>', str1)
完整代码
import requests
import re
from bs4 import BeautifulSoup
# 利用bs4和re库获取html中我们想要的文本信息
for i in range(1, 2):
kv = {
'page': i}
r = requests.get('https://mingyan.supfree.net/search.asp', params=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
html = r.text
soup = BeautifulSoup(html, 'html.parser')
soup1 = soup.find('table')
stockInfo = soup1.find_all('a')
str1 = str(stockInfo)
contents = re.findall(r'<a href="honda\.asp\?id=\d+" target="_blank">(.*?)</a>', str1)
authors = re.findall(r'<a href="toyota\.asp\?id=[\u4e00-\u9fa5]+" target="_blank">(.*?)</a>', str1)
print(contents)
print(authors)
运行效果如下

方法二:直接用re库查找文本内容
import requests
import re
# from bs4 import BeautifulSoup
for i in range(1, 2):
kv =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









